






当我使用nltk进行分词时,报了这个错。
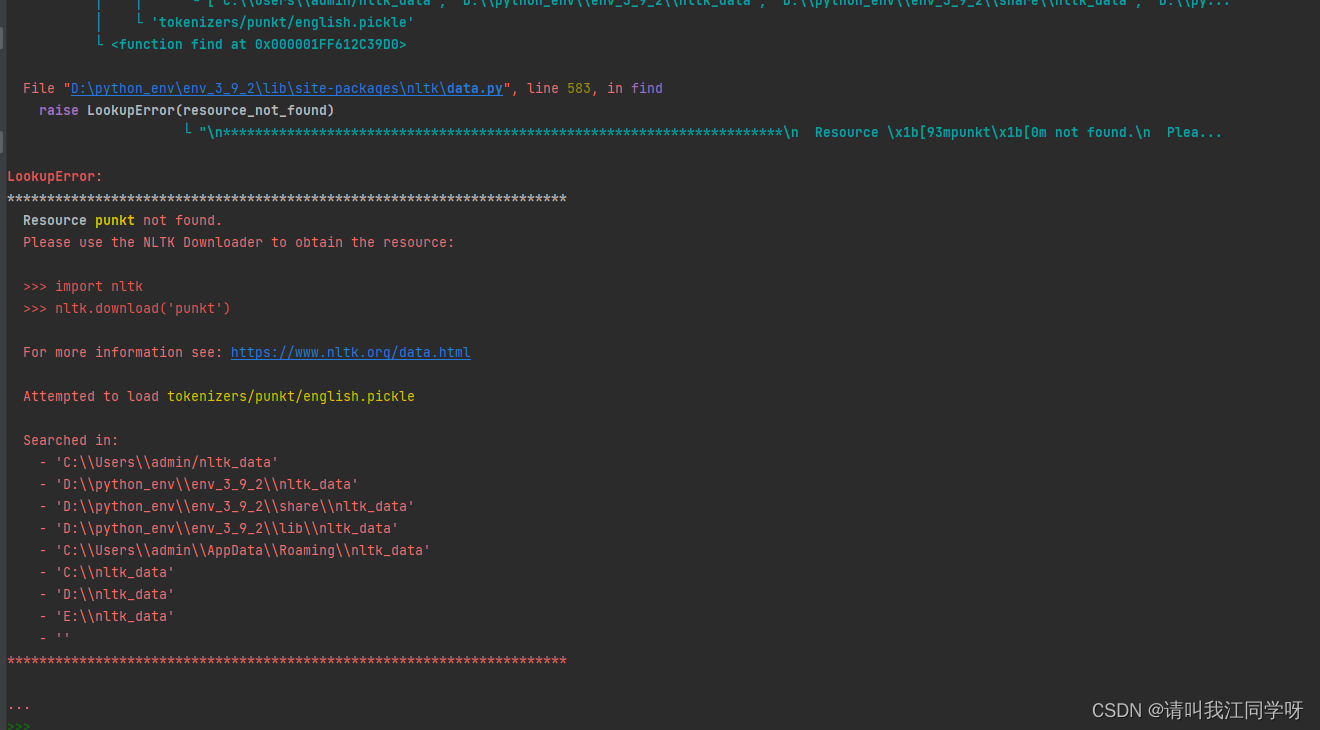
LookupError:
**********************************************************************
Resource punkt not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt')
For more information see: https://www.nltk.org/data.html
Attempted to load tokenizers/punkt/english.pickle
Searched in:
- 'C:\\Users\\admin/nltk_data'
- 'D:\\python_env\\env_3_9_2\\nltk_data'
- 'D:\\python_env\\env_3_9_2\\share\\nltk_data'
- 'D:\\python_env\\env_3_9_2\\lib\\nltk_data'
- 'C:\\Users\\admin\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- ''
**********************************************************************
从报错信息上看,是由于punkt没能下载导致的问题,于是我查了以下资料:
- nltk.download(‘punkt‘)报错
- 已解决nltk.download(‘punkt’) [nltk_data] Error loading punkt: [WinError 10060] [nltk_data]
- 离线下载安装 NLTK 的 nltk_data 模块
- nltk包的下载与离线导入
- nltk.download()下载数据,错误代码11004,快速本地下载数据集的方法
- nltk.download(‘punkt‘)报错问题解决方案
但是这些方法全部都得放在指定文件夹下,不能随着项目代码移动到不同的电脑上使用,直到我偶然发现了这个方法nltk.data.load(),接着通过研究发现nltk.data有个类似sys.path的东西,可以通过添加路径,增加查找资源的路径,于是我通过nltk.data.path.append("./res/nltk/")将项目文件夹底下的nltk文件夹加入其中,于是成功分句了。
最后放一下下载nltk资源的地方http://www.nltk.org/nltk_data/















 2098
2098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









