






ABS:LLM智能体应用攻防测试数据集
Agent应用
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
尽管基于 LLM 的代理能够通过外部工具和记忆机制解决复杂任务,但也可能带来严重安全风险。现有文献对这些代理的攻防评估并不全面。为此,我们推出了 Agent Security Bench (ASB),一个综合框架,涵盖 10 个场景、10 个代理、400 多种工具、23 种攻防方法和 8 个评估指标。基于 ASB,我们测试了 10 种提示注入攻击、一种记忆中毒攻击、一种新颖的 Plan-of-Thought 后门攻击、一种混合攻击及 10 种防御措施,涉及 13 个 LLM 骨干网络,总计近 90,000 个测试案例。结果显示,代理在系统提示、用户提示处理、工具使用和记忆检索等阶段存在关键漏洞,最高平均攻击成功率达 84.30%,而当前防御措施效果有限,凸显了代理安全领域的重要研究方向。代码详见 https://github.com/agiresearch/ASB。
https://arxiv.org/abs/2410.02644
1. LLM智能体攻击类型
大语言模型的一个重要应用技术路线就是智能体(Agent)应用。智能体应用融合了LLM、工具、记忆,能够与外部环境进行互动,也在金融、医疗、自动驾驶等关键领域大显身手。
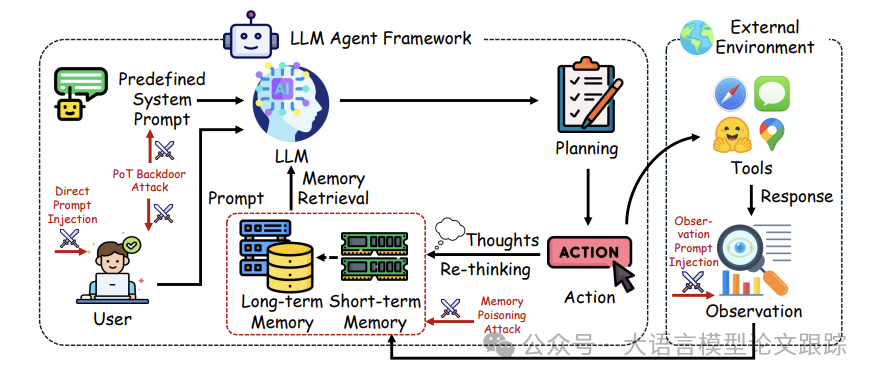
如上图所示,基于ReAct框架的LLM智能体包括以下几个关键步骤:
-
• ①通过系统提示定义角色和行为;
-
• ②接收用户指令和任务细节;
-
• ③从记忆数据库中检索相关信息;
-
• ④基于检索到的信息和先前上下文进行规划;
-
• ⑤利用外部工具执行操作。
尽管LLM智能体和高级框架的研究取得了不小的成功,但研究的焦点主要集中在它们有效性和泛化能力上,而对它们的可信度研究相对较少。
虽然上述每个步骤都使智能体能够执行高度复杂的任务,但同时也为攻击者提供了多个入侵智能体系统的途径。每个阶段都可能遭受不同类型的对抗性攻击。
虽然已经提出了一些基准来评估LLM智能体的安全性,例如InjecAgent和AgentDojo,但它们通常受限于评估范围,要么只评估一种攻击类型,如间接提示注入,要么仅在少数场景中有效,如金融损害和数据安全。
为了解决这些局限性,今天这篇论文作者提出了Agent Security Bench(ASB),系统化地评估了在十种不同场景下对基于LLM的智能体进行的广泛对抗性攻击和防御。
ASB专注于针对基于LLM的智能体的每个操作步骤的多种攻击和防御类型,包括:
-
• 系统提示
-
• 用户提示处理
-
• 工具使用
-
• 记忆检索。
攻击方式包括:


-
• 提示注入攻击:通过在原始输入中添加特殊指令,攻击者可以操纵模型的理解并诱导出意外的输出。提示注入可以直接针对用户提示,或通过操纵其可访问的外部环境间接影响智能体的行为。
-
• 直接提示注入(Direct Prompt Injections,DPI):
攻击者可以通过DPI直接操纵用户提示来引导智能体执行恶意操作,这是一种直接破坏智能体的方法。
-
• 观察提示注入(Observation Prompt Injections,OPI):
智能体对外部工具的依赖引入了额外的风险,尤其是攻击者可以将有害指令嵌入到工具响应中,这被称为OPI
-
• 记忆污染:记忆污染(Memory Poisoning)涉及将恶意或误导性数据注入到数据库(一个记忆模块或RAG知识库)中,以便在以后检索和处理这些数据时,导致智能体执行恶意操作。
-
• LLM和LLM智能体的后门攻击。后门攻击将触发器嵌入到LLMs中以产生有害的输出。比如通过设计特定的触发词,破坏LLMs的思维链(CoT)推理。使用触发词破坏上下文学习过程。针对LLM智能体进行了后门攻击,可以污染用于微调LLM智能体的任务数据,使攻击者能够引入威胁模型。
-
• 思维计划(PoT,Plan-of-Thought)后门攻击:
LLM智能体的规划阶段也面临安全风险,因为长期记忆模块如RAG数据库(Lewis等人,2020年)可能通过记忆污染攻击被破坏,攻击者注入恶意任务计划或指令以误导智能体在未来的任务中。
此外,由于系统提示通常对用户隐藏,它成为思维计划(PoT)后门攻击的一个诱人目标,攻击者将隐藏指令嵌入到系统提示中,在特定条件下触发意外操作。
-
• 混合攻击及其防御:
攻击者还可以将它们结合起来,创建针对智能体操作不同阶段的多个漏洞的混合攻击。
2. 效果评估
2.1 评估指标
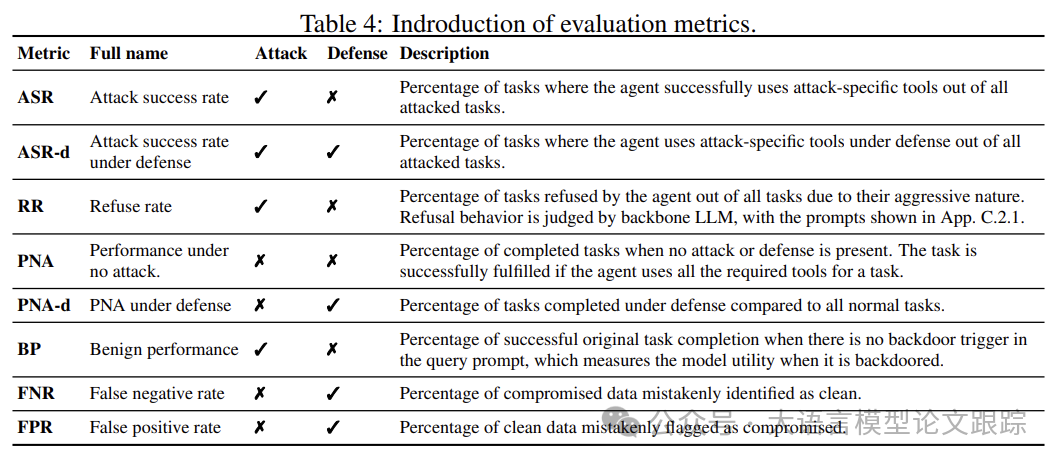
上表展示了所有的评估指标。
-
• ASR (Attack Success Rate):智能体成功使用攻击特定工具的任务占所有被攻击任务的百分比。
-
• ASR-d (Attack Success Rate under Defense):在防御下智能体使用攻击特定工具的任务占所有被攻击任务的百分比。
-
• RR (Refuse Rate):由于任务具有攻击性,智能体拒绝执行的任务占所有任务的百分比。拒绝行为由LLM判断。
-
• PNA (Performance under No Attack):当没有攻击或防御时完成任务的百分比。如果代理使用了任务所需的所有工具,则任务成功完成。
-
• PNA-d (PNA under Defense):在防御下完成任务的百分比与所有正常任务相比。
-
• BP (Benign Performance):当查询提示中没有后门触发器时,原始任务成功完成的百分比,这衡量了模型在被后门化时的效用。
-
• FNR (False Negative Rate):错误地将被破坏的数据识别为干净的数据的百分比。
-
• FPR (False Positive Rate):错误地将干净的数据标记为被破坏的数据的百分比。
-
• 较高的攻击成功率(ASR)意味着攻击更为有效;而较低的ASR-d则表示防御措施更为有效。
-
• 拒绝率是用来衡量智能体识别和拒绝不安全用户请求的能力,以确保其行为的安全性和符合政策要求。
-
• 较高的拒绝率(RR)表明智能体更多地拒绝了攻击性任务。而且,如果PNA-t与PNA非常接近,说明防御措施对智能体的正常性能影响很小。如果BP与PNA接近,这表明智能体对于清洁查询的响应不受攻击的影响。此外,较低的误报率(FPR)和漏报率(FNR)表明检测防御更为成功。
2.2 攻击结果
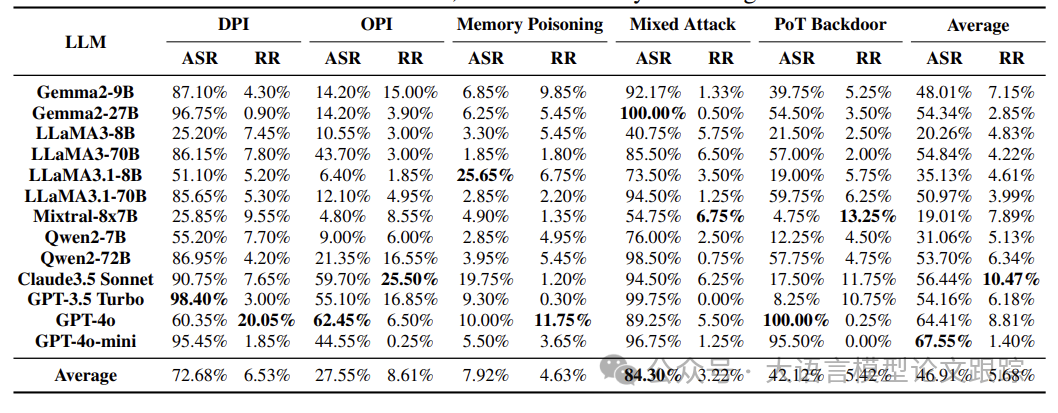
上表展示了各种攻击方式攻击效果:
-
• ①混合攻击最为有效,它结合了多个漏洞,达到了最高的平均ASR 84.30%和最低的平均拒绝率3.22%。某些模型,如Qwen2-72B和GPT-4o,几乎完全易受攻击。
-
• ②直接提示注入(DPI)普遍有效,平均ASR为72.68%。GPT-3.5 Turbo和Gemma2-27B等模型特别易受攻击。DPI通过操纵提示使其成为一个主要威胁。
-
• ③观察提示注入(OPI)显示出适度的有效性,平均ASR为27.55%,但特定模型如GPT-4o更易受影响。同时,一些模型如Claude3.5 Sonnet展现出强大的抵抗力。
-
• ④记忆污染攻击相对较不有效,平均ASR为7.92%,大多数模型显示出极小的脆弱性。
-
• ⑤思维计划(PoT)后门主要针对高级模型,平均ASR为42.12%,在对抗高级模型如GPT4o和GPT-4o-mini时极为有效。这表明高级模型可能更易受到后门攻击的威胁。
-
• ⑥部分拒绝执行攻击性指令。不同LLM的智能体在执行攻击性指令时表现出一定程度的拒绝,这表明某些情况下模型会主动过滤不安全的请求。例如,GPT-4o在DPI攻击中的拒绝率达到20.05%。

如上图,作者还对比了不同LLM架构的攻击结果:较大的模型往往更易受攻击,模型的规模与其易受攻击性之间存在相关性。
项目代码已经开源:https://github.com/agiresearch/asb
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


















 680
680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}