







 mmFER是一种创新的毫米波雷达面部表情识别系统,旨在多媒体物联网应用中提供情感感知。该系统采用双定位方法,通过生物特征信息(如心跳和呼吸)准确地从噪声中定位被测者,再使用高斯混合模型进行面部区域定位。此外,设计了一种跨域转移管道,将图像领域的知识有效转移到毫米波领域,实现了80.57%的平均识别准确性。mmFER系统克服了传统相机和穿戴传感器的隐私和舒适性问题,以及WiFi和超声波方法的性能和多目标支持不足的问题。
mmFER是一种创新的毫米波雷达面部表情识别系统,旨在多媒体物联网应用中提供情感感知。该系统采用双定位方法,通过生物特征信息(如心跳和呼吸)准确地从噪声中定位被测者,再使用高斯混合模型进行面部区域定位。此外,设计了一种跨域转移管道,将图像领域的知识有效转移到毫米波领域,实现了80.57%的平均识别准确性。mmFER系统克服了传统相机和穿戴传感器的隐私和舒适性问题,以及WiFi和超声波方法的性能和多目标支持不足的问题。
原始笔记链接: https://mp.weixin.qq.com/s?__biz=Mzg4MjgxMjgyMg==&mid=2247486744&idx=1&sn=b7abbd894d79debc16610d9d53a27b43&chksm=cf51bfe1f82636f7c8191ee2e10d8b810e3e6c9502e465d0d41bb53f7868ca8021cb395dfc0a#rd
↑ \uparrow ↑ 打开上述链接即可阅读全文
MobiCom 2023 | mmFER: Millimetre-wave Radar based Facial Expression Recognition for Multimedia IoT Applications
毫米波感知论文阅读笔记:MobiCom 2023, mmFER: Millimetre-wave Radar based Facial Expression Recognition for Multimedia IoT Applications
原文链接:https://dl.acm.org/doi/10.1145/3570361.3592515

0 Abstract
-
Background
- Facial expression recognition is vital for enabling emotional awareness in multimedia IoT applications
- Traditional camera / wearable sensor based approaches’ limitations: ❌ privacy, ❌ discomfort
- Recent device-free approaches using WiFi/ultrasound also have limitations: ❌ poor performance / ❌ multiple targets
-
Method
-
Proposes mmFER , a novel mmWave radar based facial expression recognition system
-
Uses a dual-locating approach to extract subtle facial muscle movements from noisy raw mmWave signals
✅ Locates subjects by sensing biometric information (i.e., heart rate and respiration) ⇒ \Rightarrow ⇒ eliminate ambient noise of static/dynamic objects
✅ Locates facial areas of subjects by a Gaussian Mixture Model based face-matching
-
Designs a cross-domain transfer pipeline
- enable effective knowledge transfer from image to mmWave domain
-
-
Experiments
- Achieves accuracy of 80.57% on average at 0.3-2.5m range
- Shows robustness to various real-world settings
-
Contribution
- First mmWave radar based FER system detecting subtle facial muscle movements
- Dual-locating approach to accurately locate faces from noisy signals
- Cross-transfer pipeline for effective model knowledge transfer
1 Introduction
Background and Motivation
-
Facial expression recognition (FER)
- plays a vital role to provide emotional awareness
- emotional awareness is a key factor to enable better service quality and user experience in multimedia IoT applications
-
FER has been studied extensively over the last decade
-
1: Vision-based approaches
- achieve state-of-the-art accuracy
- but are vulnerable to lighting conditions
- Depth camera approaches work better in low light but still have issues with illumination and occlusion
- Camera approaches also raise privacy concerns
-
2 Wearable sensor approaches
- may cause discomfort from long-time wearing.
-
3 Device-free approaches using WiFi or ultrasound signals
- WiFi-based approach may fail with body motions due to limitations of WiFi signals
- Ultrasound-based approach is limited to 60cm range, insufficient for most multimedia applications.
- also don’t support multi-user applications well
-
mmWave sensing is recently popular
- due to high bandwidth and robustness
- provides higher signal resolution to detect subtle movements compared to WiFi/ultrasound
- It has multi-target capability due to high range resolution
- It is illumination free and has fair penetration ability
The paper designs an effective mmWave FER system
Key challenges
-
Source : Facial expressions trigger facial muscle movements across multiple facial areas
-
mmWave radar uses MIMO with antenna arrays to acquire spatial information of these movements
-
But off-the-shelf mmWave radar has limited antennas, resulting in:
❌ Low angular resolution (15-deg azimuth, 58-deg elevation).
❌ Sparse point clouds after merging to improve SNR.
-
-
Challenge 1: Sparse point clouds
-
Enhancing point clouds has limitations:
❌ Advanced radar is expensive and bulky.
❌ Supervised learning needs large labeled datasets
-
This paper: leverages raw mmWave signals containing rich Doppler information
✅ Key challenge is accurately extracting spatial facial information from noisy raw signals
✅ Beamforming focuses on small areas avoiding noise, but:👉 Cannot detect multiple targets simultaneously.
👉 Reduces spatial information by compromising angular resolution
-
-
Challenge 2: Low angular resolution and noise (How to extracting spatial facial information from noisy raw signals?)
-
Converting the problem to spatial localization
✅ Locate subjects by verifying biometric information (heartbeat, respiration).
✅ Extract spatial facial information by filtering out body motions.
✅ Explore correlation between facial muscle movements and spatial facial features.
-
-
Challenge 3: Deep learning needs large training datasets, difficult to collect for mmWave
- Leverage rich image datasets for FER
- Apply cross-domain transfer learning to transform model knowledge from image to mmWave
Proposed mmFER system, contributions and implications
-
mmFER system proposed to address the challenges.
- Dual-locating approach localizes subjects and their facial areas from raw mmWave signals.
- Cross-transfer pipeline enables effective model knowledge transfer from image to mmWave.
-
Contributions
- First mmWave FER system detecting subtle facial muscle movements.
- Dual-locating approach to accurately localize faces from noisy signals.
- Cross-domain transfer pipeline for effective model transfer.
-
Implications
-
mmFER moves a significant step towards the promising mmWave-based FER
✅ addresses privacy concerns
✅ eliminates the need for illumination
✅ robustly works even when the user is wearing various accessories, like masks
✅ outperforms Wi-Fi and ultrasonic approaches
✅ higher bandwidth, longer detection range, and multi-target capability
-
Wide Application of mmFER
🚩 Recommendation systems: sense users’ preferences and reactions in a privacy-preserving manner
🚩 Healthcare: provide timely feedback about the mental state of patients
🚩 AR/VR systems: understand users’ attention and intent in indoor or outdoor environments, improving user experiences
-
2 PRELIMINARY
- Principles of MIMO in mmWave Radar
- MIMO to estimate AoA
- commercial mmWave radars have limited antennas, yielding low angular resolution
- Set-up
- Preliminary experiments done using TI IWR1843BOOST mmWave radar
- Watching movie scenario created with 27-inch screen and radar below screen
- Subject sits 1m from screen to watch movies and perform “surprise” expression
- Radar placed upright to switch 15-deg angular resolution from azimuth to elevation
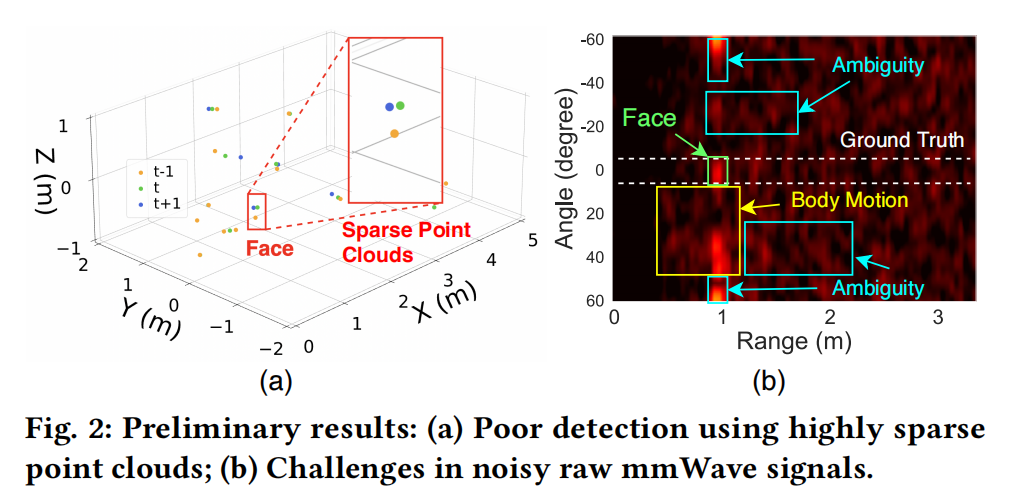
- Sparse Point Clouds
- Point clouds generated contain all motions over time
- Point clouds are sparse and largely contain irrelevant motions or reflections ⇒ \Rightarrow ⇒ infeasible
- Challenges in Raw mmWave Signals
- Preprocessing :Angle FFT applied to raw data converts time-domain to spatial data.
- Feasibility :Facial spatial information can be located but with limited 15-deg resolution
- Challenges : Massive ambient noise and body motion information observed
- Conclusion : Extracting subtle spatial facial information is challenging.
3 mmFER Design
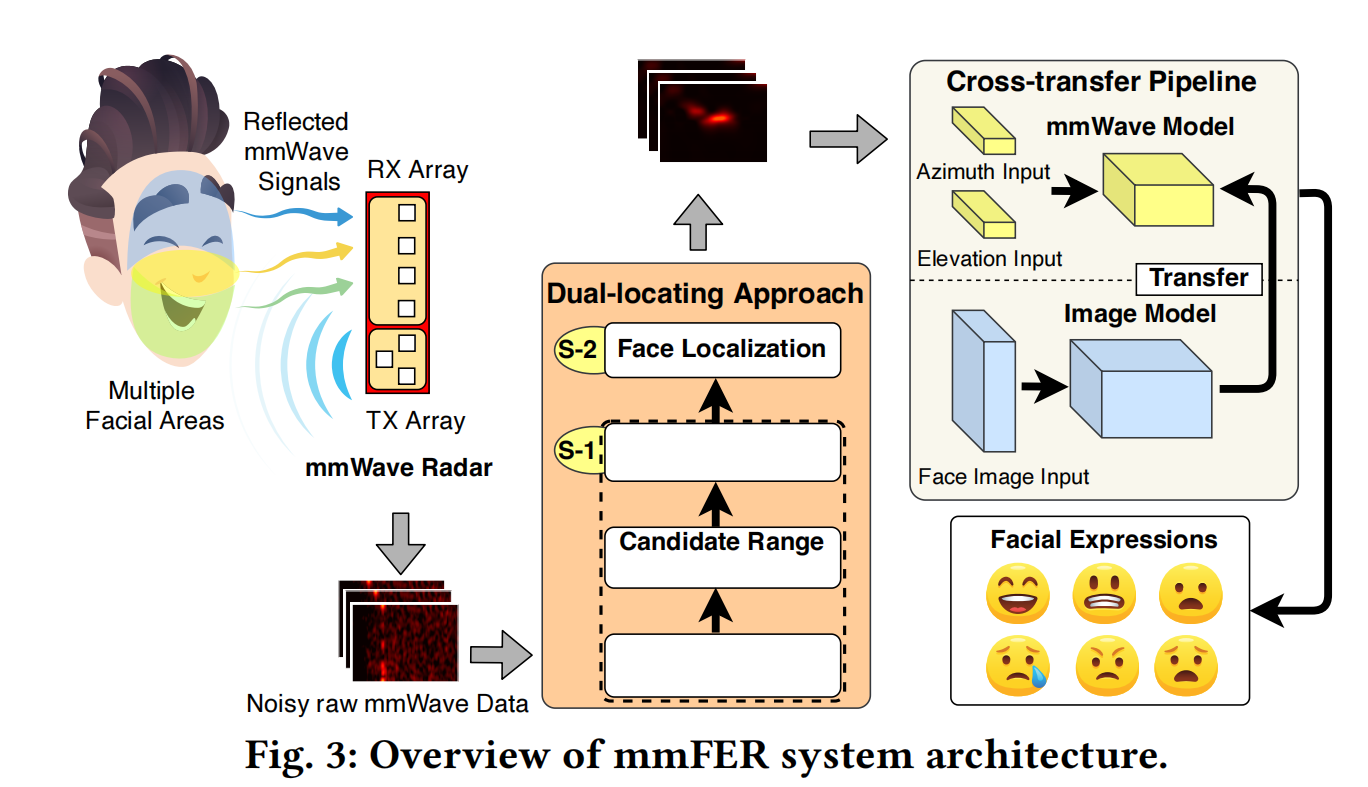
- 3.1 spatial face localization
- propose a dual-locating approach to extracting spatial facial information
- Input: raw mmWave signals
- Output: angle (A) and range ® Heatmaps of multiple facial areas
- 3.2 Cross-transfer pipeline
- mmWave FER model
- Input: Heatmaps
- Output: Facial expression labels
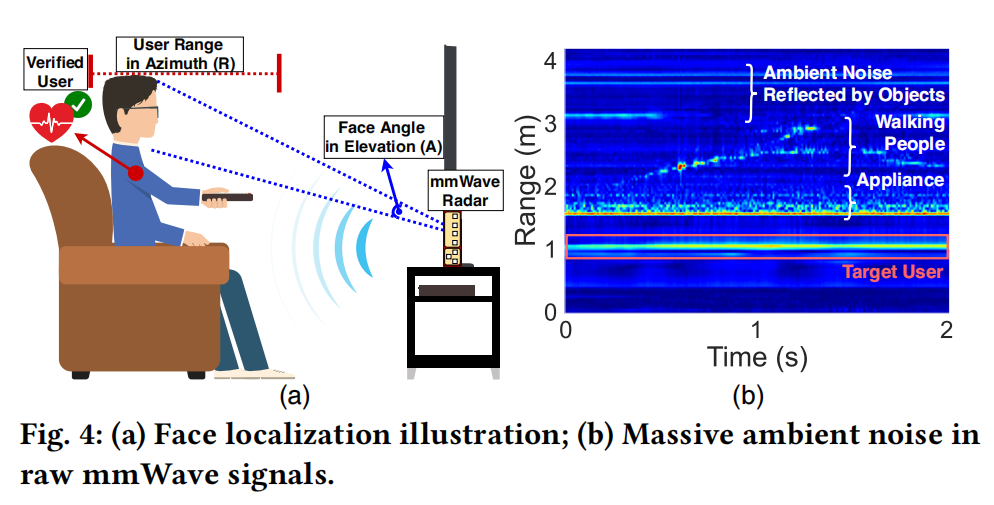
3.1 Dual-locating Approach
- Motivation:
- raw mmWave signals received indoors usually contain massive ambient noise (上图(b))
- while facial muscle movements caused by facial expressions are subtle
- Solution
- a two-step process
- 先 locate subjects, 再 locate facial areas of each subject
3.1.1 Subject Localization (Step 1 of Dual-locating approach)
目标:locates subjects of interest marked as anchor points in azimuth range
-
Dynamic Object Removal
- 目的 :Removes dynamic objects from raw signals
- 特点 :Uses range profile instead of range Doppler to estimate moving objects
- Doppler spectrum of body motions may overlap with facial movements
- 方法
- Defines adaptive velocity threshold based on frame periodicity and range resolution
- Removes objects with velocity greater than threshold based on range shift over time
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











