







目录
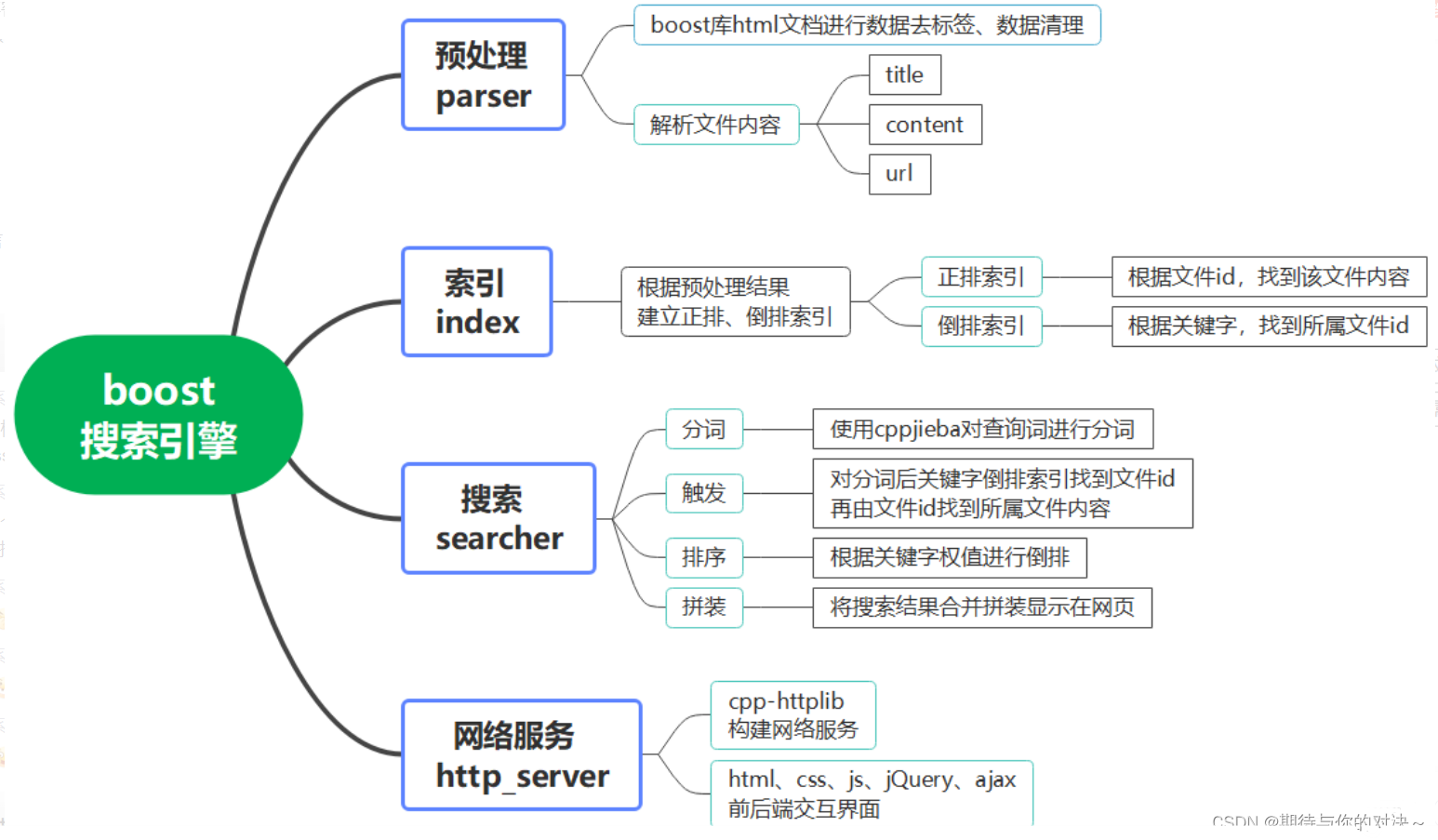
一·功能和框架
功能:实现boost文档站内搜索。通过输入关键字,将与关键字有关的网页按文档权值大小,罗列出来。前端显示包括,标题,摘要,网址~
框架:
二·技术栈与项目环境
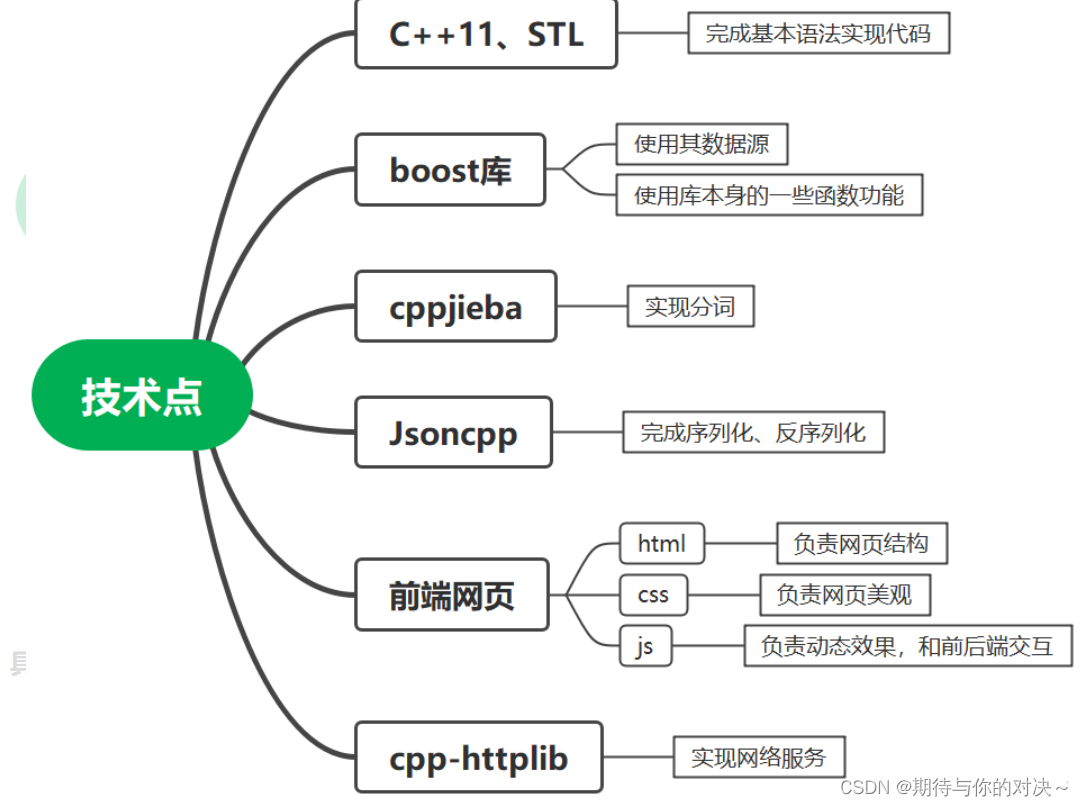
技术栈:
c/c++、c++11、STL、准标准库boost、Jsoncpp、cppjieba、cpp-httplib
项目环境:
Linux CentOS 7云服务器、vim/gcc(g++)/Makefile、vscode
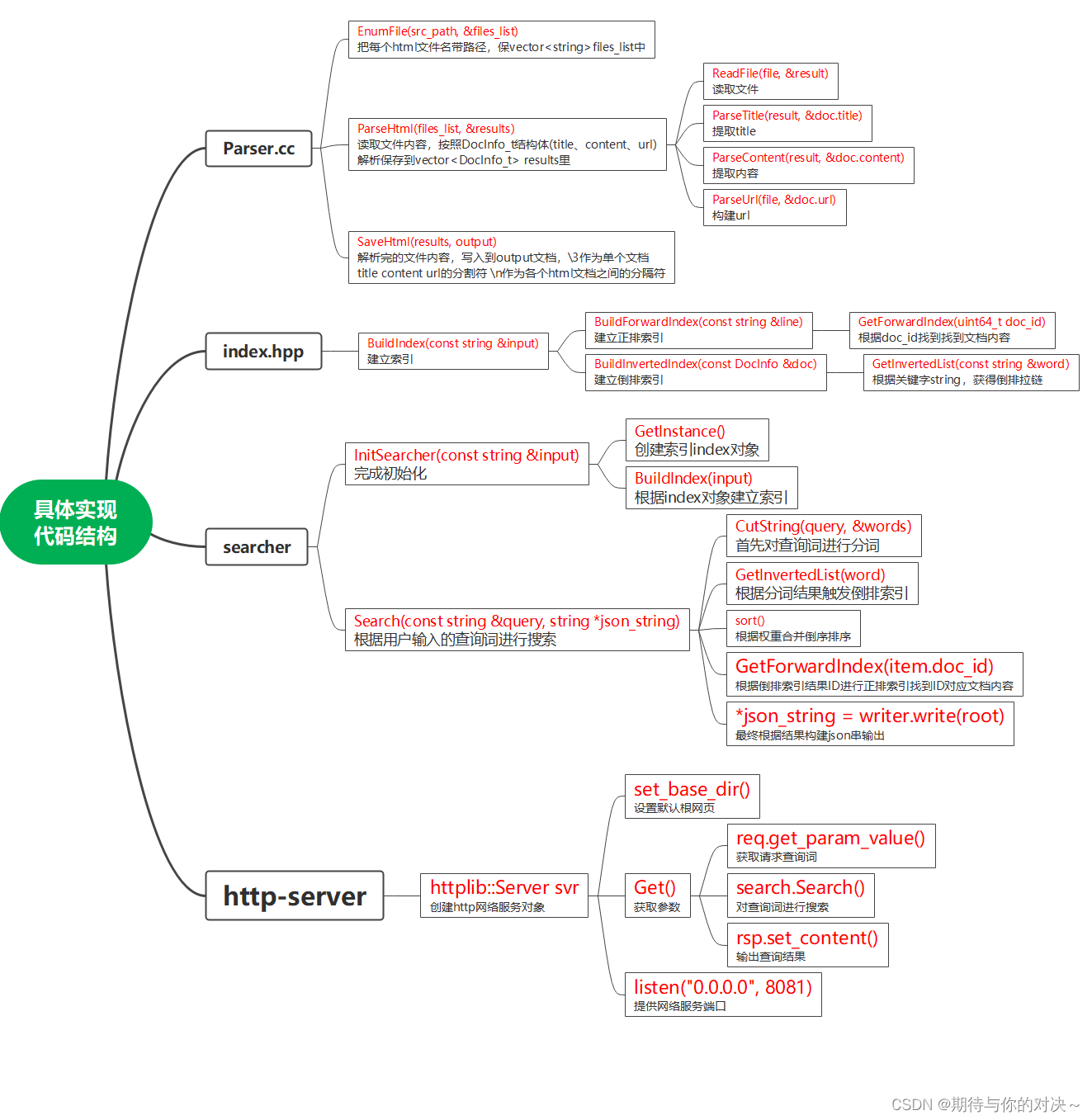
三·具体代码结构
 四·项目背景
四·项目背景
项目与日常搜索搜索网站不同,如百度,360,搜狗。此搜索引擎只支持boost库1.78版本站内搜索
boost库:

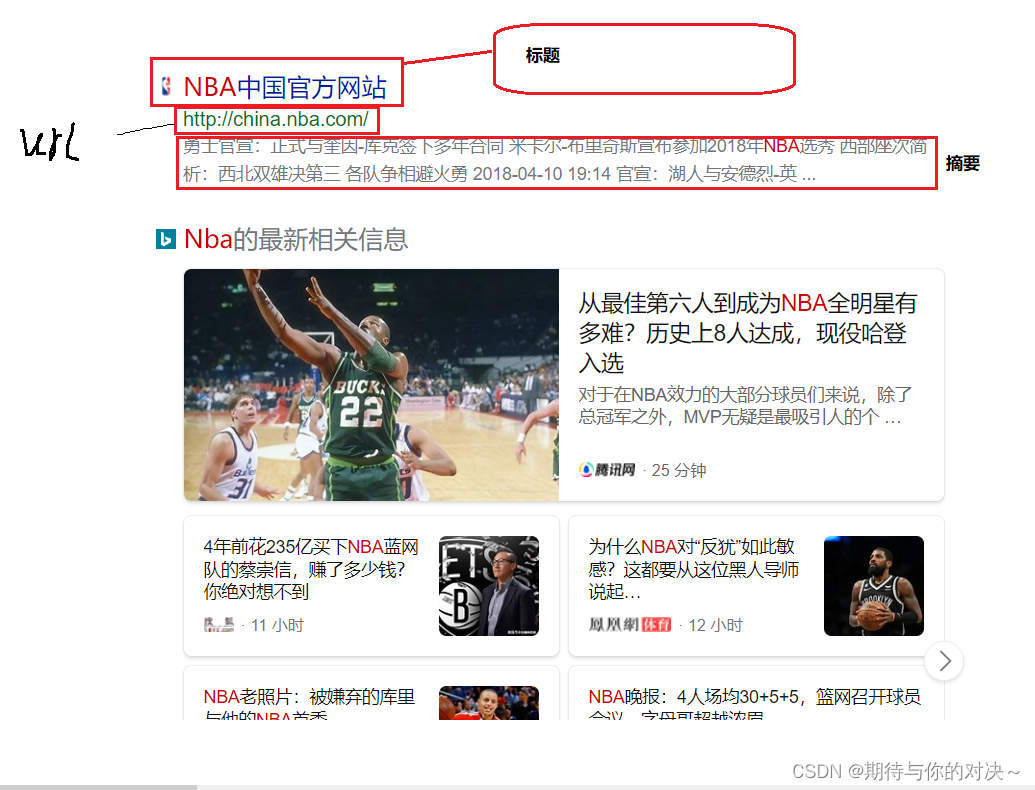
我们平时在网上搜索的内容都以三个内容返回给我们;标题,摘要,网页url
我们在数据清理阶段只需要对boost/html下的文件标题,摘要,url进行处理即可
五·项目宏观原理
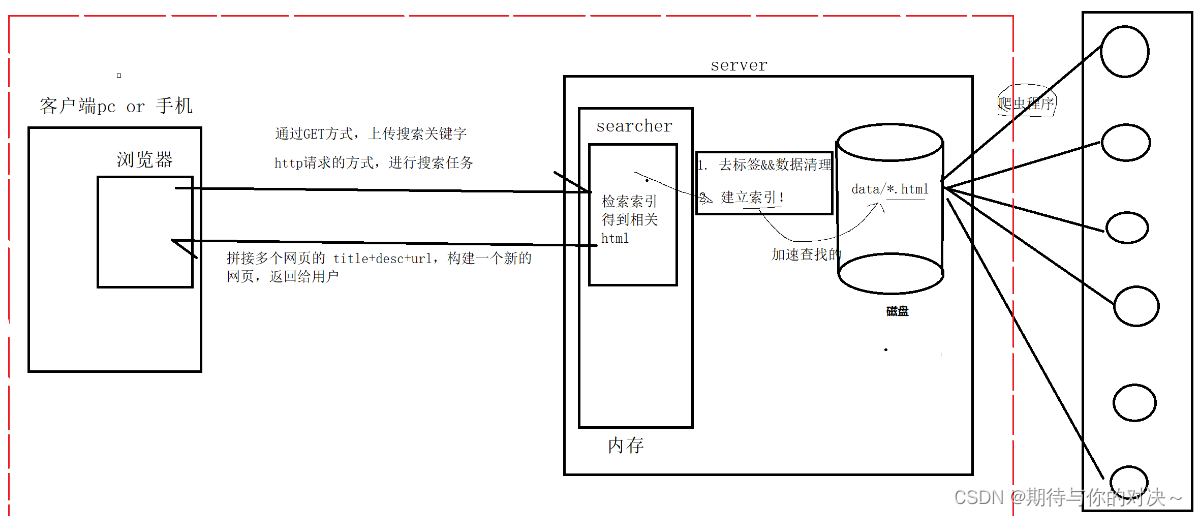
六·数据去标签模块
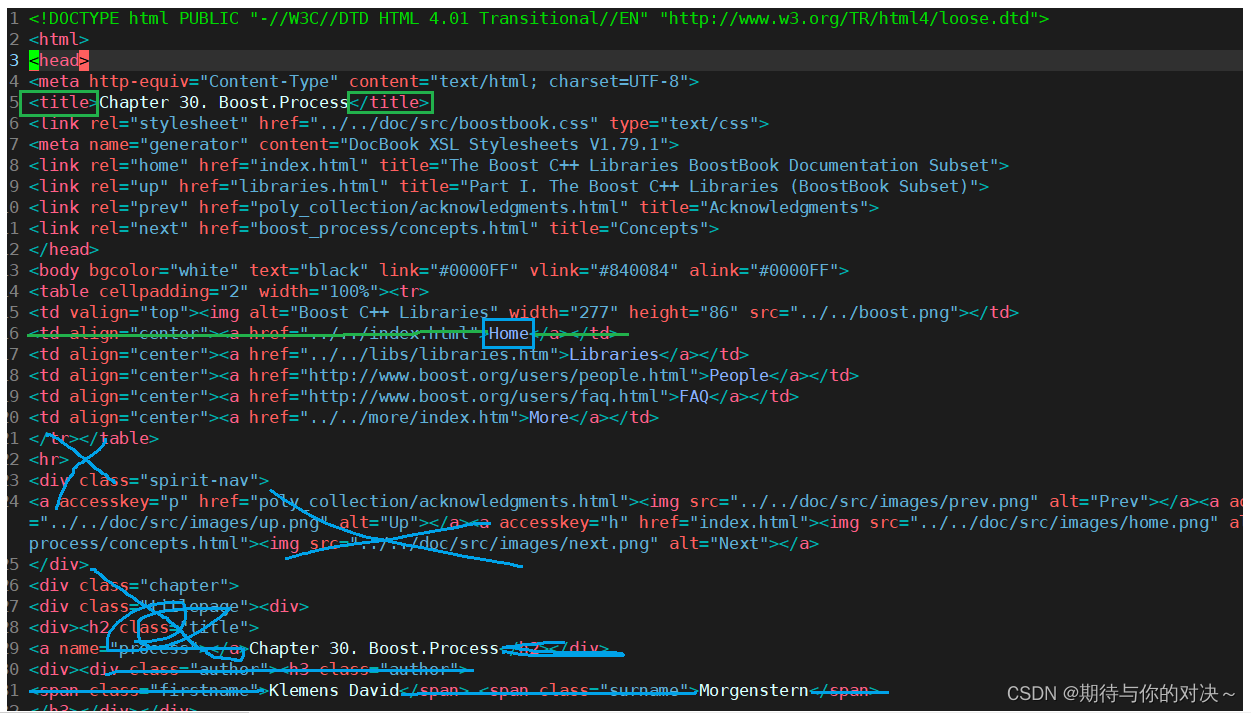
我们下载到linux中的boost1.78文档中有好多东西是我们不需要的
以上<title></title>和划线的都是不需要的我们将这一些去掉并将这些文档内容按每个文档:
文档1:标题\3摘要\3/url\n
文档2:标题\3摘要\3/url\n
...
以此这样排列好放在一个特定目录下方便我们进行检索
在进行原始文件的处理时用到了boost库开发的工具就掠过吧~
去标签代码:parser.cc
//判断文件是否为html后缀文件,是的话就放在一个集合进行统一处理 bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list); //解析文件将文件标题,目录,URl按照我们上面说的方式整理放在一个集合。 bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results); //将处理好的html文件(已经处理好的去标签,数据清洗完的。统一放在output文件里。每个文件按\n分割) bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output);int main() { std::vector<std::string> files_list; //第一步: 递归式的把每个html文件名带路径,保存到files_list中,方便后期进行一个一个的文件进行读取 if (!EnumFile(src_path, &files_list)) { std::cerr << "enum file name error!" << std::endl; return 1; } // 第二步: 按照files_list读取每个文件的内容,并进行解析 std::vector<DocInfo_t> results; if (!ParseHtml(files_list, &results)) { std::cerr << "parse html error" << std::endl; return 2; } // //第三步: 把解析完毕的各个文件内容,写入到output,按照\3作为每个文档的分割符 if (!SaveHtml(results, output)) { std::cerr << "sava html error" << std::endl; return 3; } return 0; } bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list) { namespace fs = boost::filesystem; fs::path root_path(src_path); //判断路径是否存在,不存在,就没有必要再往后走了 if (!fs::exists(root_path)) { std::cerr << src_path << " not exists" << std::endl; return false; } //定义一个空的迭代器,用来进行判断递归结束 fs::recursive_directory_iterator end; for (fs::recursive_directory_iterator iter(root_path); iter != end; iter++) { //判断文件是否是普通文件,html都是普通文件 if (!fs::is_regular_file(*iter)) { continue; } if (iter->path().extension() != ".html") { //判断文件路径名的后缀是否符合要求 continue; } std::cout << "debug: " << iter->path().string() << std::endl; //当前的路径一定是一个合法的,以.html结束的普通网页文件 files_list->push_back(iter->path().string()); //将所有带路径的html保存在files_list,方便后续进行文本分析 } return true; } static bool ParseTitle(const std::string &file, std::string *title) { std::size_t begin = file.find("<title>"); if (begin == std::string::npos) { return false; } std::size_t end = file.find("</title>"); if (end == std::string::npos) { return false; } begin += std::string("<title>").size(); if (begin > end) { return false; } *title = file.substr(begin, end - begin); return true; } static bool ParseContent(const std::string &file, std::string *content) { //去标签,基于一个简易的状态机 enum status { LABLE, CONTENT }; enum status s = LABLE; for (char c : file) { switch (s) { case LABLE: if (c == '>') s = CONTENT; break; case CONTENT: if (c == '<') s = LABLE; else { //我们不想保留原始文件中的\n,因为我们想用\n作为html解析之后文本的分隔符 if (c == '\n') c = ' '; content->push_back(c); } break; default: break; } } return true; } static bool ParseUrl(const std::string &file_path, std::string *url) { std::string url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html"; std::string url_tail = file_path.substr(src_path.size()); *url = url_head + url_tail; return true; } // // for debug static void ShowDo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









