







线性回归与逻辑回归
线性回归
对于分类的问题,数据是离散的。对于回归,目标值是连续的。线性回归其目的是为了寻找一定的趋势。
在一个n维的模型中。其模型可以使用
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
d
x
d
+
b
f(x)=w_1x_1+w_2x_2+...+w_dx_d+b
f(x)=w1x1+w2x2+...+wdxd+b
表示模型称为线性模型。w称为权重,b称为偏置项。
回归是一种迭代的算法,对于预测不可能和实际值一致,因此我们需要一个值来描述预测是否准确。这个定义为损失函数。
对于最小二乘法,其损失函数为误差的平方和。
梯度下降
对于函数中的w参数值,对于數據量较多的情况下,我们无法进行直接算法得出因此需要另外一种方法来计算参数值。
w
=
w
0
+
α
∂
f
∂
w
0
w=w_0+\alpha\frac{\partial f}{\partial w_0}
w=w0+α∂w0∂f
f为损失函数,
α
\alpha
α为学习速率需要手动指定。
∂
f
∂
w
0
\frac{\partial f}{\partial w_0}
∂w0∂f表示方向,需要沿着这个函数下降的方向找,最后能找最低点。
参考文章:https://www.cnblogs.com/itmorn/p/11129806.html
批量梯度下降BGD
在批量下降中每次计算一次一个参数的梯度下降都需要计算所有的样本点。
随机梯度下降SGD(大坑待填)
随机梯度在批量下降中每次计算以一个随机的点为基础计算所需要下降的梯度。
小批量随机梯度下降(大坑待填)
小批量梯度下降介于BGD与SGD之间每次取一部分来计算梯度下降的方向。
回归性能评估
均方误差(MSE)
线性回归特点
线性回归器是最简单、易用的回归模型,但是其并不能解决过拟合问题。
共线性特征
多重共线性(Multicollinearity)是指线性回归模型中的解释变量之间由于存在较精确相关关系或高度相关关系而使模型估计失真或难以估计准确。完全共线性的情况并不多见,一般出现的是在一定程度上的共线性,即近似共线性。
过拟合与欠拟合(线性回归)
过拟合的原因
1、原始特征过多,存在一些嘈杂特征,模型过于复杂
解决办法
1、进行特征选择,消除关联性大的特征
2、交叉验证
3、正则化
欠拟合的原因
1、原始特征较少
解决办法
1、进行特征选择,消除关联性大的特征
2、交叉验证
正则化
作用:可以使得W的每个元素很小,都接近与0
优点:越小的参数说明模型越简单,越简单的参数越不容易产生过拟合现象
正则化就是通过对模型参数进行调整(数量和大小),降低模型的复杂度,以达到可以避免过拟合的效果。正则化是机器学习中的一种叫法,其它领域内叫法各不相同:
机器学习把L1和L2叫正则化,统计学领域叫惩罚项,数学领域叫范数。
正则化是一个典型的用于选择模型的方法。它是结构风险最小化策略的实现,是在经验风险上加一个正则化项或惩罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。
R ( f ) = 1 N ∑ i = 1 n L ( y i , f ( x i ) ) + λ J ( f ) R(f)=\frac1N\sum_{i=1}^n{L(y_i,f(x_i))}+\lambda J(f) R(f)=N1i=1∑nL(yi,f(xi))+λJ(f)
- 第一项即损失函数的表示
- 后一项中的J(f)就表示模型的复杂度 ,它是定义在假设空间F上的泛函(通常是指一种定义域为函数,而值域为实数的“函数”。换句话说,就是从函数组成的一个向量空间到实数的一个映射。也就是说它的输入为函数,而输出为实数,来自维基百科),模型f越复杂,复杂度J(f)就越大;反之,模型越简单,复杂度J(f)就越小。也就是说,复杂度表示了对复杂模型的惩罚。λ≥0是系数,用以权衡经验风险和模型复杂度。结构风险小的模型往往对训练数据以及位置的测试数据都有较好的预测。
Lasso回归
具有L1正则化的线性最小二乘法。
岭回归
具有L2正则化的线性最小二乘法。
岭回归:回归得到的回归参数更符合实际,更可靠,另外,能让估计参数的波动范围变小,变得更稳定。在存在病态数据较多的研究中具有较大的实用价值。
ElasticNet回归
具有L1与L2正则化的线性最小二乘法。

逻辑回归
一种适用于处理因变量为分类变量的回归问题,最常见的是二分类或者二项分布问题。例如通过一个人的身高体重,肤色等判定是否容易生病。0表示生病,1表示不生病。这类问题被称为逻辑回归问题。虽然说是回归,但是逻辑回归其实是一种分类问题。
广义线性模型(GLM)
对于线性回归,其模型为
y
=
θ
T
x
y=\theta^Tx
y=θTx
对于线性模型来说其数值为连续性的,无法直接用于分类问题。需要对于预测值进行一次再处理,这个处理的函数称之为连接函数(link function),即下图中的
G
G
G 函数。处理后的到的GLM如下图所示:

广义线性模型是一种应用灵活的线性模型,它认为因变量是属于指数簇分布的(可理解为是一种限制),即对于输入的
X
X
X,
Y
Y
Y 具有如下形式的分布:

指数族分布
如果一类分布可以写成如下形式,则它可以叫做 指数族分布 (exponential family distributions) 。

如果分布中的T,A,h 固定,当
η
\eta
η 改变时,将在这个家族中获得不同的分布。
伯努利分布(也叫两点分布,0-1分布)、泊松分布和高斯分布都属于指数族分布
sigmod函数
Sigmoid函数是一个有着优美S形曲线的数学函数,在逻辑回归、人工神经网络中有着广泛的应用。Sigmoid函数的数学形式是:
f ( x ) = 1 1 + e − x f\left(x\right)=\frac1{1+e^{-x}} f(x)=1+e−x1
当X为负无穷时,sigmoid函数趋近于0,当X为正无穷时,sigmoid函数趋近于1。同时这个函数连续,光滑,连续单调。因此被用在逻辑回归模型的分类器上。Sigmod值可以将其理解为概率值。
为什么选用sigmod函数?
其根本的原因在于逻辑回归前提是,我们假设了变量是服从伯努利分布的(也就是0-1分布,这也是为什么逻辑回归是适用于二分类问题的)

经过推导后我们得出结论,当因变量服从伯努利分布时,广义线性模型就为逻辑回归。
逻辑回归公式
h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x h_\theta\left(x\right)=g\left(\theta^Tx\right)=\frac1{1+e^{-\theta^Tx}} hθ(x)=g(θTx)=1+e−θTx1
逻辑回归的损失函数、优化
与线性回归原理相同,但是由于是分类问题,只能通过梯度下降求解。
对于逻辑回归分为两种结果,即一类的结果,二类的结果。其损失函数实际含义可以描述为预测逻辑回归的准确性,当预测完全准确时,损失函数为0。其完整的损失函数可以如下表示:
cos t ( h θ ( x ) , y ) = ∑ i = 1 m − y i log ( h θ ( x ) ) − ( 1 − y i ) log ( 1 − h θ ( x ) ) \cos t\left(h_\theta\left(x\right),y\right)=\sum_{i=1}^m-y_i\log\left(h_\theta\left(x\right)\right)-\left(1-y_i\right)\log\left(1-h_\theta\left(x\right)\right) cost(hθ(x),y)=i=1∑m−yilog(hθ(x))−(1−yi)log(1−hθ(x))
损失函数的形式为交叉熵。
逻辑回归的损失函数为什么不选择MSE(均方差)?
LR的基本形式如下

假如一元逻辑回归, 如果使用梯度下降的方法对w和b进行更新,那么就需要将损失函数对这两个参数进行求导。
![[公式]](https://img-blog.csdnimg.cn/20201118201614862.png#pic_center)
![[公式]](https://img-blog.csdnimg.cn/20201118201627402.png#pic_center)
可以看到 w,b 的更新速率与当前的预测值sigmoid函数的导数有关,sigmoid的图像如下

所以,如果当前模型的输出接近0或者1时,梯度下降更新的参数值就会非常小,接近0,使得求得的梯度很小,损失函数收敛的很慢。
逻辑回归的参数估计
对于二回归问题,我们假定
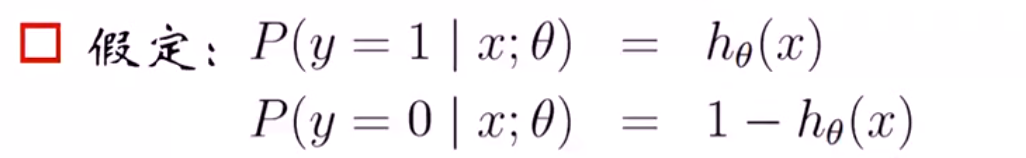
从中可以得到概率一般式
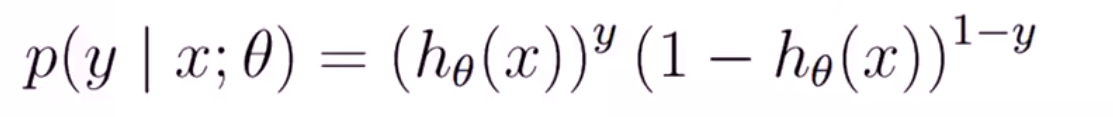
由最大似然估计可以得到
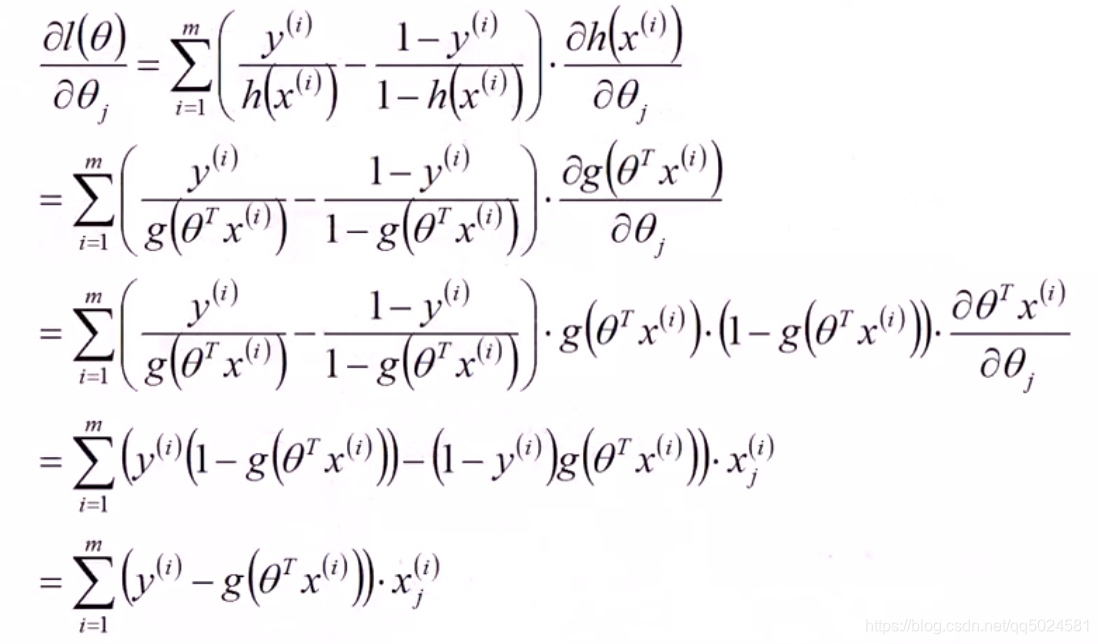
根据梯度的定义,就可以得到逻辑回归的梯度下降公式:
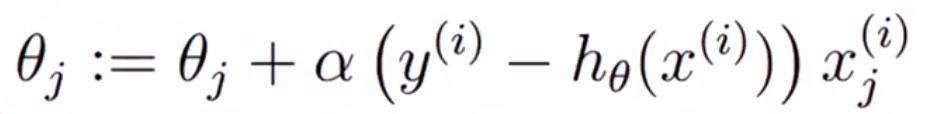
SoftMax分类
一种基于逻辑回归的K分类问题

逻辑回归与线性回归
逻辑回归与线性回归的区别与联系
-
区别
线性回归假设响应变量服从正态分布,逻辑回归假设响应变量服从伯努利分布
线性回归优化的目标函数是均方差(最小二乘),而逻辑回归优化的是似然函数(交叉熵)
线性归回要求自变量与因变量呈线性关系,而逻辑回归没有要求
线性回归分析的是因变量自身与自变量的关系,而逻辑回归研究的是因变量取值的概率与自变量的概率
逻辑回归处理的是分类问题,线性回归处理的是回归问题,这也导致了两个模型的取值范围不同:0-1和实数域
参数估计上,都是用极大似然估计的方法估计参数(高斯分布导致了线性模型损失函数为均方差,伯努利分布导致逻辑回归损失函数为交叉熵) -
联系
两个都是线性模型,线性回归是普通线性模型,逻辑回归是广义线性模型
表达形式上,逻辑回归是线性回归套上了一个Sigmoid函数
判别模型与生成模型
| ____ | 判别模型 | 生成含义 |
|---|---|---|
| ____ | 逻辑回归 | 朴素贝叶斯 |
| 解决问题 | 二分类 | 多分类 |
| 应用场景 | 癌症,二分类需要概率 | 文本分类 |
| 参数 | 正则化力度 | 没有 |
| 同类算法 | K近邻、决策树,随机森林,神经网络 | 隐含马尔科夫模型 |
对于判别模型与生成模型的区别在于:生成模型需要知道先验概率即历史数据,才能进行判断属于某个分类
ROC曲线
在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例的比类,即TPR(在所有实际为阳性的样本中,被正确地判断为阳性之比率。TPR=TP/(TP+FN)),但同时也将更多的负实例当作了正实例,即提高了FPR (在所有实际为阴性的样本中,被错误判断为阳性的概率,称为FPR,FPR=FP/(FP+TN)) 。为了形象化这一变化,在此引入ROC,ROC曲线可以用于评价一个分类器。

AUC面积
当存在两个分类器时,我们可以通过分类器之间是否有相互覆盖得出某个分类器是较为优秀的。也可以通过覆盖面积判断。
AUC面积为ROC曲线的覆盖面积,其覆盖面积的大小表示分类器的好坏。
- AUC = 1,是完美分类器。
- AUC = [0.85, 0.95], 效果很好
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差.
AR自回归模型
利用前期若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型。该模型认为通过时间序列过去时点的线性组合加上白噪声即可预测当前时点,它是随机游走的一个简单扩展。下图中展示了一个时间如果可以表示成如下结构,那么就说明它服从p阶的自回归过程,表示为AR§。其中,ut表示白噪声,是时间序列中的数值的随机波动,但是这些波动会相互抵消,最终是0。
θ
\theta
θ表示自回归系数。
x
(
t
)
=
θ
1
x
(
t
−
1
)
+
θ
2
x
(
t
−
2
)
+
⋯
+
θ
m
x
(
m
−
1
)
+
u
(
t
)
x(t)=\theta_1x(t-1)+\theta_2x(t-2)+\cdots+\theta_mx(m-1)+u(t)
x(t)=θ1x(t−1)+θ2x(t−2)+⋯+θmx(m−1)+u(t)
MA
MA(Moving Average Model)移动平均模型。通过将一段时间的白噪声序列进行加权和,可以得到移动平均方程。表示为MA(q) θ \theta θ表示移动回归系数,ut表示不同时间点的白噪声。
x ( t ) = θ 1 u ( t − 1 ) + θ 2 u ( t − 2 ) + ⋯ + θ m u ( m − 1 ) + u ( t ) x(t)=\theta_1u(t-1)+\theta_2u(t-2)+\cdots+\theta_mu(m-1)+u(t) x(t)=θ1u(t−1)+θ2u(t−2)+⋯+θmu(m−1)+u(t)
ARMA
ARMA(Auto Regressive and Moving Average Model)自回归移动平均模型,自回归移动平均模型是自回归和移动平均模型两部分组成。所以可以表示为ARMA(p,q)。p是自回归阶数,q是移动平均阶数。
x
(
t
)
=
θ
1
x
(
t
−
1
)
+
θ
2
x
(
t
−
2
)
+
⋯
+
θ
m
x
(
m
−
1
)
+
θ
1
u
(
t
−
1
)
+
θ
2
u
(
t
−
2
)
+
⋯
+
θ
m
u
(
m
−
1
)
+
u
(
t
)
x(t)=\theta_1x(t-1)+\theta_2x(t-2)+\cdots+\theta_mx(m-1)+\theta_1u(t-1)+\theta_2u(t-2)+\cdots+\theta_mu(m-1)+u(t)
x(t)=θ1x(t−1)+θ2x(t−2)+⋯+θmx(m−1)+θ1u(t−1)+θ2u(t−2)+⋯+θmu(m−1)+u(t)
从式子中可以看出,自回归模型结合了两个模型的特点,其中AR可以解决当前数据与后期数据之间的关系,MA可以解决随机变动也就是噪声的问题。
时间序列分析
时间序列,就是按时间顺序排列的,随时间变化的数据序列。
生活中各领域各行业太多时间序列的数据了,销售额,顾客数,访问量,股价,油价,GDP,气温。。。
随机过程的特征有均值、方差、协方差等。
如果随机过程的特征随着时间变化,则此过程是非平稳的;相反,如果随机过程的特征不随时间而变化,就称此过程是平稳的。
下图所示,左边非稳定,右边稳定。
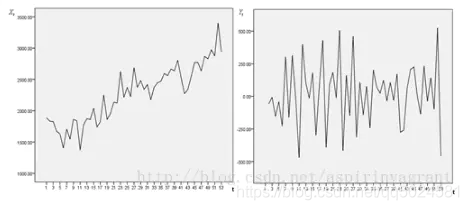
非平稳时间序列分析时,若导致非平稳的原因是确定的,可以用的方法主要有趋势拟合模型、季节调整模型、移动平均、指数平滑等方法。
若导致非平稳的原因是随机的,方法主要有ARIMA(autoregressive integrated moving average)及自回归条件异方差模型等。
ARIMA
ARIMA(Auto Regressive Integrate Moving Average Model)差分自回归移动平均模型。ARIMA模型是为了解决在ARMA基础上,非平稳系列的模型。也是基于平稳的时间序列的或者差分化后是稳定的,另外前面的几种模型都可以看作ARIMA的某种特殊形式。表示为ARIMA(p, d, q)。p为自回归阶数,q为移动平均阶数,d为时间成为平稳时所做的差分次数,也就是Integrate单词的在这里的意思。














 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









