










视频拼接融合产品的产品与架构设计一
以上是第一期,以前思考的时候还是比较着急,现在思考的更多了,现实世界的拼接更加需要我们沉下心来做,尤其是对于更多画面,画面更加清晰怎么做
本篇章不在于其他功能,在于说明选型和效率问题
重中之重-选型
使用什么硬件
我来清除地阐述现在所有的硬件平台,绝无虚言,
1 nvidia 英伟达的cuda
英伟达的产品好用,主要在于cuda生态,同时细节处理丰满,运用简单,他的gpu解码器和编码器和tensor core 分别为不同的芯片,可以流水线处理,windows下可以使用dlss 进行超分处理,可以同时使用cuda技术解码和directx 11 技术解码,vulcan技术解码,可以在gpu中直接处理所有算法,而不用下放到cpu,拼接完成,编码完成后发出rtsp流,后面我会证明为什么要使用cuda。
2 amd
amd的显卡解码在windows下可以直接使用directx11,至于其他可以使用opencl 去做,这一部分需要熟悉opencl的kernel,也是可以的,效率会稍稍差一些,如果是没有什么选择,尽量使用nvidia的夏卡
3 intel 显卡
intel的核显很强大,编解码非常厉害,同时intel出的独立显卡也是很好用的,同样可以使用他的独立显卡,如出的arc A750 ,arcA770,都是可用的,图像处理也没有问题,可以选,但是慎重
4 瑞芯微3588
瑞芯微3588 可以用,解码芯片和编码芯片也很突出,有硬件的rga处理
不过技术文档不友好,但是还是可以用,记住流程,使用rga硬件,使用opencl都可以的
5 树莓派
可以硬件解码,图像处理可以使用opencl
6 华为昇腾(Ascend)
暂时对图像处理不友好,可以使用opencv高版本进行处理,npu可以使用
7 其他国产显卡
暂时不要进行研究处理,通用性还没有那么好,等待各个图像处理和AI处理都可以了,再进行下一步
至于国内的显卡,我为什么现在不推荐做,因为现在还不成熟,而对于amd 和 intel 显卡我们要排在英伟达的后面,因为英伟达确实通用性非常强。
以上希望其他研究者,学者与我联系,如果可能,我会尽我所能进行测试分析,或者纠正我说的错误
分布式架构
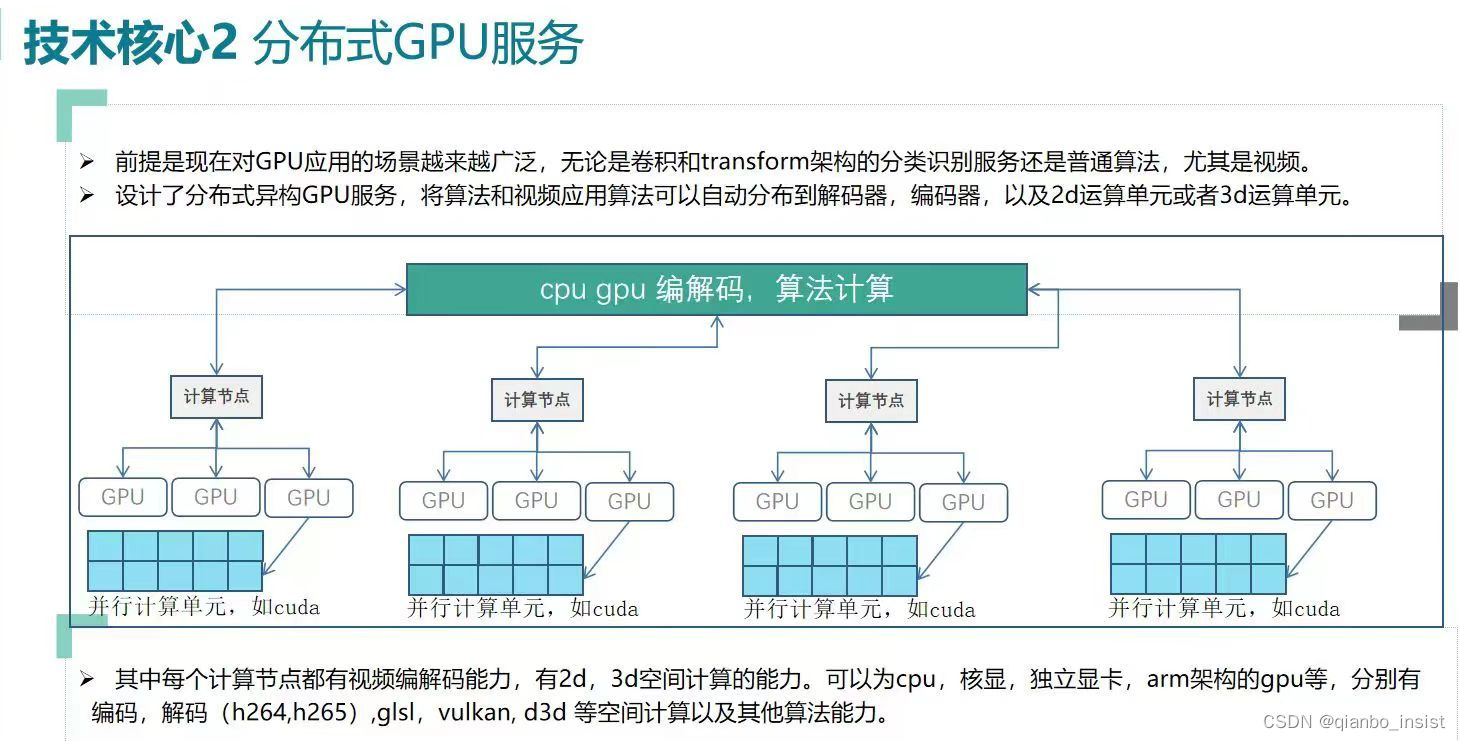
下面我就nvidia显卡进行分析,说明cuda的效率
cuda nv12 和 bgr 互相转化
为什么要使用bgr 和 nv12 的转化?因为我们都知道大名鼎鼎的opencv,处理图像和滤波算法以及AI算法推理,可以使用bgr方式,这样,使用cuda转化,使用bgr 和 rgb方式进行AI算法推理和普通算法处理图像,结束后立即编码,
__global__ void BGR2NV12Kernel(const uchar3* srcBGR, unsigned char* dstY, unsigned char* dstUV, int width, int height, int srcStep, int dstYStep, int dstUVStep) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
int srcIndex = y * srcStep + x ;
int dstYIndex = y * dstYStep + x;
int dstUVIndex = y / 2 * dstUVStep + x;
// BGR to NV12 conversion
uchar3 pixel = srcBGR[srcIndex];
dstY[dstYIndex] = 0.299f * pixel.x + 0.587f * pixel.y + 0.114f * pixel.z; // Y component
//以下为uv分量转化
}
}
结果出来的图像是这样的
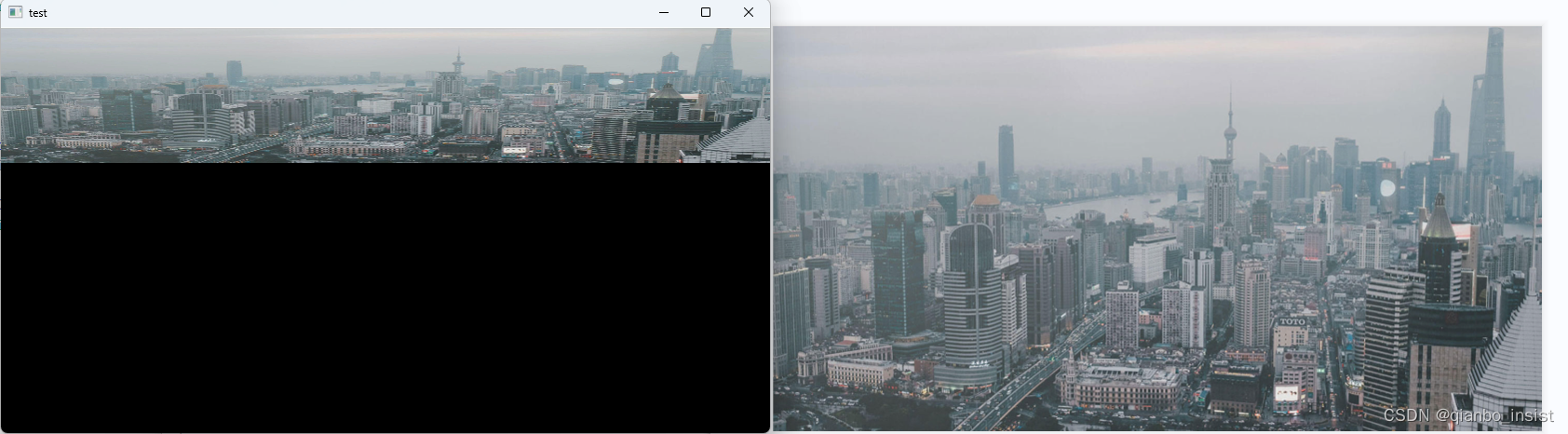
考虑x周横向是3个像素,修改一下
int srcIndex = y * srcStep + x *3;

离目标有点远,仔细分析cuda代码,应该是这样
uchar3* ppixel = (uchar3*)((unsigned char*)srcBGR + y * srcStep) + x;
这下正确了,cuda的好用就在于像素并行操作!
右边是原图,左边是cuda转硬件的bgr 到 nv12,再次使用 nv12 转成bgr ,进行显示,耗费时间,我们加几行代码进行计算
double startTime = cv::getTickCount();
// 在这里执行你需要测量耗时的操作
// 例如,这里模拟一个延时操作
// 记录结束时间
double endTime = cv::getTickCount();
//bgr 转nv12
bgr_to_nv12_cuda(reinterpret_cast<uchar3*>(gpu_input_image.data), frame->data[0],
frame->data[1], w, h, gpu_input_image.step, frame->linesize[0], frame->linesize[1]);
//nv12 转 bgr
nv12_to_rgb24_cuda(frame->data[0], frame->data[1], memory, m1.step, frame->linesize[0], frame->linesize[1], frame->width, frame->height, 3);
// 计算时间差,单位为毫秒
double elapsedTimeMs = (endTime - startTime) / cv::getTickFrequency() * 1000.0;
std::cout << "Elapsed time in milliseconds: " << elapsedTimeMs << std::endl;
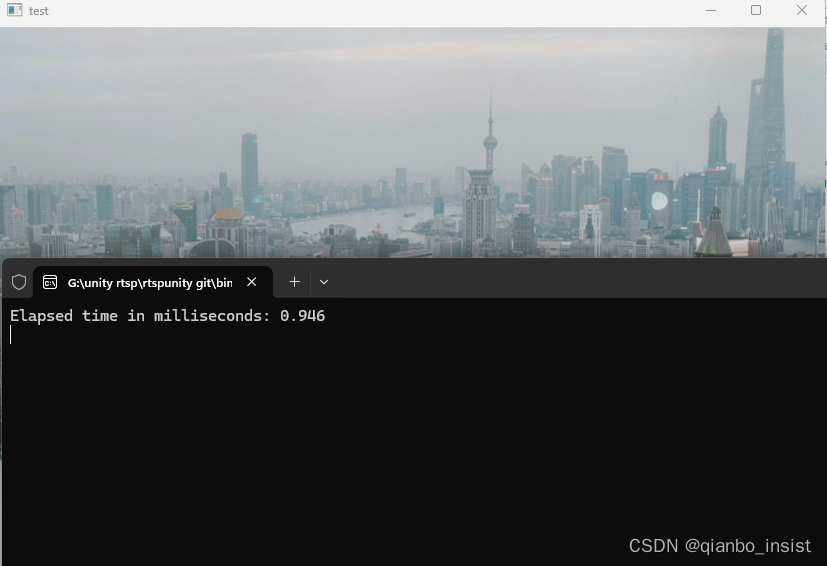
nvidia 1650 显卡,使用cuda ,花费0.946 毫秒,1毫秒不到完成2次转化,图片太小,我们加一个2k的图像进行转化:如下所示
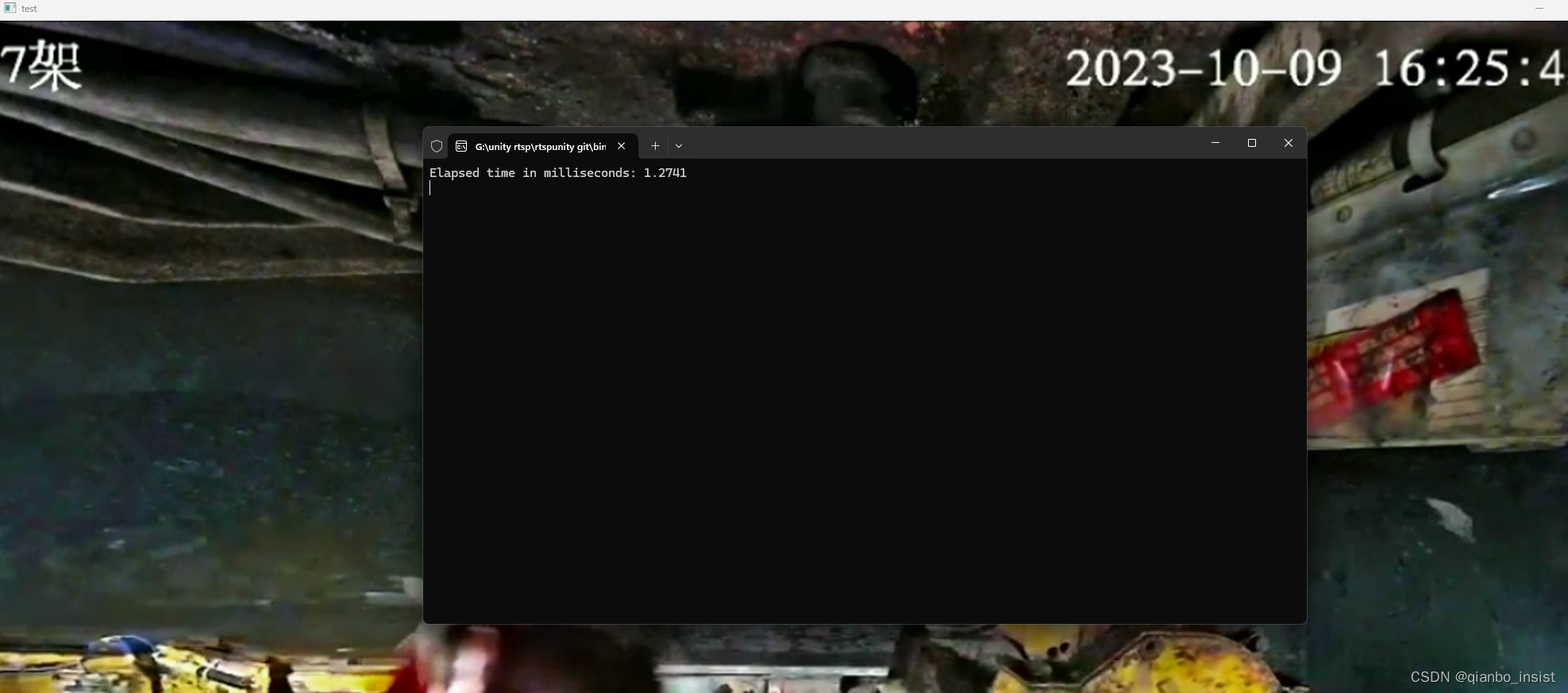
花费1.27 毫秒,性能开始下降,比较危险,看看是否能够提高
线程块修改
dim3 block(16, 16);
dim3 block(32, 32);
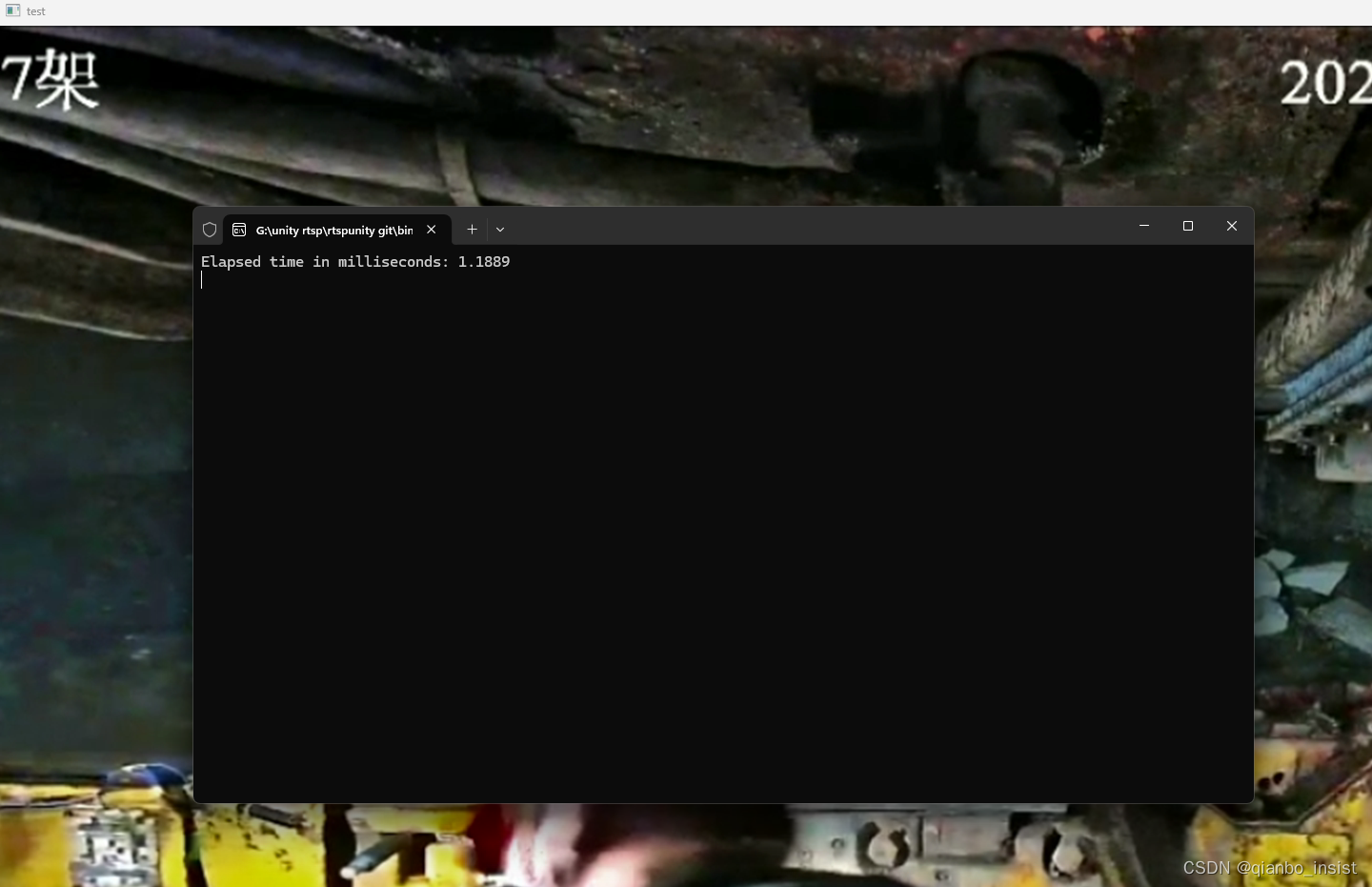
基本上提高了一点,不大,4k画面估计要到2-3毫秒,我们再次测试一下
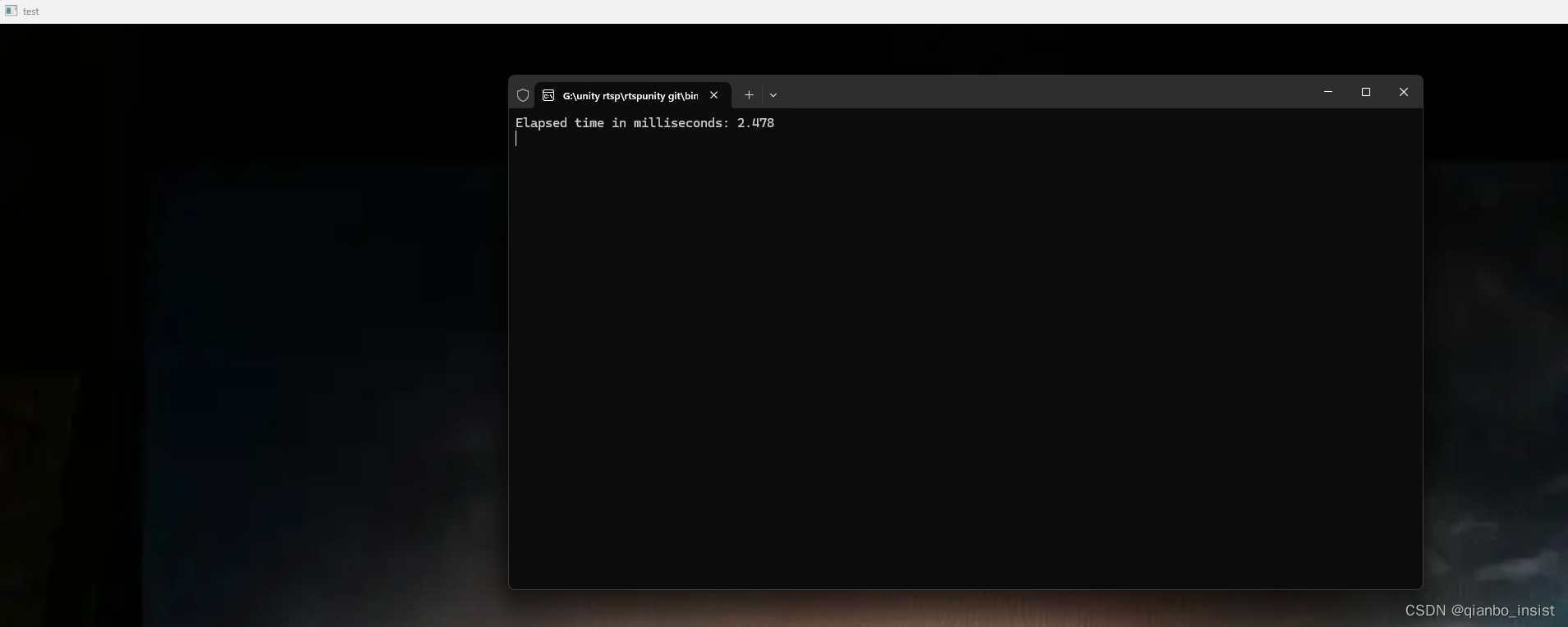
果然到了2.478 毫秒,这个时间有些超量,希望可以优化到1毫秒多。
对于一秒钟视频25帧画面来说,4k画面需要2.5 * 25 = 62.5 毫秒,说实话有点多了。
如果我们使用ffmpeg cpu swscale, 后果不堪设想。
总结
总之效率是最重要的,还有一点一直是我所思考的,如果死磕gpu,那么cpu 会浪费,所以对gpu 和 cpu 除了要分布式处理,还要进行分担,所以我决定从多点出发,需要进行cpu 前处理插件点,gpu处理插件点,gpu下拉后插件点 ,利用cpu 多核处理能力,同时分担gpu的任务。
未完,待续。。。。。。。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











