损失函数中正则化中的平方项的作用!!
最新推荐文章于 2025-02-25 00:15:00 发布










 本文讨论了在损失函数中添加平方项作为正则化项的策略,强调其优点包括方便的梯度计算、有效控制权重大小和易于与其他损失结合,以防止过拟合并提升模型泛化能力。
本文讨论了在损失函数中添加平方项作为正则化项的策略,强调其优点包括方便的梯度计算、有效控制权重大小和易于与其他损失结合,以防止过拟合并提升模型泛化能力。
本文讨论了在损失函数中添加平方项作为正则化项的策略,强调其优点包括方便的梯度计算、有效控制权重大小和易于与其他损失结合,以防止过拟合并提升模型泛化能力。
本文讨论了在损失函数中添加平方项作为正则化项的策略,强调其优点包括方便的梯度计算、有效控制权重大小和易于与其他损失结合,以防止过拟合并提升模型泛化能力。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




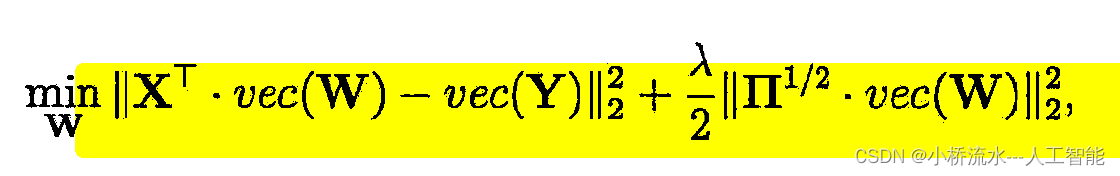

















 1万+
1万+





