







最近看了下文生图领域的最新进展,发现ICLR 2025有篇工作实现了轻量化的文生图模型,看效果图着实不错,本文来试玩一下。
论文标题:Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-to-Image Synthesis
论文地址:https://arxiv.org/abs/2411.10781
开源代码:https://github.com/viiika/Meissonic

1.论文内容概述
本文主要介绍了一种名为 Meissonic 的新型文本到图像(T2I)生成模型,旨在通过 masked image modeling(MIM)方法提升高质量高分辨率图像生成的效率和性能。
1.1 研究背景与动机
当前主流的T2I生成模型(如Stable Diffusion XL)依赖于计算密集的扩散模型,虽然性能优异,但对硬件需求较高。
现有的MIM方法(如MaskGIT和MUSE)虽效率较高,但存在生成分辨率(最高512×512)和性能(细节、文本对齐)的局限性。
1.2 主要创新点
-
混合模态Transformer架构:结合多模态和单模态Transformer层,比例设为1:2,提升跨模态交互和视觉表示能力
-
高级位置编码(RoPE):采用Rotary Position Embedding避免高分辨率下细节丢失,解决了传统绝对位置编码的失真问题
-
动态掩码率调节:将掩码率离散化为1000级调节信号,使模型能自适应生成不同阶段,显著提升图像细节
-
数据与训练优化:使用高质量训练数据、微调(如分辨率、人类偏好分数)和特征压缩层,支持1024×1024分辨率生成
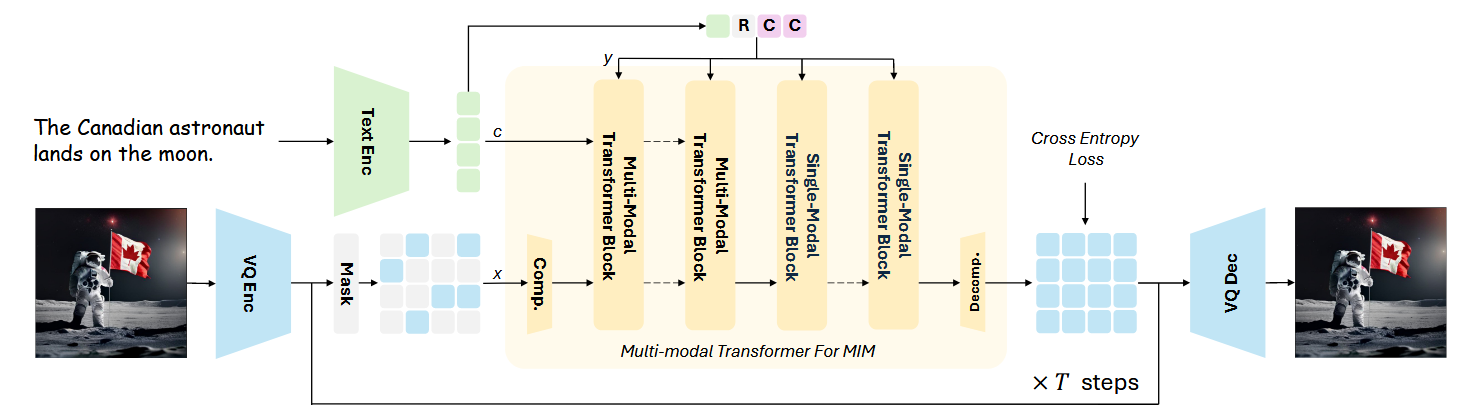
上图展示了Meissonic模型的核心架构,左侧部分充分展示了MIM的原理,即对输入图像分割为若干图像块,然后进行随机遮盖,这种方式对图像不需要人工标注,可利用海量无标注图像进行训练。
1.3 功能简介
除了基本的根据文本生成图像的功能外,它还包含了图像修复(Inpainting)和图像外绘(Outpainting)两个功能。
图像修复是指掩盖(mask)图像中一部分内容,图像根据其它内容对这部分内容进行重新生成。
图像外绘是指扩展图像的原始边界。
下图中,第一行为图像修复的效果;第二行为图像外绘的效果;第三行为不用遮掩方法,直接利用纯文本对画面的内容进行修改(该方式似乎并未在仓库开源)

1.4 输出速度及显存需求
这篇工作吸引我兴趣的一大原因是其称能在消费级显卡中生成1024 x 1024分辨率大小的图像。
在代码仓库中,其给出了原始模型(FP32)和量化精度(FP16和FP8)模型生成单张图片的速度和显存占用情况。
| Precision (Steps=64, Resolution=1024x1024) | Batch Size=1 (Avg. Time) | Memory Usage |
|---|---|---|
| FP32 | 13.32s | 12GB |
| FP16 | 12.35s | 9.5GB |
| FP8 | 12.93s | 8.7GB |
2. 使用方式
- 克隆仓库
git clone https://github.com/viiika/Meissonic/
cd Meissonic
- 创建虚拟环境并安装依赖
conda create --name meissonic python
conda activate meissonic
pip install -r requirements.txt
git clone https://github.com/huggingface/diffusers.git
cd diffusers
pip install -e .
- 启动运行
提供了两种运行方式
方式一:通过基于Gradio的交互式web界面:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2666
2666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











