







-
-
- 文本挖掘的基本概念
-
1.基本信息检索技术而来
Information Retrieval
传统的图书信息服务必备的3大要素:
书(知识的化身,)图书馆(知识的殿堂)、图书管理员(知识的保护者与传播的保护者)
网络的世界就是一个虚拟化的电子图书馆。
书有新的形式,(web Page,Net News,Images,BBS)
图书馆有新的建筑方式(Web serve ,Image DB。。)
图书馆员有了新的竞争者(search engine :百度,谷歌)
这些图书馆员就是
信息检索技术。:
基本检索法
全面扫描(Full-Text Scanning)*、
逐步比对法
将待查的字符串直接和文件字符串进行快速字符串进行比对
文件不多,且异动频繁(经常更新,删除,修改)时使用。
Windows的搜索就是全文扫描
我们的系统档案比较少。而且经常会改变。就很适合全文扫描。
优点:
不需要建立关键词索引
简化数据库中数据的增加与更新的工作
不需要额外的空间来储存索引。
缺点:
检索数据反应时间缓慢。(后面都是为了改善这个缺点,优点就会变成缺点。)
关键词(keyword)
我们是不会查询所有含有的的文章。
一篇文章中不是所有词都是重要的
文章中关键词要以什么为单位来抽取关键词(字,词,词组、概念)
人工抽取关键词:
成本高(品质也很高)
属于控制词汇(controlled Vocabulary可以用来当成词料。)
自动抽取关键词。
成本低
属于非控制词汇(Non-controlled Vocabulary)
大部分是自动抽取。虽然没办法解答,但是统计上有意义。

关键词。机器没法理解时,我们怎么找到词汇呢?
控制词汇:由专家进行制定的字汇集,大小约在2000个左右。
一前页为例。关键词是日本,广告,可口可乐。
自动构建的关键词的大小一般的是控制词汇的100倍以上,提供了更弹性化,更多元化的检索方式。
非控制词汇
如何选择非控制词汇 inverse Document Frequency (IDF)逆文件排列
IDF=log2(N/n)
N是指有多少文章:
n是某个词在多少篇文章出现过。:(加势力大周(n=1 N=5 IDF=2.32))
IDF越大说明这个词越重要,越是我们需要的关键词,idf越小说明这个词越没有检索价值
如果一个词每篇文章都出现,那它可能就是功能词,可能就没意义。
IDF代表信息量:一个东西比较少出现,那么它的带来的信息就比较大。
比如一年就下几次雪,经常出太阳。你告诉别人,明天会出太阳。明天会下雪(没意义)
再比如,一个学生天天都来上课,一个学生天天都在宿舍自学。
前者来上课,没有带来信息,后者来上课,就说明可能有考试或者其他活动。
五篇文章:的关键词IDF出现特殊情况:
喋血案那篇文章
IDF:说>喋血案>因=和
此现象不是很合理、如何解决。
IDF的计算必须要有前提条件,文章的数量必须够大,因为我们只提取了五篇文章,其中2篇都说了喋血案,说又只出现了一次
如果文章有100篇,那么说肯定就小于喋血案了。因为说比较常用
因为量太少,所以经常会有错误产生。
选择关键词,就直接将IDF定一个阈值,过滤大于等于该值的值为关键词
剩下的词就是停用词(Stops WORDs)
在英文里一定要先进行原型(词根)储存,在进行IDF
关键词步骤总结:
读取文献
分词(中文)
重整为原型(stem word)(英文)
计算每个word的IDF
利用阈值选出代表文献的关键词和IDF,产生stop word
逐步项term(任何单位取代)翻转(Inversion of Terms(可以任何单位取代,比如字,词,概念,句子))*、
Inversed fild
利用繁复的索引来提高检索的销量
直接检索索引就可以,不用检索文件的内容。
利用逐项反转法:每一个文件都可以利用反转文件其本身的内容,记录文字的位置,来表达文件的内涵。
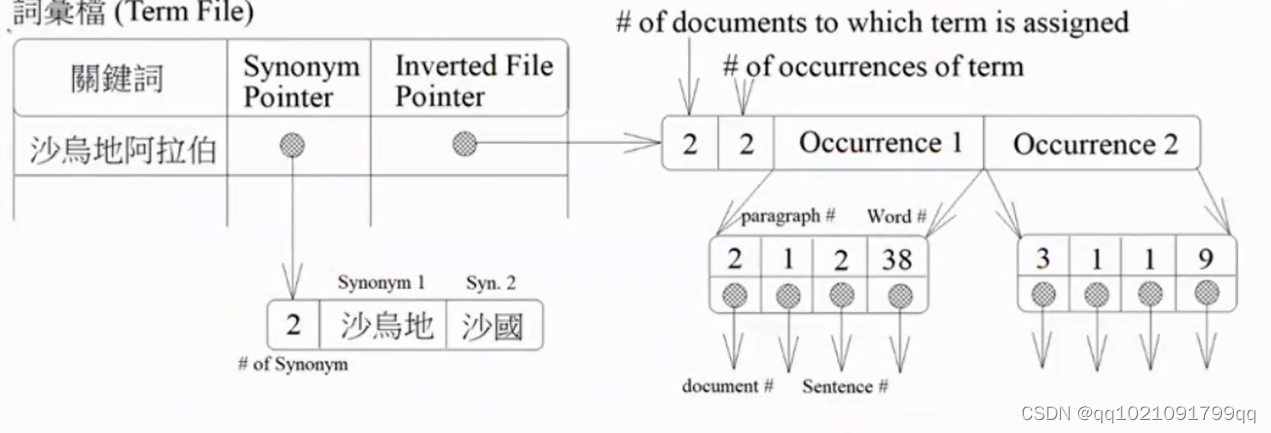
词汇档,把所有的关键词放在第一列,第二列放同义词的文档。第三列反转的指标。
指标的一个数字2,代表出现在了几篇文章 后面的2代表出现次数。Occurrence代表出现第2篇文章,第一段,第2句话,第38个词(从文章开头开始算)
第3篇文章,第1段,第1句话,第9个词。
逐项反转的关键词的索引结构就是这样,记录下来之后,如果今天你搜索,
可以利用第二列的同义词达到智能的效果,
反转的效果:原本都是文章——》关键词,变成了关键词——》文章
缺点:这个方法的索引内容比原文多百分之50-百分之300
优点:查询速度很快。
关键词和关键词索引的区别,
由于建立这种索引并不困难所以普遍用在商业化的产品使用上。
这个方法对比其他方法,较容易与同义词词典结合。较有利于同义词的处理。
有了这个索引结构(文章位置精确到段落,某句,第几个词),我们很容易运用布尔运算来达到,检索的目的。且速度非常快。
(A and B)
(A or B)
(A and not B)
A和B同时出现在同一段的文章
A和B是否出现在同一句
















 4496
4496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











