






1、 前言
通过之前的学习,有分类算法kNN近邻算法,回归算法线性回归算法。可以总结,机器学习就是寻找一种函数f(x)并进行优化,且这种函数能够做预测、分类、生成等工作。
那么可以总结出关于“如何找到函数f(x)”的方法论,可看作是机器学习三板斧。
1、 定义一个函数集合
2、 判断函数的好坏
3、 选择最好的函数
通过3,我们的目标是损失函数最小化
那么,梯度下降法是目前机器学习、深度学习,解决最优化问题的算法中,最核心、应用最广的方法。
2、why gradient_descent
抛开具体场景,仅从数学抽象角度来看,每个模型都有自己的损失函数,无论监督学习还是非监督学习。损失函数包含若干模型参数,如在多元线性回归中,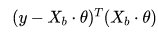
我们要找到使损失函数尽可能小的参数未知模型参数。
在之前的简单线性回归算法中,我们通过最小二乘法来求损失函数的最小值,但是这只是一个特例。在绝大多数的情况下,损失函数是很复杂的(比如逻辑回归),根本无法得到参数估计值的表达式。因此需要一种对大多数函数都适用的方法。这就引出了“梯度算法”。
那么,梯度下降法是做什么的。
首先梯度下降(Gradient Descent, GD),不是一个机器学习算法,而是一种基于搜索的最优化方法。梯度下降(Gradient Descent, GD)优化算法,其作用是用来对原始模型的损失函数进行优化,以便寻找到最优的参数,使得损失函数的值最小。
梯度下降算法通过导数告诉我们此时此刻某参数应该朝什么方向,以怎样的速度运动,能安全高效降低损失值,朝最小损失值靠拢。
2.1 什么是梯度
对于一元函数,其到数的几何意义是某点切线的斜率,也表示函数在该点的变化率。导数越大,说明函数在该点的变化越大
导函数表示函数沿X方向的变化率
对于二元函数,存在偏导数,它对x和y的偏导数为
1、函数在y方向不变时,函数值沿x方向的变化率
2、函数在x方向不变时,函数值沿y方向的变化率
通过数学推导,可得到方向导数
梯度下降第二步,找到相对于该位置下降最快的方向,我们的方向导数即代表函数变化率与方向的关系,即梯度。
同样,可以将一元函数、二元函数的推导结论作用于高元函数。
所以,高元函数在某点的梯度就是对每一个自变量求偏导,组成一个向量,在该点的取值,该向量的方向就是函数在该点处增长最快额方向。则,其负方向就是函数减少最快的方向
所以,当我们需要最小化损失函数时,只需使损失函数沿负梯度方向前行,使损失函数最快下降。
2.2学习率
我们已经知道,梯度对应的是下山的方向,而参数 对应的是步伐的长度。在学术上,我们称之为“学习率”(learning rate),是模型训练时的一个很重要的超参数,能直接影响算法的正确性和效率:
首先,学习率不能太大。因此从数学角度上来说,一阶泰勒公式只是一个近似的公式,只有在学习率很小,也就是很小时才成立。并且从直观上来说,如果学习率太大,那么有可能会“迈过”最低点,从而发生“摇摆”的现象(不收敛),无法得到最低点
其次,学习率又不能太小。如果太小,会导致每次迭代时,参数几乎不变化,收敛学习速度变慢,使得算法的效率降低,需要很长时间才能达到最低点。
2.3致命问题
梯度算法有一个比较致命的问题:
从理论上,它只能保证达到局部最低点,而非全局最低点。在很多复杂函数中有很多极小值点,我们使用梯度下降法只能得到局部最优解,而不能得到全局最优解。那么对应的解决方案如下:首先随机产生多个初始参数集,即多组;然后分别对每个初始参数集使用梯度下降法,直到函数值收敛于某个值;最后从这些值中找出最小值,这个找到的最小值被当作函数的最小值。当然这种方式不一定能找到全局最优解,但是起码能找到较好的。
对于梯度下降来说,初始点的位置,也是一个超参数。
3 数学推导
比较麻烦,还需要多回看
4 随机梯度
在之前介绍的梯度下降法的步骤中,在每次更新参数时是需要计算所有样本的,通过对整个数据集的所有样本的计算来求解梯度的方向。这种计算方法被称为:批量梯度下降法BGD(Batch Gradient Descent)。但是这种方法在数据量很大时需要计算很久。
针对该缺点,有一种更好的方法:随机梯度下降法SGD(stochastic gradient descent),随机梯度下降是每次迭代使用一个样本来对参数进行更新。虽然不是每次迭代得到的损失函数都向着全局最优方向,但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。但是相比于批量梯度,这样的方法更快,我们也是可以接受的
4.1 学习率的取值
随机梯度下降法的过程中,学习率的取值很重要,这是因为如果学习率一直取一个固定值,所以可能会导致点已经取到最小值附近了,但是固定的步长导致点的取值又跳去了这个点的范围。因此我们希望在随机梯度下降法中,学习率是逐渐递减的。
设计一个函数,使学习率随着下降循环次数的增加而减小。
我们想到最简单的表示方法是一个倒数的形式,不过这样也会有问题,如果循环次数比较小的时候,学习率下降的太快了,比如循环次数为1变为2,则学习率减少50%。因此我们可以将分子变为常数,并在分母上增加一个常数项来来缓解初始情况下,学习率变化太大的情况,且更灵活。
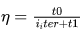
4.2 总结
批量梯度下降法BGD(Batch Gradient Descent)。
优点:全局最优解;易于并行实现;
缺点:当样本数据很多时,计算量开销大,计算速度慢。
循环终结方式:1、循环次数。2、收敛达到最小值
针对于上述缺点,其实有一种更好的方法:随机梯度下降法SGD(stochastic gradient descent),随机梯度下降是每次迭代使用一个样本来对参数进行更新。
优点:计算速度快;
缺点:收敛性能不好
循环终结方式:1、循环次数















 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









