




碎碎念:在大一大二时听课有的时候会发现听不太懂,那时候只觉得是我自己的基础不好的原因,但现在我发现“听不懂”是能够针对性解决的。比如抽样调查这门课,分析过后我发现我听不懂的原因之一是“没有框架”,一大堆知识扑面而来但我没有建立起自己的逻辑框架,那些零零碎碎的知识看起来毫无章法,才导致我听不懂。那今天的分层抽样就按照讲故事的顺序展开吧~
第一次更新:2024/5/8
目录
一. 分层抽样概述
1. 什么是分层抽样
我们先不看课本上那一长串的符号描述,我们来看国家统计局的定义:
分层抽样(stratified sampling)也称类型抽样,它首先将要研究的总体按某种特征或某种规则划分为不同的层(组),然后按照等比例或最优比例的方式从每一层(组)中独立、随机地抽取个体,最后将各层的样本结合起来对总体的目标量进行估计。
这么来看,分层抽样做的不过就是三个工作:分层、抽样、估计。
那我们就按照这个顺序来展开这项工作。
2. 如何分层
国家统计局的定义里写道 “ 将研究的总体按某种特征或某种规则划分为不同的层(组)”,在实际抽样操作中通常确实采用这种方式,如按照行政机构设置来分层、按照社会经济特征(家庭规模、收入水平等)。但是我们如果在抽取一些工厂样品时,没有明显特征,但是又想要用分层那该怎么分?那就用到统计方法了。
我们在这里将有明显特征的数据定义为“特征分层”,无明显特征的数据定义为“自然分层”。(只是为了方便书写的描述,主要小编没有找到这两者都兼顾到的相关的论文)
⭐ 分层原则
- 层内相似,层间相异(提高估计精度)
- 不重不漏
(1)特征分层
特征分层是什么?
在分层抽样中,通常会根据一定的特征或因素对总体进行分层,这些因素可以根据研究目的和总体特征来选择。例如,可以根据地区、年龄、性别、职业、收入等因素进行分层。每个层应该具有相似的特征,以便在每个层中进行随机抽取样本时能够更好地代表该层的特点。
为什么要进行特征分层?
首先,根据总体的某些特征来分层操作较为简便
其次,根据总体中的人口特征(如年龄、性别、职业、收入等)、地理位置、时间等因素进行分层,可以更好地研究不同群体在不同环境或条件下的变化和趋势。
如何进行特征分层?
在实际操作中我们通常会按照行政机构设置来分层,当层(组)是按行业或行政区划进行划分时,分层抽样为组织实施调查提供了方便。
比如在最近一场市场调查分析大赛中,我们调查的对象是全体武汉市常住居民,首先通过PPS抽样从武汉市的13个区中抽取6个行政区,接着采用分层抽样从6个行政区中抽取入样街道。依据这样的分层标准,在实时操作中极大提高了效率。
(2)自然分层
什么是自然分层?
自然分层/组,通常是按照数据集自身特征进行分组(可以等距也可以不等距)。来个例子理解一下:
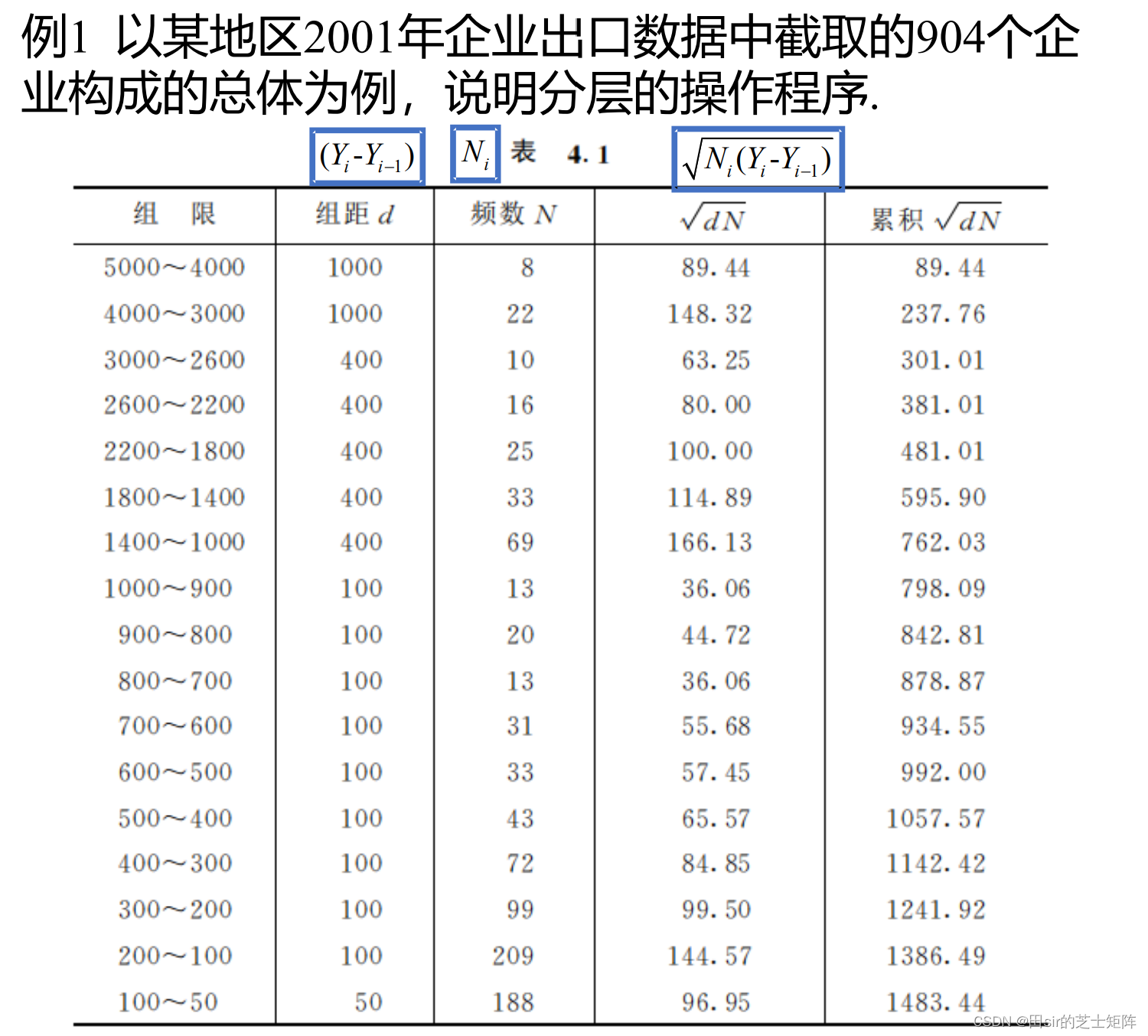
第一列的组限就是我们自然分组的标识。
为什么要进行自然分层?
调查总体没有什么明显特征时通常可以用自然分组来分类汇总。
如何确定分层的层数?——累计平方根法
我们在这里只讲结论和应用,具体论证可以看这篇论文:
主要原理就是要保证层内相似,层间相异
DH方法(累计平方根)给出结论:各层所占的频率(频数)的平方根与各层所占间距的平方根之乘积相等。也就是保证分层后的:
其中di表示第i层的层内间距,Ni表示第i层的频数。
我们直接上干货——做题方法
在这一类型的题目中通常会给我们一些数据变量:在一个表格中列出分层变量的取值范围(组限)、对应的频数、频数的平方根、向下累积的频数平方根。如下:
step1. 初步分层
经验模拟表明使用5~6个层是比较适宜的。
摘自《抽样调查》北大出版社
如果要分k层,就用累计频数平方根除以k得到分层点。
我们就用右下角那个累计的数字1483.44除以5得296.69
那就规定第一层边界点在296.69处,第二层边界点在2×296.69=593.38处,第三层边界点在3×296.69=890.07处以此类推。是不是发现表内的累计和我们计算出的有点差距,没关系我们找最接近这个值的当作边界点就可以。
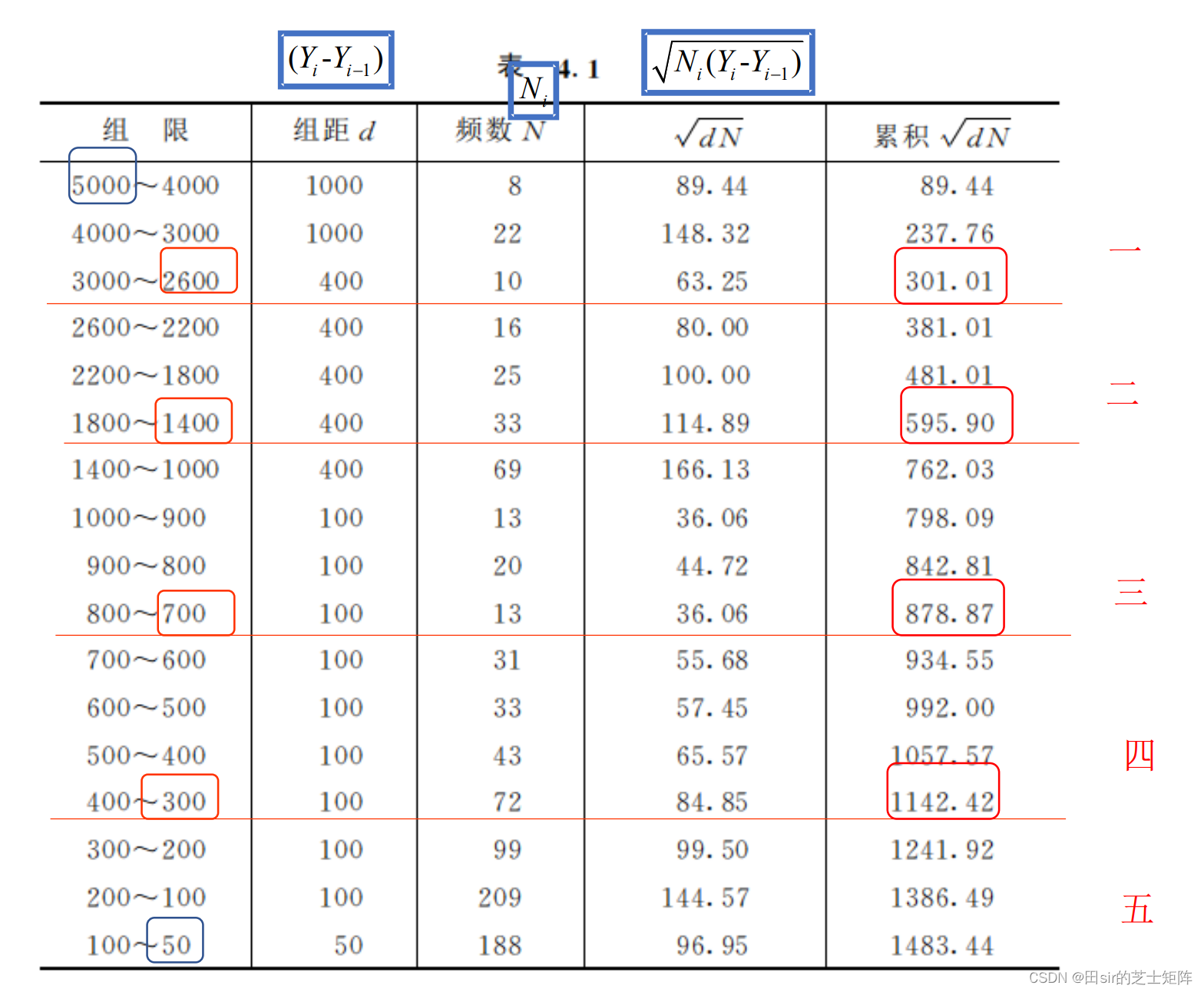
step2. 合并层并计算新的
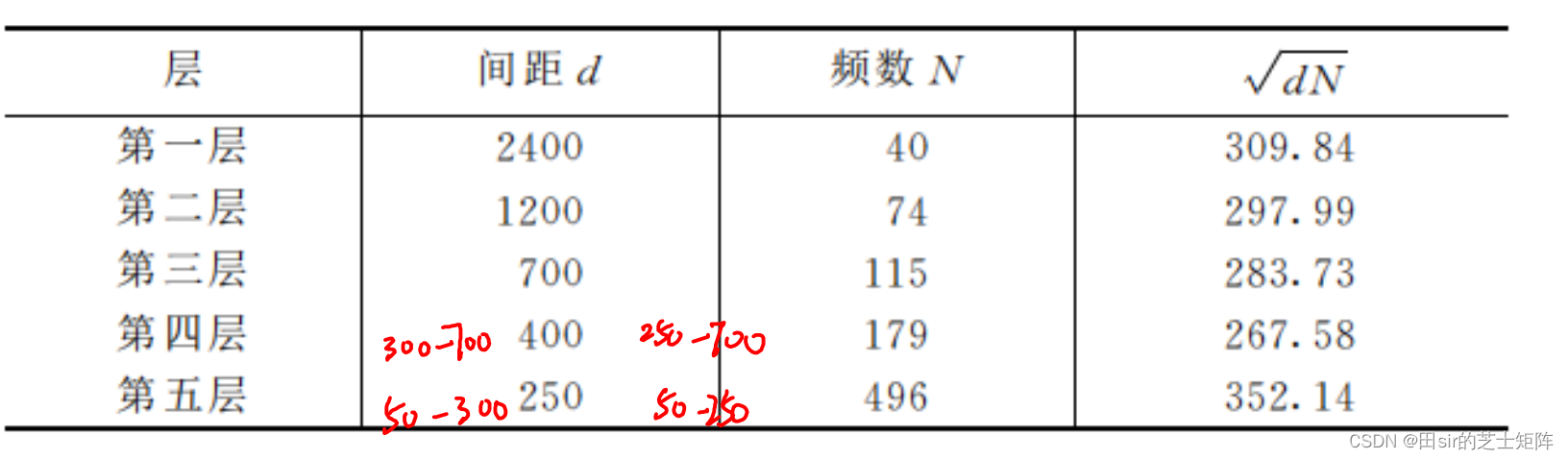
我们将这5个层的组距d,频数N,和进行统计,绘制新表格:
step3. 修正分层(看情况可以不写)
那怎么知道我们分的好不好呢?这就要用到我们说的DH方法(也就是累计平方根)原理了(人话版):
看最后一列
309.84、297.99、283.73、267.58、352.14这几个数里267.58很明显有点小,而352.14又很明显有点大。所以可以尝试给第四层多50个样本,第五层少50个样本,再做新统计:
| 层 | 间距d | 频数N | √𝒅𝑵 |
| 第一层 | 2400 | 40 | 309.84 |
| 第二层 | 1200 | 74 | 297.99 |
| 第三层 | 700 | 115 | 283.73 |
| 第四层 | 450 | 226 | 267.58 |
| 第五层 | 200 | 449 | 352.14 |
现在是不是差不多了。
“给第四层多50个样本,第五层少50个样本”这一步数据哪儿来的,还有另一个组限分的更细的表有写,如果题目只给了上面一个表,咱就不需要再调整了。
3. 如何抽样
我们在这个部分聚焦于两个问题:怎么抽和抽多少,专业一点就叫做抽样方式和样本量分配。
(1)抽样方式
- 如果每层都是按照简单随机抽样进行抽取,则是分层随机抽样,大多数情况下都是分层随机抽样。
- 分层抽样也可以依据每层样本的特点选择合适的抽样方式如:PPS抽样、ΠPS抽样等
(2)样本量确定
想要确定我们在每层抽多少我们还需要考虑两方面:一共要抽多少(总样本量确定)以及每层抽多少(样本量分配)。
1) 总样本量确定
先看这篇文章,我们会再单独出一期详细的样本量确定方法的
《抽样技术》第3章 分层随机抽样(st)_累计平方根-CSDN博客
2)样本量分配
我们知道要抽取的总的样本量为n,划分层数为K层时,每层抽取的样本量假设为ni。
等额分配
各层样本量:
按比例分配
各层样本量:
均方误差:
适用情况:各层单元数或者层权已知,其他信息量很少
奈曼最优分配
各层样本量:
均方误差:
最小均方误差:
核心原理:层内方差最小
考虑费用的最优分配
费用表示:
样本总量:
各层样本量:
适用情况:费用固定层内方差最小;层内方差固定费用减少

















 1895
1895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









