







引言
接着上一篇双参数双门限法的语音端点检测的文章写。
上一篇用了两个参数,短时能量和短时过零率。
这一篇只用一个参数,短时能量。当然,还可以用其他特征。总之,特征个数(种类)仅限一个。
基本思想
设置2个参数。从静音到大于大门限T2时,认为第一次大于T2时是语音起点。再看什么时候低于小门限T1,决定终点。大概是这样。
注意事项
这种度量,可以是越大越相似,可以是越小越相似。这要看实际采用什么作为“距离”度量了。
为了检测出语音之间的停顿,在检测的过程中,需要设定当前的状态(语音、过渡、静音等状态)。
一边检测,一边更新当前的状态。有时候,检测出当前好像是静音状态,但其实可能仅是语音之间的停顿而已。
因此,需要“延音”,即再往前走几帧。看是否真的是停顿。比如,设置一个停顿的计数器silence_counter。
停顿一帧,silence_counter++。判断是否大于预设的,最大允许停顿的帧数。
如果是,则看是否是突发噪声等。如果还没有,那如果本来是语音段来的话,就继续保持语音段,往前再延几帧。
总之,很是麻烦。很繁琐。容易重复,也容易漏。
为了避免这种情况的发生,最好,列出状态转移表,把当前每一种状态的判别情况写清楚。
最后,画出流程图。直接写代码很头疼。
主函数
%% 单参数的双门限VAD
% 作者:qcy
% 版本:v1.1
% 版本说明:1. 封装 单参数双门限检测 函数 my_vad_param1d();
% 2. 本文件是利用 短时能量特征 进行端点检测。
% 版本:v1.0
% 版本说明:使用对数谱距离作为标准
% 时间:2016年11月3日9:47:28
%%
clear;
close all;
clc
%% 导入音频
filedir=[]; % 设置文件路径
% filename='bluesky1.wav'; % 设置文件名称
filename='seaboat.wav'; % 设置文件名称
% filename='静默检测.m4a'; % 设置文件名称
fle=[filedir filename]; % 构成文件路径和名称
SNR = 5;
[xx,fs] = audioread(fle);
xx=xx-mean(xx); % 消除直流分量
x=xx/max(abs(xx)); % 幅值归一化
N=length(x); % 取信号长度
time=(0:N-1)/fs; % 设置时间
signal=Gnoisegen(x,SNR); % 叠加噪声
figure(1);
subplot(311);
plot(time,signal);
%% 短时能量提取
% 设置帧长、步长
wlen_time = 0.02; % [s]
step_time = 0.01; % [s]
wlen = round(wlen_time*fs);
nstep = round(step_time*fs);
nframes = fix((length(x)-wlen)/nstep)+1; % 帧数
frame_time = frame2time(nframes, wlen, nstep, fs); % 计算每帧对应的时间
Er = get_st_energy( x,fs,wlen_time,step_time,'hamming','dB' );
% 因为有噪声,可以考虑对Er进行滤波,使其平滑
Er = multimidfilter(Er,3);
figure(1);
subplot(312)
plot(frame_time,Er);
% plot(Er);
title('短时能量');
%% 2. 获取噪声特性,定义静默检测中所需要的一些参数
% (1) 测量环境噪声,获取一些噪声的参数
noise_frame_idx=floor((0.1-wlen_time)/step_time)+1; % % 假定前100ms是环境噪声
eavg=mean(Er(1:noise_frame_idx)); % 计算环境噪声的 平均短时功率
esig=std(Er(1:noise_frame_idx)); % 计算环境噪声的 短时功率的标准差
% (2) 根据背景噪声设置阈值
ITU = -15; % constant in the range [-10 -20] dB
ITR_HIGH = max([ITU-10 eavg+3*esig]); % 均值往上加3倍标准差,作为短时功率的阈值
ITR_LOW = ITR_HIGH - 3; % 大于ITR_LOW,小于ITR_LOW,认为可能是语音和静音之间
%% 3. 单参数双门限检测
T1 = ITR_LOW;
T2 = ITR_HIGH;
SILENCE = 0;
TRANSITION = 1;
SPEECH = 2;
MAX_TRANSITION_FRAME_LENGTH = 10;
MIN_SPEECH_FRAME_LENGTH = 4;
dist = Er;
[B,E] = my_vad_param1d( dist,T1,T2,MAX_TRANSITION_FRAME_LENGTH,MIN_SPEECH_FRAME_LENGTH );
%% 画图
figure(1);
subplot(313);
plot(time,signal);
for k=1 : length(E) % 画出起止点位置
nx1= B(k);
nx2 = E(k);
line([frame_time(nx1) frame_time(nx1)],[-1.5 1.5],'color','r','LineStyle','-');
line([frame_time(nx2) frame_time(nx2)],[-1.5 1.5],'color','r','LineStyle','--');
end
%% 播放
% for k=1 : length(E)
% nx1= B(k);
% nx2 = E(k);
% fprintf('Press any key to continue...\n');
% pause;
% sound(signal(round(frame_time(nx1)*fs):round(frame_time(nx2)*fs)),fs);
% end
单参数双门限检测函数
function [ B,E ] = my_vad_param1d( dist,T1,T2,MAX_TRANSITION_FRAME_LENGTH,MIN_SPEECH_FRAME_LENGTH )
%function [ output_args ] = my_vad_param1d( dist,T1,T2,MAX_TRANSITION_FRAME_LENGTH,MIN_SPEECH_FRAME_LENGTH )
% 单参数的双门限检测函数
%
% 输入参数
% dist:每一帧的距离度量
% T1:低门限
% T2:高门限
% MAX_TRANSITION_FRAME_LENGTH:最大允许的过渡段的帧数
% MIN_SPEECH_FRAME_LENGTH:所允许的最短的语音帧数
% 返回参数
% B:端点所在帧序号。数组。
% E:终点所在帧序号。数组。
%
% 版本:v1.0
% 作者:qcy
% 时间:2016年11月4日12:58:51
if nargin < 5
MIN_SPEECH_FRAME_LENGTH = 5;
end
if nargin < 4
MAX_TRANSITION_FRAME_LENGTH = 8;
end
SILENCE = 0;
TRANSITION = 1;
SPEECH = 2;
state = SILENCE;
speech_counter = 0;
transition_counter = 0;
B = [];
E = [];
k_speech = 0; % 语音段序号
for k = 1 : length(dist)
dist_k = dist(k);
switch state
case{SILENCE,TRANSITION} % 从静音、过渡来的
if dist_k > T2 % 当前已经进入语音段的阈值
state = SPEECH;
speech_counter = speech_counter + 1;
transition_counter = 0;
k_speech = k_speech + 1;
B(k_speech) = k;
elseif dist_k > T1 % 仅在过渡段,语音还没有开始
state = TRANSITION;
speech_counter = 0;
% speech_counter = speech_counter + 1;
% transition_counter = 0;
elseif dist_k < T1 % 还是静音段
state = SILENCE;
speech_counter = 0;
transition_counter = 0;
end
case SPEECH % 从语音段来的
% 【注意】 原来写的是>T2,但效果不是很好。T2要求太高了。
% 通常要比T1小,语音才会真正结束。观察一下短时能量的图就知道了。
if dist_k > T1 % 比低的门限高,就认为还在语音段。
state = SPEECH;
speech_counter = speech_counter + 1; % 语音段继续计数
transition_counter = 0;
else % 低于较低的T1门限,“似乎”进入静音段。
transition_counter = transition_counter + 1;
% 有可能是语音结束,可能是语音间停顿,有可能是突发噪声。下面验证。
if transition_counter < MAX_TRANSITION_FRAME_LENGTH % 小于预定的语音中最长间隔、停顿
state = SPEECH; % 就还认为是语音段 --> 起到 “延音” 的作用
speech_counter = speech_counter + 1;
else % 如果停顿很长了,就可能是语音结束了。可不可能是“突发的噪声”呢?
if speech_counter < MIN_SPEECH_FRAME_LENGTH % 判断是语音结束还是噪声
state = SILENCE; % 噪声
speech_counter = 0;
transition_counter = 0;
if k_speech > 0 % 刚刚如果把噪声错误地当做起点了,
k_speech = k_speech - 1;
B = B(1:end-1); % 发现是突发的噪声,就把刚刚记录的起点从起点数组中去掉
end
elseif speech_counter > MIN_SPEECH_FRAME_LENGTH % 确实是语音,不是噪声
state = SILENCE; % 语音结束
speech_counter = 0;
transition_counter = 0;
E(k_speech) = k;
end
end
end
end
end
if length(B)>length(E) % 好像,起点总会要么跟终点个数一样多,要么多一个
% 最后一个终点没有找到,就把最后一帧当做终点。
E(length(E)+1) = length(dist);
end
工具函数
生成AWGN,加入信号。
function [y,noise] = Gnoisegen(x,snr)
% Gnoisegen函数是叠加高斯白噪声到语音信号x中
% [y,noise] = Gnoisegen(x,snr)
% x是语音信号,snr是设置的信噪比,单位为dB
% y是叠加高斯白噪声后的带噪语音,noise是被叠加的噪声
noise=randn(size(x)); % 用randn函数产生高斯白噪声
Nx=length(x); % 求出信号x长
signal_power = 1/Nx*sum(x.*x); % 求出信号的平均能量
noise_power=1/Nx*sum(noise.*noise);% 求出噪声的能量
noise_variance = signal_power / ( 10^(snr/10) ); % 计算出噪声设定的方差值
noise=sqrt(noise_variance/noise_power)*noise; % 按噪声的平均能量构成相应的白噪声
y=x+noise; % 构成带噪语音
因为有噪声,短时特征可以先平滑处理。采用多次中值滤波。
function y=multimidfilter(x,m,order)
if nargin < 3
order = 5; % 默认使用5阶中值滤波
end
a=x;
for k=1 : m
b=medfilt1(a, order);
a=b;
end
y=b;结果示意
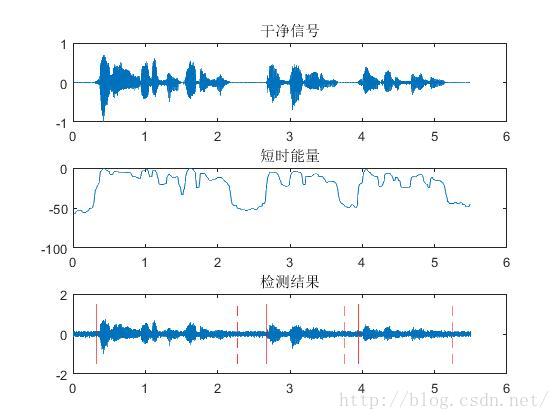
第一张子图里的干净信号加了AWGN后,成为了第三张子图里带有噪声的信号。
检测是在含噪声的信号中检测的。
















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











