






本文作者系360奇舞团前端开发工程师
各位帅哥美女大家好!!!
俗话讲温故而知新,在AI技术日新月异的今天,很荣幸为大家分享一些AI相关的内容。也欢迎各位积极留言讨论。
梯度下降(Gradient Descent)是机器学习和深度学习中最常用的优化算法之一,通过迭代地调整参数来减少误差,梯度下降帮助模型从初始状态逐渐学习到数据中的复杂模式。在最近一年的研究论文中,梯度下降及其各种变体继续扮演着重要的角色,特别是在机器学习和深度学习领域。由于数据量和计算复杂度的不断增加,梯度下降算法,及其改进版本,得到了广泛的研究和应用。以下是从arxiv搜索关键字为“Gradient Descent 2024”得到的部分截图。
希望这篇文章能够帮助大家理解梯度下降的概念与思想,尽量以直观的形式来让大家了解梯度下降算法的过程和工作原理。我们开始吧!
1. 梯度是什么,为啥要下降?
梯度下降的核心思想是:在当前位置计算损失函数的梯度(即方向和大小),然后沿着梯度的反方向进行参数更新,以期望在迭代过程中损失函数的值逐渐减小。
想象你作为一个盲人,正在一座山上,你的目标是以最快的方式下山到达山谷。可很遗憾,你的眼睛并看不见,手中只有一根拐杖来探测前方的道路,所以你需要一步步地找到下山的最佳路线。在这种情况下,梯度下降就像是你每一步都用拐杖来感受前方的坡度,然后决定往哪个方向迈步,以便每一步都尽可能地朝山下走。

梯度下降主要用于解决那些可以通过迭代优化参数来最小化或最大化目标函数的问题。这些问题广泛存在于各类机器学习任务中,包括但不限于:
线性回归:
在房价预测模型中,可以使用线性回归来估计房价与房屋特征(如面积、房间数、位置等)之间的关系。通过梯度下降算法,可以找到最佳的权重参数,使得模型预测的价格与实际价格之间的均方误差最小。
分类任务:
在电子邮件分类(垃圾邮件与非垃圾邮件)中,逻辑回归常用来预测一个电子邮件是否为垃圾邮件。通过梯度下降调整模型参数,优化分类的准确性。
图像识别:
在图像识别任务中,如使用卷积神经网络(CNN)来识别和分类数字图像(例如,MNIST数据集中的手写数字)。梯度下降用于训练网络,通过最小化实际输出和预期输出之间的差异来不断调整网络中的权重和偏置。
深度学习:
在自然语言处理(NLP)中,比如使用BERT或Transformer模型进行文本情感分析。这些模型通常包含数百万甚至数十亿的参数,梯度下降算法用于在大量文本数据上训练这些模型,以优化它们的表现。
2. 数学基础先搞清
梯度下降的数学基础主要涉及计算和应用函数的梯度来寻找函数的最小值点。这个过程可以从以下几个核心概念理解:
梯度
梯度是一个向量,指明了多变量函数在给定点上增长最快的方向。在数学上,对于一个函数 𝑓(𝑥1,𝑥2,...,𝑥𝑛),其梯度由该函数对每个变量的偏导数组成,表示为:
梯度方向
梯度指示函数值增加最快的方向;相对应地,梯度的反方向则是函数值减少最快的方向。
参数更新规则
参数按以下规则更新,以实现函数值的减小:
其中:
表示模型参数。
是学习率,控制步长大小。
是参数 处的函数梯度。
3. 举个简单的例子
假设我们有一些二维数据点(𝑥𝑖,𝑦𝑖),这些点大致分布在一条二次曲线上。我们的目标是找到这条曲线的最佳拟合,使得数据点到直线的距离最小。我们可以用一个二次函数来拟合这些数据点:,是模型预测的输出,𝑤1,𝑤1和𝑤0分别是二次函数的三个系数。
我们希望最小化预测值与真实值之间的误差,可以使用均方误差(MSE)作为损失函数
对于每个参数 𝑤0,𝑤1,𝑤2,我们分别计算损失函数的偏导数:
𝑤0:
𝑤1:
𝑤2:
假设我们有以下数据点:(1,1),(2,4),(3,9),(4,16),(5,25)。这些点显然分布在一条二次曲线上。
初始化𝑤0=0,𝑤1=0,𝑤2=0,选择学习率𝛼=0.001
以下为代码实现:
import numpy as np
x_values = np.array([1, 2, 3, 4, 5])
y_values = np.array([1, 4, 9, 16, 25])
N = 5
w0, w1, w2 = 0, 0, 0
alpha = 0.001
iterations = 20
for _ in range(iterations):
# 计算预测值
y_pred = w2 * x_values**2 + w1 * x_values + w0
# 计算偏导
dL_dw0 = (2/N) * np.sum(y_pred - y_values)
dL_dw1 = (2/N) * np.sum((y_pred - y_values) * x_values)
dL_dw2 = (2/N) * np.sum((y_pred - y_values) * x_values**2)
# 更新参数
w0 -= alpha * dL_dw0
w1 -= alpha * dL_dw1
w2 -= alpha * dL_dw2
loss = np.mean((y_pred - y_values) ** 2)
print(f'Iteration {_+1}: w0={w0}, w1={w1}, w2={w2}, Loss={loss}')
print(f'Final Parameters: w0={w0}, w1={w1}, w2={w2}')第一次迭代:
更新参数:
通过多次迭代,𝑤0,𝑤1和𝑤2会逐渐接近真实的最优值。
| round | 𝑤0 | 𝑤1 | 𝑤2 |
|---|---|---|---|
| 1 | 0.011 | 0.042 | 0.154 |
| 2 | 0.022 | 0.090 | 0.392 |
| 3 | 0.035 | 0.143 | 0.621 |
| ... | ... | ... | ... |
| 10 | 0.051 | 0.214 | 0.945 |
| ... | ... | ... | ... |
| 100 | 0.026 | 0.181 | 0.957 |
我们把这些点在三维空间中画出来,就可以直观的看到,参数在不断地向损失值低的方向前进。
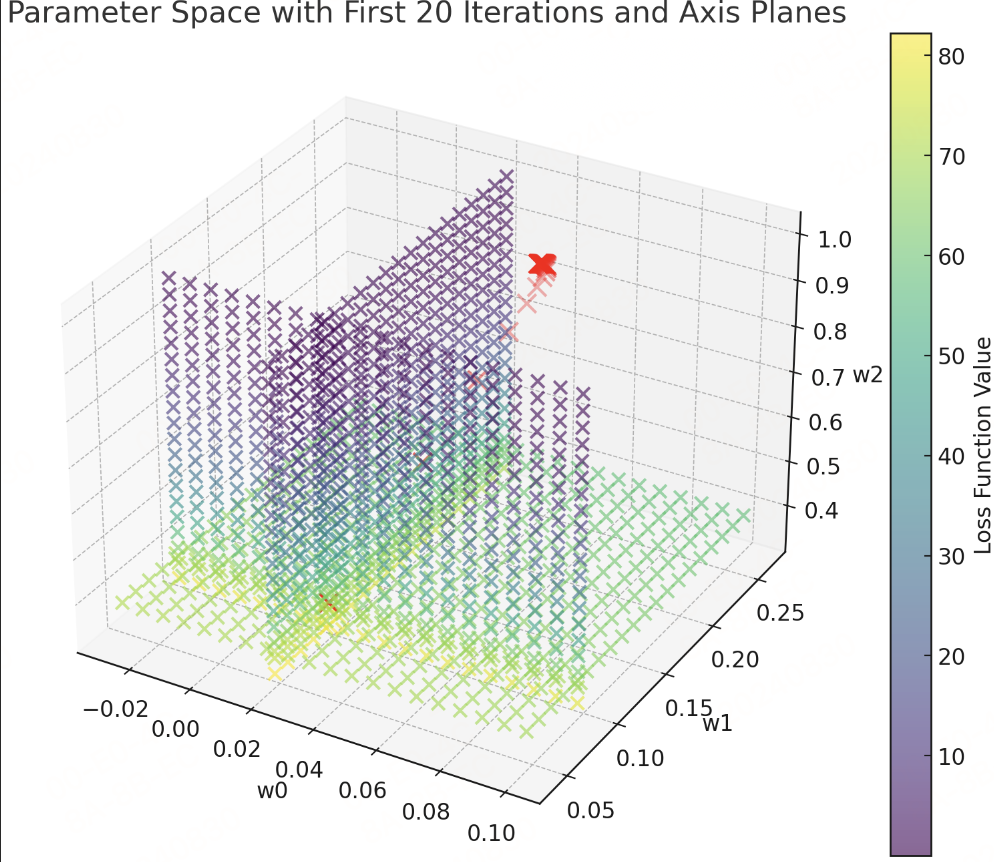
由于三维空间中无法直观的感受“梯度下降”的过程,让我们固定𝑤0,观察𝑤1、𝑤2与损失函数之间的关系:
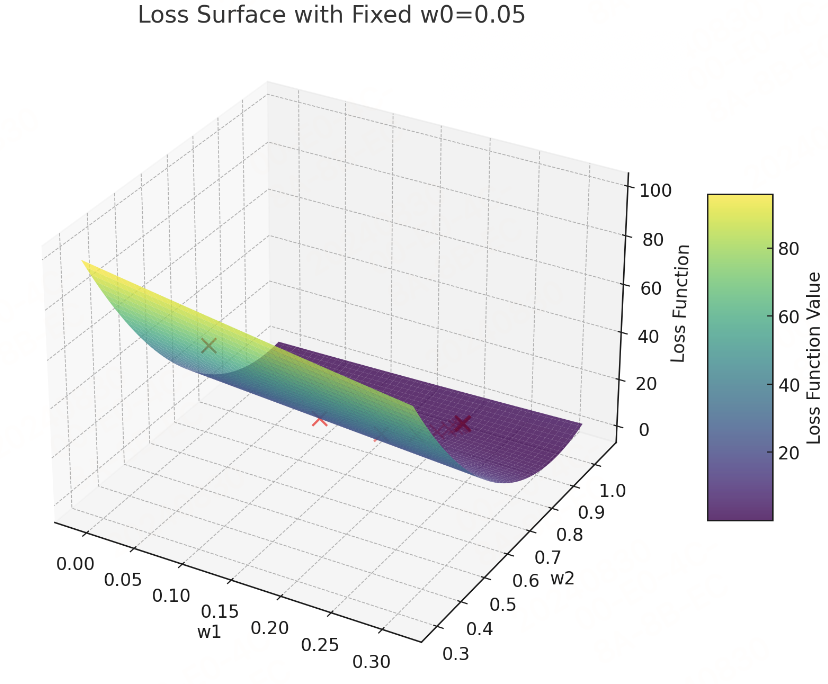
我们可以清楚地看到梯度下降如何从高损失区域逐渐移动到低损失区域。
4. 步子应该迈多大?
学习率是梯度下降算法中的一个关键参数,它决定了每次迭代中参数更新的幅度。设置学习率时需要在以下几个因素之间找到平衡。
步子太小:
优点:收敛过程更平滑,更容易找到最优解。
缺点:收敛速度慢,可能需要大量迭代才能接近最优解,容易陷入局部最优解。就像你到达了一个较低的山谷。虽然你确实比最初的地方处要低(损失函数值降低了),但你还没有达到整个山谷的最低处(全局最优解)。如果学习率太小,或者没有外部的推动力(如动量法或随机扰动),你可能会困在这个地方,因为所有方向的坡度都显示你要“上山”才行。
步子太大:
优点:收敛速度快,能够更快地接近最优解。
缺点:容易跳过最优解,导致不收敛或在最优解附近来回震荡,甚至发散。就像你在蹦床上用力过猛地跳跃。虽然你知道目标在哪里,但每次调整参数的幅度都太大,以至于你从目标的一边直接跳到了另一边,完全错过了那个最优点。结果,你可能会不断在目标附近来回震荡,始终无法精准地达到最优解。
在实际操作中,我们可以动态地选择学习率。例如,开始时用较大的学习率进行快速收敛,当接近最优解时,减小学习率以微调参数。或者使用优化算法,如 Adam、RMSprop 等,它们会根据梯度信息自动调整学习率。这类算法在许多情况下能够提供更好的收敛性能,尤其是在学习率难以手动调节的情况下。
仔细想想,这何尝不是“中庸之道”的一种体现呢?如果学习率过大,可能会导致过度调整甚至偏离正确方向;如果过小,进展则会过于缓慢。所以,在追求目标时,应该避免极端,选择适当的路径,既不过于激进,也不过于保守,而是根据环境和条件适时调整策略。
5. 总结
梯度下降不仅是一个数学算法,它的工作原理中也体现了哲学的智慧。通过不断的努力和调整来逐步接近真理,保持平衡与适应,从错误中学习,在未知中成长,在全局与局部之间找到最佳的解决路径。面对未知,我们需要勇敢前行,尽管每一步都可能充满不确定性,但只要我们不断调整和改进,最终就能找到通往目标的道路。
6. 参考资料
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324. https://doi.org/10.1109/5.726791
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. https://arxiv.org/abs/1412.6980
https://zh.wikipedia.org/wiki/%E6%A2%AF%E5%BA%A6%E4%B8%8B%E9%99%8D%E6%B3%95
https://www.bilibili.com/read/cv33733975/
https://towardsdatascience.com/gradient-descent-algorithm-a-deep-dive-cf04e8115f21
- END -
如果您关注前端+AI 相关领域可以扫码进群交流

添加小编微信进群😊
关于奇舞团
奇舞团是 360 集团最大的大前端团队,非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。
















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









