







- 【小记】下采样和池化的区别:
池化的神解释:
池化 = 涨水
池化的过程 = 升高水位(扩大矩阵网格)
池化的目的是为了得到物体的边缘形状。可以想象水要了解山立体的形状,水位低时得出山脚的形状,水位中等时得出山腰的形状,水位高时得出山顶的形状,三点就可以大致描出山的简笔画。而卷积的过程是区分哪里是水,哪里是山。 对于网络结构而言,上面的层看下面的层经过 pooling 后传上来的特征图,就好像在太空上俯瞰地球,看到的只有山脊和雪峰。这即是对特征进行宏观上的进一步抽象。
池化方法:
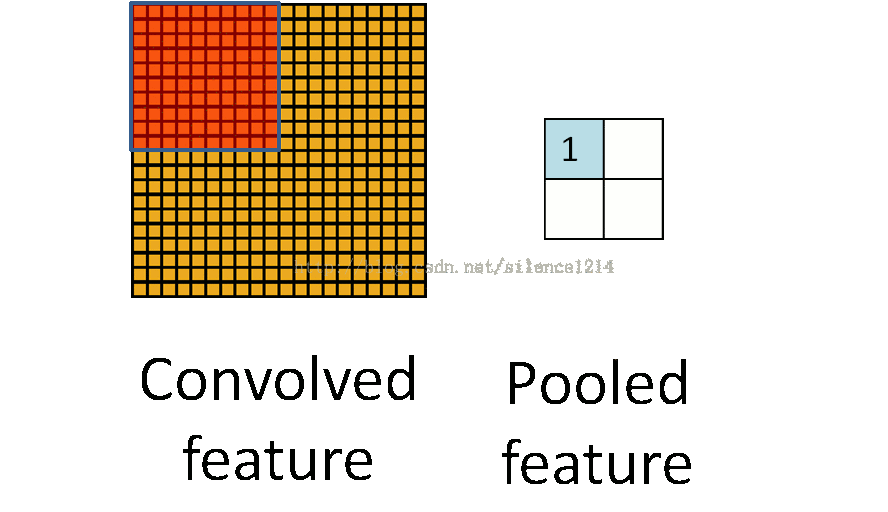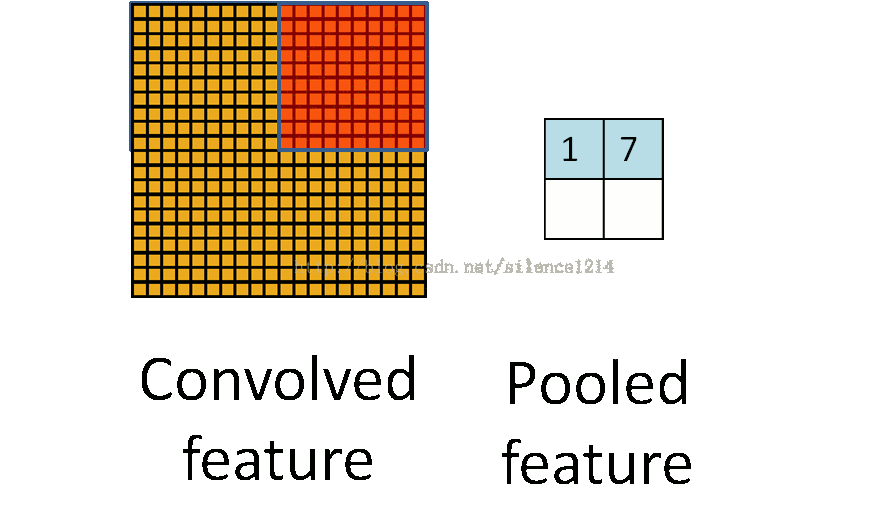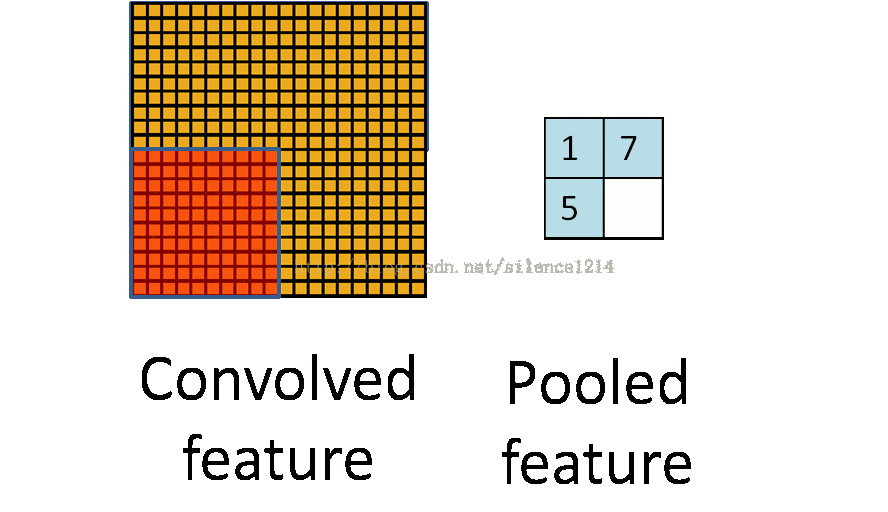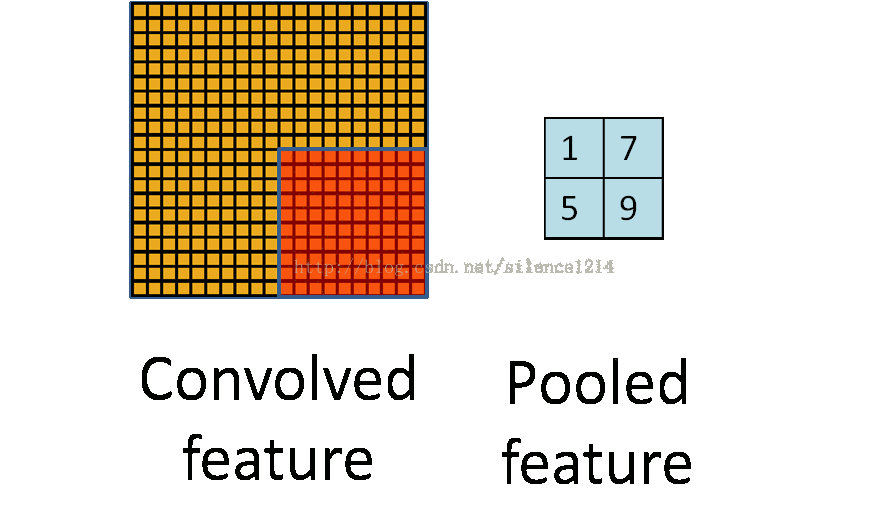
1、max-pooling:对邻域内特征点取最大值;
2、mean-pooling:对邻域内特征点求平均
池化的作用:
1、降维,减少网络要学习的参数数量;
2、防止过拟合;
3、扩大感受野;
4、实现不变性(平移、旋转、尺度不变性) - 卷积和池化的区别: 池化(pooling),也即降采样(subsample),降低数据的大小。
设输入的为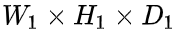 ,池化层的大小是
,池化层的大小是 ,stride步为
,stride步为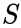 ,输出的矩阵的大小是
,输出的矩阵的大小是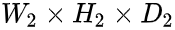 ,则:
,则: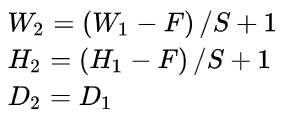
- 卷积:
池化: - Relu激活函数的作用:一言以蔽之,其实,relu函数的作用就是增加了神经网络各层之间的非线性关系,否则,如果没有激活函数,层与层之间是简单的线性关系,每层都相当于矩阵相乘,这样怎么能够完成我们需要神经网络完成的复杂任务。ReLU的有效性体现在两个方面:1、更加有效率的梯度下降以及反向传播:避免了梯度爆炸和梯度消失问题;2、简化计算过程,加快训练速度。
- 深度学习VGG模型核心拆解,AlexNet和VGGNet,看到这,让我不由得先去看看CNN网络。
- CNN(卷积神经网络)入门,
- CNN基础知识——卷积(Convolution)、填充(Padding)、步长(Stride)
深度学习里面所谓的卷积运算(Convolution),其实它被称为互相关(cross-correlation)运算:将图像矩阵中,从左到右,由上到下,取与滤波器同等大小的一部分,每一部分中的值与滤波器中的值对应相乘后求和,最后的结果组成一个矩阵,其中没有对核进行翻转。
我们以灰度图像为例进行讲解:从一个小小的权重矩阵,也就是卷积核(kernel)开始,让它逐步在二维输入数据上“扫描”。卷积核“滑动”的同时,计算权重矩阵和扫描所得的数据矩阵的乘积,然后把结果汇总成一个输出像素。见下图。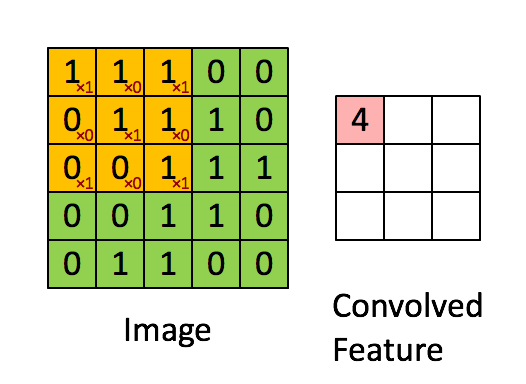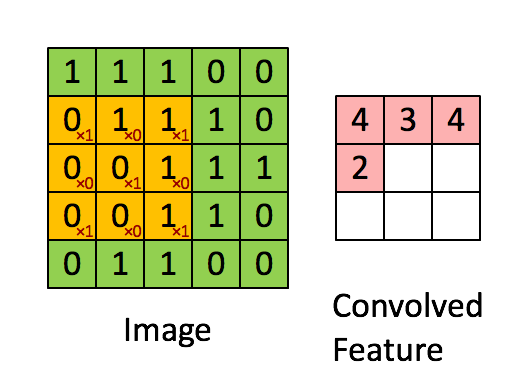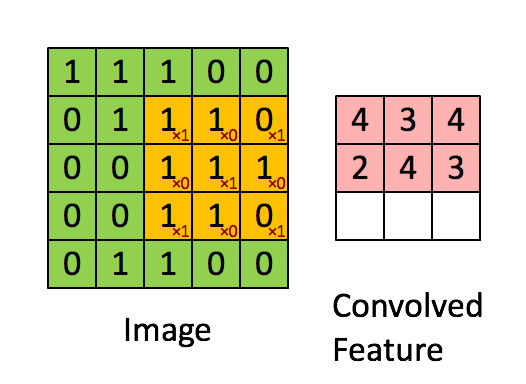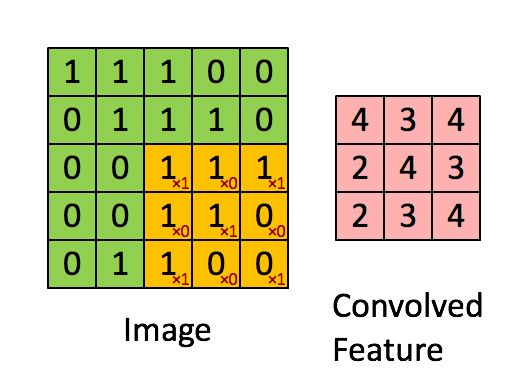
有时时我们还希望输入和输出的大小应该保持一致。为解决这个问题,可以在进行卷积操作前,对原矩阵进行边界填充(Padding),也就是在矩阵的边界上填充一些值,以增加矩阵的大小,通常都用“0”来进行填充的。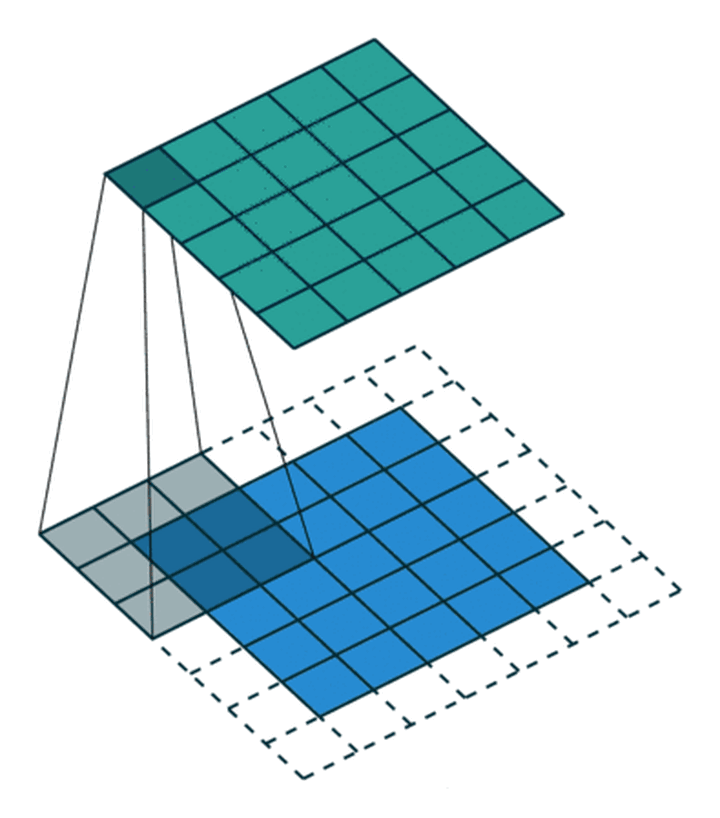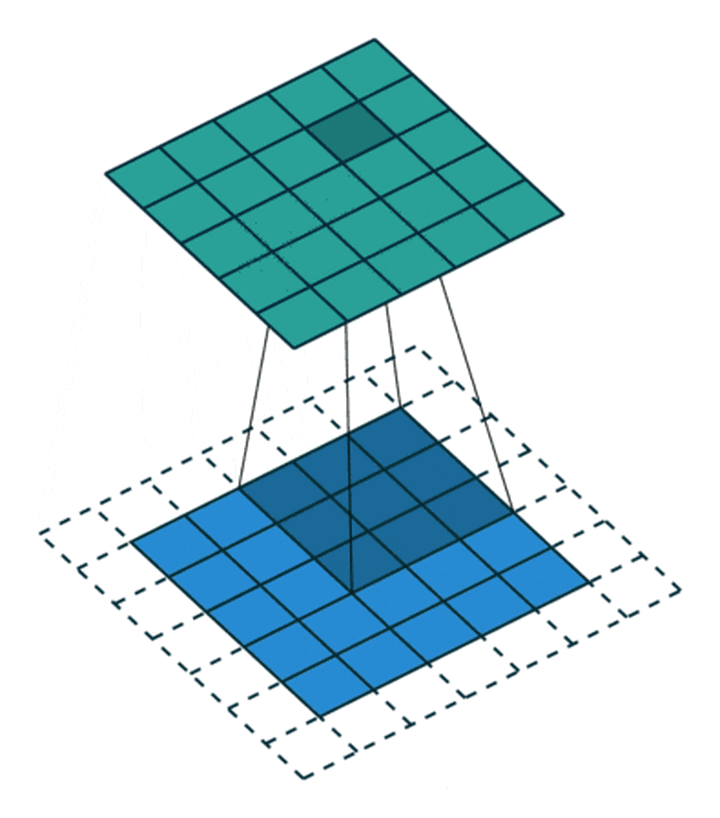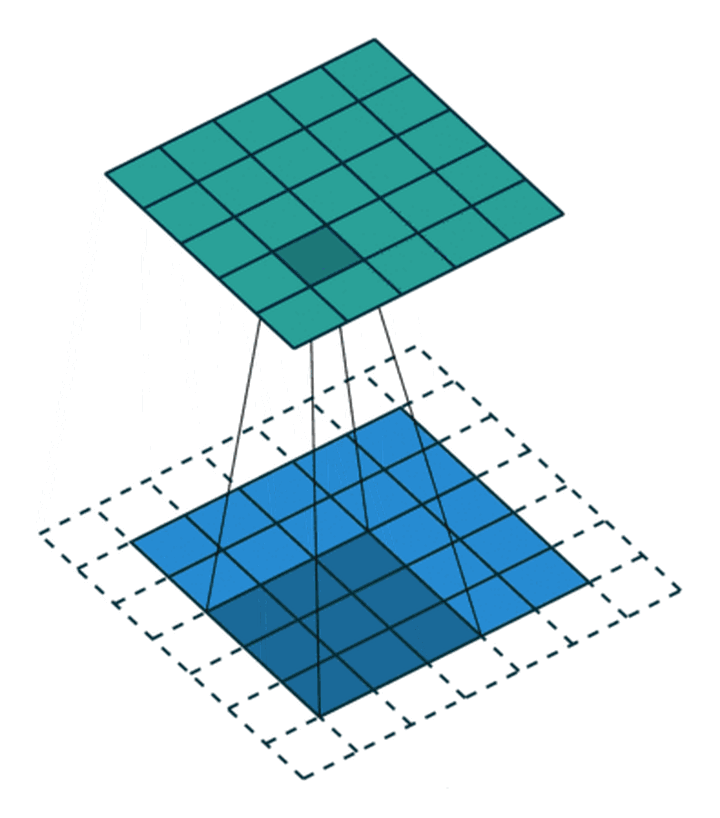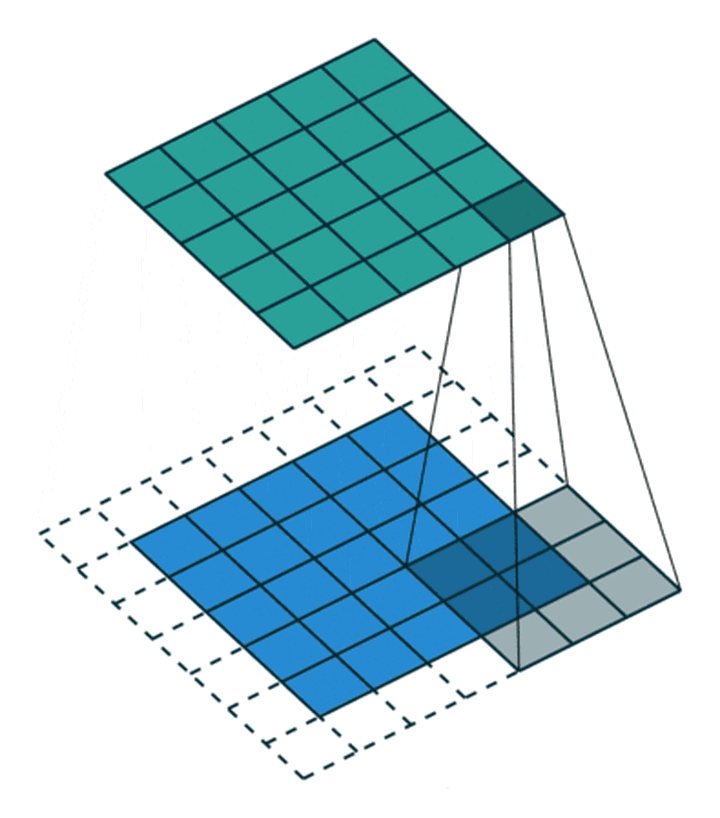
卷积过程中,有时需要通过padding来避免信息损失,有时也要在卷积时通过设置的步长(Stride)来压缩一部分信息,或者使输出的尺寸小于输入的尺寸。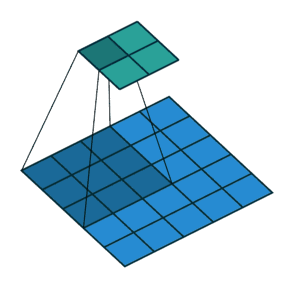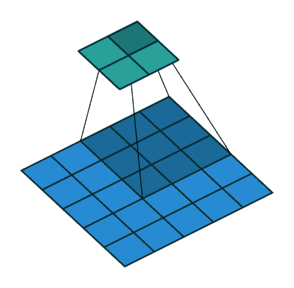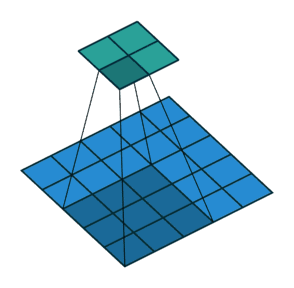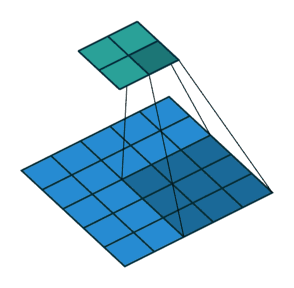
Stride的作用:是成倍缩小尺寸,而这个参数的值就是缩小的具体倍数,比如步幅为2,输出就是输入的1/2;步幅为3,输出就是输入的1/3。以此类推。见下图。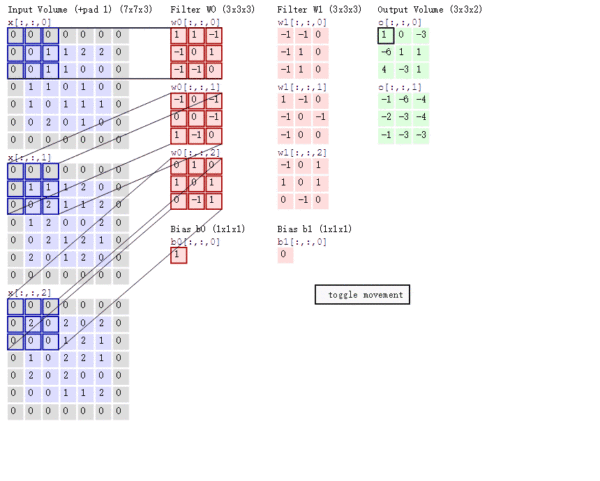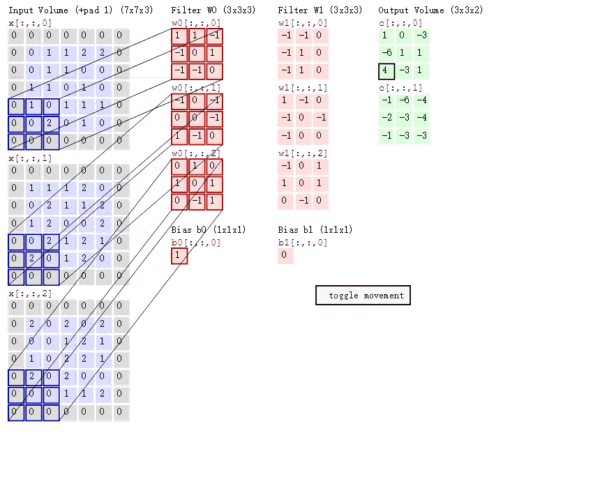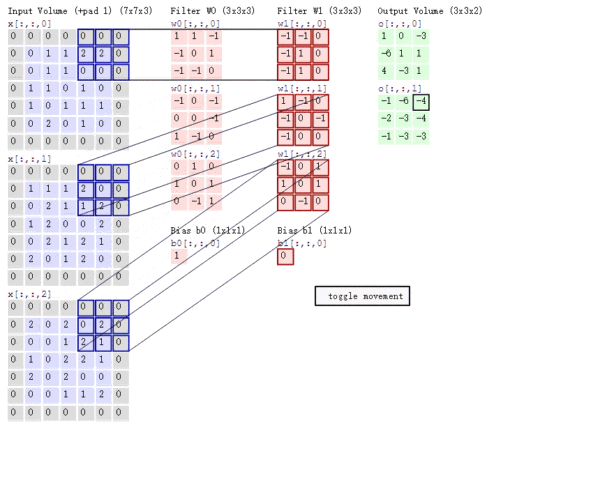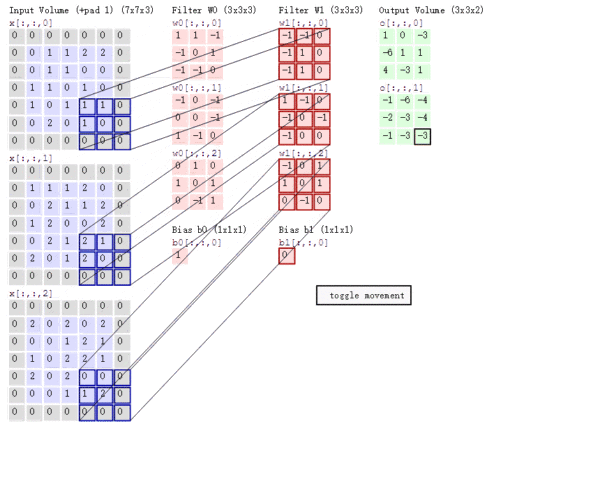
- 【卷积核的大小一般为奇数*奇数】 1*1,3*3,5*5,7*7都是最常见的。这是为什么呢?为什么没有偶数*偶数?
(1)更容易padding
在卷积时,我们有时候需要卷积前后的尺寸不变。这时候我们就需要用到padding。假设图像的大小,也就是被卷积对象的大小为n*n,卷积核大小为k*k,padding的幅度设为(k-1)/2时,卷积后的输出就为(n-k+2*((k-1)/2))/1+1=n,即卷积输出为n*n,保证了卷积前后尺寸不变。但是如果k是偶数的话,(k-1)/2就不是整数了。(2)更容易找到卷积锚点
在CNN中,进行卷积操作时一般会以卷积核模块的一个位置为基准进行滑动,这个基准通常就是卷积核模块的中心。若卷积核为奇数,卷积锚点很好找,自然就是卷积模块中心,但如果卷积核是偶数,这时候就没有办法确定了,让谁是锚点似乎都不怎么好。 -
【卷积的计算公式】
输入图片的尺寸:一般用
 表示输入的image大小。
表示输入的image大小。 卷积核的大小:一般用
 表示卷积核的大小。
表示卷积核的大小。 填充(Padding):一般用
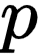 来表示填充大小。
来表示填充大小。 步长(Stride):一般用
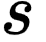 来表示步长大小。
来表示步长大小。 输出图片的尺寸:一般用
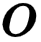 来表示。
来表示。
如果已知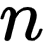 、
、 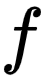 、
、 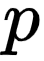 、 可以求得
、 可以求得 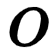 ,计算公式如下:
,计算公式如下: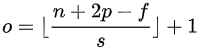
其中"
 "是向下取整符号,用于结果不是整数时进行向下取整。
"是向下取整符号,用于结果不是整数时进行向下取整。 -
【多通道卷积】
上述例子都只包含一个输入通道。实际上,大多数输入图像都有 RGB 3个通道。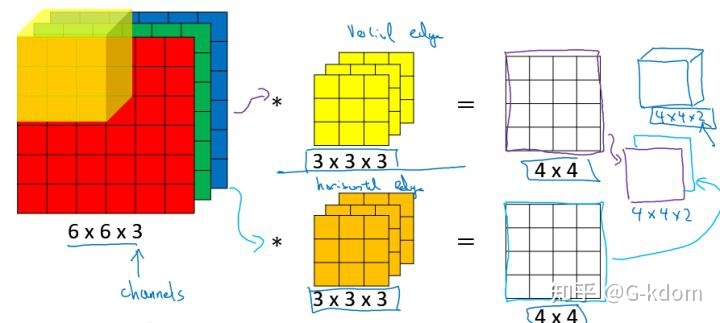
这里就要涉及到“卷积核”和“filter”这两个术语的区别。在只有一个通道的情况下,“卷积核”就相当于“filter”,这两个概念是可以互换的。但在一般情况下,它们是两个完全不同的概念。每个“filter”实际上恰好是“卷积核”的一个集合,在当前层,每个通道都对应一个卷积核,且这个卷积核是独一无二的。
多通道卷积的计算过程:将矩阵与滤波器对应的每一个通道进行卷积运算,最后相加,形成一个单通道输出,加上偏置项后,我们得到了一个最终的单通道输出。如果存在多个filter,这时我们可以把这些最终的单通道输出组合成一个总输出。
这里我们还需要注意一些问题——滤波器的通道数、输出特征图的通道数。
某一层滤波器的通道数 = 上一层特征图的通道数。如上图所示,我们输入一张
 的RGB图片,那么滤波器(
的RGB图片,那么滤波器( 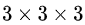 )也要有三个通道。
)也要有三个通道。 某一层输出特征图的通道数 = 当前层滤波器的个数。如上图所示,当只有一个filter时,输出特征图(
 )的通道数为1;当有2个filter时,输出特征图(
)的通道数为1;当有2个filter时,输出特征图(  )的通道数为2。
)的通道数为2。 -
分类数据集: fenleiCIFAR-10数据集说明、说明链接2
CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( a叩lane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练圄片和 10000 张测试图片。 CIFAR-10 的图片样例如图所示。
-
深度神经网络(Deep Neural Networks,DNN),参考文章:深度神经网络(DNN)
虽然DNN看起来很复杂,但是从小的局部模型来说,还是和感知机一样,即一个线性关系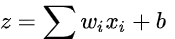 加上一个激活函数
加上一个激活函数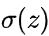
-
CNN网络介绍 ,参考一篇很好的文章《CNN网络介绍》
-
CNN(卷积神经网络)入门,参考文章《CNN(卷积神经网络)入门》
-
全连接层到底什么用?我来谈三点。
1、全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽(注1)。
2、目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling,GAP)取代FC来融合学到的深度特征,最后仍用softmax等损失函数作为网络目标函数来指导学习过程。需要指出的是,用GAP替代FC的网络通常有较好的预测性能。
3、在FC越来越不被看好的当下,我们近期的研究(In Defense of Fully Connected Layers in Visual Representation Transfer)发现,FC可在模型表示能力迁移过程中充当“防火墙”的作用。具体来讲,假设在ImageNet上预训练得到的模型为,则ImageNet可视为源域(迁移学习中的source domain)。微调(fine tuning)是深度学习领域最常用的迁移学习技术。针对微调,若目标域(target domain)中的图像与源域中图像差异巨大(如相比ImageNet,目标域图像不是物体为中心的图像,而是风景照,见下图),不含FC的网络微调后的结果要差于含FC的网络。因此FC可视作模型表示能力的“防火墙”,特别是在源域与目标域差异较大的情况下,FC可保持较大的模型capacity从而保证模型表示能力的迁移。(冗余的参数并不一无是处。)
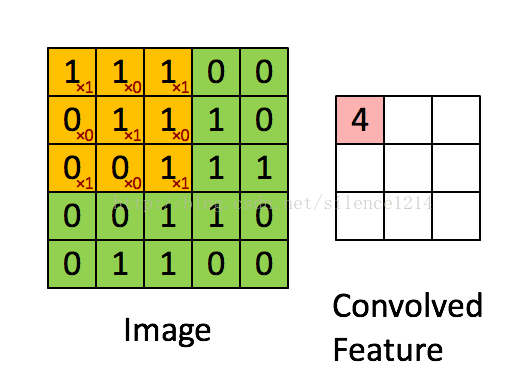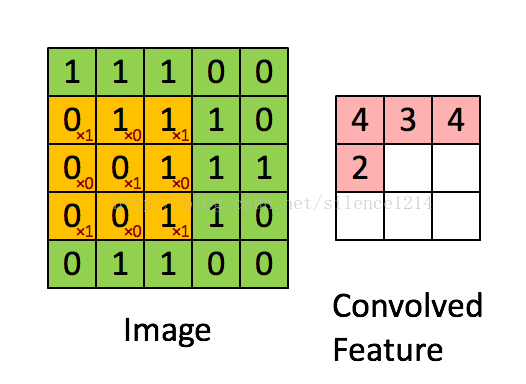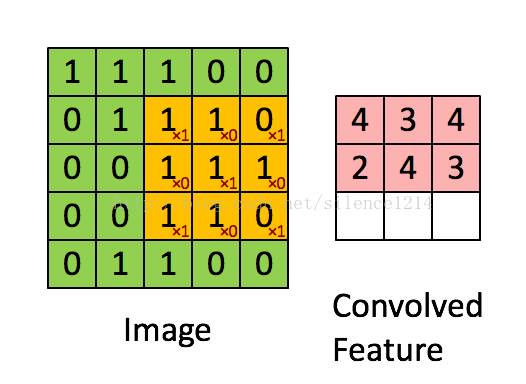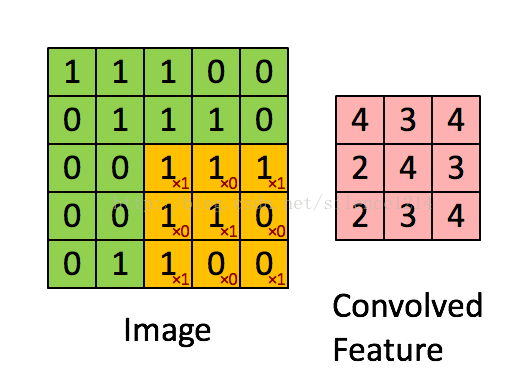














 4608
4608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









