







 本文通过Kaggle的手写数字识别挑战,探讨了神经网络的细节,包括增加网络层数、权重初始化问题、简单参数调整的影响以及使用Batch Normalization算法对模型性能的提升。实验结果显示,合理调整网络结构和使用BN算法能显著提高模型准确率。
本文通过Kaggle的手写数字识别挑战,探讨了神经网络的细节,包括增加网络层数、权重初始化问题、简单参数调整的影响以及使用Batch Normalization算法对模型性能的提升。实验结果显示,合理调整网络结构和使用BN算法能显著提高模型准确率。
题目
https://www.kaggle.com/c/digit-recognizer
前言
上一篇写了一些基础的代码,用一个最简单的神经元来写了一个手写数字的识别。在这一篇里,首先扩展了神经网络的深度,并且处理了深度所带来的权重初始化的问题,另外,还尝试用了batch normalization算法进行了优化。
增加网络层数
把网络层数加深并不难,只要处理好输入输出就可以了,这里直接贴个代码好了。这里有两个隐藏层,算是比较少的了,也可以根据情况修改layers,就可以增加层数了。
#self.learning_rate = 0.02 self.batch_size = 50
def hide_layer(self, x, layer_name, var_shape):
n_input = np.prod(var_shape[:-1])
w_initializer = tf.truncated_normal_initializer(mean=0,stddev=1,dtype=tf.float32)
b_initializer = tf.constant_initializer(0.1, dtype=tf.float32)
W = tf.get_variable(layer_name + '_w', var_shape, initializer=w_initializer,dtype=tf.float32, trainable=True)
b = tf.get_variable(layer_name + '_b', [var_shape[-1]],initializer=b_initializer,dtype=tf.float32, trainable=True)
out = tf.matmul(x,W) + b
return tf.nn.elu(out)
def build_model(self):
print 'build_model'
self.x = tf.placeholder(tf.float32,[None, 784])
layer_output = self.x
layers = [784,30,10]
n = len(layers) - 1
for i in range(n):
var_shape = [layers[i], layers[i + 1]]
layer_output = self.hide_layer(layer_output, 'layer_' + str(i), var_shape)
self.y = tf.nn.softmax(layer_output)
self.label = tf.placeholder(tf.float32,[None,10])
self.cross_entropy = -tf.reduce_sum(self.label*tf.log(self.y))
opt = tf.train.GradientDescentOptimizer(learning_rate=self.learning_rate)
self.train_step = opt.minimize(self.cross_entropy)
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
self.sess = tf.Session(config=config)
init = tf.global_variables_initializer()
self.sess.run(init)
self.saver = tf.train.Saver(tf.global_variables())ok,到这里还好,当你把代码跑起来,可能会发现,loss为nan的情况更容易出现了,尤其是多加两层隐藏层会更加明显,训练很难进行下去。遇到这种情况,改小学习率是有效果的,但是过小的学习率无法让模型训练到一个合适的识别率。
权重初始化问题
为什么我们网络在层数较少的时候没问题,层数一增加,就发现loss为0了呢?说到底,还是参数初始化有问题,当我们增加层数的时候,因为参数大部分比较小,那么就会出现越乘输出越小的现象,当输出为0或者无限接近于0的时候(计算机有精度限制),算出的梯度就会变成nan了。因此,我们需要合理地安排变量的初始值,使得开始的时候,神经网络计算的输出不为0。
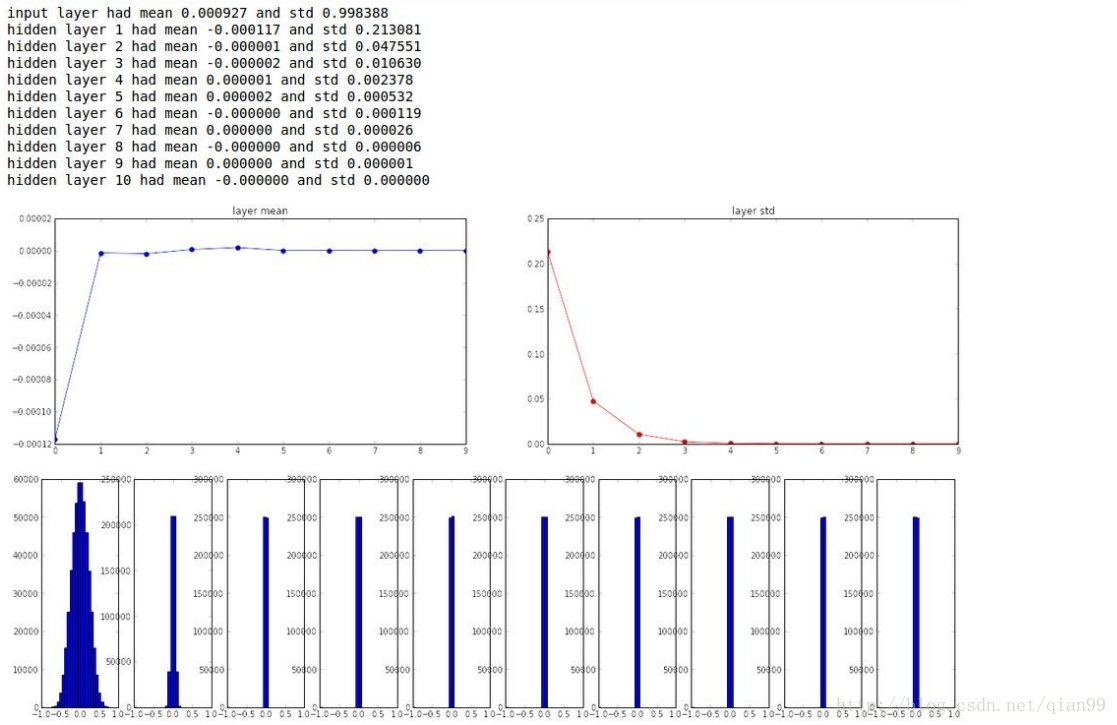
从下面这幅图可以看到,layer1的权重分布是一个标准的正态分布,但是从第3层开始,权重的就几乎都为0了。
怎样初始化可以避免最终的输出都变成这样呢?其实前辈们已经想好了解决方案,在使用sigmoid作为激活函数的时候,可以这样初始化权重:
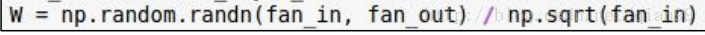
就是初始化的时候还是用一个正态分布,但是每个值都除
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









