







转载 https://blog.csdn.net/u013007900/article/details/78049587
参考:
目录
0 背景
朴素贝叶斯(Naive Bayes)是一种简单的分类算法,它的经典应用案例为人所熟知:文本分类(如垃圾邮件过滤)。本文把重点放在理论推导和三种常用模型。
1 理论基础
朴素贝叶斯算法是基于贝叶斯定理与特征条件独立假设的分类方法。
1.1 贝叶斯定理
贝叶斯定理便是基于条件概率,通过P(A|B)来求P(B|A):

上式中的分母P(A),可以根据全概率公式分解为:

其中P(B|A)为posterior,P(B)为priori,P(A|B)为likelihood,P(A)为evidence。朴素贝叶斯通过Maximum a-posterior(MAP)。
1.2 特征条件独立假设


2. 三种常见的模型
2.1 多项式模型
当特征是离散的时候,使用多项式模型。
2.1.1 实例1
描述:训练集统计结果(指定统计词频):
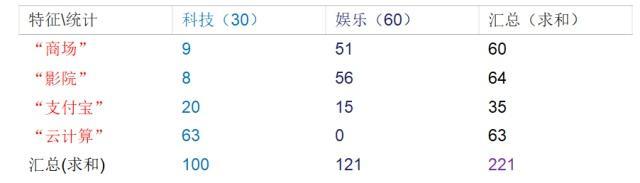
现有一篇被预测文档:出现了影院、支付宝、云计算,计算属于科技、娱乐的类别概率?
实例公式:
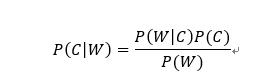
注:w为给定文档的特征值(频数统计,预测文档提供),c为文档类别
公式可以理解为:
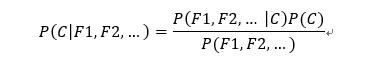
其中C可以是不同类别
P(C):每个文档类别的概率(某类别文档数/总文档数)
P(W|C):给定类别下特征(被预测文档中出现的词)的概率
计算方法:P(F1│C)=Ni/N(训练文档中去计算)
Ni为所属C类别下的F1词出现的次数
N为所属C类别下的所有词出现的次数和
P(F1,F2,…) 预测文档中的每个词的概率(计算时可以忽略)
分析的结果

从上面的例子我们得到娱乐概率为0,这是不合理的。解决方法:拉普拉斯平滑系数
2.1.2 平滑系数

2.1.3 实例2
有如下训练数据,15个样本,2维特征 ,种类别-1,1。给定测试样本,判断其类别。

解答如下:
运用多项式模型,令α=1,n=2
- 计算先验概率
- 计算各种条件概率
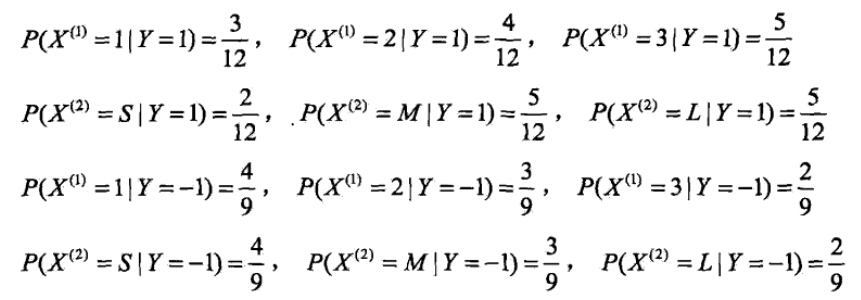
- 对于给定的
,计算:
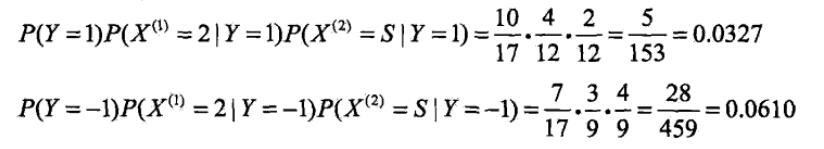
由此可以判定y=-1。
2.1.4 实例3
给定一组分好类的文本训练数据(单词重复出现),如下:
| docId | doc | 类别 In c=China? |
| 1 | Chinese Beijing Chinese | yes |
| 2 | Chinese Chinese Shanghai | yes |
| 3 | Chinese Macao | yes |
| 4 | Tokyo Japan Chinese | no |
给定一个新样本Chinese Chinese Chinese Tokyo Japan,对其进行分类。该文本用属性向量表示为d=(Chinese, Chinese, Chinese, Tokyo, Japan),类别集合为Y={yes, no}。
类yes下总共有8个单词,类no下总共有3个单词,训练样本单词总数为11,因此P(yes)=8/11, P(no)=3/11。类条件概率计算如下: (平滑:a=1,n=6)
分母中的8,是指yes类别下textc的长度,也即训练样本的单词总数,6是指训练样本有Chinese,Beijing,Shanghai, Macao, Tokyo, Japan 共6个单词,3是指no类下共有3个单词。
有了以上类条件概率,开始计算后验概率:
比较大小,即可知道这个文档属于类别china。
2.2 高斯模型
当特征是连续变量的时候,运用多项式模型就会导致很多(不做平滑的情况下),此时即使做平滑,所得到的条件概率也难以描述真实情况。所以处理连续的特征变量,应该采用高斯模型。
下面是一组人类身体特征的统计资料。
| 性别 | 身高(英尺) | 体重(磅) | 脚掌(英寸) |
|---|---|---|---|
| 男 | 6 | 180 | 12 |
| 男 | 5.92 | 190 | 11 |
| 男 | 5.58 | 170 | 12 |
| 男 | 5.92 | 165 | 10 |
| 女 | 5 | 100 | 6 |
| 女 | 5.5 | 150 | 8 |
| 女 | 5.42 | 130 | 7 |
| 女 | 5.75 | 150 | 9 |
已知某人身高6英尺、体重130磅,脚掌8英寸,请问该人是男是女?
根据朴素贝叶斯分类器,计算下面这个式子的值。
P(身高|性别) x P(体重|性别) x P(脚掌|性别) x P(性别)
这里的困难在于,由于身高、体重、脚掌都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。怎么办?
这时,可以假设男性和女性的身高、体重、脚掌都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数。有了密度函数,就可以把值代入,算出某一点的密度函数的值。
比如,男性的身高是均值5.855、方差0.035的正态分布。所以,男性的身高为6英尺的概率的相对值等于1.5789(大于1并没有关系,因为这里是密度函数的值,只用来反映各个值的相对可能性)。
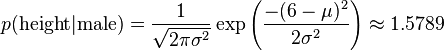
对于脚掌和体重同样可以计算其均值与方差。有了这些数据以后,就可以计算性别的分类了
P(身高=6|男) x P(体重=130|男) x P(脚掌=8|男) x P(男) = 6.1984 x e-9
P(身高=6|女) x P(体重=130|女) x P(脚掌=8|女) x P(女) = 5.3778 x e-4 (判断该人为女性。)
总结
高斯模型 假设 每一维特征都服从高斯分布(正态分布):
表示类别为
的样本中,第i维特征的均值。
表示类别为
的样本中,第i维特征的方差。
2.3 伯努利模型
与多项式模型一样,伯努利模型适用于离散特征的情况,所不同的是,伯努利模型中每个特征的取值只能是1和0(以文本分类为例,某个单词在文档中出现过,则其特征值为1,否则为0).
伯努利模型中,条件概率的计算方式是:
当特征值为1时,
当特征值为0时,
多项式模型和伯努利模型在文本分类中的应用比较:
设某文档d=(t1,t2,…,tk),tk是该文档中出现过的单词,允许重复,
在伯努利模型中:
P(c)= 类c下的样本总数/整个训练样本的总数
P(tk|c)=(类c下包含单词tk的样本数+a)/(类c下样本总数+a*n) (进行平滑)
在多项式模型中:
先验概率P(c)= 类c下单词总数/整个训练样本的单词总数
类条件概率P(tk|c)=(类c下单词tk在各个文档中出现过的次数之和+1)/(类c下单词总数+|V|)
|V|则表示训练样本包含多少种单词,(即抽取单词,单词出现多次,只算一个),
使用 2.1.4例子中的数据,模型换成伯努利模型。(a=1,n=2)
类yes下总共有3个文件,类no下有1个文件,训练样本文件总数为4,因此P(yes)=3/4
条件概率如下:
P(Chinese | yes)=(3+1)/(3+2)=4/5,
P(Japan | yes)=P(Tokyo | yes)=(0+1)/(3+2)=1/5
P(Beijing | yes)= P(Macao|yes)= P(Shanghai |yes)=(1+1)/(3+2)=2/5
P(Chinese|no=P(Japan|no)=P(Tokyo| no) =(1+1)/(1+2)=2/3
P(Beijing| no)= P(Macao| no)= P(Shanghai | no)=(0+1)/(1+2)=1/3
有了以上类条件概率,开始计算后验概率,
因此,这个文档不属于类别china。















 884
884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









