









 本文深入探讨了图像质量评估(IQA)领域的关键技术,包括有参考和无参考评估方法,如PSNR、SSIM、VMAF及BRISQUE算法。重点介绍了BRISQUE算法的原理,以及DIQA算法如何利用深度学习提升图像质量预测。文章还提供了DIQA算法的Python实现代码。
本文深入探讨了图像质量评估(IQA)领域的关键技术,包括有参考和无参考评估方法,如PSNR、SSIM、VMAF及BRISQUE算法。重点介绍了BRISQUE算法的原理,以及DIQA算法如何利用深度学习提升图像质量预测。文章还提供了DIQA算法的Python实现代码。
常用的图像质量评估(IQA)分为无参考和有参考两种类型。常见的有参考图像质量评估方法有PSNR,SSIM以及VMAF。其中vmaf是针对视频来讲的,在它的评价方法里面添加了一些时域信息,如果应用于单张图片,需要做一些处理,如去除时域信息。有参考意味着图像质量是以参考图为基准。基于参考图像都是高清图像的假设,这些评价方法已经广泛应用于图像压缩以及图像传输、拼接之类的处理后图像的质量,假如这张参考图的质量本身就比较渣,那么该评价指标可信度就大大降低。另一方面,由于人眼感知信号的复杂性,两种不同类型的图像(纹理复杂度,或者图像归属种类),即使psnr或者ssim相同,人眼判断的结果可能差别很大。因此,拥有一套好的无参考的图像质量评价指标或模型可以帮助企业寻找最佳的压缩参数,并在不影响用户体验的情况下节省带宽。
传统的无参考图像质量评价方法,如Brenner 梯度函数、Tenengrad 梯度函数、Laplacian 梯度函数以及图像信息熵函数等,在一定程度上可以判断出图像清晰度的层次,但是对于不同类型或者场景的图像可能会出现重大失误。但是对于同一张图片进行了不同级别的distortion,还是能够分辨出来的。因此在特定场景下,例如图像的对焦,还是有一定的应用场景。这些具体方法可以参考该博客
自然场景统计NSS,作为视觉信号的一个微小子集,其在IQA上应用的越来越多。这是由于自然图像的像素强度分布不同于湿疹的图像像素强度分布,前者更加遵循高斯分布,而不自然或者失真的图像不遵循或者导致高斯分布变形。由此引出基于NSS的图像质量评估的算法BRISQUE。
BRISQUE:No-Reference Image Quality Assessment in the Spatial Domain
BRISQUE,根据其全称可知,它是在空间域内的这一种无参考图像质量评估算法。该算法将一张图像(各种失真和程度)表示成一个由人工设计的特征向量,然后使用支持向量机SVM进行分类。特征向量的长度为36,每张图片需要经过两次提取,每次提取18个特征元素,第二次提取在原图的基础上进行缩放0.5倍。其提取特征向量的方法大致经过, 从图像中提取mean subtracted contrast normalized (MSCN) coefficients,亮度去均值对比度归一化系数,将MSCN系数拟合成asymmetric generalized Gaussian distribution(AGGD)非对称性广义高斯分布。

注意,这里指出图像输入的是亮度值。C的作用是防止分母是0。得出的MSCN系数:I冒,是和原图尺寸一样大小的矩阵。有了就可以计算零均值广义高斯分布(GGD)的形状参数(两个,这两个参数可以作为上面提到的每一次提取的十八个特征元素的前两个)。
剩下的16个参数由非对称广义高斯分布拟合MSCN相邻系数内积,并且同个四个非对称广义高斯分布(AGGD)拟合MSCN四个方向上的内机,每一个AGGD的形状参数个数为四个。总之,这些人工设计的特征,计算量和公式都是有点复杂的,相关原理解释可以查看该篇博客.
有了特征向量,就可以使用SVM进行训练了。原理或者公示介绍太多,还是代码来的清楚。这里提供一份C++和Python版本实现算法github地址。我尝试这跑了一下,感觉准确度不太好。两幅图像差不多,但是一副图像添加可一些特效文字。分数相差很大。并且需要说明的是,分数越高质量越差。
之所以简单的介绍BRISQUE是因为,在图像领域通过深度学习提取特征或者进行分类得出的结果已经大多好于传统算法。BRISQUE成为了另一种方法的结果对比算法。这也侧面说明了BRISQUE算法的经典。
RankIQA:Learning from Rankings for No-reference Image Quality Assessment
该算法我在之前的一篇博客中进行过简单的介绍。
DIQA:Deep CNN-Based Blind Image Quality Predictor
由于人工打分的数据集数量太小,该方法同rankIQA一样,也是经历过两个阶段的训练。
第一阶段只需要确定一对图片的相关信息是不同程度的失真即可。并且训练的数据需要图像归一化。该归一化可以理解成高频信息的提取。并且通过深度学习来提取失真图像的高频信息丢失部分。通过这种思想的原因在于,1:图像的失真对其低频信息影响不大,2:人眼视觉系统对图像的低频信息的改变不太敏感。所以整个深度学习的训练过程参与数据不是原图像,而是图像提取的高频信息。图像的高频信息可以通过使用边缘检测算子对边缘信息提取的方法,也可以使用原图减去原图的高斯模糊图(图像进行高斯模糊后,丢失了高频信息)的间接方法。
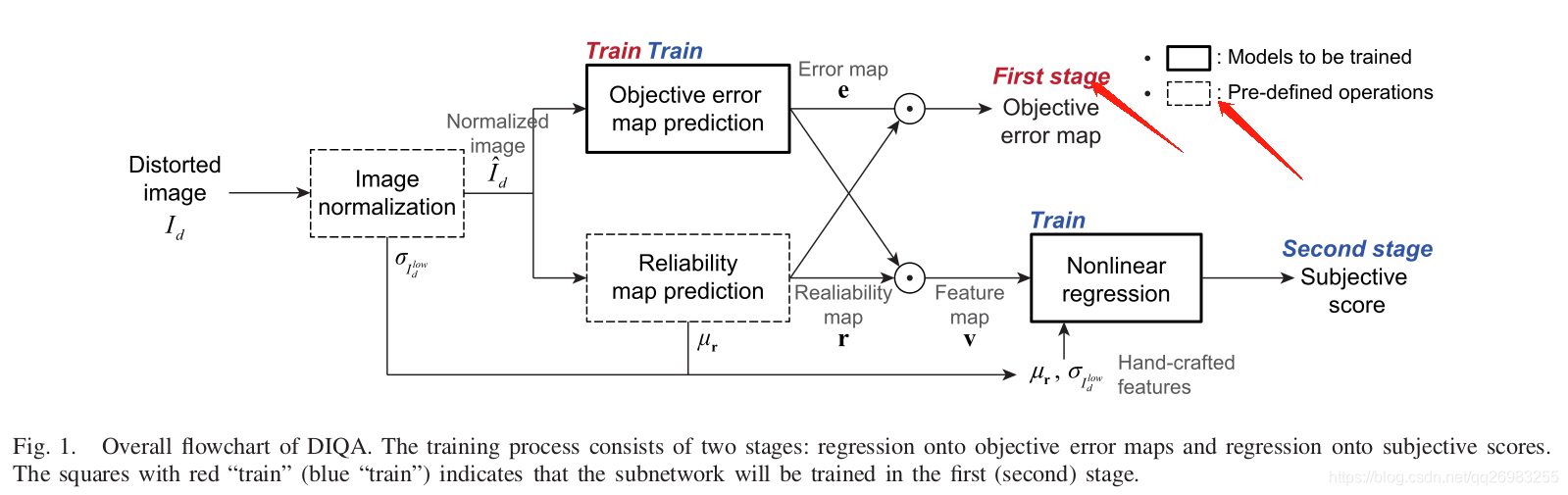
该图是整个训练的流程图,我在上图标注了两个箭头,一个箭头是第一阶段训练的位置,第二个是提醒一下虚框是预定义操作。
我们看到,first stage的目标有两个输入,一个是error map另外一个就是realiability map。
其中error map是通过深度学习网络而形成的特征图。其结构为:
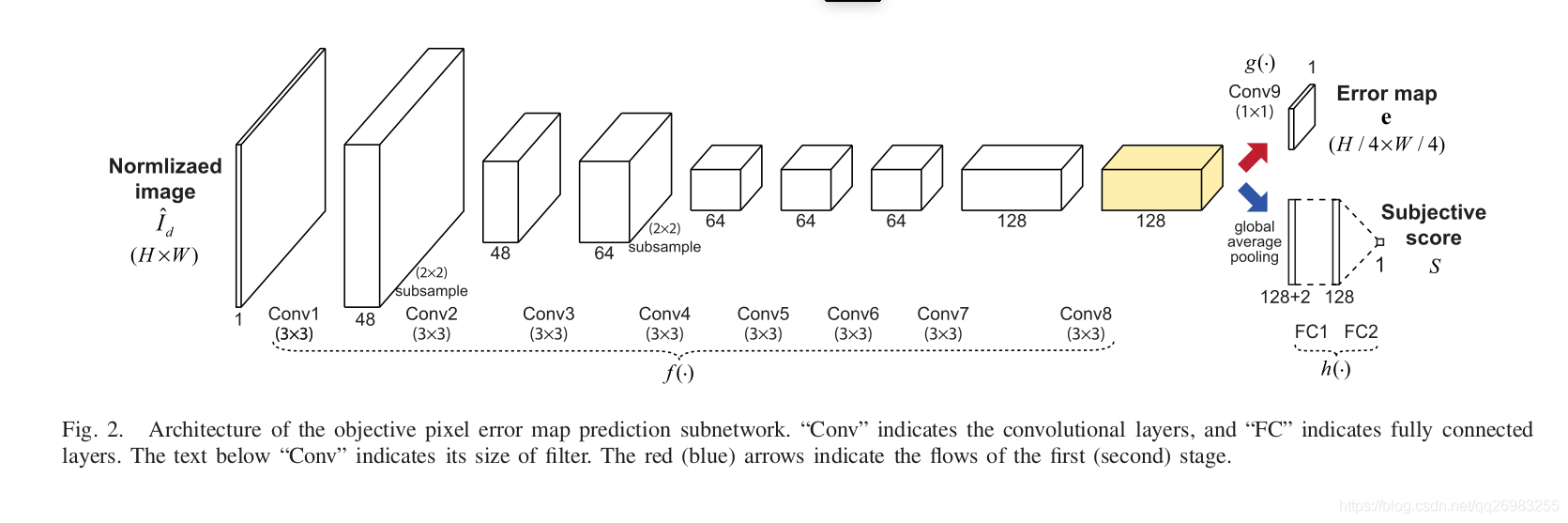
从conv1到conv8使用f(*)表示,g(*)是conv9。从1-8 进行了四倍的缩小。8-9中,将channel数将为1。
那么loss函数表示方法为:
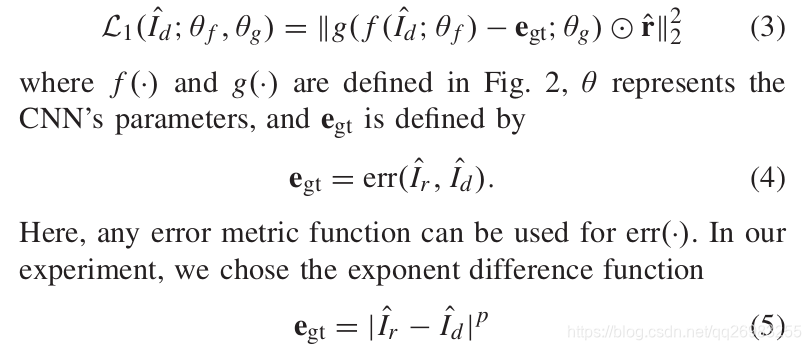
其中,Ir冒为参考图像(原图)的高频信息图像,Id冒为失真图像的高新信息图。P为指数参数。因为图像是通过0-1的数表示,当P为1是就是参考图像与失真图像差的绝对值。并且都是很小的数。当底数小于1,那么指数也小于1,那么结果肯定比底数大。这里相当于对参考图像与失真图像差的绝对值进行放大的作用(扩展一下小知识,图像处理中的色彩校正,伽马矫正)。还有一个参数r冒的意义:它即是reliability map。
![]()
![]()
其中,r冒存在的意义:r中有太多零值,因为零对图像上的空间信息上无意义,做的一种变换。r是针对纹理部分与平坦部分,进行了一种权值分配(高频部分权重大大增加)。因为模型输入的是失真图像的高频信息,结合loss函数克制,该系数可以使消除平坦部分对预测error map所产生的不利影响。
上述设计的到参数以及公式,使用Python语言,tensorflow框架下实现的代码
def calculate_error_map(I_d_data, I_r_data):
I_d = image_preprocess(I_d_data)
I_r = image_preprocess(I_r_data)
r = rescale(average_reliability_map(I_d, 0.2), 1 / 4)
e_gt = rescale(error_map(I_r, I_d, 0.2), 1 / 4)
return I_d, e_gt, r
其中,返回的三个参数分别为,失真函数的高频部分(也是网络的输入),e_gt为loss函数中的公式5。r即为r冒。
loss函数:
tf.reduce_mean(tf.square((y_true - y_pred) * r))其中y_pred为conv9的输出,y_true为e_gt
def normalize_kernel(kernel: tf.Tensor) -> tf.Tensor:
return kernel / tf.reduce_sum(kernel)
def gaussian_kernel2d(kernel_size: int, sigma: float, dtype=tf.float32) -> tf.Tensor:
_range = tf.range(kernel_size)
x, y = tf.meshgrid(_range, _range)
constant = tf.cast(tf.round(kernel_size / 2), dtype=dtype)
x = tf.cast(x, dtype=dtype) - constant
y = tf.cast(y, dtype=dtype) - constant
kernel = 1 / (2 * math.pi * sigma ** 2) * tf.exp(-(x ** 2 + y ** 2) / (2 * sigma ** 2))
return normalize_kernel(kernel)
def gaussian_filter(image: tf.Tensor, kernel_size: int, sigma: float, dtype=tf.float32) -> tf.Tensor:
kernel = gaussian_kernel2d(kernel_size, sigma)
if image.get_shape().ndims == 3:
image = image[tf.newaxis, :, :, :]
image = tf.cast(image, tf.float32)
image = tf.nn.conv2d(image, kernel[:, :, tf.newaxis, tf.newaxis], strides=1, padding='SAME')
return tf.cast(image, dtype)
def image_shape(image: tf.Tensor, dtype=tf.int32) -> tf.Tensor:
shape = tf.shape(image)
shape = shape[:2] if image.get_shape().ndims == 3 else shape[1:3]
return tf.cast(shape, dtype)
def scale_shape(image: tf.Tensor, scale: float) -> tf.Tensor:
shape = image_shape(image, tf.float32)
shape = tf.math.ceil(shape * scale)
return tf.cast(shape, tf.int32)
def rescale(image: tf.Tensor, scale: float, dtype=tf.float32, **kwargs) -> tf.Tensor:
assert image.get_shape().ndims in (3, 4), 'The tensor must be of dimension 3 or 4'
image = tf.cast(image, tf.float32)
rescale_size = scale_shape(image, scale)
rescaled_image = tf.image.resize(image, size=rescale_size, **kwargs)
return tf.cast(rescaled_image, dtype)
def read_image(filename: str, **kwargs) -> tf.Tensor:
stream = tf.io.read_file(filename)
return tf.image.decode_image(stream, **kwargs)
def image_preprocess(image: tf.Tensor) -> tf.Tensor:
image = tf.cast(image, tf.float32)
image = tf.image.rgb_to_grayscale(image)
image_low = gaussian_filter(image, 16, 7 / 6)
image_low = rescale(image_low, 1 / 4, method=tf.image.ResizeMethod.BICUBIC)
image_low = tf.image.resize(image_low, size=image_shape(image), method=tf.image.ResizeMethod.BICUBIC)
return image - tf.cast(image_low, image.dtype)
def error_map(reference: tf.Tensor, distorted: tf.Tensor, p: float=0.2) -> tf.Tensor:
assert reference.dtype == tf.float32 and distorted.dtype == tf.float32, 'dtype must be tf.float32'
return tf.pow(tf.abs(reference - distorted), p)
def reliability_map(distorted: tf.Tensor, alpha: float) -> tf.Tensor:
assert distorted.dtype == tf.float32, 'The Tensor must by of dtype tf.float32'
return 2 / (1 + tf.exp(- alpha * tf.abs(distorted))) - 1
def average_reliability_map(distorted: tf.Tensor, alpha: float) -> tf.Tensor:
r = reliability_map(distorted, alpha)
return r / tf.reduce_mean(r)通过上述代码,既可以进行DIQA的第一阶段训练,也是最为核心的训练阶段。然后在第一阶段的基础上进行第二阶段的训练,在第二阶段时,需要添加两个特征变量。这个在流程图上已经很好的注明,并且也不难理解。但是需要说明的是,添加的位置(第一个全连接层还是第二个全连接成)效果稍微有点差别,但是并不能说谁好谁坏。在论文中对添加的位置(填不填加)对结果的影响都有统计,在不同的数据集上也不能确定孰好孰坏。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









