






咱们聊聊大型语言模型(LLMs)的训练范式吧,这可是个大话题。从最早的GPT模型到现在的复杂开放权重LLMs,这一路走来,变化可真不少。记得最开始,LLMs的训练就只关注预训练,但现在,这事儿已经发展到包括预训练和后训练两个阶段了。后训练阶段,通常就是监督指令微调和对齐。

就拿谷歌的Gemma模型来说吧,最近在一篇文章里头详细描述了。这篇文章叫《Gemma 2: Improving Open Language Models at a Practical Size》(https://arxiv.org/abs/2408.00118),挺有意思的。
Gemma 2模型有三种不同的规模,分别是20亿、90亿和270亿参数。这模型的亮点在于,它不是一味追求增加训练数据集的规模,而是更注重开发那些既小又高效的LLMs。
还有一点特别值得一提,那就是Gemma 2的词汇量超级大,有256k个标记(tokens)。相比之下,Llama 2的词汇表只有32k个标记,Llama 3也不过是128k个标记。
最后,Gemma 2还用了滑动窗口注意力机制,这跟Mistral早期的模型有点像,可能是为了减少内存的使用成本。
3.2 Gemma 2 预训练
咱们再聊聊Gemma 2的预训练部分。Gemma的研究人员发现,即使是小型模型,通常也是训练不足的。他们没有选择简单地增加训练数据集的规模,而是更注重保持训练的质量,并通过一些替代方法来实现改进,比如知识蒸馏,这跟苹果的AFM方法有点像,具体请参见《Apple LLM: 智能基础语言模型(AFM)》。
说到27B的Gemma 2模型,它是从头开始训练的。但是,那些更小的模型,比如2B和9B的,就用了知识蒸馏的方式来训练,这跟我们之前提到的苹果的方法差不多。
训练数据的规模也很有意思,27B模型训练了13万亿个标记,9B模型训练了8万亿个标记,而2B模型则训练了2万亿个标记。而且,跟苹果的方法一样,Gemma团队也优化了数据混合,这也是为了提高模型的性能。这一系列的操作,都是为了确保模型能够学得更好,表现得更出色。
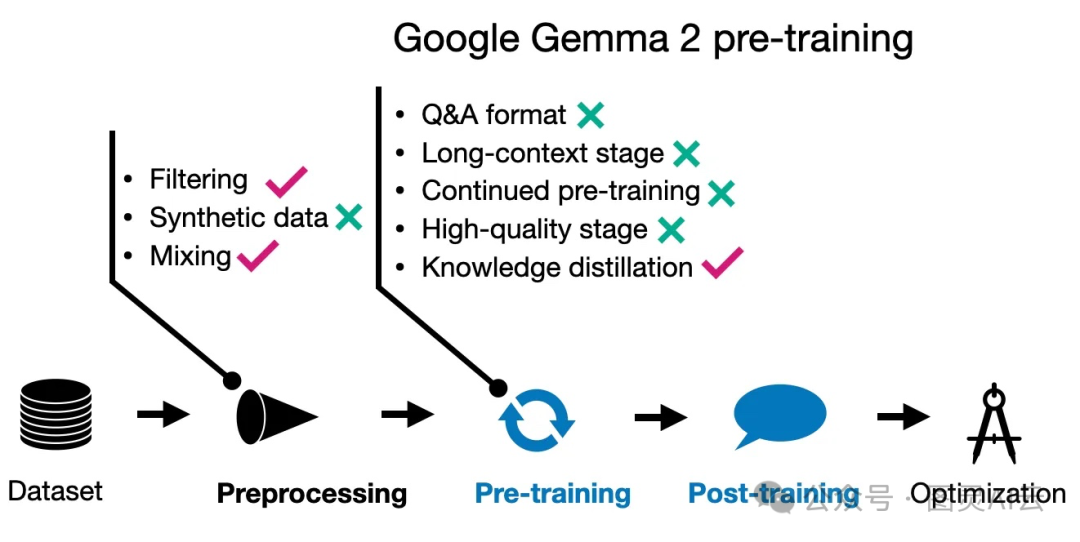
Gemma 2 预训练的技术总览
3.3 Gemma 2 后训练
咱们再来看看Gemma模型的后训练过程。这里面包括了两个典型的步骤:监督微调(SFT)和人类反馈的强化学习(RLHF),具体可见《您真的了解人类反馈强化学习(RLHF)吗?》。
在监督微调阶段,Gemma模型用的是纯英文的指令数据,这些数据是人工生成和机器生成的内容混合在一起的。特别有意思的是,这些响应大多数是由一个教师模型生成的,而且在SFT阶段也用到了知识蒸馏。
至于强化学习部分,Gemma的RLHF方法有个特别的地方:在SFT之后,用来做RLHF的奖励模型的规模,是策略(目标)模型的十倍大。这个比例挺有意思的。
他们用的RLHF算法本身是比较标准的,但是有一个独特的创新点:他们通过一个叫做WARP(Weighted Average Reward Model with Perturbations)的方法来平均策略模型。WARP其实是WARM(Weighted Average Reward Model,加权平均奖励模型)的升级版。
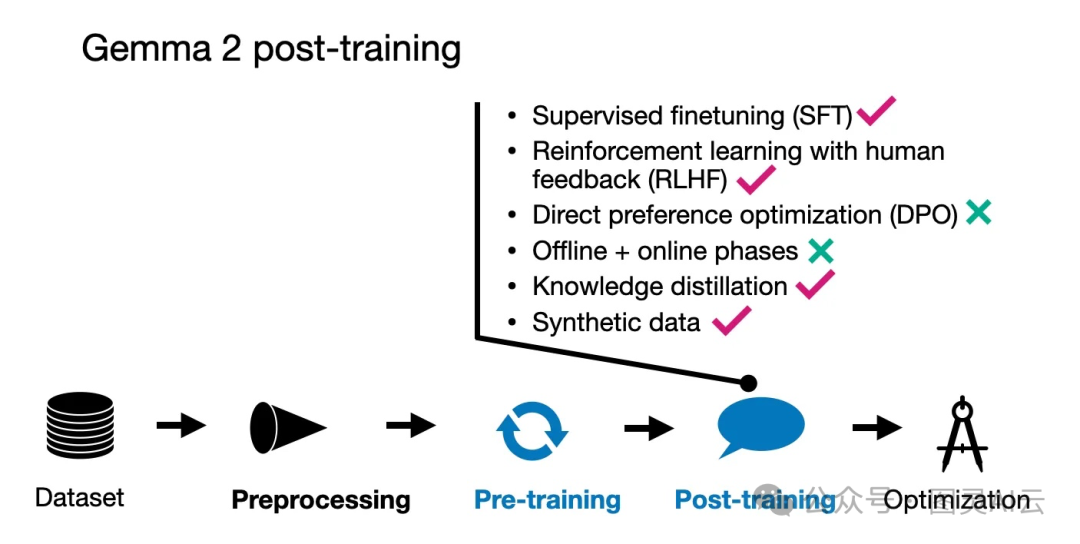
Gemma 2 后训练的技术总览
总的来说,Gemma模型的后训练过程,通过结合监督微调和人类反馈的强化学习,再加上一些独特的技术和方法,使得模型在理解和生成文本方面表现得更加出色。这一系列的训练步骤,都是为了确保模型能够更好地理解和回应用户的指令。
3.4 结论
总结一下,Gemma团队在他们的模型训练中,确实把知识蒸馏这个方法用到了极致。无论是在预训练阶段还是后训练阶段,他们都采用了这种方法,这跟苹果的做法有点像。
有意思的是,他们并没有采用那种多阶段的预训练方法,或者至少在他们的论文里,并没有详细地说明这一点。这可能意味着他们在训练模型的时候,有自己独特的思路和方法。
通过这样的训练策略,Gemma模型在理解和生成文本方面,可能会有不错的表现。这也让我们对Gemma模型的未来充满了期待。毕竟,一个好的语言模型,能够更好地理解和回应用户的需求,这对于提升用户体验来说,是非常重要的。
















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









