










DQN还是Q-learning
初学者引导:选择DQN还是Q-learning?
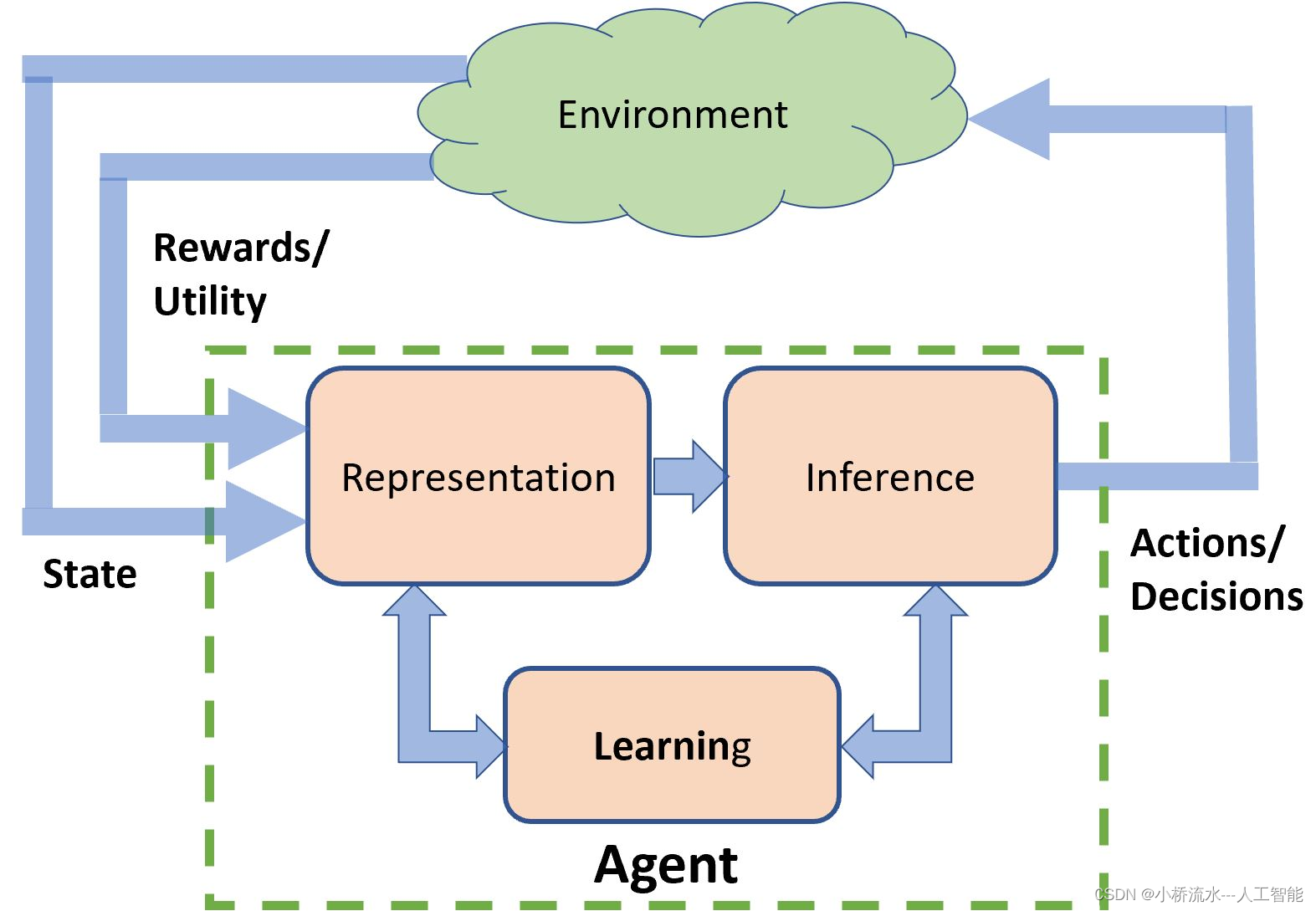
在进入强化学习的世界时,初学者常常面临从何处开始的选择困难。两种常见的强化学习算法——Q-learning和DQN(Deep Q-Networks),各有特点和应用场景。本篇博客将详细解析这两种算法的基本原理、优缺点以及适用性,帮助新手选择最适合自己学习路径的算法。
Q-learning:基础与原理
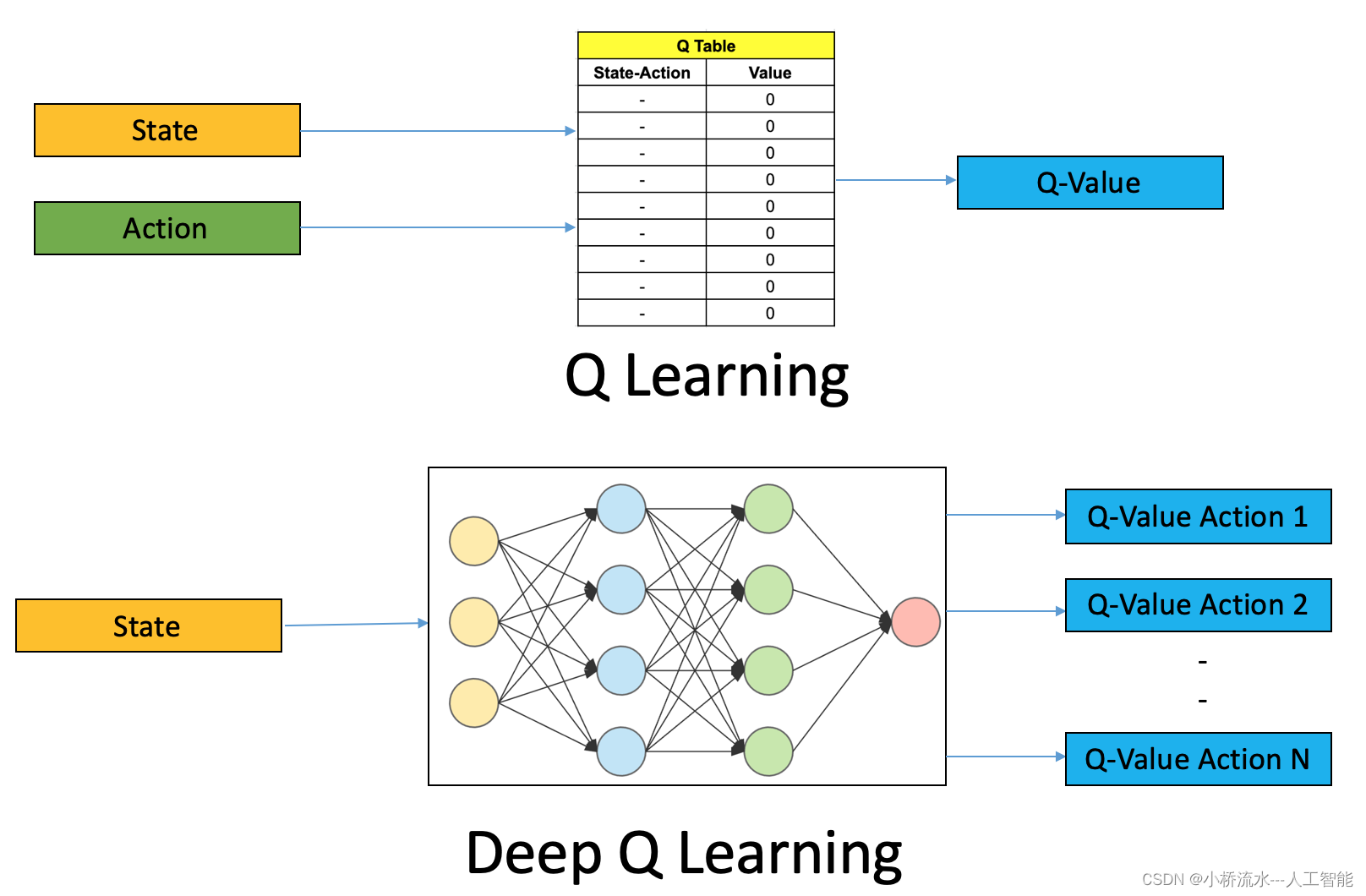
Q-learning是一种无模型的强化学习算法,适合解决具有离散动作空间的问题。它基于价值迭代,通过学习动作价值函数(action-value function),即Q函数,来寻找最优策略。
Q函数定义
Q函数 Q ( s , a ) Q(s, a) Q(s,a)表示在状态 s s s 下采取动作 a a a并遵循最优策略的预期回报。
Q-learning算法流程
- 初始化:Q值表初始化为零或随机值。
- 探索与利用:根据当前Q表,以一定的概率选择最优动作(利用)或随机动作(探索),以平衡探索和利用。
- Q值更新:通过以下更新公式调整Q值:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma \max_{a'} Q(s', a') - Q(s, a)] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
其中 r r r 是奖励, s ′ s' s′ 是结果状态, α \alpha α 是学习率, γ \gamma γ 是折扣因子。
优点:简单直观,易于实现,对初学者友好。
缺点:只适用于离散且较小的状态空间,难以直接应用于高维连续状态空间。
DQN:深度学习的结合
DQN是Q-learning的一个扩展,它通过引入深度神经网络来近似Q函数,使得强化学习可以应用于高维的状态空间,如视觉输入等。
DQN的核心组成
- 神经网络:作为函数逼近器,用于近似Q函数。
- 经验回放:通过存储智能体的经验并在训练时随机抽取,打破样本间的相关性,稳定学习过程。
- 目标网络:引入一个周期性更新的目标网络,减少学习过程中的移动目标问题。
优点:能够处理高维的状态空间,适用于复杂问题。
缺点:实现复杂,计算资源需求较高,对超参数调整敏感。
新手学习建议
对于初学者而言,建议首先学习Q-learning。理由如下:
- 理论基础扎实:Q-learning提供了强化学习的基础理论和直观理解,对于掌握更复杂的算法(如DQN)至关重要。
- 实现简单:相比DQN,Q-learning的实现更简单,便于新手快速上手和理解。
- 基础迁移:在掌握了Q-learning后,对于理解DQN中的核心概念如价值函数、探索与利用等将更加容易。
详细实践建议:从小规模问题开始,如解决迷宫问题或简单的游戏,逐渐过渡到更复杂
的问题,再尝试引入神经网络进行DQN学习。
结论
对于强化学习初学者,从Q-learning开始是一个合理的选择,它不仅能帮助您构建坚实的理论基础,还能逐步引导您进入更为复杂的深度强化学习领域。希望本篇博客能帮助您清晰地理解Q-learning和DQN的区别及各自的优势,为您的强化学习之旅提供明确的学习路径和指导。

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









