







0 Abstract
- 作者指出他们提出了一种新颖的基于对比学习的FSL网络框架,这种框架可以将对比学习很好的集成到现在广泛使用的two-stage training paradigm(包括pre-training和meta-learning两个stages)
- 在pre-training stage,提出了self-supervised constrastive loss,包括两种对比关系:1️⃣feature vector .vs. feature map2️⃣feature map .vs. feature map
更好的利用global information和local information学习到比较好的初始化表征(initial representations)。 - 在meta-learning stage,提出了cross-view episodic training mechanism,对同一轮次的两个不同视角进行最近中心点分类(nearest centroid classification),并基于此采用一种distance-scaled contrastive loss。这两种strategies使model讷讷狗狗克服不同视角之间的bias,提高表征的可迁移能力。
Keywords:FSL,Meta Learning,Constrastive learning,Cross-view episodic learning
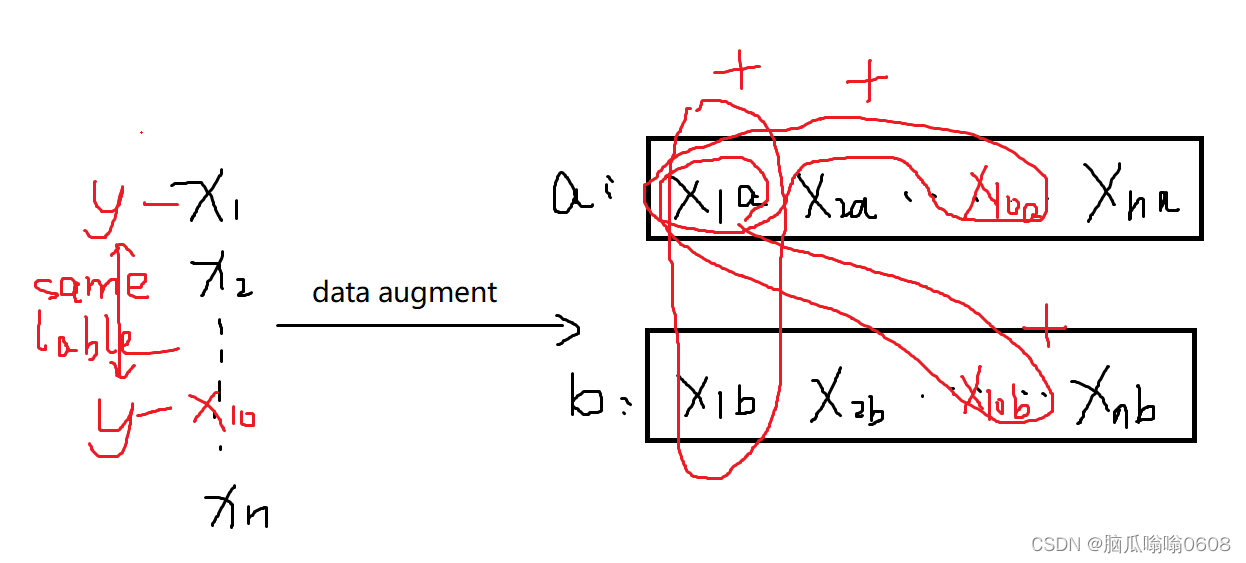
tips:本文的cross-view我个人理解就是对同一张图片用不同的data augmentation后得到的图片彼此属于不同view。
1 Introduction
👇图是overview of their framework

- In this work, we propose a contrastive learning-based framework that seamlessly integrates contrastive learning into the pre-training and meta-training stages to tackle the FSL problem.
- training stage:两种contrastive loss function,分别是s(supervised)和ss(self-supervised)的,考虑了global和local的信息。
- meta-learning stage:a cross-view episodic training(CVET) mechanism来提取可概括的表征,并用nearest-centroid classification和inter-instance distance scaling,对不同数据增强方式下的Q1和Q2分别计算其与原型之间的相似度(具体看framework)
- baseline:FEAT
- preliminary:经典的meta-learning问题setting,不再赘述
2 Pre-Training
- 通过framework图可知,pre-training阶段总共有4个loss function:
1️⃣LCE是分类器的交叉熵损失函数
2️⃣Global self-supervised contrastive loss
(1)目标:“aims to enhance the similarity between the views of the same image, while reducing the similarity between the views of different images”。
(2)equation:
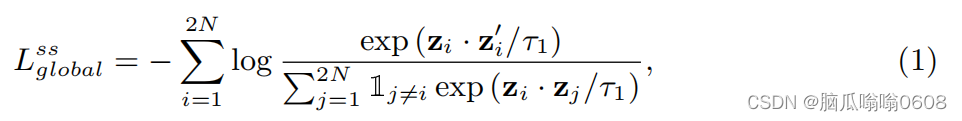
其中
(3)说明:
①2N表示training dataset的N张images使用某两种数据增强方式后得到的图片数。hi表示提取出的图像特征经过GAP(global average pooling)后得到的global feature。zi表示样本xi使用一种数据增强方式后得到的projected vector,zi’表示另一种数据增强方式后得到的projected vector。因此分子表示positive pair,分母表示negative pair。τ表示temperature parameter。
②同一个样本xi使用两种数据增强方式后的得到样本互为positive pair,它俩与其余2N-2的样本为negative pair。
③这个损失函数的值要小,则分子要大、分母要小,即正样本对之间的similarity要越大越好、负样本对之间的similarity越小越好。
3️⃣Local self-supervised contrastive loss
(1)目标:“equation(1) might ignore some local discriminative information in feature map xi-hat which could be beneficial in meta-testing.”“boost the robustness and generalizability of the representations”
(2)equation:
包含两个module,map-map module局部对局部和map-vector module局部对全局。
图(a)中,xa-hat、xb-hat分别表示两种数据增强方式后得到的样本的特征;三个f函数表示spatial projection head,通过这些头map就被投影成HW×D的vector了。然后分别将a与b的map相互对齐(即图中交叉的线头)、然后softmax,计算相似度,这些相似度将会用于求loss。
图(b)中,ub表示map(DxHW),za表示特征投影后得到的vector(Dx1),传入的特征分别对应于两种数据增强方式得到的map和vector。然后对map的每个像素位置(i,j)(大小为1xD)与za做点积得到的结果再计算vector-map相似度、然后计算loss。
最后,Local self-supervised contrastive loss等于这两个module的loss之和。

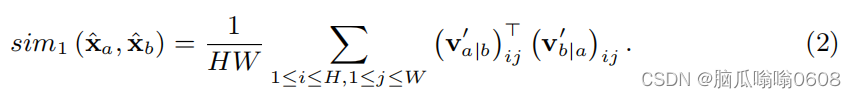
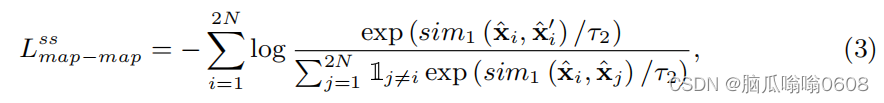
上式中分子是positive pair,分母是negative pair。
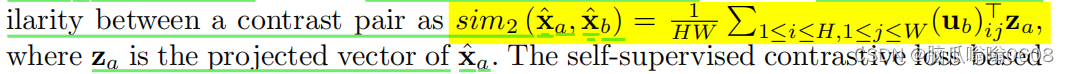
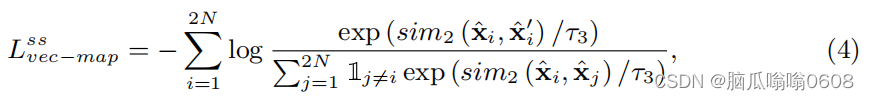
上式中分子是positive pair,分母是negative pair。
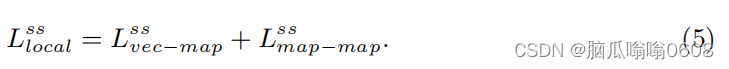
4️⃣Global supervised contrastive loss
(1)目标:“To exploit the correlations among individual instances and the correlations among different instances from the same category”
(2)equation:
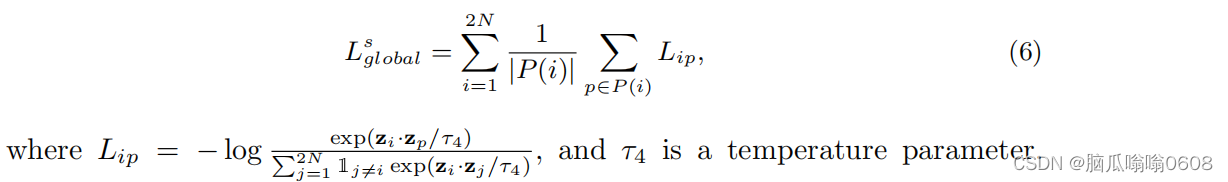
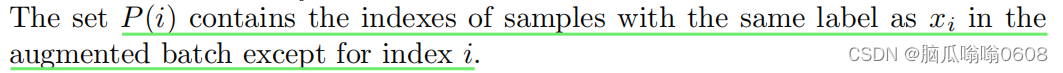
通过作者的目标和原paper讲解,我们知道,这里的positive pair与前几个式子不太一样,这里的正样本对是被扩充了的。原来只有同一个样本被数据增强后得到的样本互为正样本对,现在不仅如此、有相同标签的也是正样本对。
- pre-training的总LOSS如下👇
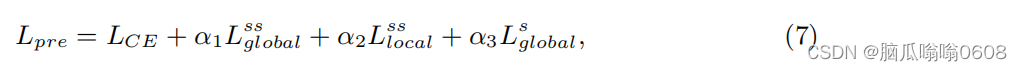
where LCE is the CE loss, and α1, α2 and α3 are balance scalars.
3 Meta-Training
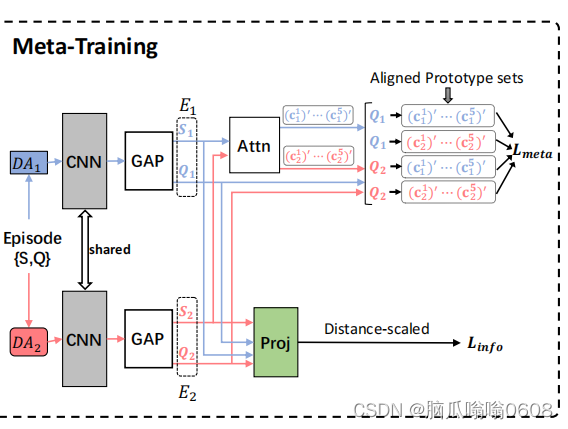
1️⃣Cross-view Episodic Training
E表示Episode的缩写。将E视作共享上下文(shared context),将two augmented episodes视作E的两个views(看图把这两个view的特征共同输入module中去了所以叫cross-view吧)。经过GAP后,得到全局向量hi,然后计算两个集合S1和S2中每个类的原型、送入Attn模块加工得到处理后的原型(注意只有support里面的样本会被计算)。用下式计算query集合中的每个样本的概率分布
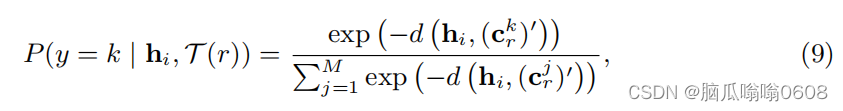
τ是数据增强方式的分布,d是欧氏距离,然后再计算下面的损失。m和n可以取1或2,就如图上所示计算L11 L12 L21 L22的损失
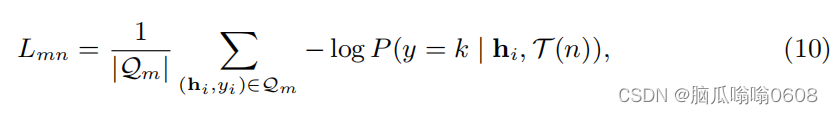
最后the cross-view classification loss as follows:

2️⃣Distance-scaled Contrastive Loss
如图所示,投影后得到的projected vector,然后用下面的式子计算得到每个class的原型。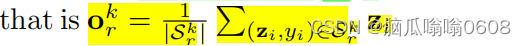
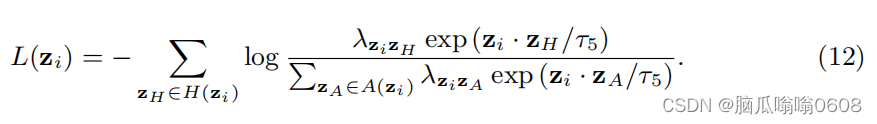
注意,求原型的时候,用的是E1和E2所有数据,在(12)中用的是Q1和Q2中的数据。式子中zi和zH互为正样本对,这里的正样本对也是扩充了的。zA是另一个样本的集合,新增了原型。

3️⃣total loss
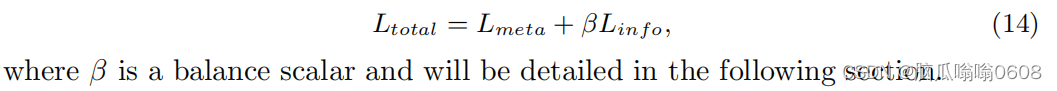
4 Experiment
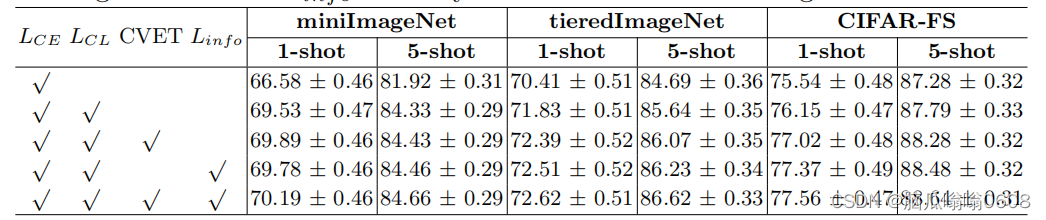
baseline是FEAT。在3个数据集上进行了实验:miniImageNet dataset、tieredImageNet、CIFAR-FS。table就不放了,看原文。然后还进行了消融实验证明每个loss function的功能。

5 Conclusion
这篇paper的损失函数很多,主要的创新点是将对比学习更好融合进two-stages的模型中去。每个损失作者都在讲解具体公式前说了下aim to……,我的阅读paper量还不够所以觉得太绕了、说不清,只能通过ablation实验明白每个loss的作用。















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









