








论文地址:https://arxiv.org/abs/2203.15712
论文代码:https://github.com/dahyun-kang/ifsl
目录
Abstract
We introduce the integrative task of few-shot classification and segmentation (FS-CS) that aims to both classify and segment target objects in a query image when the target classes are given with a few examples. This task combines two conventional few-shot learning problems, few-shot classification and segmentation. FS-CS generalizes them to more realistic episodes with arbitrary image pairs, where each target class may or may not be present in the query. To address the task, we propose the integrative few-shot learning (iFSL) framework for FS-CS, which trains a learner to construct class-wise foreground maps for multi-label classification and pixel-wise segmentation. We also develop an effective iFSL model, attentive squeeze network (ASNet), that leverages deep semantic correlation and
global self-attention to produce reliable foreground maps. In experiments, the proposed method shows promising performance on the FS-CS task and also achieves the state of the art on standard few-shot segmentation benchmarks.
我们介绍了小样本分类和分割(FS-CS)的集成任务,目的是在目标类给出的例子很少的情况下,对查询图像中的目标对象进行分类和分割。该任务结合了两个传统的小样本学习问题,小样本分类和分割。FS-CS将它们推广到具有任意图像对的更真实的任务中,其中每个目标类可能出现在查询图像中,也可能不出现在查询图像中。为了解决这一任务,我们提出了FS-CS的综合小样本学习(iFSL)框架,该框架训练学习器构建用于多标签分类和像素分割的分类前景图。我们还开发了一个有效的iFSL模型——注意力挤压网络(ASNet),利用深度语义相关性和全局自注意来生成可靠的前景图。在实验中,所提出的方法在FS-CS任务上表现出良好的性能,并且在标准的小样本分割基准上也达到了最先进的水平。
1. Introduction
Few-shot learning [15,16,30,82,84] is the learning problem where a learner experiences only a limited number of examples as supervision. In computer vision, it has been most actively studied for the tasks of image classification [22, 29, 66] and semantic segmentation [6, 41, 48, 59]among many others [21,49,54,94,99]. Few-shot classification (FS-C) aims to classify a query image into target classes when a few support examples are given for each target class. Few-shot segmentation (FS-S) is to segment out the target class regions on the query image in a similar setup. While being closely related to each other [33, 92, 100], these two few-shot learning problems have so far been treated individually. Furthermore, the conventional setups for the few-shot problems, FS-C and FS-S, are limited and do not reflect realistic scenarios; FS-C [28, 55, 76] presumes that the query always contains one of the target classes in classification, while FS-S [25,52,63] allows the presence of multiple classes but does not handle the absence of the target classes in segmentation. These respective limitations prevent few-shot learning from generalizing to and evaluating on more realistic cases in the wild. For example, when a query image without any target class is given as in Fig. 1, FS-S learners typically segment out arbitrary salient objects in the query.
小样本学习[15,16,30,82,84]是学习器只使用有限数量的例子作为监督的学习问题。在计算机视觉中,对图像分类[22,29,66]和语义分割[6,41,48,59]等任务的研究最为活跃[21,49,54,94,99]。小样本分类(FS-C)的目的是在为每个目标类提供一些支持示例时,将查询图像分类为目标类。小样本分割(FS-S)是在类似的设置中分割出查询图像上的目标类区域。虽然这两个小样本学习问题彼此密切相关[33,92,100],但迄今为止都是单独处理的。此外,用于小样本分类FS-C和小样本分割FS-S的常规设置是有限的,不能反映现实情况,FS-C[28,55,76]假设查询图像中总是包含分类中的一个目标类,而FS-S[25,52,63]允许存在多个目标类,但不处理分割中目标类的缺失。这些各自的局限性阻碍了小样本学习在更现实的情况下进行推广和评估。例如,如图1所示,当给出一个不含任何目标类的查询图像时,FS-S学习器通常会在查询图像中分割出任意显著对象。
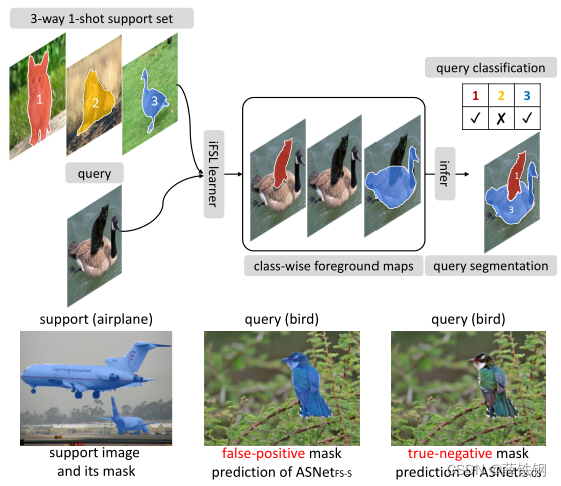
Figure 1. Top: Integrative few-shot learning framework (iFSL) for integrative few-shot classification and segmentation (FS-CS).
Bottom: FS-S learners are trained to segment a query image using a semantically-coupled support set thus often blindly highlight any salient objects regardless of support semantics. The proposed FS-CS learners are trained to predict class presence as well as corresponding masks thus correctly discriminate what to segment basedon the semantic relevance between the query and the support.
图1。上图:用于综合小样本分类和分割(FS-CS)的综合小样本学习框架(iFSL)。
下图:FS-S学习器使用语义耦合的支持集分割查询图像,因此不考虑支持语义如何,总是会盲目地突出任何显著对象。本文所提出的FS-CS学习器能够在训练后预测类的存在以及相应的掩码,从而根据查询图像和支持图像之间的语义相关性正确区分要分割的内容。
To address the aforementioned issues, we introduce the integrative task of few-shot classification and segmentation (FS-CS) that combines the two few-shot learning problems into a multi-label and background-aware prediction problem. Given a query image and a few-shot support set for target classes, FS-CS aims to identify the presence of each target class and predict its foreground mask from the query. Unlike FS-C and FS-S, it does not presume either the class exclusiveness in classification or the presence of all the target classes in segmentation.
为了解决上述问题,我们引入了小样本分类和分割的集成任务(FS-CS),它将两个小样本学习问题结合成一个多标签和背景感知的预测问题。给定一个查询图像和目标类的几个样本支持集,FS-CS旨在识别每个目标类的存在,并从查询图像中预测其前景掩码。与FS-C和FS-S不同,FS-CS既不假定分类问题中的类排他性(各个类不允许存在包含关系),也不假定分割问题中所有目标类都存在。
As a learning framework for FS-CS, we propose integrative few-shot learning (iFSL) that learns to construct shared foreground maps for both classification and segmentation. It naturally combines multi-label classification and pixel-wise segmentation by sharing class-wise foreground maps and also allows to learn with class tags or segmentation annotations. For effective iFSL, we design the attentive squeeze network (ASNet) that computes semantic correlation tensors between the query and the support image features and then transforms the tensor into a foreground map by strided self-attention. It generates reliable foreground maps for iFSL by leveraging multi-layer neural features [44, 45] and global self-attention [11, 75]. In experiments, we demonstrate the efficacy of the iFSL framework on FS-CS and compare ASNet with recent methods [44, 86–88]. Our method significantly improves over the other methods on FS-CS in terms of classification and segmentation accuracy and also outperforms the recent FS-S methods on the conventional FS-S. We also cross-validate the task transferability between the FS-C, FS-S, and FS-CS learners, and show the FS-CS learners effectively generalize when transferred to the FS-C and FS-S tasks.
Our contribution is summarized as follows:
作为FS-CS的学习框架,我们提出了集成小样本学习框架(iFSL),学习构建用于分类和分割的共享前景图。iFSL通过共享类前景图自然地结合了多标签分类和像素级别的分割问题,而且允许使用类标签或分割标签进行学习。为了实现有效的iFSL,我们设计了注意力挤压网络(ASNet),该网络计算查询和支持图像特征之间的语义相关张量,然后通过跨步自注意力机制将其转换为前景图。利用多层神经特征[44,45]和全局自注意[11,75]为iFSL生成可靠的前景图。在实验中,我们证明了iFSL框架在FS-CS上的有效性,并将ASNet与最近的方法进行了比较[44,86-88]。我们的方法在分类和分割精度方面相比于FS-CS上的其他方法有了显著的提高,在传统FS-S上也优于最近的FS-S方法。我们还交叉验证了FS-C、FS-S和FS-CS学习器之间的任务可迁移性,并表明FS-CS学习器在转移到FS-C和FS-S任务时能够做到有效地泛化。
我们的贡献概述如下:
• We introduce the task of integrative few-shot classification and segmentation (FS-CS), which combines few-shot classification and few-shot segmentation into an integrative task by addressing their limitations.
本文提出了集成小样本分类与分割任务(FS-CS),该任务针对小样本分类与分割的局限性,将两者融合为一个集成任务。
• We propose the integrative few-shot learning framework (iFSL), which learns to both classify and segment a query image using class-wise foreground maps.
我们提出了集成小样本学习框架( iFSL ),该框架学习使用类前景图对查询图像进行分类和分割。
• We design the attentive squeeze network (ASNet), which squeezes semantic correlations into a foreground map for iFSL via strided global self-attention.
我们设计了注意力挤压网络( ASNet ),通过跨步全局自注意力机制将语义相关性挤压到iFSL的前景图中。
• We show in extensive experiments that the framework, iFSL, and the architecture, ASNet, are both effective, achieving a significant gain on FS-S as well as FS-CS.
我们在大量的实验中表明,iFSL框架和ASNet架构都是有效的,二者在FS-S和FS-CS上都取得了显著的增益。
2. Related work
Few-shot classification (FS-C). Recent FS-C methods typically learn neural networks that maximize positive class similarity and suppress the rest to predict the most probable class. Such a similarity function is obtained by a) meta-learning embedding functions [1,23,26,28,51,67,76,93,96], b) meta-learning to optimize classifier weights [17, 61, 69], or c) transfer learning [7,9,20,37,50,58,71,81], all of which aim to generalize to unseen classes. This conventional formulation is applicable if a query image corresponds to no less or more than a single class among target classes. To generalize FS-C to classify images associated with either none or multiple classes, we employ the multi-label classification [4, 8, 12, 31, 42]. While the conventional FS-C methods make use of the class uniqueness property via using the categorical cross-entropy, we instead devise a learning framework that compares the binary relationship between the query and each support image individually and estimates a binary presence of the corresponding class.
小样本分类(FS-C)。 最近的FS-C方法使用的神经网络通常是通过学习最大化正类相似度,并抑制其余的类别来预测最可能的类。这样的相似函数是通过以下方法获得的:
a)元学习嵌入函数[1,23,26,28,51,67,76,93,96],
b)优化分类器权重的元学习[17,61,69],
c)迁移学习[7,9,20,37,50,58,71,81],
所有这些方法都旨在泛化到未学习到的类。如果查询图像对应的目标类大于等于一个类,则适用此常规公式。为了将FS-C推广到能够分类无类或多类的图像,我们采用了多标签分类[4,8,12,31,42]。传统的FS-C方法通过使用分类交叉熵来利用类的唯一性,而我们则设计了一个学习框架,对查询图像和每个支持图像之间的二元关系进行单独比较,并估计相应类别的二元存在。
Few-shot semantic segmentation (FS-S). A prevalent FS-S approach is learning to match a query feature map with a set of support feature embeddings that are obtained by collapsing spatial dimensions at the cost of spatial structures [10, 18, 38, 40, 47, 65, 78, 89, 90, 95, 98]. Recent methods [73, 86–88, 97] focus on learning structural details by leveraging dense feature correlation tensors between the query and each support. HSNet [44] learns to squeeze a dense feature correlation tensor and transform it to a segmentation mask via high-dimensional convolutions that analyze the local correlation patterns on the correlation pyramid. We inherit the idea of learning to squeeze correlations and improve it by analyzing the spatial context of the correlation with effective global self-attention [75]. Note that several methods [68, 77, 91] adopt non-local self-attention [80] of the query-key-value interaction for FS-S, but they are distinct from ours in the sense that they learn to transform image feature maps, whereas our method focuses on transforming dense correlation maps via self-attention.
小样本语义分割(FS-S)。 一种流行的FS-S方法是学习将查询特征图与一组支持特征嵌入进行匹配,这些支持特征嵌入是以空间结构为代价,通过折叠空间维度获得的[10,18,38,40,47,65,78,89,90,95,98]。最近的方法[73,86-88,97]侧重于利用查询和每个支持之间的密集特征关联张量来学习结构细节。HSNet[44]通过分析相关金字塔上的局部相关模式,学习挤压密集特征关联张量,并通过高维卷积将其转换为分割掩膜。我们继承了学习挤压相关性的思想,并通过分析具有全局自注意力机制的空间上下文的相关性来改进它[75]。值得注意的是,一些方法[68,77,91]采用了FS-S中查询键值交互的非局部自注意力[80],但它们与我们的方法不同,它们学习转换图像特征映射,而我们的方法侧重于通过自注意转换密集关联映射。
FS-S has been predominantly investigated as an one-way segmentation task, i.e., foreground or background segmentation, since the task is defined so that every target (support) class object appears in query images, thus being not straightforward to extend to a multi-class problem in the wild. Consequently, most work on FS-S except for a few [10, 40, 70, 78] focuses on the one-way segmentation, where the work of [10,70] among the few presents two-way segmentation results from person-and-object images only, e.g., images containing (person, dog) or (person, table).
FS - S主要作为一种单向的分割任务进行研究,即前景或背景分割,因为该任务的定义使得每个目标(支持)类对象都出现在查询图像中,所以不能直接扩展到多类问题。因此,除了少数几个[ 10,40,70,78]外,大多数FS-S的工作都集中在单向分割上,其中[10,70]只对人与物图像进行双向分割,例如,包含(人、狗)或(人、桌)的图像。
Comparison with other few-shot approaches. Here we contrast FS-CS with other loosely-related work for generalized few-shot learning. Few-shot open-set classification [39] brings the idea of the open-set problem [14, 62] to few-shot classification by allowing a query to have no target classes. This formulation enables background-aware classification as in FS-CS, whereas multi-label classification is not considered. The work of [19, 72] generalizes few-shot segmentation to a multi-class task, but it is mainly studied under the umbrella of incremental learning [5, 43, 56]. The work of [64] investigates weakly-supervised few-shot segmentation using image-level vision and language supervision, while FS-CS uses visual supervision only. The aforementioned tasks generalize few-shot learning but differ from FS-CS in the sense that FS-CS integrates two related problems under more general and relaxed constraints.
与其他小样本方法的比较。 这里,我们将FS-CS与其他用于广义少小样本学习的松相关工作进行了比较。[39]通过允许查询图像没有目标类,将开集问题[14,62]的思想引入到小样本分类中。该公式支持FS-CS中的背景感知分类,而不考虑多标签分类。[19,72]的工作将小样本分割推广到多类任务,但主要是在增量学习的框架下进行研究[5,43,56]。[64]的工作研究了使用图像级视觉和语言监督的弱监督小样本分割,而FS-CS仅使用视觉监督。上述任务推广了小样本学习,但与FS-CS不同的是,FS-CS在更一般和更宽松的约束下集成了两个相关问题。
3. Problem formulation
Given a query image and a few support images for target classes, we aim to identify the presence of each class and predict its foreground mask from the query (Fig. 1), which we call the integrative few-shot classification and segmentation (FS-CS). Specifically, let us assume a target (support) class set C s C_{s} Cs of N N N classes and its support set S = { ( x s ( i ) , y s ( i ) ) ∣ y s ( i ) ∈ C s } i = 1 N K S = \{ (x^{(i)}_{s} , y^{(i)}_{s})|y^{(i)}_{s} \in C_{s} \}^{N K}_{i=1} S={(xs(i),ys(i))∣ys(i)∈Cs}i=1NK , which contains K labeled instances for each of the N classes, i.e., N-way K-shot [55, 76]. The label y s ( i ) y^{(i)}_{s} ys(i) is either a class tag (weak label) or a segmentation annotation (strong label). For a given query image x x x, we aim to identify the multi-hot class occurrence y C y_{C} yC and also predict the segmentation mask Y S Y_{S} YS corresponding to the classes. We assume the class set of the query C C C is a subset of the target class set, i.e., C ⊆ C s C \subseteq C_{s} C⊆Cs, thus it is also possible to obtain y C = ∅ y_{C} = \emptyset yC=∅ and Y S = ∅ Y_{S} = \emptyset YS=∅. This naturally generalizes the existing few-shot classification [67,76] and few-shot segmentation [52, 63].
给定一个查询图像和一些目标类的支持图像,我们旨在从查询图像中识别每个类的存在并预测其前景掩码(图1),我们称之为集成小样本分类和分割(FS-CS)。具体来说,我们假设有一个 N N N个类的目标(支持)类集 C s C_{s} Cs,它的支持集 S = { ( x s ( i ) , y s ( i ) ) ∣ y s ( i ) ∈ C s } i = 1 N K S = \{ (x^{(i)}_{s} , y^{(i)}_{s})|y^{(i)}_{s} \in C_{s} \}^{N K}_{i=1} S={(xs(i),ys(i))∣ys(i)∈Cs}i=1NK,其中包含 N N N个类中每个类的 K K K个标记实例,即N-way K-shot[55,76]。标签 y s ( i ) y^{(i)}_{s} ys(i)可以是类标签(弱标签),也可以是分割标签(强标签)。对于给定的查询图像 x x x,我们的目标是识别multi-hot 编码的类别出现向量 y C y_{C} yC,并预测该类对应的分割掩码 Y S Y_{S} YS。假设查询类集 C C C是目标类集的子集,即 C ⊆ C s C \subseteq C_{s} C⊆Cs,因此也有可能得到 y C = ∅ y_{C} = \emptyset yC=∅, Y S = ∅ Y_{S} = \emptyset YS=∅。这自然推广了现有的小样本分类[67,76]和小样本分割[52,63]。
Multi-label background-aware prediction. The conventional formulation of few-shot classification (FS-C) [17,67,76] assigns the query to one class among the target classes exclusively and ignores the possibility of the query belonging to none or multiple target classes. FS-CS tackle this limitation and generalizes FS-C to multi-label classification with a background class. A multi-label few-shot classification learner f C f_{C} fC compares semantic similarities between the query and the support images and estimates class-wise occurrences: y C ^ = f C ( x , S ; θ ) \hat{y_{C}} = f_{C}(x, S; \theta) yC^=fC(x,S;θ) where y C ^ \hat{y_{C}} yC^ is an N-dimensional multi-hot vector each entry of which indicates the occurrence of the corresponding target class. Note that the query is classified into a background class if none of the target classes were detected. Thanks to the relaxed constraint on the query, i.e., the query not always belonging to exactly one class, FS-CS is more general than FS-C.
多标签背景感知预测。 传统的小样本分类(FS-C)[17,67,76]将查询图像专门分配给目标类中的一个类,忽略了查询图像属于无目标类或多个目标类的可能性。FS-CS解决了这一限制,并将FS-C推广到带有背景类的多标签分类。多标签小样本分类学习器 f C f_{C} fC比较了查询图像和支持图像之间的语义相似性,并估计按类出现的情况: y C ^ = f C ( x , S ; θ ) \hat{y_{C}} = f_{C}(x, S; \theta) yC^=fC(x,S;θ),其中 y C ^ \hat{y_{C}} yC^是一个 N N N维的multi-hot向量,其中的每一项都表示对应目标类是否出现在查询图像中。值得注意的是,如果没有检测到目标类,则将查询图像分类到背景类。由于FS-CS放松了对查询图像的约束,即查询图像不总是属于同一个类,因此FS-CS比FS-C更具有一般性。
Integration of classification and segmentation. FS-CS integrates multi-label few-shot classification with semantic segmentation by adopting pixel-level spatial reasoning. While the conventional FS-S [47,52,63,65,78] assumes the query class set exactly matches the support class set, i.e., C = C s C=C_{s} C=Cs, FS-CS relaxes the assumption such that the query class set can be a subset of the support class set, i.e., C ⊆ C s C \subseteq C_{s} C⊆Cs. In this generalized segmentation setup along with classification, an integrative FS-CS learner f f f estimates both class-wise occurrences and their semantic segmentation maps: { y C ^ , Y S ^ } = f ( x , S ; θ ) \{ \hat{y_{C}}, \hat{Y_{S}} \} = f(x, S; \theta) {yC^,YS^}=f(x,S;θ). This combined and generalized formulation gives a high degree of freedom to both of the few-shot learning tasks, which has been missing in the literature; the integrative few-shot learner can predict multi-label background-aware class occurrences and segmentation maps simultaneously under a relaxed constraint on the few-shot episodes.
分类和分割的集成。 FS-CS采用像素级空间推理,将多标记小样本分类与语义分割相结合。虽然传统的FS-S[47,52,63,65,78]假设查询类集与支持类集完全匹配,即 C = C s C=C_{s} C=Cs,但FS-CS放宽了这个假设,使得查询类集可以是支持类集的子集,即 C ⊆ C s C \subseteq C_{s} C⊆Cs。在这种广义的分类分割设置中,一个集成的FS-CS学习器 f f f同时预测了类别及其语义分割映射: { y C ^ , Y S ^ } = f ( x , S ; θ ) \{ \hat{y_{C}}, \hat{Y_{S}} \} = f(x, S; \theta) {yC^,YS^}=f(x,S;θ)。这种组合和一般化的公式给了两个小样本学习任务高度的自由度,这在文献中是缺失的;集成的少样本学习器可以在放松对少样本片段的约束下,同时预测多标签背景感知类的出现和分割映射。
4. Integrative Few-Shot Learning (iFSL)
To solve the FS-CS problem, we propose an effective learning framework, integrative few-shot learning (iFSL). The iFSL framework is designed to jointly solve few-shot classification and few-shot segmentation using either a class tag or a segmentation supervision. The integrative few-shot learner f f f takes as input the query image x x x and the support set S S S and then produces as output the class-wise foreground maps. The set of class-wise foreground maps y y y is comprised of Y ( n ) ∈ R H × W Y(n) \in \mathbb{R}^{H×W} Y(n)∈RH×W for N N N classes:
y = f ( x , S ; θ ) = { Y ( n ) } n = 1 N (1) y = f(x, S; \theta) = \{Y(n)\} ^{N}_{n=1} \tag{1} y=f(x,S;θ)={Y(n)}n=1N(1)
为了解决FS-CS问题,我们提出了一种有效的学习框架——小样本集成学习框架(iFSL)。iFSL框架旨在使用类标签或分割监督来共同解决少样本分类和少样本分割。集成少样本学习器
f
f
f将查询图像
x
x
x和支持集
S
S
S作为输入,然后生成类前景映射作为输出。对于
N
N
N个类,类前景映射集合
y
y
y由
Y
(
n
)
∈
R
H
×
W
Y(n) \in \mathbb{R}^{H×W}
Y(n)∈RH×W组成:
y
=
f
(
x
,
S
;
θ
)
=
{
Y
(
n
)
}
n
=
1
N
(1)
y = f(x, S; \theta) = \{Y(n)\} ^{N}_{n=1} \tag{1}
y=f(x,S;θ)={Y(n)}n=1N(1)
where H × W H × W H×W denotes the size of each map and θ \theta θ is parameters to be meta-learned. The output at each position on the map represents the probability of the position being on a foreground region of the corresponding class.
其中 H × W H × W H×W表示每个map的大小, θ \theta θ是要学习的参数。map上每个位置的输出表示该位置处于对应类别前景区域的概率。
Inference. iFSL infers both class-wise occurrences and segmentation masks on top of the set of foreground maps Y Y Y. For class-wise occurrences, a multi-hot vector y C ^ ∈ R N \hat{y_{C}} \in \mathbb{R}^{N} yC^∈RN is predicted via max pooling followed by thresholding:
y C ^ ( n ) = { 1 i f m a x p ∈ [ H ] × [ W ] Y ( n ) ( p ) ≥ δ 0 o t h e r w i s e (2) \hat{y_{C}} ^{(n)} = \begin{cases} 1 & if max_{p \in [H] × [W]} Y^{(n)}(p)\geq\delta\\ 0 & otherwise \\ \end{cases} \tag{2} yC^(n)={10ifmaxp∈[H]×[W]Y(n)(p)≥δotherwise(2)
推理。 iFSL在前景映射集合
y
y
y上推理出类别出现和分割掩码。对于类别出现,通过最大池化和阈值化来预测multi-hot类别出现向量
y
C
^
∈
R
N
\hat{y_{C}} \in \mathbb{R}^{N}
yC^∈RN:
y
C
^
(
n
)
=
{
1
i
f
m
a
x
p
∈
[
H
]
×
[
W
]
Y
(
n
)
(
p
)
≥
δ
0
o
t
h
e
r
w
i
s
e
(2)
\hat{y_{C}} ^{(n)} = \begin{cases} 1 & if \quad max_{p \in [H] × [W]} Y^{(n)}(p)\geq\delta\\ 0 & otherwise \\ \end{cases} \tag{2}
yC^(n)={10ifmaxp∈[H]×[W]Y(n)(p)≥δotherwise(2)
where p p p denotes a 2D position, δ \delta δ is a threshold, and [ k ] [k] [k] denotes a set of integers from 1 to k, i.e., [ k ] = 1 , 2 , ⋅ ⋅ ⋅ , k [k] = {1,2,· · · ,k} [k]=1,2,⋅⋅⋅,k. We find that inference with average pooling is prone to miss small objects in multi-label classification and thus choose to use max pooling. The detected class at any position on the spatial map signifies the presence of the class.
其中 p p p表示二维坐标, δ \delta δ是阈值, [ k ] [k] [k] 表示1到k的整数集合,即 [ k ] = 1 , 2 , ⋅ ⋅ ⋅ , k [k] = {1,2,· · · ,k} [k]=1,2,⋅⋅⋅,k。我们发现,在多标签分类中,使用平均池化的推理容易漏掉小对象,因此选择使用最大池化。在空间映射的任何位置检测到的类都表示该类的存在。
For segmentation, a segmentation probability tensor Y S ∈ R H × W × ( N + 1 ) Y_{S} \in \mathbb{R}^{H×W×(N+1)} YS∈RH×W×(N+1) is derived from the class-wise foreground maps. As the background class is not given as a separate support, we estimate the background map in the context of the given supports; we combine N class-wise background maps into an episodic background map on the fly. Specifically, we compute the episodic background map Y b g Y_{bg} Ybg by averaging the probability maps of not being foreground and then concatenate it with the class-wise foreground maps to obtain a segmentation probability tensor Y S Y_{S} YS:
Y b g = 1 N ∑ n = 1 N ( 1 − Y ( n ) ) (3) Y_{bg} = \frac{1}{N} \sum_{n=1}^N (1-Y^{(n)}) \tag{3} Ybg=N1n=1∑N(1−Y(n))(3)
Y S = [ Y ] [ Y b g ] ∈ R H × W × ( N + 1 ) (4) Y_{S} = [Y][Y_{bg}]\in \mathbb{R}^{H×W×(N+1)} \tag{4} YS=[Y][Ybg]∈RH×W×(N+1)(4)
对于语义分割,从类前景映射中推导出分割概率张量
Y
S
∈
R
H
×
W
×
(
N
+
1
)
Y_{S} \in \mathbb{R}^{H×W×(N+1)}
YS∈RH×W×(N+1)。由于背景类不是作为一个单独的支持,我们在给定支持的上下文中估计背景映射;我们动态地将N个类背景映射组合成一个情景背景映射。具体来说,我们通过计算不属于前景的概率的平均值来计算情景背景映射
Y
b
g
Y_{bg}
Ybg,然后将其与类前景映射连接起来,得到分割概率张量
Y
S
Y_{S}
YS:
Y
b
g
=
1
N
∑
n
=
1
N
(
1
−
Y
(
n
)
)
(3)
Y_{bg} = \frac{1}{N} \sum_{n=1}^N (1-Y^{(n)}) \tag{3}
Ybg=N1n=1∑N(1−Y(n))(3)
Y
S
=
[
Y
]
[
Y
b
g
]
∈
R
H
×
W
×
(
N
+
1
)
(4)
Y_{S} = [Y][Y_{bg}]\in \mathbb{R}^{H×W×(N+1)} \tag{4}
YS=[Y][Ybg]∈RH×W×(N+1)(4)
The final segmentation mask Y ^ S ∈ R H × W \hat Y_{S} \in \mathbb{R}^{H×W} Y^S∈RH×W is obtained by computing the most probable class label for each position:
Y ^ S = a r g m a x n ∈ [ N + 1 ] Y S (5) \hat Y_{S} = arg max_{n \in[N+1]} Y_{S} \tag{5} Y^S=argmaxn∈[N+1]YS(5)
通过计算每个位置的最可能类标签,得到最终分割掩码
Y
^
S
∈
R
H
×
W
\hat Y_{S} \in \mathbb{R}^{H×W}
Y^S∈RH×W:
Y
^
S
=
a
r
g
m
a
x
n
∈
[
N
+
1
]
Y
S
(5)
\hat Y_{S} = arg max_{n \in[N+1]} Y_{S} \tag{5}
Y^S=argmaxn∈[N+1]YS(5)
Learning objective. The iFSL framework allows a learner to be trained using a class tag or a segmentation annotation using the classification loss or segmentation loss, respectively. The classification loss is formulated as the average binary cross-entropy between the spatially average-pooled class scores and its ground-truth class label:
where y g t y_{gt} ygt denotes the multi-hot encoded ground-truth class.
学习目标。 iFSL框架允许使用类标签,或分割标签来训练学习器,其中,分割标签使用分类损失或分割损失。分类损失表示为空间平均池化类别得分与其真实类别标签之间的平均二值交叉熵:
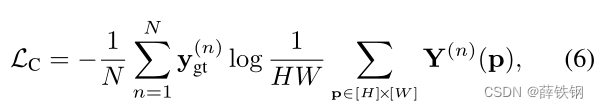
其中,
y
g
t
y_{gt}
ygt表示multi-hot编码形式的真实类别。
The segmentation loss is formulated as the average cross-entropy between the class distribution at each individual position and its ground-truth segmentation annotation:
where Y g t Y_{gt} Ygt denotes the ground-truth segmentation mask.
分割损失表示为每个个体位置上的类分布与其真实分割标签之间的平均交叉熵:
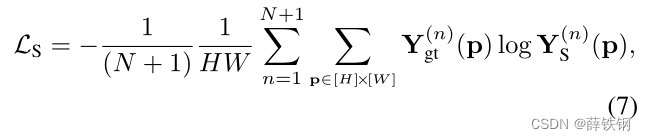
其中,
y
g
t
y_{gt}
ygt表示真实的分割掩码。
These two losses share a similar goal of classification but differ in whether to classify each image or each pixel. Either of them is thus chosen according to the given level of supervision for training.
这两种损失具有相似的分类目标,但在针对图像级别进行分类还是像素级别进行分类存在差异。因此,根据给定的监督水平选择其中之一进行训练。
5. Model architecture
注:在本节中,我们采用“目标”一词来表示嵌入在自注意学习上下文中的“查询”[11,24,53,75,79],以避免与待分割的“查询”图像同音混淆。
In this section, we present Attentive Squeeze Network (ASNet) of an effective iFSL model. The main building block of ASNet is the attentive squeeze layer (AS layer), which is a high-order self-attention layer that takes a correlation tensor and returns another level of correlational representation. ASNet takes as input the pyramidal cross-correlation tensors between a query and a support image feature pyramids, i.e., a hypercorrelation [44]. The pyramidal correlations are fed to pyramidal AS layers that gradually squeeze the spatial dimensions of the support image, and the pyramidal outputs are merged to a final foreground map in a bottom-up pathway [34,35,44]. Figure 2 illustrates the overall process of ASNet. The N-way output maps are computed in parallel and collected to prepare the class-wise foreground maps in Eq. (1) for iFSL.
在本节中,我们提出了一个有效的iFSL模型的注意力挤压网络(ASNet)。ASNet的主要构建块是注意力挤压层(AS层),这是一个高阶的自注意力层,接收一个相关张量并返回另一个层次的相关表示。ASNet将查询图像与支持图像特征金字塔之间的金字塔互相关张量作为输入,即超相关[44]。金字塔相关性被馈送到金字塔AS层,逐渐挤压支持图像的空间维度,金字塔输出以自下而上的路径合并得到最终的前景图[34,35,44]。图2展示了ASNet的总体流程。对N路输出图进行并行处理并收集,得到式1中的类前景图。
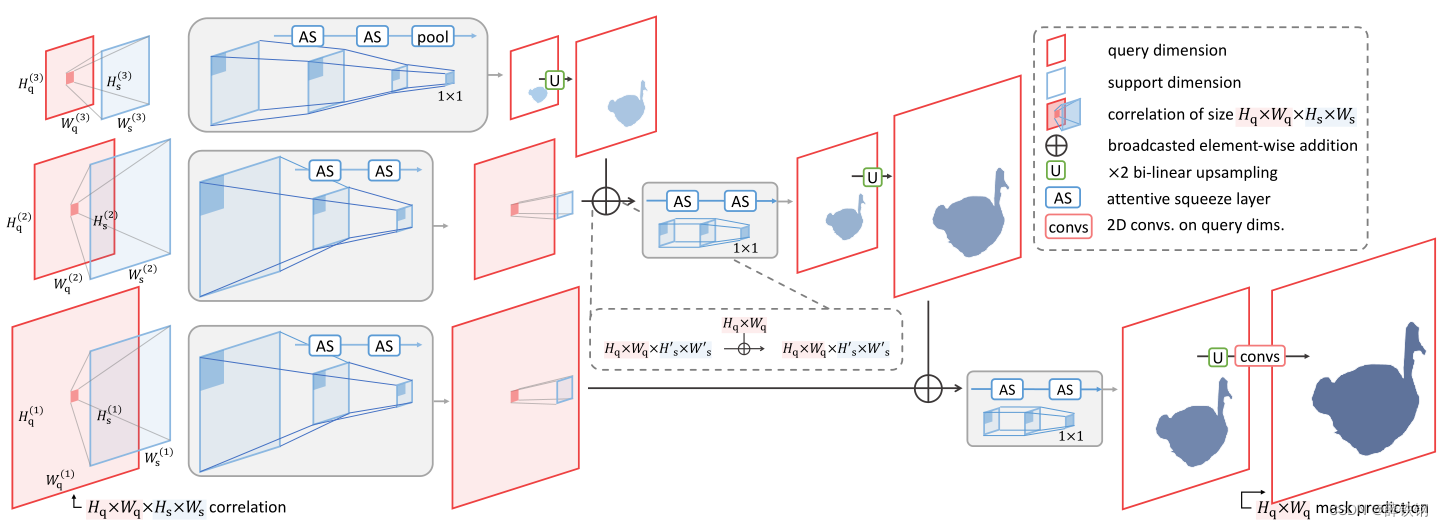
Figure 2. Overview of ASNet. ASNet first constructs a hypercorrelation [44] with image feature maps between a query (colored red) and a support (colored blue), where the 4D correlation is depicted as two 2D squares for demonstrational simplicity. ASNet then learns to transform the correlation to a foreground map by gradually squeezing the support dimension on each query dimension via global self- attention. Each input correlation, intermediate feature, and output foreground map has a channel dimension but is omitted in the illustration.
图2。ASNet概述。ASNet首先用查询(红色)和支持(蓝色)之间的图像特征映射构造了一个超相关[44],其中4D相关性被描述为两个2D正方形,以便演示简单。然后,ASNet学会通过全局自注意力逐步压缩每个查询维度上的支持维度,将相关性转换为前景图。每个输入相关、中间特征和输出前景映射都有一个通道维度,但在图中省略了。
5.1. Attentive Squeeze Network (ASNet)
Hypercorrelation construction. Our method first constructs N K N K NK hypercorrelations [44] between a query and each N K N K NK support image and then learns to generate a foreground segmentation mask w.r.t. each support input. To prepare the input hypercorrelations, an episode, i.e., a query and a support set, is enumerated into a paired list of the query, a support image, and a support label: { ( x , ( x s ( i ) , y ( i ) s ) ) } i = 1 N K \{(x, (x^{(i)}_{s} , y^{(i)}{s} ))\}_{i=1}^{N K} {(x,(xs(i),y(i)s))}i=1NK . The input image is fed to stacked convolutional layers in a CNN and its mid- to high-level output feature maps are collected to build a feature pyramid { F ( l ) } l = 1 L \{F^{(l)}\}^L_{l=1} {F(l)}l=1L, where l l l denotes the index of a unit layer, e.g., Bottleneck layer in ResNet50 [22]. We then compute cosine similarity between each pair of feature maps from the pair of query and support feature pyramids to obtain 4D correlation tensors of size H q ( l ) × W q ( l ) × H s ( l ) × W s ( l ) H^{(l)}_{q} ×W^{(l)}_{q} ×H^{(l)}_{s} ×W^{(l)}_{s} Hq(l)×Wq(l)×Hs(l)×Ws(l) , which is followed by ReLU [46]:
C ( l ) ( p q , p s ) = R e L U ( F q ( l ) ( p q ) ⋅ F s ( l ) ( p s ) ∣ ∣ F q ( l ) ( p q ) ∣ ∣ ∣ ∣ F s ( l ) ( p s ) ∣ ∣ ) (8) C^{(l)}(p_{q},p_{s})=ReLU(\frac{F^{(l)}_{q}(p_{q}) \cdot F^{(l)}_{s}(p_{s})}{ ||F^{(l)}_{q}(p_{q})||\quad||F^{(l)}_{s}(p_{s})||})\tag{8} C(l)(pq,ps)=ReLU(∣∣Fq(l)(pq)∣∣∣∣Fs(l)(ps)∣∣Fq(l)(pq)⋅Fs(l)(ps))(8)
超相关构造。 我们的方法首先在查询图像和每个 N K N K NK支持图像之间构建 N K N K NK超相关性[44],然后学习生成一个以每个支持输入为基础的前景分割掩码。为了准备输入的超相关,一个集合,即一个查询图像和一个支持集,被枚举成查询图像、支持图像和支持图像的标签的配对列表: { ( x , ( x s ( i ) , y ( i ) s ) ) } i = 1 N K \{(x, (x^{(i)}_{s} , y^{(i)}{s} ))\}_{i=1}^{N K} {(x,(xs(i),y(i)s))}i=1NK。输入图像被送入CNN中的堆叠卷积层,并收集 中高层的输出特征图 来构建特征金字塔 { F ( l ) } l = 1 L \{F^{(l)}\}^L_{l=1} {F(l)}l=1L,其中 l l l表示单元层的索引,例如ResNet50网络中的Bottleneck层[22]。然后,我们从查询和支持特征金字塔中计算每对特征图之间的余弦相似度,以获得大小为 H q ( l ) × W q ( l ) × H s ( l ) × W s ( l ) H^{(l)}_{q} ×W^{(l)}_{q} ×H^{(l)}_{s} ×W^{(l)}_{s} Hq(l)×Wq(l)×Hs(l)×Ws(l)的4D相关张量,然后再进行ReLU [46]:
C ( l ) ( p q , p s ) = R e L U ( F q ( l ) ( p q ) ⋅ F s ( l ) ( p s ) ∣ ∣ F q ( l ) ( p q ) ∣ ∣ ∣ ∣ F s ( l ) ( p s ) ∣ ∣ ) (8) C^{(l)}(p_{q},p_{s})=ReLU(\frac{F^{(l)}_{q}(p_{q}) \cdot F^{(l)}_{s}(p_{s})}{ ||F^{(l)}_{q}(p_{q})||\quad||F^{(l)}_{s}(p_{s})||})\tag{8} C(l)(pq,ps)=ReLU(∣∣Fq(l)(pq)∣∣∣∣Fs(l)(ps)∣∣Fq(l)(pq)⋅Fs(l)(ps))(8)
These L L L correlation tensors are grouped by P P P groups of the identical spatial sizes, and then the tensors in each group are concatenated along a new channel dimension to build a hypercorrelation pyramid: { C ( p ) ∣ C ( p ) ∈ R H q ( p ) × W q ( p ) × H s ( p ) × W s ( p ) × C i n ( p ) } p = 1 P \{C^{(p)}|C^{(p)} \in \mathbb{R}^{H^{(p)}_{q} ×W^{ (p)}_{q} ×H^{(p)}_{s} ×W^{(p)}_{s} ×C^{(p)}_{in}} \}^{P}_{p=1} {C(p)∣C(p)∈RHq(p)×Wq(p)×Hs(p)×Ws(p)×Cin(p)}p=1P such that the channel size C i n ( p ) C^{(p)}_{in} Cin(p) corresponds to the number of concatenated tensors in the p t h p_{th} pth group. We denote the first two spatial dimensions of the correlation tensor, i.e., R H q × W q \mathbb{R}^{H_{q}×W_{q}} RHq×Wq, as query dimensions, and the last two spatial dimensions, i.e., R H s × W s \mathbb{R}^{H_{s}×W_{s}} RHs×Ws, as support dimensions hereafter.
将这 L L L个相关张量按相同空间大小的 P P P组进行分组,然后将每组中的张量沿着新的通道维度进行级联,构建超相关金字塔: { C ( p ) ∣ C ( p ) ∈ R H q ( p ) × W q ( p ) × H s ( p ) × W s ( p ) × C i n ( p ) } p = 1 P \{C^{(p)}|C^{(p)} \in \mathbb{R}^{H^{(p)}_{q} ×W^{ (p)}_{q} ×H^{(p)}_{s} ×W^{(p)}_{s} ×C^{(p)}_{in}} \}^{P}_{p=1} {C(p)∣C(p)∈RHq(p)×Wq(p)×Hs(p)×Ws(p)×Cin(p)}p=1P 使得信道大小 C i n ( p ) C^{(p)}_{in} Cin(p) 对应于第 p t h p_{th} pth 组中的级联张量的数量。我们将相关性张量的前两个空间维度 R H q × W q \mathbb{R}^{H_{q}×W_{q}} RHq×Wq作为查询维度,后两个空间维度 R H s × W s \mathbb{R}^{H_{s}×W_{s}} RHs×Ws作为支持维度。
Attentive squeeze layer (AS layer). The AS layer transforms a correlation tensor to another with a smaller support dimension via strided self-attention. The tensor is recast as a matrix with each element representing a support pattern. Given a correlation tensor C ∈ R H q × W q × H s × W s × C i n C \in \mathbb{R}^{H_{q} ×W_{q} ×H_{s} ×W_{s} ×C_{in}} C∈RHq×Wq×Hs×Ws×Cin in a hypercorrelation pyramid, we start by reshaping the correlation tensor as a block matrix of size H q × W q H_{q} ×W_{q} Hq×Wq with each element corresponding to a correlation tensor of C X p ∈ R H s × W s × C i n C_{X_{p}}\in \mathbb{R}^{H_{s} ×W_{s} ×C_{in}} CXp∈RHs×Ws×Cinon the query position x q x_{q} xq such that
注意力挤压层(AS层)。 AS层通过跨步自注意力将一个相关张量转换为另一个支持维数更小的相关张量。张量被重写为一个矩阵,每个元素代表一个支持模式。给定一个超相关金字塔中的相关张量 C ∈ R H q × W q × H s × W s × C i n C \in \mathbb{R}^{H_{q} ×W_{q} ×H_{s} ×W_{s} ×C_{in}} C∈RHq×Wq×Hs×Ws×Cin,首先将相关张量重塑为大小为 H q × W q H_{q} ×W_{q} Hq×Wq的分块矩阵,每个元素对应查询位置 x q x_{q} xq上的相关张量 C ( X q ) ∈ R H s × W s × C i n C_{(X_{q})}\in \mathbb{R}^{H_{s} ×W_{s} ×C_{in}} C(Xq)∈RHs×Ws×Cin,使得
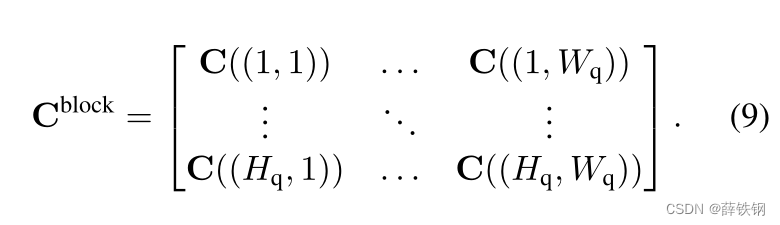
We call each element a support correlation tensor. The goal of an AS layer is to analyze the global context of each support correlation tensor and extract a correlational representation with a reduced support dimension while the query dimension is preserved: R H q × W q × H s × W s × C i n → R H q × W q × H s ′ × W s ′ × C o u t \mathbb{R}^{H_{q} ×W_{q} ×H_{s} ×W_{s} ×C_{in}} \xrightarrow{}\mathbb{R}^{H_{q} ×W_{q} ×H^{'}_{s} ×W^{'}_{s} ×C_{out}} RHq×Wq×Hs×Ws×CinRHq×Wq×Hs′×Ws′×Cout , where H s ′ ≤ H s H^{′}_{s} \leq H_{s} Hs′≤Hs and W s ′ ≤ W s W^{′}_{s} \leq W_{s} Ws′≤Ws. To learn a holistic pattern of each support correlation, we adopt the global self-attention mechanism [75] for correlational feature transform. The self-attention weights are shared across all query positions and processed in parallel.
我们称每个元素为支持相关张量。AS层的目标是分析每个支持度相关张量的全局上下文,并在保持查询维度不变的情况下提取支持度维度降低的相关表示: R H q × W q × H s × W s × C i n → R H q × W q × H s ′ × W s ′ × C o u t \mathbb{R}^{H_{q} ×W_{q} ×H_{s} ×W_{s} ×C_{in}} \xrightarrow{}\mathbb{R}^{H_{q} ×W_{q} ×H^{'}_{s} ×W^{'}_{s} ×C_{out}} RHq×Wq×Hs×Ws×CinRHq×Wq×Hs′×Ws′×Cout,其中 H s ′ ≤ H s H^{′}_{s} \leq H_{s} Hs′≤Hs和 W s ′ ≤ W s W^{′}_{s} \leq W_{s} Ws′≤Ws。为了学习每个支持度相关的整体模式,我们采用全局自注意力机制[75]进行相关特征转换。自注意力权重在所有查询位置共享并并行处理。
Let us denote a support correlation tensor on any query position X q X_{q} Xq by C s = C b l o c k ( X q ) C^{s} = C^{block}(X_{q}) Cs=Cblock(Xq) for notational brevity as all positions share the following computation. The self-attention computation starts by embedding a support correlation tensor C s C^{s} Cs to a target , key, value triplet: T , K , V ∈ R H s ′ × W s ′ × C h d T, K, V \in \mathbb{R}^{H^{′}_{s} ×W^{′}_{s} ×C_{hd}} T,K,V∈RHs′×Ws′×Chd, using three convolutions of which strides greater than or equal to one to govern the output size. The resultant target and key correlational representations, T T T and K K K, are then used to compute an attention context. The attention context is computed as following matrix multiplication:
A = T K T ∈ R H s ′ × W s ′ × H s ′ × W s ′ (10) A=TK^{T} \in \mathbb{R}^{H^{'}_{s} ×W^{'}_{s} × H^{'}_{s} ×W^{'}_{s} } \tag{10} A=TKT∈RHs′×Ws′×Hs′×Ws′(10)
我们用
C
s
=
C
b
l
o
c
k
(
X
q
)
C^{s} = C^{block}(X_{q})
Cs=Cblock(Xq)表示任意查询位置
X
q
X_{q}
Xq上的一个支持相关张量,因为所有位置共同进行以下计算。自注意力计算首先将一个支持相关张量
C
s
C^{s}
Cs嵌入到一个目标、键、值三元组
T
,
K
,
V
∈
R
H
s
′
×
W
s
′
×
C
h
d
T, K, V \in \mathbb{R}^{H^{′}_{s} ×W^{′}_{s} ×C_{hd}}
T,K,V∈RHs′×Ws′×Chd中,使用三个步长大于等于1的卷积来控制输出大小。生成的目标和值相关表示
T
T
T和
K
K
K被用来计算注意力上下文。注意力上下文计算如下矩阵相乘:
A
=
T
K
T
∈
R
H
s
′
×
W
s
′
×
H
s
′
×
W
s
′
(10)
A=TK^{T} \in \mathbb{R}^{H^{'}_{s} ×W^{'}_{s} × H^{'}_{s} ×W^{'}_{s} } \tag{10}
A=TKT∈RHs′×Ws′×Hs′×Ws′(10)
Next, the attention context is normalized by softmax such that the votes on key foreground positions sum to one with masking attention by the support mask annotation Y s Y_{s} Ys if available to attend more on the foreground region:
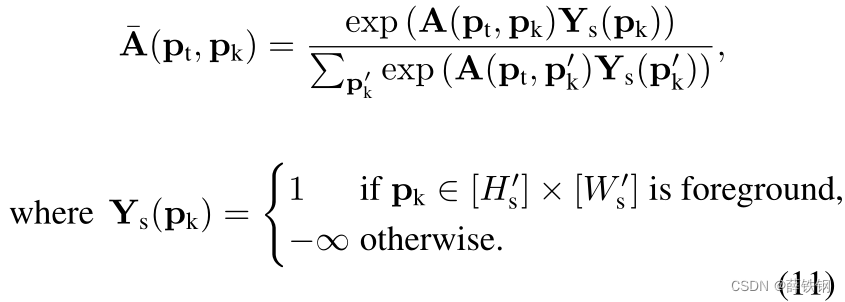
接下来,通过softmax对注意力上下文进行归一化,如果有更多的关注前景区域,则支持掩码标注
Y
s
=
1
Y_{s}=1
Ys=1,这样就可以使关键前景位置上的投票总和为1:
A
‾
(
p
t
,
p
k
)
=
e
x
p
(
A
(
p
t
,
p
k
)
Y
s
(
p
k
)
)
∑
p
k
′
e
x
p
(
A
(
p
t
,
p
k
′
)
Y
s
(
p
k
′
)
)
\overline{A}(p_{t},p_{k})=\frac{exp(A(p_{t},p_{k})Y_{s}(p_{k}))}{\sum_{p^{'}_{k}} exp(A(p_{t},p_{k}^{'})Y_{s}(p_{k}^{'}))}
A(pt,pk)=∑pk′exp(A(pt,pk′)Ys(pk′))exp(A(pt,pk)Ys(pk))
w
h
e
r
e
Y
s
(
p
k
)
=
{
1
i
f
p
k
∈
[
H
s
′
]
×
[
W
]
s
′
i
s
f
o
r
e
g
r
o
u
n
d
−
∞
o
t
h
e
r
w
i
s
e
(11)
where Y_{s}(p_{k})=\begin{cases} 1 & if p_{k} \in [H^{'}_{s}] × [W]^{'}_{s} is foreground\\ -\infty & otherwise \\ \end{cases}\tag{11}
whereYs(pk)={1−∞ifpk∈[Hs′]×[W]s′isforegroundotherwise(11)
The masked attention context A ‾ \overline{A} A is then used to aggregate the value embedding V V V:
C A s = A ‾ V ∈ R H s ′ × W s ′ × C h d (12) C^{s}_{A}=\overline{A} V \in \mathbb{R}^{H^{'}_{s}×W^{'}_{s}×C_{hd} }\tag{12} CAs=AV∈RHs′×Ws′×Chd(12)
然后利用掩码注意上力下文
A
‾
\overline{A}
A对值嵌入
V
V
V进行聚合:
C
A
s
=
A
‾
V
∈
R
H
s
′
×
W
s
′
×
C
h
d
(12)
C^{s}_{A}=\overline{A} V \in \mathbb{R}^{H^{'}_{s}×W^{'}_{s}×C_{hd} }\tag{12}
CAs=AV∈RHs′×Ws′×Chd(12)
The attended representation is fed to an MLP layer, W o W_{o} Wo, and added to the input. In case the input and output dimensions mismatch, the input is optionally fed to a convolutional layer, W I W_{I} WI. The addition is followed by an activation layer ϕ ( ⋅ ) \phi(·) ϕ(⋅) consisting of a group normalization [85] and a ReLU activation [46]:
参与的表示被馈送到MLP层
W
o
W_{o}
Wo,并添加到输入中。当输入和输出维度不匹配时,可选地将输入送入卷积层
W
I
W_{I}
WI。然后是由一组归一化[ 85 ]和ReLU激活[ 46 ]组成的激活层
ϕ
(
⋅
)
\phi(·)
ϕ(⋅):
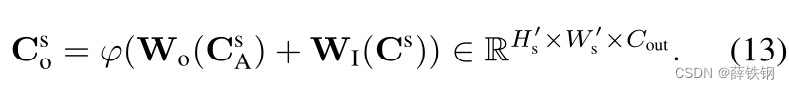
The output is then fed to another MLP that concludes a unit operation of an AS layer:
然后将输出反馈到另一个MLP,该MLP完成一个AS层的单元操作:
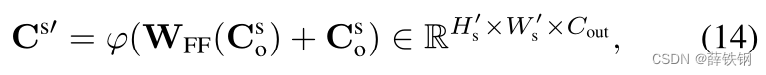
which is embedded to the corresponding query position in the block matrix of Eq. (9). Note that the AS layer can be stacked to progressively reduce the size of support correlation tensor, H s ′ × W s ′ H^{′}_{s} × W^{′}_{s} Hs′×Ws′ , to a smaller size. The overall pipeline of AS layer is illustrated in the supplementary material.
输出的 C S ′ C^{S^{'}} CS′嵌入到分块矩阵中相应的查询位置(式9)。需要注意的是,可以对AS层进行堆叠,逐步减小支持相关张量 H s ′ × W s ′ H^{'}_{s} ×W^{'}_{s} Hs′×Ws′的大小。AS层的完整pipline在补充材料中进行了说明。
Multi-layer fusion. The pyramid correlational representations are merged from the coarsest to the finest level by cascading a pair-wise operation of the following three steps: upsampling, addition, and non-linear transform. We first bilinearly upsample the bottommost correlational representation to the query spatial dimension of its adjacent earlier one and then add the two representations to obtain a mixed one C m i x C^{mix} Cmix. The mixed representation is fed to two sequential AS layers until it becomes a point feature of size H s ′ × W s ′ = 1 H^{′}_{s} × W^{′}_{s}=1 Hs′×Ws′=1, which is fed to the subsequent pyramidal fusion. The output from the earliest fusion layer is fed to a convolutional decoder, which consists of interleaved 2D convolution and bilinear upsampling that map the C-dimensional channel to 2 (foreground and background) and the output spatial size to the input query image size. See Fig. 2 for the overall process of multilayer fusion.
多层融合。 通过级联 上采样、加法和非线性变换 3个步骤的成对操作,将金字塔相关表示从最粗的级别合并到最细的级别。我们首先将最底层的相关表示进行双线性上采样,使得它的维度变成其相邻的早期表示的查询空间维度,然后将这两个表示相加得到一个混合表示 C m i x C^{mix} Cmix。混合表示被馈送到两个连续的AS层,直到它成为大小为 H s ′ × W s ′ = 1 H^{′}_{s} × W^{′}_{s}=1 Hs′×Ws′=1的点特征,再被馈送到后续的金字塔融合。最早融合层的输出被馈送到卷积解码器,卷积解码器由交错2D卷积和双线性上采样组成,将C维通道映射到2(前景和背景),输出空间大小映射到输入查询图像大小。多层融合的整体过程如图2所示。
Class-wise foreground map computation. The K-shot output foreground activation maps are averaged to produce a mask prediction for each class. The averaged output map is normalized by softmax over the two channels of the binary segmentation map to obtain a foreground probability prediction Y ( n ) ∈ R H × W Y^{(n)} \in \mathbb{R}^{H×W} Y(n)∈RH×W .
类的前景映射计算。 对K-shot输出的前景激活映射进行平均,以产生每个类的掩码预测。将平均后的输出映射在二值分割映射的两个通道上进行softmax归一化,得到前景概率预测 Y ( n ) ∈ R H × W Y^{(n)} \in \mathbb{R}^{H×W} Y(n)∈RH×W。
6. Experiments
In this section we report our experimental results regarding the FS-CS task, the iFSL framework, as well as the ASNet after briefly describing implementation details and evaluation benchmarks. See the supplementary material for additional results, analyses, and experimental details.
在本节中,在简要描述实现细节和评估标准之后,我们将报告关于FS-CS任务、iFSL框架以及ASNet的实验结果。有关额外的结果、分析和实验细节,请参阅补充材料。
6.1. Experimental setups
Experimental settings. We select ResNet-50 and ResNet-101 [22] pretrained on ImageNet [60] as our backbone networks for a fair comparison with other methods and freeze the backbone during training as similarly as the previous work [44, 73]. We train models using Adam [27] optimizer with learning rate of 1 0 − 4 10^{−4} 10−4 and 1 0 − 3 10^{−3} 10−3 for the classification loss and the segmentation loss, respectively. We train all models with 1-way 1-shot training episodes and evaluate the models on arbitrary N-way K-shot episodes. For inferring class occurrences, we use a threshold δ = 0.5 \delta=0.5 δ=0.5. All the AS layers are implemented as multi-head attention with 8 heads. The number of correlation pyramid is set to P = 3 P = 3 P=3.
实验设置。 我们选择在ImageNet[60]上预训练的ResNet-50和ResNet-101[22]作为我们的backbone,以便与其他方法进行公平的比较,并在训练过程中冻结backbone,与之前的工作相似[44,73]。对于分类损失和分割损失,我们使用Adam[27]优化器训练模型,学习率分别为 1 0 − 4 10^{−4} 10−4和 1 0 − 3 10^{−3} 10−3 。我们用1-way 1-shot训练集来训练所有模型,并在任意的N-way K-shot集合上评估模型。为了推断类的出现,我们使用阈值 δ = 0.5 \delta=0.5 δ=0.5。所有的AS层均采用8头多头注意力机制。相关金字塔数设置为 P = 3 P = 3 P=3。
Dataset. For the new task of FS-CS, we construct a benchmark adopting the images and splits from the two widely-used FS-S datasets, P a s c a l − 5 i Pascal-5^{i} Pascal−5i [13, 63] and C O C O − 2 0 i COCO-20^{i} COCO−20i [36, 47], which are also suitable for multi-label classification [83]. Within each fold, we construct an episode by randomly sampling a query and an N-way K-shot support set that annotates the query with N-way class labels and an (N+ 1)-way segmentation mask in the context of the support set. For the FS-S task, we also use P a s c a l − 5 i Pascal-5^{i} Pascal−5i and C O C O − 2 0 i COCO-20^{i} COCO−20i following the same data splits as [63] and [47], respectively.
数据集。 对于FS-CS的新任务,我们采用了 P a s c a l − 5 i Pascal-5^{i} Pascal−5i[13, 63]和 C O C O − 2 0 i COCO-20^{i} COCO−20i [36, 47]这两个广泛使用的FS-S数据集,数据集中的图像和分割构建了一个基准,这两个数据集也适用于多标签分类[83]。在每个fold中,我们通过随机采样查询和N-way K-shot支持集来构造一个集,该支持集在支持集的上下文中用N-way类标签和(N+ 1)-way分割掩码来标注查询。对于FS-S任务,我们也分别使用 P a s c a l − 5 i Pascal-5^{i} Pascal−5i和 C O C O − 2 0 i COCO-20^{i} COCO−20i ,数据分割方式与[63]和[47]相同。
Evaluation. Each dataset is split into four mutually disjoint class sets and cross-validated. For multi-label classification evaluation metrics, we use the 0/1 exact ratio E R = 1 [ y g t = y C ] ER = \mathbb{1}[y_{gt} =y_{C}] ER=1[ygt=yC] [12]. In the supplementary material, we also report the results in accuracy a c c = 1 N ∑ n 1 [ y g t ( n ) = y C ( n ) ] acc = \frac{1}{N} \sum_{n}\mathbb{1}[y_{gt}^{(n)} =y_{C}^{(n)}] acc=N1∑n1[ygt(n)=yC(n)]For segmentation, we use mean IoU m I o U = 1 C ∑ C I O U c mIoU = \frac{1}{C}\sum_{C}IOU_{c} mIoU=C1∑CIOUc[63, 78], where I o U c IoU_{c} IoUc denotes an IoU value of cth class.
评估。 每个数据集被分割成四个相互分离的类集并进行交叉验证。对于多标签分类评估指标,我们使用0/1精确比率 E R = 1 [ y g t = y C ] ER = \mathbb{1}[y_{gt} =y_{C}] ER=1[ygt=yC][12]。在补充材料中,我们还报告了精度 a c c = 1 N ∑ n 1 [ y g t ( n ) = y C ( n ) ] acc = \frac{1}{N} \sum_{n}\mathbb{1}[y_{gt}^{(n)} =y_{C}^{(n)}] acc=N1∑n1[ygt(n)=yC(n)]的结果。为了细分,我们使用平均值 m I o U = 1 C ∑ C I O U C mIoU = \frac{1}{C}\sum_{C}IOU_{C} mIoU=C1∑CIOUC[63,78],其中 I o U c IoU_{c} IoUc表示第C类的IoU值。

Figure 3. 2-way 1-shot segmentation results of ASNet on FS-CS.The examples cover all three cases of C = ∅ C = ∅ C=∅, C ⊂ C s C ⊂ C_{s} C⊂Cs, and C = C s C = C_{s} C=Cs.The images are resized to square shape for visualization.
图3。基于FS-CS的ASNet在2-way 1-shot上的分割结果。这些例子涵盖 C = ∅ C = ∅ C=∅、 C ⊂ C s C ⊂ C_{s} C⊂Cs和 C = C s C = C_{s} C=Cs的所有三种情况。图像被调整为正方形形状以便可视化。
6.2. Experimental evaluation of iFSL on FS-CS
In this subsection, we investigate the iFSL learning framework on the FS-CS task. All ablation studies are conducted using ResNet50 on P a s c a l − 5 i Pascal-5^{i} Pascal−5i and evaluated in 1-way 1-shot setup unless specified otherwise. Note that it is difficult to present a fair and direct comparison between the conventional FS-C and our few-shot classification task since FS-C is always evaluated on single-label classification benchmarks [2,32,57,74,76], whereas our task is evaluated on multi-label benchmarks [13,36], which are irreducible to a single-label one in general.
在本小节中,我们将研究FS-CS任务中的iFSL学习框架。除非另有规定,所有消融实验均使用ResNet-50在 P a s c a l − 5 i Pascal-5^{i} Pascal−5i上进行,并采用1-way 1-shot的方法进行评估。请注意,由于FS-C总是在单标签分类基准上进行评估[2,32,57,74,76],而我们的任务是在多标签基准上进行评估[13,36],这些基准通常不能简化为单标签基准,因此很难在传统FS-C和我们的小样本分类任务之间进行公平和直接的比较,
Effectiveness of iFSL on FS-CS. We validate the iFSL framework on FS-CS and also compare the performance of ASNet with those of three recent state-of-the-art methods, PANet [78], PFENet [73], and HSNet [44], which are originally proposed for the conventional FS-S task; all the models are trained by iFSL for a fair comparison. Note that we exclude the background merging step (Eqs. 3 and 4) for PANet as its own pipeline produces a multi-class output including background. Tables 1 and 2 validate the iFSL framework on the FS-CS task quantitatively, where our ASNet surpasses other methods on both 1-way and 2-way setups in terms of few-shot classification as well as the segmentation performance. The 2-way segmentation results are also qualitatively demonstrated in Fig. 3 visualizing exhaustive inclusion relations between a query class set C C C and a target (support) class set C s C_{s} Cs in a 2-way setup.
iFSL在FS-CS中的有效性。 我们验证了FS-CS上的iFSL框架,并将ASNet的性能与最近的三种最先进的方法进行了比较,分别是PANet [78], PFENet[73]和HSNet[44],这三种方法最初是为传统的FS-S任务提出的;所有模型都经过iFSL训练,以便公平比较。注意,我们排除了PANet的背景合并步骤(公式3和4),因为它自己的pipeline 会产生包含背景的多类输出。表1和表2定量地验证了iFSL框架在FS - CS任务上的有效性,其中我们的ASNet在小样本分类和分割方面的性能都超过了1-way和2 -way设置上的其他方法。图3也定性地展示了2-way设置中查询类集 C C C 和目标(支持)类集 C s C_{s} Cs之间的穷举包含关系。
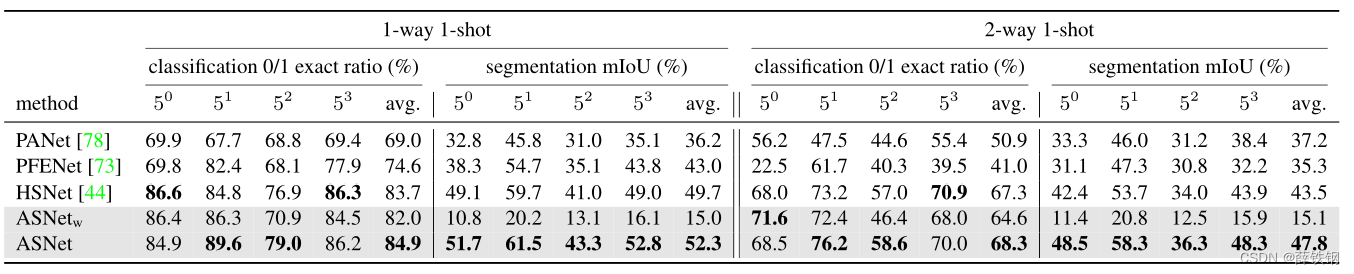
Table 1. Performance comparison of ASNet and others on FS-CS and P a s c a l − 5 i Pascal-5^{i} Pascal−5ii [63]. All methods are trained and evaluated under the iFSL framework given strong labels, i.e., class segmentation masks, except for A S N e t w ASNet_{w} ASNetw that is trained only with weak labels, i.e., class tags.
表1。ASNet在FS-CS和 P a s c a l − 5 i Pascal-5^{i} Pascal−5i上的性能比较[63]。所有的方法都在iFSL框架下训练和评估,并给予强标签,即类分割掩码;除了 A S N e t w ASNet_{w} ASNetw只使用弱标签,即类标签进行训练。
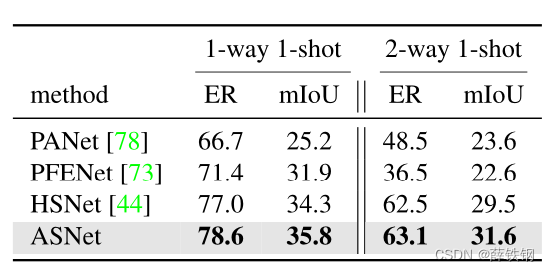
Table 2. Performance comparison of ASNet and others on FS-CS and C O C O − 2 0 i COCO-20^{i} COCO−20i
表2。ASNet等网络在FS-CS和 C O C O − 2 0 i COCO-20^{i} COCO−20i 上的性能比较
Weakly-supervised iFSL. The iFSL framework is versatile across the level of supervision: weak labels (class tags) or strong labels (segmentation masks). Assuming weak labels are available but strong labels are not, ASNet is trainable with the classification learning objective of iFSL (Eq. 6) and its results are presented as A S N e t w ASNet_{w} ASNetw in Table 1. A S N e t w ASNet_{w} ASNetwperforms on par with ASNet in terms of classification ER (82.0% vs. 84.9% on 1-way 1-shot), but performs ineffectively on the segmentation task (15.0% vs. 52.3% on 1-way 1-shot). The result implies that the class tag labels are sufficient for a model to recognize the class occurrences, but are weak to endorse model’s precise spatial recognition ability.
弱监督iFSL。 iFSL框架在各个监督级别上都是通用的:弱标签(类标签)或强标签(分割掩码)。假设弱标签可用而强标签不可用,ASNet以iFSL 为分类学习目标进行训练(式6 ),其结果如表1中的 A S N e t w ASNet_{w} ASNetw所示。 A S N e t w ASNet_{w} ASNetw在分类ER ( 82.0 % vs.84.9 %)上表现与ASNet相当,但在分割任务( 15.0 % vs.52 . 3 %)上表现不佳。结果表明,类别标签对于模型识别 类别出现 是足够的,但对于模型精确的空间识别能力是很弱的。
Multi-class scalability of FS-CS. In addition, FS-CS is extensible to a multi-class problem with arbitrary numbers of classes, while FS-S is not as flexible as FS-CS in the wild. Figure 4 compares the FS-CS performances of four methods by varying the N-way classes from one to five, where the other experimental setup follows the same one as in Table 1. Our ASNet shows consistently better performances than other methods on FS-CS in varying number of classes.
FS-CS的多类可扩展性。 FS - CS可扩展到任意类数的多类问题,而FS - S在实际应用中不如FS - CS灵活。图4通过将类别个数从1个改为5个,比较了四种方法的FS-CS性能,其他实验设置与表1相同。在不同的类别数量下,我们的ASNet在FS-CS上的性能始终优于其他方法。
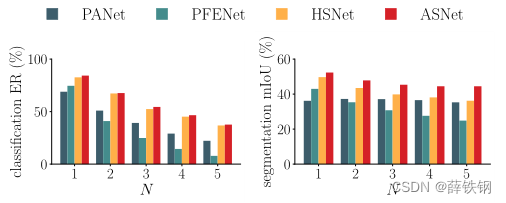
Figure 4. N-way 1-shot FS-CS performance comparison of four methods by varying N from 1 to 5.
图4。 N从1到5变化时,四种方法的N-way 1-shot FS-CS性能比较
Robustness of FS-CS against task transfer . We evaluate the transferability between FS-CS, FS-C, and FS-S by training a model on one task and evaluating it on the other task. The results are compared in Fig. 5 in which ‘FS-S →FS-CS’ represents the result where the model trained on the FS-S task (with the guarantee of support class presence) is evaluated on the FS-CS setup. To construct training and validation splits for FS-C or FS-S, we sample episodes that satisfy the constraint of support class occurrences . For training FS-C models, we use the class tag supervision only. All the other settings are fixed the same, e.g., we use ASNet with ResNet50 and P a s c a l − 5 i Pascal-5^{i} Pascal−5i.
FS-CS对任务迁移的鲁棒性。 我们通过在一个任务上训练一个模型并在另一个任务上评估FS - CS、FS - C和FS - S之间的可迁移性。图5中,’ FS-S→FS-CS '表示在FS - S任务(有了支持类存在性的保证)上训练的模型在FS - CS设置上评估的结果。为了构建FS - C或FS - S的训练和验证分割,我们对满足支持类发生约束的事件进行采样 。对于FS - C模型的训练,我们只使用类标签监督。其他的设置都是固定不变的,例如我们使用ASNet搭配ResNet50网络和 P a s c a l − 5 i Pascal- 5^{i} Pascal−5i。
The results show that FS-CS learners, i.e., models trained on FS-CS, are transferable to the two conventional few-shot learning tasks and yet overcome their shortcomings. The transferability between few-shot classification tasks, i.e., FS-C and F S − C S w FS-CS_{w} FS−CSw, is presented in Fig. 5 (a). On this setup, the F S − C S w FS-CS_{w} FS−CSw learner is evaluated by predicting a higher class response between the two classes, although it is trained using the multi-label classification objective. The FS-CS learner closely competes with the FS-C learner on FS-C in terms of classification accuracy. In contrast, the task transfer between segmentation tasks, FS-S and FS-CS, results in asymmetric outcomes as shown in Fig. 5 (b) and ©. The FS-CS learner shows relatively small performance drop on FS-S, however, the FS-S learner suffers a severe performance drop on FS-CS. Qualitative examples in Fig. 1 demonstrate that the FS-S learner predictsa vast number of false-positive pixels and results in poor performances. In contrast, the FS-CS learner successfully distinguishes the region of interest by analyzing the semantic relevance of the query objects between the support set.
结果表明,FS-CS学习器,即在FS-CS上训练的模型,可以转移到两种传统的小样本学习任务中,并克服了它们的缺点。小样本分类任务FS-C和 F S − C S w FS-CS_{w} FS−CSw之间的可迁移性如图5 (a)所示。在此设置下, F S − C S w FS-CS_{w} FS−CSw学习器通过预测两个类之间更高的类响应来进行评估,尽管它是使用多标签分类目标进行训练的。FS-CS学习器在分类精度方面与FS-C上的FS-C学习器竞争密切。相比之下,分割任务FS-S和FS-CS之间的任务转移导致了如图5 (b)和©所示的不对称结果。FS-CS学习器在FS-S上表现出相对较小的性能下降,而FS-S学习器在FS-CS上表现出严重的性能下降。图1中的定性例子表明FS-S学习器预测了大量的假阳性像素,结果表现不佳。相比之下,FS-CS学习器通过分析支持集之间查询对象的语义相关性成功地区分了感兴趣的区域。
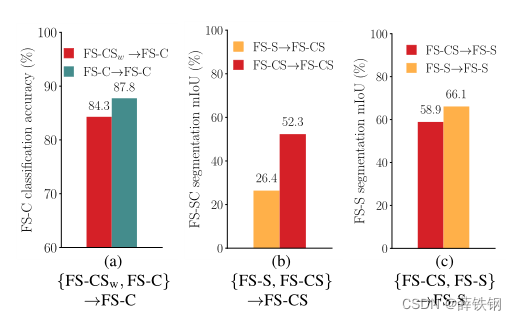
Figure 5. Results of task transfer. A → B denotes a model trained on task A and evaluated on task B. F S − C S w FS-CS_{w} FS−CSw denotes FS-CS with weak labels. (a): Exclusive 2-way 1-shot classification accuracy of FS-C or F S − C S w FS-CS_{w} FS−CSw learners on FS-C. (b): 1-way 1-shot segmentation mIoU of FS-S or FS-CS learners on FS-CS. ©: 1-way 1-shot segmentation mIoU of FS-S or FS-CS learners on FS-S.
图5。 任务转移的结果。A→B表示在任务A上训练并在任务B上评估的模型。 F S − C S w FS-CS_{w} FS−CSw 表示带有弱标签的FS-CS。(a): FS-C或 F S − C S w FS-CS_{w} FS−CSw 学习器在FS-C上的2-way 1-shot分类精度。(b): FS-S或FS-CS学习器在FS-CS上的1-way 1-shot分割的mIoU。©: FS-S或FS-CS学习器在FS-S上的1-way 1-shot分割的mIoU。
6.3. Comparison with recent FS-S methods on FS-S
Tables 3 and 4 compare the results of the recent few-shot semantic segmentation methods and ASNet on the conventional FS-S task. All model performances in the tables are taken from corresponding papers, and the numbers of learnable parameters are either taken from papers or counted from their official sources of implementation. For a fair comparison with each other, some methods that incorporate extra unlabeled images [40, 90] are reported as their model performances measured in the absence of the extra data. Note that ASNet in Tables 3 and 4 is trained and evaluated following the FS-S setup, not the proposed FS-CS one.
表3和表4比较了最近的少样本语义分割方法和ASNet在常规FS - S任务上的结果。表中的所有模型性能均取自相应的论文,可学习参数的数量要么取自论文,要么从其官方实现来源统计。为了进行公平的比较,在没有额外数据的情况下,一些纳入额外未标记图像的方法[40,90]被报告为在没有额外数据的情况下测量的模型性能。注意,表3和表4中的ASNet是按照FS - S设置进行训练和评估的,而不是提出的FS - CS设置。
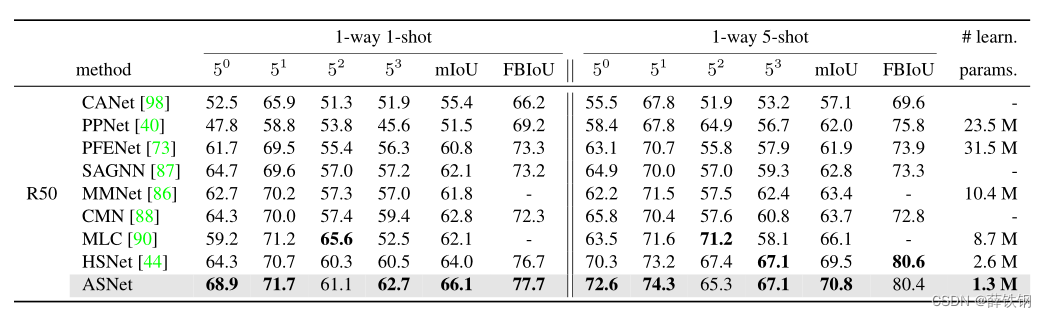
Table 3. FS-S results on 1-way 1-shot and 1-way 5-shot setups on P a s c a l − 5 i Pascal-5^{i} Pascal−5i [63] using ResNet50 [22] (R50).
表3。 使用ResNet50 [22] (R50)在
P
a
s
c
a
l
−
5
i
Pascal-5^{i}
Pascal−5i [[63]上的1-way 1-shot和1-way 5-shot 设置的FS-S结果。
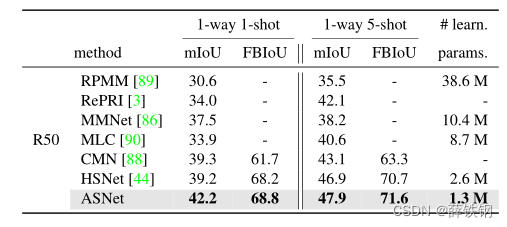
Table 4. FS-S results on 1-way 1-shot and 1-way 5-shot setups on COCO-20i [47].
表4。 在COCO-20i数据集上的1-way 1-shot 和 1-way 5-shot设置。
The results verify that ASNet outperforms the existing methods including the most recent ones [86, 88, 90]. Especially, the methods that cast few-shot segmentation as the task of correlation feature transform, ASNet and HSNet [44], outperform other visual feature transform
methods, indicating that learning correlations is beneficial for both FS-CS and FS-S. Note that ASNet is the most lightweight among others as ASNet processes correlation features that have smaller channel dimensions, e.g., at most 128, than visual features, e.g., at most 2048 in ResNet50.
结果验证了ASNet优于现有方法,包括最新的方法[86,88,90]。特别是将小样本分割作为相关特征变换任务的方法ASNet和HSNet[44]优于其他视觉特征变换方法,表明相关性学习对FS-CS和FS-S都有好处。请注意,ASNet是最轻量级的,因为ASNet处理的相关特征具有更小的通道维度,例如,最多128,比视觉特征,例如,在ResNet50中最多2048。
6.4. Analyses on the model architecture
We perform ablation studies on the model architecture to reveal the benefit of each component. We replace the global self-attention in the ASNet layer with the local self-attention [53] to see the effect of the global self-attention (Table 5a). The local self-attention variant is com-
patible with the global ASNet in terms of the classification exact ratio but degrades the segmentation mIoU significantly, signifying the importance of the learning the global context of feature correlations. Next, we ablate the attention masking in Eq. (11), which verifies that the attention masking prior is effective (Table 5b). Lastly, we replace the multi-layer fusion path with spatial average pooling over the
support dimensions followed by element-wise addition (Table 5c), and the result indicates that it is crucial to fuse outputs from the multi-layer correlations to precisely estimate class occurrence and segmentation masks.
我们对模型架构进行消融研究,以验证每个组件的有点。我们将ASNet层的全局自注意替换为局部自注意[53],看看全局自注意的效果(表5a)。局部自注意变体在分类精确比方面与全局ASNet兼容,但分割mIoU显著降低,表明学习特征关联的全局上下文的重要性。接下来,我们消去式11中的注意屏蔽,验证了注意屏蔽先验是有效的(表5b)。最后,我们将多层融合路径替换为支持维上的空间平均池化,然后按元素添加(表5c),结果表明,融合多层相关性的输出对于精确估计类出现和分割掩码至关重要。

Table 5. Ablation study of the AS layer on 1-way 1-shot on P a s c a l − 5 i Pascal-5^{i} Pascal−5i[63] using ResNet50 [22].
表5。 利用ResNet50在 P a s c a l − 5 i Pascal-5^{i} Pascal−5i上使用1-way 1-shot 进行消融实验。
7. Discussion
We have introduced the integrative task of few-shot classification and segmentation (FS-CS) that generalizes two existing few-shot learning problems. Our proposed integrative few-shot learning (iFSL) framework is shown to be effective on FS-CS, in addition, our proposed attentive squeeze network (ASNet) outperforms recent state-of-the-art methods on both FS-CS and FS-S. The iFSL design allows a model to learn either with weak or strong labels, that being said, learning our method with weak labels achieves low segmentation performances. This result opens a future direction of effectively boosting the segmentation performance leveraging weak labels in the absence of strong labels for FS-CS.
我们引入了小样本分类和分割的集成任务(FS-CS),它概括了现有的两个小样本学习问题。我们提出的综合小样本学习(iFSL)框架在FS-CS上被证明是有效的,此外,我们提出的注意力挤压网络(ASNet)在FS-CS和FS-S上都优于最近最先进的方法。iFSL设计允许模型使用弱标签或强标签进行学习,也就是说,如果使用弱标签学习,那么我们的方法可以获得较低的分割性能。这一结果为FS-CS在缺乏强标签的情况下利用弱标签有效提高分割性能开辟了未来的方向。














 3224
3224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









