







文章目录
基于YOLOv8的衣服检测
1. 背景和挑战
随着计算机视觉技术的发展,衣物检测已经成为图像识别领域中的一个重要应用。尤其是在电子商务、智能零售、虚拟试衣、时尚推荐等领域,准确地识别并分类衣物类型、款式和颜色显得尤为重要。然而,衣物检测面临着许多挑战,例如:
- 衣物种类繁多:包括不同类型的服装,如裙子、裤子、衬衫、外套等,每种衣物都有不同的款式和材质,给检测模型的训练带来了复杂性。
- 姿势变化和遮挡:衣物在不同的穿着方式、姿势变化、以及可能的遮挡下,可能表现出不同的外观,增加了识别的难度。
- 复杂背景:图像中的背景可能包含其他物品或是复杂的场景,这使得衣物与背景的区分更加困难。
为了应对这些挑战,基于深度学习的目标检测方法,尤其是YOLO(You Only Look Once)系列模型,提供了一个高效且准确的解决方案。
2. YOLO系列模型概述
YOLO 是一个基于卷积神经网络(CNN)的实时目标检测算法。YOLO模型的主要特点是通过回归问题的方式,将目标检测转化为图像中的每个区域是否包含目标的问题。它的优势在于:
- 高效性:YOLO采用端到端的训练方式,可以同时处理图像的分类和定位,极大地提高了检测速度。
- 实时性:由于YOLO是单阶段检测器,其速度远超传统的两阶段检测器(如Faster R-CNN),能够实现实时目标检测。
随着YOLO算法的不断发展,出现了多个版本,例如YOLOv2、YOLOv3、YOLOv4,直到最近的 YOLOv8。YOLOv8是最新的版本,较之前的版本在检测精度、速度和模型灵活性等方面做出了显著优化。
3. YOLOv8的特点与优势
YOLOv8 是 YOLO 系列中的最新版本,具有以下几个主要特点:
- 更高的精度:YOLOv8在精度和召回率上表现出色,尤其是在细粒度目标检测任务上。对于衣物检测,YOLOv8能够更准确地识别各种衣物类别。
- 更快的速度:YOLOv8的推理速度进一步优化,能够在较低的硬件配置下实现实时检测。
- 灵活的模型结构:YOLOv8支持不同规模的模型,从轻量级(YOLOv8n)到高性能的(YOLOv8x),使得用户可以根据具体应用场景选择最合适的模型。
- 自适应设计:YOLOv8在设计上更加注重处理复杂场景中的衣物检测任务,尤其是在多物体遮挡、复杂背景等情况下的表现提升。
4. 基于YOLOv8的衣物检测
基于YOLOv8进行衣物检测时,主要包括以下几个步骤:
4.1 数据集准备
为了训练一个高效的衣物检测模型,需要构建一个包含多种衣物类型的标注数据集。数据集的标注应该涵盖不同的衣物类型、穿着姿势以及不同的环境和背景。常见的衣物分类包括:
- 上衣(T恤、衬衫、毛衣等)
- 下装(裤子、裙子、短裤等)
- 外套(大衣、夹克、风衣等)
- 配件(帽子、鞋子、包包等)
这些数据集通常包含图像和每个衣物类别的框标注信息。常见的衣物检测数据集包括 DeepFashion、Fashion-MNIST 和 Clothes-Detection Dataset。
4.2 模型训练
在数据集准备完成后,使用YOLOv8模型进行训练。训练过程的关键步骤包括:
- 数据预处理:图像数据需要进行缩放、归一化处理,并根据具体要求进行图像增强操作(如旋转、翻转等)。
- 模型调整:根据数据集的类别数量和特征,调整YOLOv8的超参数,如学习率、批次大小等。
- 损失函数:YOLOv8使用的是多任务损失函数,能够同时优化分类损失、边框回归损失和目标检测损失,保证模型不仅能识别衣物类型,还能准确地定位物体。
4.3 模型推理
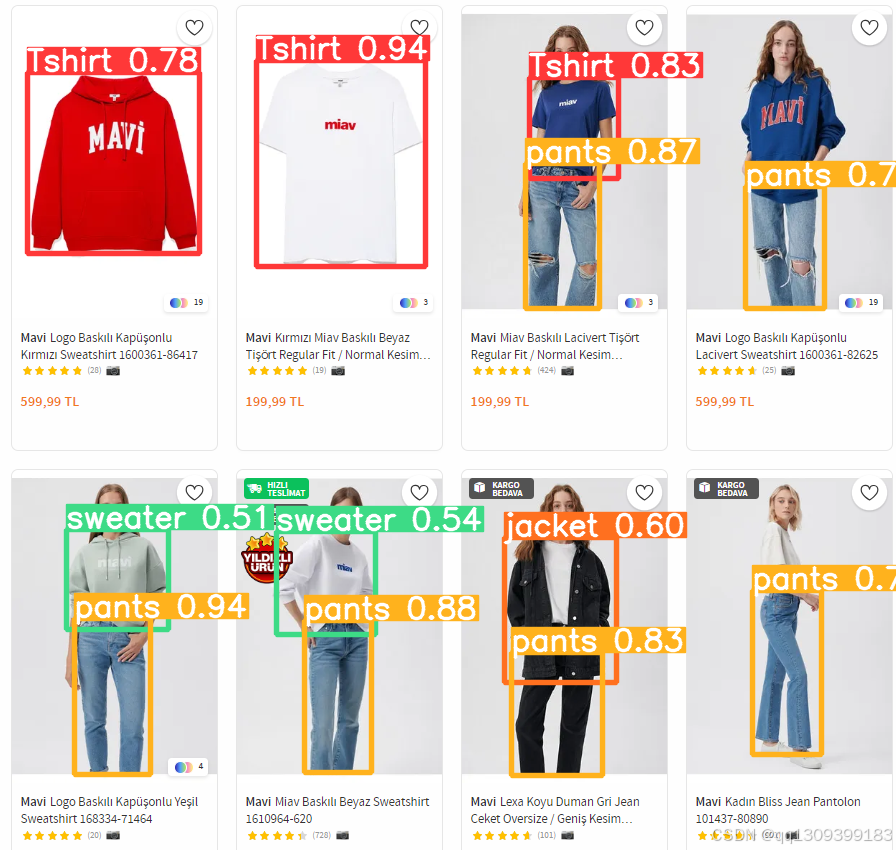
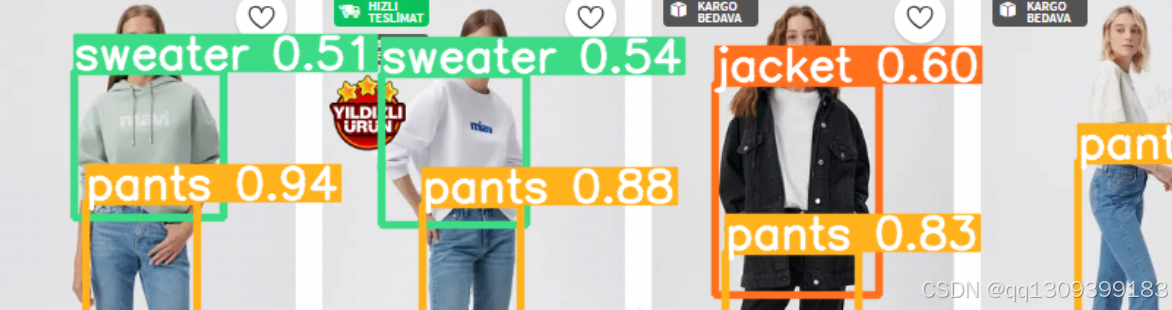
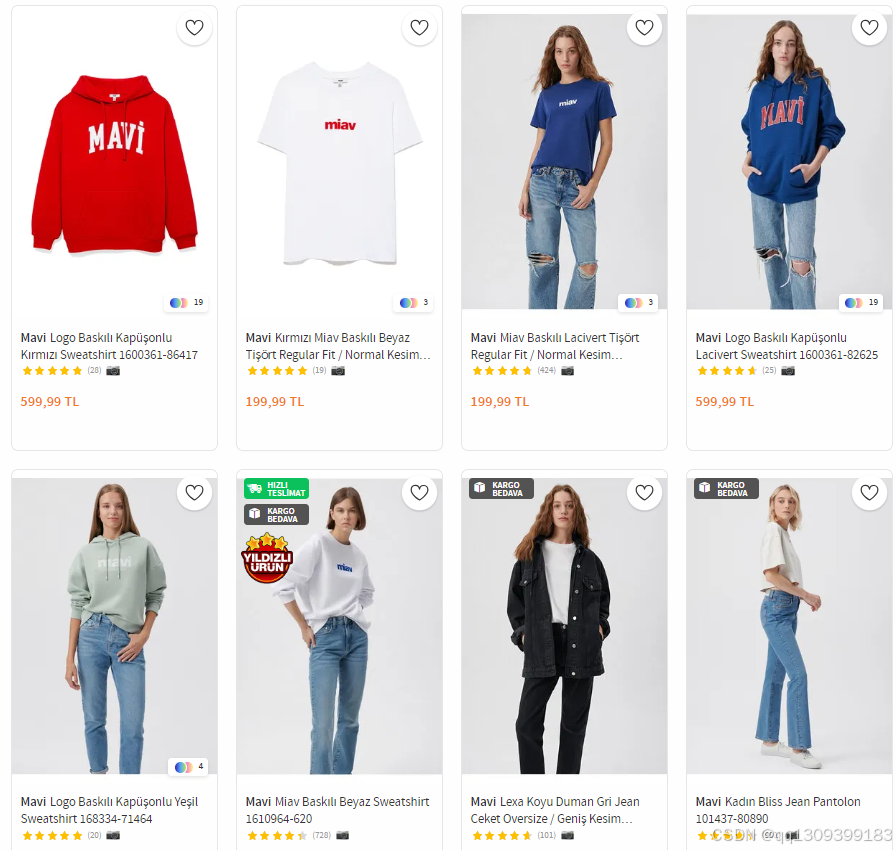
经过训练后,模型能够对新的图像进行推理,检测出图像中出现的衣物类型和其位置(边框)。YOLOv8通过实时处理每张图像,并输出检测到的所有衣物类别及其置信度和边框坐标。
例如,输入一张包含多个穿着不同衣物的人物的图像,YOLOv8能够快速输出每个人的衣物类型(如“连衣裙”,“牛仔裤”)和其在图像中的位置。YOLOv8能够处理不同的姿势变化、遮挡和复杂背景。
4.4 性能优化
YOLOv8不仅能够提供高精度的衣物检测结果,还能在速度上做出优化。针对一些低功耗设备(如移动端设备或嵌入式设备),可以选择较小的YOLOv8变种(如YOLOv8n)来减少计算量,实现快速的检测性能。
5. 应用场景
基于YOLOv8的衣物检测可以广泛应用于以下场景:
- 电子商务平台:在电子商务网站或应用中,YOLOv8能够自动标记和分类产品图片,帮助用户快速找到感兴趣的商品。
- 虚拟试衣:在虚拟试衣应用中,YOLOv8可以识别用户上传的衣物图片,并帮助其搭配不同的衣物,提供个性化的搭配建议。
- 智能零售:通过YOLOv8在智能镜子或无人商店中实现对顾客穿着衣物的自动识别和推荐,提升购物体验。
- 时尚推荐系统:基于用户穿着的衣物进行推荐,帮助用户快速找到搭配相宜的服装。
6. 结论
基于YOLOv8的衣物检测是一项高效且精准的技术,能够帮助各行各业提升图像分析的能力,尤其是在电子商务、时尚推荐和虚拟试衣等领域。YOLOv8作为最新一代的YOLO模型,其卓越的性能和灵活的适配性使其成为衣物检测的理想选择。随着YOLOv8模型的不断优化,未来在衣物检测的应用场景将会越来越广泛,推动智能零售和虚拟试衣技术的发展。


















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









