







Uncovering the Hidden Cost of Model Compression
- 论文链接:https://arxiv.org/pdf/2308.14969.pdf
- 源码链接:https://github.com/landskape-ai/reprogram_lt
简介
深度学习发展已经从训练特定任务的模型转向广泛的任务不可知预训练。目标是构建一个具有鲁棒通用表示的模型,在不需要密集训练情况下促进许多下游任务。这类模型现在包含在术语“基础模型”。在更广泛的迁移学习中,这些预训练模型对下游任务的有效性通常通过简单且计算高效的适应方法来证明,如线性探测(LP)。传统上,迁移学习是使预训练模型适应各种下游任务的基础,历史上仅限于全微调(FT)和线性探测。前者虽然通常性能优秀,但也是成本更高的方法,而后者计算上更便宜,但与全微调相比,通常表现出更低的性能。
尽管线性探测和全微调传统上是标准的迁移学习,但一种新方法,成为模型重编程或更常见的称为视觉提示(Visual Prompt,VP),已经称为一种可行且有效的替代方法,能够在性能和迁移成本方面与LP媲美。本质上VP涉及到学习扰动,这样当应用于目标数据集的输入样本时,预训练模型可以学习准确地对结果重编程的样本进行分类,而不需要对权重进行任何修改。重编程依赖于将目标数据特征与源数据的特征对齐,从而消除了对网络权重进行梯度更新的需要。因此,VP经常在效率方面与LP竞争。
虽然几项研究中已经实证证明了线性探测(LP)和视觉提示(VP)在不同目标数据场景中性能,但在受到(a)低数据量和(b)模型稀疏性的约束,对这两种方法之间的区别的探索有限。本文研究试图揭示在各种数据量设置的迁移学习领域中与稀疏模型相关的隐藏成本。在现有文献中,这些成本涵盖广泛,包括模型属性,如可靠性、分布变化下的性能、公平性等。
为此在低数据量的约束下,本文检查了预训练模型在少样本设置下的可迁移性。对于模型稀疏性的约束,本文研究包括通过压缩技术生成的大量稀疏模型,如非结构化剪枝、结构剪枝和基于彩票假说的解决方案。
实验与分析
实验设定
本文考虑了8个目标数据集,这些数据集包括近端和远端域的下游任务,包含CIFAR-10、SVHN、GTSRB、DTD、Flowers102、OxfordPets、EuroSAT和 Caltech101。模型架构方面,本文实验基于ResNet系列模型,包括ResNet-18、ResNet-34、ResNet-50和CLIP。
对于剪枝模型,对ResNet-18和ResNet-34使用GMP剪枝模型,对ResNet-50使用AC/DC、RigL以及在不同稀疏度水平下导出的彩票假说的解。所有这些检查点都是在ImageNet分类任务上预训练的。
为了确保一致性兵测量统计显著性,所有配置都使用三个种子进行,总共进行了15000多次实验。最后对于视觉提示(VP)方法,将基于随机标签映射(Random Label Mapping,RLM-VP)、基于频率的标签映射(Frequency-based Mapping,FLM-VP)和迭代标签映射(Iterative Label Mapping,ILM-VP),这是SOTA的VP方法。
性能分析
稀疏模型
GMP
使用ILM-VP、FLM-VP和RLM-VP在各种下游数据集上分析GMP剪枝的ResNet-18和ResNet-34模型在80-90%左右的逐层稀疏性水平下迁移性能,可以看出稀疏模型与其等价的密集模型相比有明显的不利影响。
图1可以看出一般的密集模型,对于ILM-VP迁移时最好的模式,其次是FLM-VP,而RLM-VP通常落后很多,除了在某些情况下如SVHN和GTSRB,这三种VP传输方法性能相当。无论迁移模式如何,所有设置中的稀疏模型都被相应的密集模型大大超过,并且稀疏模型通过不同VP模式的迁移性能之间没有明确的趋势和分级。在OxfordPets数据集,剪枝后模型迁移伤害最大,对于不同数据预算,性能差距始终超过50%。
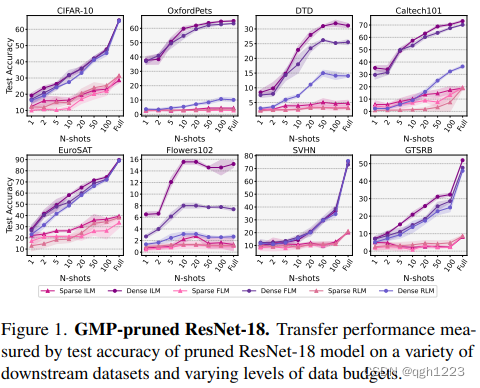
图2中观察到ResNet-34趋势与ResNet-18趋势非常相似,在ResNet-18中,无论VP类型如何,所有数据预算和所有下游数据集的密集模型都优于稀疏模型。观察到迁移模型的精度显著提高,尤其是在完整的数据设置中,这可能是因为与ResNet-18相比,模型架构的大小有所提高。本文还观察到,对于稀疏和密集模型,ILM-VP仍然始终优于其他VP方法。
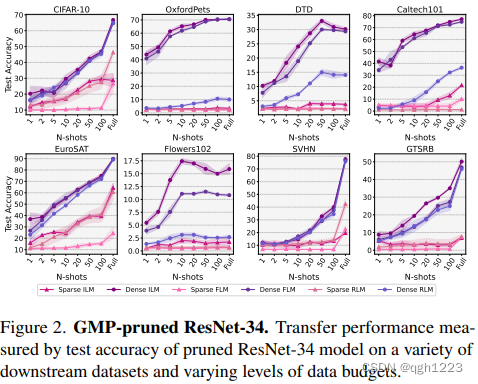
总之本文在多个下游数据集和不同数据预算设置中观察到通过视觉提示方法迁移到GMP剪枝的ResNet-18和ResNet-34模型的有害影响,尽管这些模型与密集模型的上游ImageNet-1k性能相匹配,ResNet-18性能为69.8%,ResNet-34性能为73.3%。
AC/DC与RigL
这里研究剪枝后的ResNet-50模型在AC/DC压缩的80%、90%和98%稀疏性以及RigL压缩的80%、90%和95%稀疏性下的性能。
图3和图4中观察到在顶行的的四个数据集上,密集模型在AC/DC和RigL方面都优于稀疏模型。而在底部四个数据集上,稀疏模型在某些稀疏性和数据预算设置中与密集魔心给的性能相匹配,而在Flowers102下游分类任务中,AC/DC和RigL的两组稀疏模型都比密集模型好约2%。
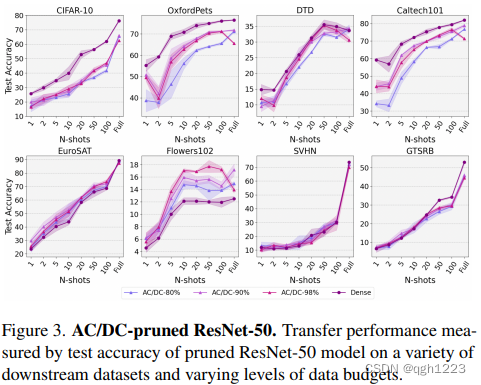
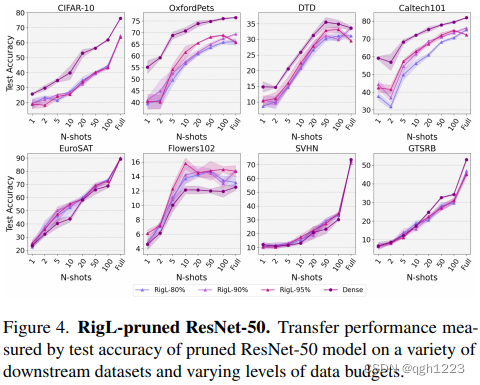
与ResNet-18和ResNet-34相比,本文发现用AC/DC和RigL剪枝的ResNet-50模型虽然总体上比其密集网络更差,但相比之下往往性能相对更好。总体上,通过这两种动态稀疏化剪枝的模型的下游任务性能趋势非常相似。
LTH
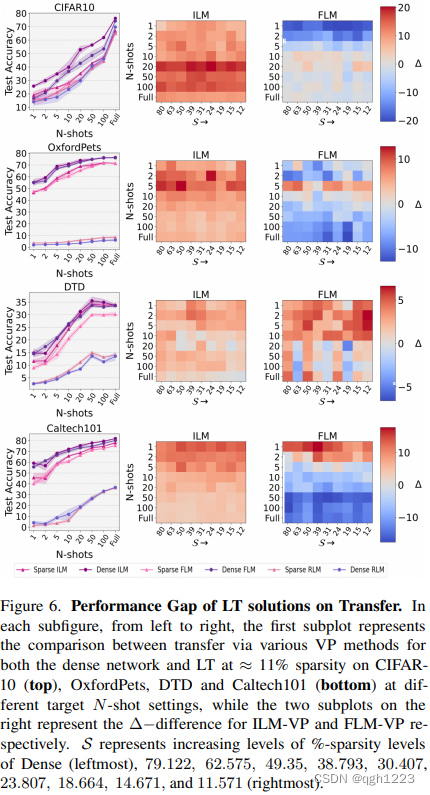
本节中研究了ResNet-50的LTH解决方案在不同数据预算设置下各种稀疏状态配置迁移时性能。在每个数据集左侧子图中报告了通过三种VP方法迁移的密集模型和最稀疏模型(稀疏度约12%)的测试精度,而右侧热图的每个单元表示在(稀疏度,N shot)对的指定状态下,密集模型性能与稀疏模型迁移之间种子的平均差异。
以CIFAR-10为例,从图6中测试精度子图来看,对于每个N样本预算,密集模型在通过ILM-VP和FLM-VP迁移时表现优于LT。此外观察到ILM-VP在所有N样本设置中都优于FLM-VP。RLM-VP性能通常比其他VP方法低得多,但与这一趋势略有偏差,本文发现稀疏模型往往与密集模型性能相匹配,尤其是在数据预算较高的迁移设置下。
此外还观察到,在ILM-VP中,LT对性能不利影响最为明显。例如,在20样本配置中,与密集对应模型相比,本文研究中所有稀疏状态下LT的TOP-1精度平均下降20%。在FLM-VP情况下,正如在一样本和二样本数据预算设置情况下所看到的那样,对于少样本情况,LT性能实际优于密集模型性能。
















 8140
8140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











