






An Analysis of Scale Invariance in Object Detection – SNIP
简介
这篇文章分析了小尺度与预训练模型尺度之间的关系, 并且提出了一个和 Cascade R-CNN 有异曲同工之妙的中心思想: 要让输入分布接近模型预训练的分布(本文主要探讨尺度的分布不一致带来的问题).
之后利用分析的结论, 提出了一个多尺度训练(MST)的升级版:Scale Normalization for Image Pyramids (SNIP).
分类和检测的难度差异
上了深度网络后, 分类任务已经做到了误差率2%(ImageNet). 为什么在COCO上才62%? 这么悬殊的距离主要因为检测数据集中包含了大量小物体, 他们成了绊脚石.

* 结论: 检测器必须同时应对如此之大的尺度变化的样本, 这就导致了我们使用ImageNet(或其他分类)预训练模型时, 有严重的domain-shift问题.
各种对付尺度变化的方法
- 深浅特征融合
- 改变卷积核(Dilated/Deformable)来识别大物体
- 每层独立predict
- 多尺度训练/测试
作者抛出的两个问题
- 检测中把图片放大了再使用对性能提升至关重要吗 (通常480x640的尺寸要放大到800x1200)?
为了检测小物体, 可以不可以在ImageNet上用低像素图片预训练一个缩放倍数较小的CNN? - 用ImageNet做预训练模型的时候训练检测器的时候, 是否所有尺寸的object都可以参与进来?
还是只是一小部分在范围内的模型(如 64x64 到 256x256)
分析现存的解决方法
浅层小物体, 深层大尺度
- 例子: SDP, SSH, MS-CNN.
- 缺点: 在浅层预测小物体时, 是以牺牲语意抽象性来实现的.
特征融合/特征金字塔
尽管Feature Pyramids 有效的综合了多卷积层特征图信息,但是对于very small/large objects 检测效果不是很好
- 例子: FPN, Mask-RCNN, RetinaNet
- 缺点: 若一个25x25的物体, 即使融合上采样x2后也仍然只有50x50. 距离预训练模型224x224还是有很大差距.
多尺度分类问题
借由分类模型的实验, 探索检测中domain-shift带来的影响. 检测中的Domain-shift主要来自于训练/测试尺度不匹配:
* 训练800x1200. 因为显存有所限制, 不能更大了
* 测试1400x2000. 为了提升小物体检测性能

CNN-B: 原图训练 / 伪高清测试
CNN-B是一个在224x224尺度上训练的模型, 其
stride=2
s
t
r
i
d
e
=
2
. 我们将测试图片降采样到 [48x48, 64x64, 80x80, 96x96,128x128], 然后再放大回224x224用于测试. 结果如图:
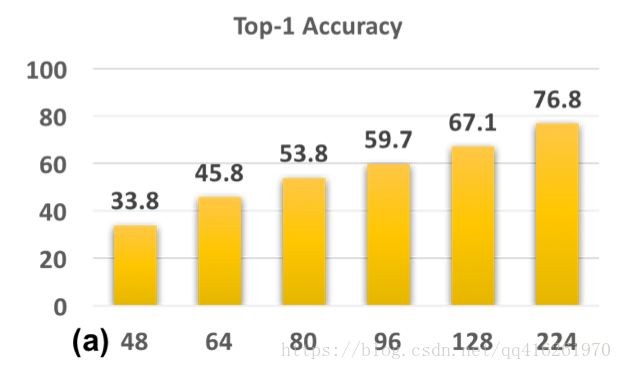
* 结论: 训/测尺度(实际上是清晰度)差距越大, 性能跌的越厉害. 因为不用与训练尺度相互匹配的尺度进行测试, 会使得模型一直在sub-optimal发挥.
CNN-S: 低清训练 / 低清测试
CNN-S是根据上述原则, 我们做一个训/测尺度匹配的实验. 选取48x48作为训/测尺度. 并且 stride=1 s t r i d e = 1 , 因为如果不修改 stride s t r i d e 的话很容易就卷没了. 模型架构变了, 于是针对与上文CNN-S的可比较性问题, 作者说:
After-all, network architectures which obtain best performance on CIFAR10 [17] (which contains small objects) are different from ImageNet
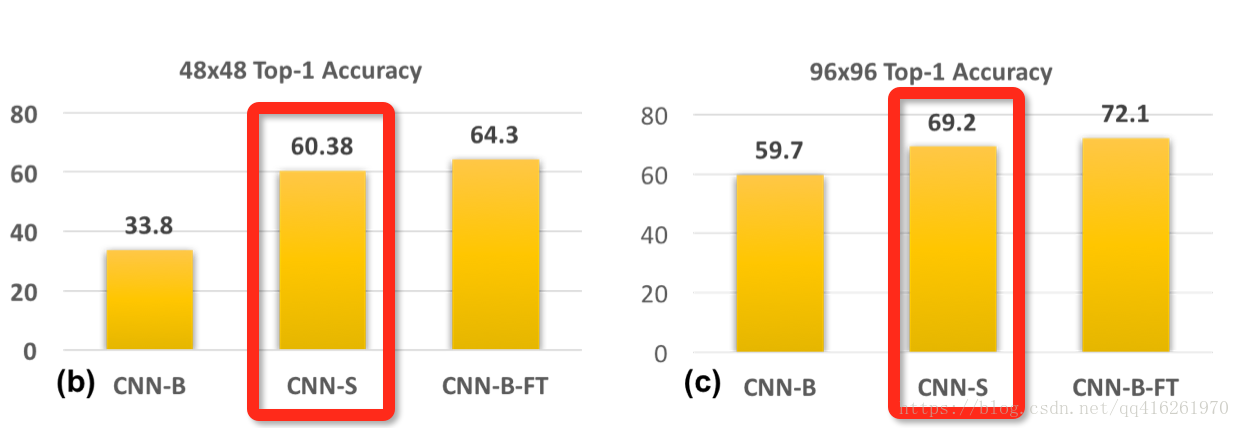
根据结果看到, 训/测尺度匹配后, 性能大幅提升. 同样将48换成96也得到一致的结果.
CNN-B-FT: 原图训练, 伪高清微调 / 伪高清测试
我们很容易想到的另一种方法就是, 为了在伪高清尺度测试, 我们就把由原图训练的CNN-B用伪高清去做微调. 最终CNN-B-FT的结果甚至好于CNN-S.
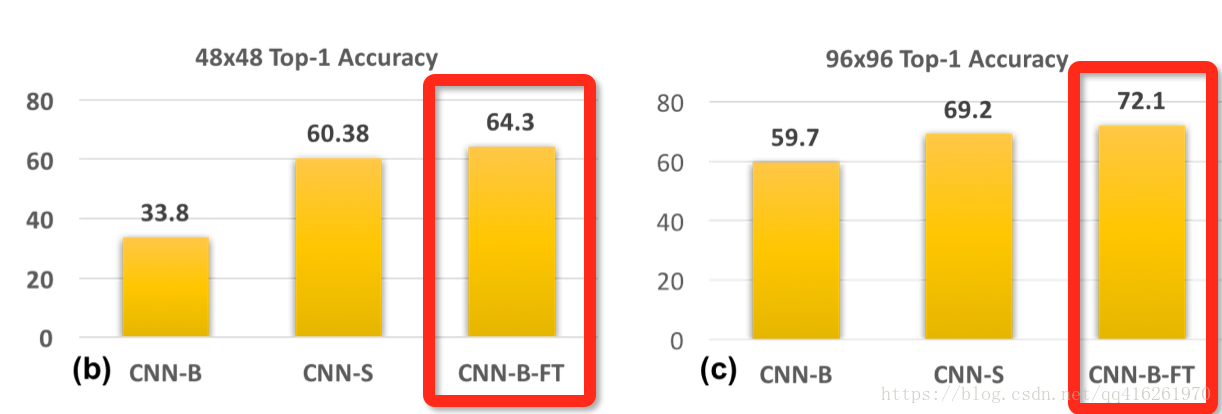
结论
- 从CNN-B-FT的实验可以得出: 在高清训练集学出来的模型依然有办法在低清晰度的图片上做预测. 直接用低清晰度图片微调好过将 stride s t r i d e 降低重新训练一个.
- 推广到目标检测上, 当尺度不同时, 我们可以选择更换在ImageNet上pre-trained网络架构. 或者我们根据上述结论, 直接使用同一个网络架构, 因为在分类任务上学到的大目标权重可以帮助我们在小目标上的分类.
分析尺度变化
数据库中原图尺寸为640x48, 小物体是小于32x32的物体
实验 800all 800 a l l vs 1400all 1400 a l l
- 实验设置: 我们选用800x1200和1400x2000两种训练尺度, 分别记作 800all 800 a l l 和 1400all 1400 a l l . 测试时, 我们都使用1400x2000的尺度.
- 结果比较:
| 800all 800 a l l | 1400all 1400 a l l |
|---|---|
| 19.6 | 19.9 |
* 分析: 正如之前分析的一样, 当训/测尺度一致时, 得到的结果最好. 所以
1400all
1400
a
l
l
胜出.
* 问题: 但是为什么只超过了一点点呢? 因为在考虑小物体的分类性能而放大图片的同时, 也将中/大尺度的样本放大得太大, 导致无法正确识别.
实验 1400<80px 1400 < 80 p x
- 实验设置: 用了大图, 却被中/大尺寸的样本破坏了性能, 那么我们就只用小于某阈值的样本进行训练, 即在原图尺寸中 >80px > 80 p x 的样本直接抛弃, 只保留 <80px < 80 p x <script type="math/tex" id="MathJax-Element-256"><80px</script>的样本参与训练.
- 结果比较:
| 1400<80px 1400 < 80 p x | 800all 800 a l l | 1400all 1400 a l l |
|---|---|---|
| 16.4 | 19.6 | 19.9 |
* 分析问题: 跟预想的不一样, 为什么性能下降这么多? 其根本原因是因为这种做法抛去了太多的样本(~30%), 导致训练集丰富性下降, 尤其是抛弃的那个尺度的样本.
实验多尺度训练(MST)
- 实验设置: 多尺度训练保证了各个尺度的样本, 都有机会被缩放到合理的尺度区间参与训练.
- 结果比较:
| 1400<80px 1400 < 80 p x | 800all 800 a l l | 1400all 1400 a l l | MST M S T |
|---|---|---|---|
| 16.4 | 19.6 | 19.9 | 19.5 |
* 分析问题: 其最终性能跟 800all 800 a l l 没太大差别, 主要原因和”实验 800all 800 a l l vs 1400all 1400 a l l 类似, 因为这一次引入了极大/极小的训练样本.
Scale Normalization for Image Pyramids (SNIP)
- 思想: SNIP是MST的升级版. 只有当这个物体的尺度与预训练数据集的尺度(通常224x224)接近时, 我们才把它用来做检测器的训练样本.
- 还基于一个假设, 即不同尺度的物体, 因为多尺度训练, 总有机会落在一个合理的尺度范围内. 只有这部分合理尺度的物体参与了训练, 剩余部分在BP的时候被忽略了
SNIP操作
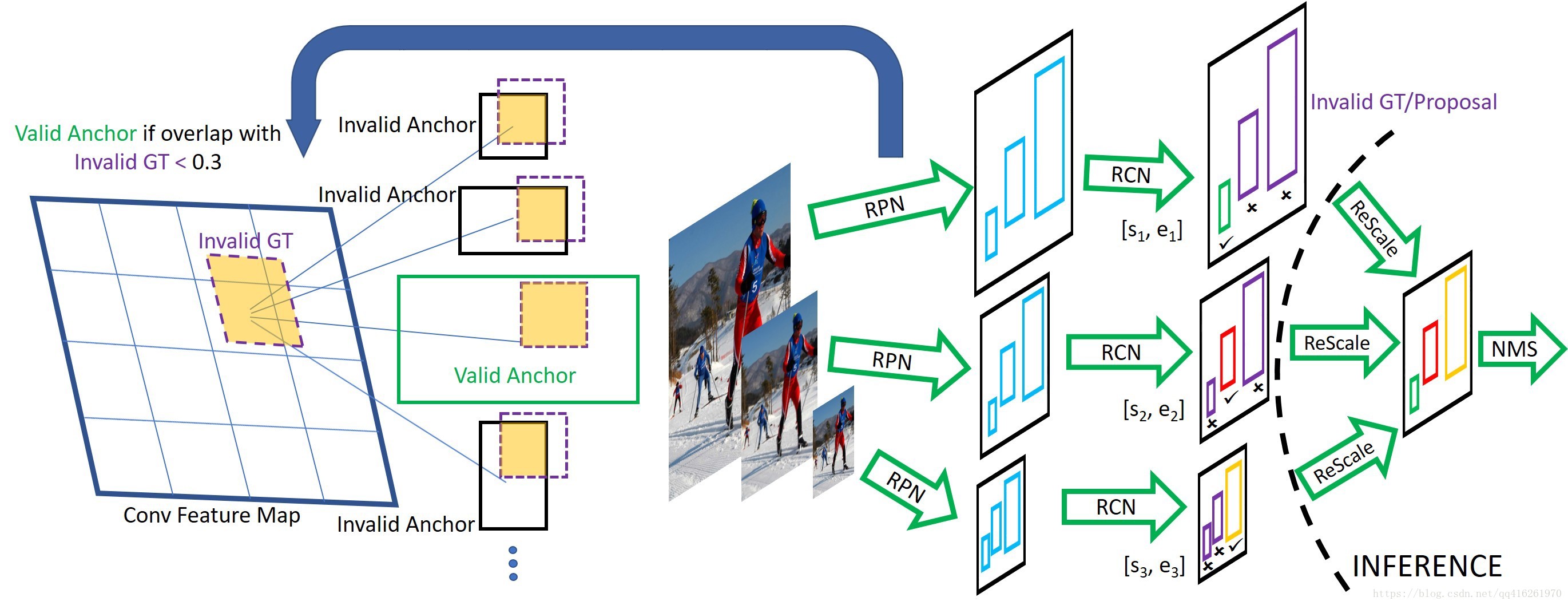
RPN阶段
- 用所有的GroundTruth给Anchors分配好+/-标签
- 根据第 i i 个尺度下的valid range: , 将GroundTruth根据是否落在范围内分为Valid/Invalid GT
- 去除那些 IoU(anchors|InvalidGT)>0.3 I o U ( a n c h o r s | I n v a l i d G T ) > 0.3 的Anchors
FC阶段
- 用所有的GroundTruth给ProposalRoIs分配好类别标签
- 弃用不在 [si,ei] [ s i , e i ] 范围内的GT和Proposals
- 全被剔除了的处理:
If there are no ground truth boxes within the valid range at a particular resolution in an image, that image- resolution pair is ignored during training
测试阶段
- 用多尺度正常进行测试
- 在合并多尺度Detection之前, 只在各个尺度留下满足其条件的Detection
- Soft-NMS合并 (对比的其他模型有没有soft-nms?)
Sub-Image采样
考虑到GPU显存, 需要crop图片来满足显存局限.
* 用最少数量的1000x1000的chips来囊括所有的小物体. 如果没有小物体的话, 这个区域就不需要进行任何计算, 加速训练.
* 操作:
只对1400x2000的图片进行采样. 800x1200/480x640/图片无小物体时, 不进行采样
sampled_chips = []
while num_sampled_unique_object < num_object:
chips = get_random_chips(size=(1000,1000), number=50)
sampled_chips.append( chips.where(chips.num_objects is max ) )
sampled_chips = sampled_chips.truncate_boundary() 














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









