







目录
摘要 2
1引言 5
1.1 课题背景和意义 5
1.2 CT成像基本原理 6
1.3 国内外研究现状及趋势 10
1.4论文主要研究内容及结构安排 12
2 与研究相关卷积神经网络概要 14
2.1 与研究相关深度学习卷积神经概要 14
2.1.1 卷积层 14
2.1.2 反卷积 16
2.1.3 激活层 17
2.1.5 全连接层 18
2.1.4 池化层 18
2.1.6 损失函数 19
2.1.7 优化算法 20
2.2 相关卷积神经网络接结构阐述 20
2.2.1 VGG 20
2.2.2 ResNet 21
2.2.3 Inception模型 22
2.2.4 生成对抗网络 22
2.3 图像质量定量评价参数 24
3 基于卷积神经网络的低剂量CT钙化点去噪研究 25
3.1 残差编码解码低剂量CT去噪结构 26
3.1.1 去噪模型 26
3.1.2 去噪网络结构 27
3.2 头部数据集 28
3.2.1 数据集介绍及处理 28
4.2.2 钙化点数据分析 29
4.2.3 网络设计 32
4.2.4 损失函数设计 33
3.3 网络训练 38
3.3.1 训练参数 38
4.3.2 训练环境 38
3.4 实验结果及分析 38
3.4.1 数据处理方案效果对比 38
3.4.2 实验结果 39
3.5 本章小结 41
4 基于生成对抗网络的非监督低剂量CT去噪算法研究 42
4.1 CycleGAN生成对抗网络框架介绍 43
4.2 基于深度学习的非监督低剂量CT去噪网络研究 44
4.2.1 生成器设计 45
4.2.2 判别器结构 49
4.2.3 损失函数调整 51
4.3 训练数据集 53
4.3.1 胸腹部临床数据 53
4.3.2 MAYO公开集数据 54
4.3.3 数据处理 55
4.4 网络训练与实验结果 55
4.4.1 训练参数说明 55
4.4.2 实验结果 56
5.5 本章总结 61
6 全文总结及展望 61
6.1 全文总结 61
6.2 展望 62
参考文献 62
摘要
1895年德国物理学家伦琴W.K.发现X射线(又称伦琴射线),X射线发明后英国电子工程师亨斯菲尔德(Hounsfield)于1967年成功制作了第一台CT机器。X射线计算机断层扫描(Computed Tomography,CT)以扫描时间快、成像清晰等特点在医学临床诊断方面广泛应用。CT对人体进行拍摄时所用的X射线产生的辐射会对人体造成伤害,近年来CT辐射问题受到人们越来越多的重视。人们用低剂量CT扫描方法来降低辐射减少对人体产生的危害,但是低剂量CT图像会产生噪声等导致CT图像质量下降,直接影响医生对病人的病情诊断。
为了提高低剂量CT图像质量,本文基于深度学习卷积神经网络方法对低剂量CT去噪图像后处理方法进行研究。针对目前基于深度学习低剂量CT去噪方法中存在的问题,从两个方面进行改进。主要工作如下:
(1)针对存在钙化点的低剂量CT数据提出了一种可以保留钙化点的低剂量CT卷积神经网络去噪方法。由于CT图像中钙化点一般较小且含钙化点的数据较少,一般的卷积神经网络会将较小的钙化点当作噪声点去掉。研究首先设计一种钙化点添加方法,对训练数据进行预处理。然后设计出满足要求的低剂量CT去噪网络。最后设计两种不同的损失函数,卷积神经网络采用这两种损失函数分两步相继训练。通过与目前常用方法进行对比研究,证明提出的方法可以保留“钙化点”的基础上完成了低剂量CT去噪。
(2)提出了一种可以利用结构不同的非对齐低剂量CT和标准剂量CT图像进行无监督训练的深度学习卷积神经网络。目前大多基于深度学习的低剂量CT去噪算法需要大量结构相同的(对齐)低剂量CT图像和标准剂量CT图像进行训练。人体胸腹部等非刚性部位获得对齐数据比较困难,限制了基于深度学习的低剂量CT去噪算法的应用范围。本文通过CycleGAN生成对抗网络框架,设计高效生成器和判别器,利用非对齐CT数据进行训练并得到了良好效果。拓宽了深度学习卷积神经网络低剂量CT去噪的范围。
关键词:低剂量CT 卷积神经网络 去噪 钙化点 非对齐
Abstract
In 1895, German physicist W.K. roentgen discovered x-ray (also known as roentgen ray). After the invention of X-ray, Hounsfield, the British electronic engineer, successfully made the first CT machine in 1967. X-ray computed tomography (CT) is widely used in clinical diagnosis because of its fast scanning time and clear imaging. In recent years, more and more attention has been paid to the problem of CT radiation. People use low-dose CT scan to reduce the harm of radiation to human body, but low-dose CT image will produce noise, which will lead to the decline of CT image quality, low-quality CT image will affect the doctor’s diagnosis of the disease.
In order to improve the image quality of low-dose CT, this paper studies the image post-processing method of low-dose CT denoising based on deep learning convolution neural network. In view of the existing problems in the denoising method of low dose CT based on deep learning, two improvements are made. The main work is as follows:
(1)(1) A convolution neural network denoising method for low dose CT data with calcification points is proposed. Because the calcification points in CT images are generally small and the data containing calcification points are few, the convolution neural network will remove the small calcification points as noise points. Firstly, a calcification adding method is designed to preprocess the training data. Then a low dose CT denoising network is designed. At last, two different loss functions are designed, which are used to train convolutional neural network in two steps. Compared with the current common methods, it is proved that the proposed method can retain the “calcification” and complete the low-dose CT denoising.
(2)A deep learning convolutional neural network is proposed, which can be used to train unsupervised images of non aligned low dose CT and standard dose CT with different structures. At present, most low-dose CT denoising algorithms based on deep learning need a large number of low-dose CT images with the same structure (alignment) and standard dose CT images for training. It is difficult to get alignment data of non rigid parts such as chest and abdomen, which limits the application of low dose CT denoising algorithm based on deep learning. In this paper, we use cyclegan to generate the network framework, design an efficient generator and discriminator, and use the non aligned CT data to train and get good results. The application of deep learning convolution neural network in low dose CT denoising is extended.
Key words: low dose CT convolution neural network denoising calcification point non alignment
1引言
1.1 课题背景和意义
CT(Computed Tomography)电子计算机断层扫描利用精确准直的X线束等,与灵敏度极高的探测器一同围绕人体做的断面扫描,可以快速获得图像清晰的CT图像应用于疾病的检查;根据所采用的射线不同可分为:X 射线 CT(X-CT)、超声 CT(UCT)以及 γ 射线 CT(γ-CT) 等[1]。1972年发明了第一台CT拍摄设备,并将其成功应用于脑部检查,宣告了CT的诞生同时也开创了数字医学影像临床引用的先河[2,3]。近年来CT技术产生了快速发展,产生如螺旋CT[4],电子束CT[5]等多种CT技术。作为现代影像学的杰出代表,CT已经成为放射诊断领域内不可缺少的一部分,是目前临床诊断中最常见的无损检测手段之一[6]。
科学技术的发展推动人类社会进步,方便人们的生活,同时科学技术使人类社会面临各种各样的风险[7]。CT 技术在为医疗诊断带来极大方便的同时,CT 扫描辐射也正在危害着人类的健康[8],研究表明,过量的X光照射会诱发产生多种疾病,如白血病、癌症、新陈代谢异常及其它一些遗传性疾病[6,9-15]。据报道,患者接受一次全身CT扫描所受到的辐射剂量相当于其位于日本广岛和长崎原子弹爆炸中心2.5km处接受的辐射量大小[16],全球医疗所致年人均辐射剂量在过去10~15年的时间里约增加1倍,尤其在高度发达的国家这种情况更为突出[17-18]。某些人群,如青少年对CT辐射敏感度约为成年人的10倍以上[19],青少年身体发育情况诊断常常需要拍摄左手腕骨CT图片,根据CT图片进行骨龄判断并结合实际年龄得到结果。目前CT已被许多发达国家列为最主要的医疗辐射源[15]。
随着人们对CT辐射认识的加深,提出在保证CT图像质量和满足临床诊断要求的同时,尽可能减少受检者的辐射剂量(ALARA)已成为当今影像学重要的研究方向和目标[20]。Naidich[21]等人在1990年首次提出低剂量CT(LDCT)的概念。在CT拍摄中X射线强度和拍摄时扫描时间长短是影响CT剂量的直接因素[22,23],实际应用中通常通过降低CT拍摄仪器X射管电流强度来降低CT剂量,管电流的下降导致信噪比下降引起密度分辨率的下降,其结果可能导致密度相近区域辨识困难[6],造成图片质量下降。降低的CT图像会影响医生的诊断。
基于以上问题,低剂量CT去噪研究近年来得到了快速发展。目前常用的低剂量CT去噪方法主要包括三个类别:投影域方法、图像域重建方法和后处理方法。其中后处理方法利用低剂量拍摄到的CT图像,对其去噪重建为标准剂量CT质量,具有不依赖具体CT设备,简单易用等特点,成为低剂量CT去噪的热点方案。
1.2 CT成像基本原理
CT成像是用X线束对人体检查部位进行扫描,由探测器接收透过人体的X线,通过转换后经将光信号转为数字信号,输入计算机处理。人体各个部位对X光线吸收情况不同,CT重建算法根据人体各个部位对CT吸收的不同程度将其转为不同的黑白像素值构成CT图像。
图像采集通过CT仪器X管仪器向被拍摄者发送X射线并围绕被拍摄者旋转持续拍摄,在X线管对立面(被拍摄者另一边)有接收X射线的检测器,检测器和X线管同步围绕被拍摄者旋转,检测到的信息为投影数据。如下图1.1所示。
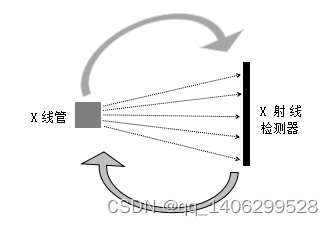
图1.1 CT设备工作图
Figure1.1 Working drawing of CT equipment
X线对人体有极强的穿透力,从X线管发出的X线可以穿过人体并被对立面的检测器接收。X线在穿过人体的时候会与人体组织发生相互作用,这主要包括光电效应和康普顿散射,光电效应使X光穿过人体时与人体的原子内层电子发生作用(需要较强的能量),光子被吸收,光子能量越高越不会被吸收,穿透性越高。光电效应是临床CT的主要衰减形式;康普顿散射指X光子与人体原子的外层电子相互作用(所需能量相对较弱)导致光子能量减弱并改变运动方向,光子方向改变后无法达到预定接收器位置使该位置相应信号减弱,光子改变方向后到达其它位置也会给相应位置带来噪声干扰,康普顿散射是CT图像噪声的主要来源。人体不同的组织和X线产生的光电效应和康普顿散热作用不同,当降低X管线电流时会使光电效应减弱,康普顿散射增强,图像产生更多噪音,质量下降。
当强度为I0的X射线通过某一种均匀介质(如下图1.2)时会产生衰减,其衰减规律可由朗伯比尔定律(Lambert-Beer law)[24]表示,如公式(1-1):
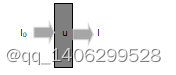
图1.2 X线穿过物体
Figure 1.2 X-ray through object
(1-1)
(1.2)
式中:I——为探测器接收到的X线强度;x——X射线穿过介质的直线长度;u——物体衰减系数。
假设物体时分段均匀的(如下图1.3),并且各段长度和衰减系数分别为x1:u1、x2:u2、…,其衰减规律如公式(1-3)。
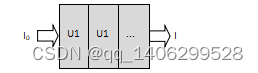
图1.3 X线穿过多个物体
Figure 1.2 X-ray through multiple object
(1-3)
上式也可表示为:
(1-4)
如果X射线穿过人体等连续不均匀介质,在某方向M为:
(1-5)
式(1-4)和式(1-5)等于号两边均可表示为X射线穿过介质后的投影,在数据采集过程中会切换几百甚至上千个扫描角度,综合所有角度的方程可以获得人体对X射线的衰减分布图U(x,y),人体大部分组织衰减系数u很小(如肌肉为0.192cm-1[24]),为了方便临床使用,不直接使用衰减系统而是采用不同组织相对于水的衰减系统的比值关系。组织N的CT值计算公式(1-6)如下:
(1-6)
式中:u0——水的衰减系数;u——所求组织衰减系数;
CT单位为“亨”(Hounsfield Unit,HU)。常见人体组织及介质CT值如下表1.1所示:
表1.1 人体部分组织和常见介质 CT 值
Table 1.1 CT values of some human tissues and common media
人体组织 CT 值(HU) 人体组织 CT 值(HU)
骨组织 >400 肝脏 50~70
钙质 80~300 脾脏 35~60
血块 64~84 胰脏 30~55
脑白质 -25~35 肾脏 25~50
脑灰质 28~44 肌肉 40~55
脑脊液 3~8 胆囊 10~30
血液 13~32 甲状腺 50~90
血浆 3~14 脂肪 -100~-20
渗出液 >15 水 0
空气 -200 以上 漏出液(蛋白<30g/L) <18±2
有了CT扫描断层各部位CT值以后,用CT值代替扫描图像对应值便可以得到CT图像。
人类眼睛只能辨别16阶灰度,CT有大约2000阶灰度,因此人眼无法准确识别每一阶灰度,只能分辨出差异不小于125Hu的CT图像,如差异小于50Hu的人体软组织人眼就无法识别出来。为了能利用CT图像的高精度同时可以观察到各个不同CT值的人体组织,人们通过分段观察的方式观察CT图像,根据需要观察组织的CT值范围,只观察该CT值范围内的图像,将该范围定义为观察的窗宽,该范围的中心即为窗位或窗中心。
窗宽的范围大小会影响CT图像的对比度。当我们选定了窗宽之后,会将该窗宽内CT范围划分为16个灰阶进行观察,例如我们选择CT值1000Hu到1160Hu区间内图像,窗宽为160Hu,这160Hu重新对应到从白到黑16个灰阶,每个灰阶CT值范围为10Hu。如果我们选择窗宽越小,每个灰阶CT值范围越小,对比度越强。要根据人体组织内CT值范围选择合适窗宽。
窗位是窗宽的中心值。如观察某组织CT图像窗宽为100Hu,窗位为1000Hu。在这张CT图像中CT值950Hu(窗位减去窗宽一半)到1050Hu(窗位加上窗宽一半)均可以被观察到。CT值大于1050Hu表现为白色,CT值小于950Hu的表现为黑色。
本文利用深度学习卷积神经网络方法进行训练,针对深度学习特点对数据进行优化,将CT图像归一话到0到1之间。如头部数据观察范围变为[0.24, 0.28],胸腹部数据观察范围为[0.23, 0.29]。
下图1.4展示直接观测CT值和利用窗口窗口观察图像的差异。
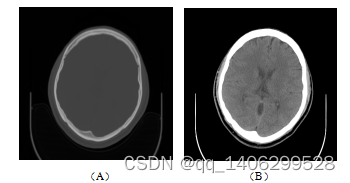
图1.4 (A)直接查看CT图像(B)采用窗口值查看CT图像
Figure 1.4 (a) view CT image directly (b) view CT image by window value
1.3 国内外研究现状及趋势
当前临床在保持硬件条件不变的情况进行低剂量CT扫描往往通过降低X射线球管中的管电流,此种方法会导致发射信号信噪比下降进而获得的CT图像质量下降影响医务工作者病情诊断。国内外学者进行了大量的研究实验提高低剂量CT的图像质量,这些工作研究方向大体可以分为三种:投影域处理方法、图像域重建方法和后处理方法。
1.3.1 投影域处理方法
投影域处理方法也称为预处理方法,对探测器接收到的投影数据进行去噪处理,然后通过滤波反投影或其它CT图像重建方法重建CT图像。此类方法速度较快效率高、便于临床应用,但是对设备具有一定依赖性,大多数厂家不提供投影数据增大了算法研究的难度。
Hsieh J等将投影数据采用自适应截断均值(adaptive trimmed mean,ATM)的方法进行处理,有效抑制重建图像中条形伪影[25];Yu L等提出一种对投影数据局部自适应双边滤波算法,提高了重建图像对比度,使人体各组织边沿信息更加清晰[26];Zhang Y等根据投影数据中不同的噪音信息,针对不同强度或性质噪声采用不同去噪方法进行滤波,并实验获得了较高质量中间图像[27];Gui Z等对投影数据采用了一种模糊中值滤波方法,对投影数据中噪声一职和伪影消除均取得良好效果[27]。投影域滤波方法对图像重建前的投影数据进行处理,如果设计不合理将直接影响重建图像质量,产生畸变等错误图像,在重建时缠手新的噪声[28],滤波算法性能非常重要[29]。
1.3.2图像域重建方法
图像重建算法包括解析重建(analytic reconstruction,AR)和迭代重建(iterative reconstruction,IR)两类[30-38]。解析法是以 Radon 变换对投影数据解析处理后计算的一种方法,如 FBP 重建算法[8]。解析法重建速度较快,但是其对CT的辐射剂量要求较高[39]。迭代法图像重建算法通过对此迭代计算获得人体每个部位CT值,获得的图像质量较好。开始时假设一种初始值,然后从某个角度进行投影得到预估值和真实值,计算其差值进行反馈修正预估值,通过一次次迭代直到预估值和真实值差值为0,此时即可获得准确CT重建出质量较高CT图像。迭代法需要较高的计算机性能,几年来随着计算机性能越来越好,迭代法也慢慢开始获得重视。
将先验信息作为惩罚项加入低剂量 CT 统计迭代重建模型中,可以有效地增强重建图像中散射噪声和伪影的去除效果[40]。马尔科夫随机场(Markov Random Field, MRF)是常用的先验模型,如Zhang R[41]等将马尔可夫随机场模型混合高斯处理提高重建质量。非局部均值和字典学习近年来也慢慢被用来进行惩罚项设计,朱永成等[42]采用K-SVD算法迭代学习去除低剂量CT噪声;郝立巍等[43]通过引入局部相位特征,设计图像子块相似性函数,对低剂量CT去除噪声的同时保留了边界、囊肿区及低密度区等重要特征。
1.3.3 后处理方法
后处理算法直接对设备拍摄得到低剂量CT图像进行去噪重建位标准剂量CT图像,与投影域处理方法相比无须获得投影数据,具有与图像重建算法和CT设备无关性,具有更好的普适性,与图象域重建算法相比具有更快的速度。可以借鉴图像去噪算法,提高算法还发效率。近年来深度学习的兴起,其在图像处理领域取得了良好的成绩,利用深度学习方法进行低剂量CT去噪的方法也表现出了强大的性能。
Zamyatin A等[44]利用自适应多尺度滤波器对低剂量CT进行去噪并且有效保留了图像边缘信息;Chen Y等[45]利用邻域加权平均算法对低剂量CT数据进行处理完成去除噪声和抑制伪影良好效果;Kang D[46]等提出一种自适应三维块匹配算法,有效提高低剂量CT图像去噪水平。Chen H[47-49]设计了设计了一种卷积神经网络完成了对低剂量CT的良好去噪效果,随后通过加深网络设计出RED-CNN网络架构,利用模拟数据和临床数据进行训练,均表现出了较强的去噪性能。Eunhee K[50-51]利用对低剂量CT进行小波处理然后送入卷积神经网络完成了去噪效果,后期利用生成对抗网络利用心脏部位非对齐数据进行训练完成非监督的低剂量CT去噪网络方法;章云港[52-53]等利用空洞卷积、批归一化(Batch Normalization,BN)和残差学习[54]设计卷积神经网络降低网络的复杂度,不仅提高了训练速度同时得到了高质量的去噪水平,提出一种改进型残差解编码网络,通过减小卷积网络卷积尺寸和更改普通卷积层为空洞卷积等方式改进RED-CNN完成高效低剂量CT去噪效果;吕晓琪等[55]利用池化层、批归一化和残差学习设计深度学习网络对完整的肺部低剂量CT完成了去噪;徐曾春等[55]利用改进型WGAN对低剂量CT进行去噪并取得良好效果。
1.4论文主要研究内容及结构安排
科研工作者对低剂量CT去噪做了大量的研究,在CT扫描的投影域、图像重建和后处理等各方面都获得优异的去噪效果。随着深度学习技术的发展,已有大量基于深度学习的低剂量CT去噪研究,如Chen H等[57]研究人员提出的深度学习卷积神经网络,无论模拟低剂量CT数据还是临床数据,与传统方法的高性能低剂量CT去噪算法相比均表现出巨大的优势。但是深度学习方法仍有一些问题值得研究和探索,如低剂量CT中的钙化点问题和非监督训练问题。
研究从图像后处理方向入手,利用深度学习卷积网络强大的图像处理能力针对含钙化点的CT数据提出一种含钙化点的低剂量CT去噪算法。针对结构不同低剂量CT和标准剂量CT非对齐数据提出一种无监督的低剂量CT去噪网络,可以应用非对齐数据进行训练并获得了良好的效果。
(1)解决低剂量CT去噪中钙化点问题。钙化点是人体中的钙化组织,有良性的也由恶性的,应当引起我们的重视。并非每个人都有钙化点,钙化点也可能只存在在某些部位,因此只有极少CT图像中存在钙化点。钙化点在CT图像上特征和噪声非常相似,除比噪声点稍大外无明显差别,目前低剂量CT去噪算法往往将其作为噪声去除,影响医生对病情诊断。研究提出一种基于深度学习卷积神经网络的低剂量CT去噪算法,通过设计数据处理算法,改进低剂量CT去噪网络和损失函数设计等工作,成功实现对由钙化点的低剂量CT数据去噪并保留钙化点。
(2)提出一种基于深度学习卷积神经网络的无监督的低剂量CT训练算法。随着深度学习的发展,其在低剂量CT去噪领域表现出了强大的性能,相比传统低剂量CT去噪算法也具有很大的优势。现有的深度学习卷积神经网络低剂量CT去噪方法大多需要大量结构相同的低剂量CT和标准剂量CT数据进行有监督学习。目前仅有一种应用于心脏部位的无监督训练方法且性能较差,研究利用生成对抗网络架构提出一种非监督的深度学习训练方法并获得了优异的低剂量CT去噪能力。
文章结构安排如下:
第一章引言。首先介绍本文课题的研究和意义;然后,简介CT原理并进一步介绍了国内外研究人员从各方面进行低剂量CT去噪的研究现状;最后提出本文的内容和结构安排。
第二章与研究相关卷积神网络知识概要及本文网络评价指标。介绍与本文研究相关的深度学习知识概要及研究所设计到的卷积神经网络框架,提出本文网络评价指标,为后面章节部分进行知识预备。
第三章基于卷积神经网络的低剂量含钙化点CT去噪研究。首先通过头部数据集展示钙化点并总结其特点提出低剂量CT去噪中钙化点问题研究的意义,然后利用经典的卷积神经网络低剂量CT去噪方法探讨对包含钙化点数据去噪中遇到的问题。接着从数据预处理、损失函数和网络设计数据设计等方面完成包含钙化点的低剂量CT去噪,最后通过与经典低剂量CT去噪方法对比总结证明提出方法的优势并进行本章小结。
第四章基于生成对抗网络的无监督低剂量CT去噪研究。首先展示非对齐的CT数据特点,通过经典低剂量CT去噪方法实现对齐去噪提出无监督方法的意义,然后通过对经典非监督深度学习方法框架的研究从生成器、判别器和损失函数方面进行改进提出非监督的低剂量CT去噪算法。最后通过与现有方法进行对比研究提出研究的价值并进行本章小结。
第五章总结和展望,通过总结文本的研究工作及取得成就,分析放方法中仍存在的问题,提出相关问题解决方法和未来的研究方向。
2 与研究相关卷积神经网络知识概要及网络性能测试指标
2.1 与研究相关深度学习卷积神经概要
LeCun[63]于1989年提出世界上第一个真正意义上的卷积神经网络,从广为流传的手写字体识别LeNet[65]网络,到2012到Alex Krizhevsky等发布AlexNet[64],卷积神经网络近几年获得了快速的发展,在计算机视觉和自然语言处理方面表现出强大性能。如人脸检测、人脸识别到图像去噪等应用。本章通过对卷积神经网络的组成等基础知识进行概要,讨论卷积神经网络的卷积层、激活层、池化层和全连接层等结构及其特点。
2.1.1 卷积层
卷积层由若干卷积核和偏置组成,通过与输入图像或特征层进行点积和累加得到特征图(feature map)。卷积核可以提取输入图像的局部特征,不同的卷积核会提取输入图像的不同特征。卷积核的尺寸中长和宽为该卷积核的感受野,说明了卷积核所能感知的区域。卷积核的通道数与输入图像的通道数相同。当卷积操作开始后,卷积核由设置的步长(卷积核在图像上滑动时移动元素数)由左向右、由上向下滑动,卷积核初始位置由padding确定,每滑动一次卷积核上元素和图像上对应元素相加并求和得到输出矩阵对应值,如下图2.1所示:
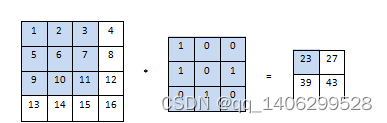
图2.1 卷积操作示意图
Figure 2.1 schematic diagram of convolution operation
以上图二维卷积运算为例,输入图像为441矩阵,卷积核为331,步长为1。初始位置卷积运算:11+20+30+51+60+71+90+101+110=23,以这种方式依次滑动计算,得到输出结果。
卷积层具有两个主要特征:局部连接和权值共享。
(1)局部连接:也叫稀疏连接,指卷积层节点只和前一层的部分节点连接。这种局部感知结构理念受动物视觉皮层结构启发,动物对外界事物的视觉感知过程先局部感知然后全局。在计算机视觉中,同一张图像不同区域的相关性与其相互间距离正相关,图像中的两个像素距离越近其相关性越大,反之越弱。局部感知神经元对局部进行感知,在更高层将之前的局部信息综合得到全局信息。通过局部连接可以让卷积网络只关注应该关注的位置,同时可以大大降低神经网络的参数,如10个神经元对一张100×100图像连接,如果采用全连接方式,每个神经元都要与图像的所有像素进行连接,参数量将达到10×100×100=105,很难进行训练。如果采用局部连接方式,每个神经元与10×10的局部图像连接,参数量为10×(100/10)×(100/10)=103。
(2)权值共享:权值共享指同卷积层的一次卷积运算卷积核权重是共享的,无论卷积到输入图像的哪个位置,卷积核权重都是一样的。同一卷积层的不同卷积核参数可能不同,不同卷积层中卷积核也可能不同。通过权值共享可以进一步降低训练参数,如上例子中让每个神经元的1010权值相同,那么需要训练的参数量降低为10*10。
一个卷积核仅能学习到一种特征,实际生活中仅凭某一种特征无法准确的描述区分不同事物,如猫和狗,只给出颜色不能准确的描述它们也无法正确区分它们。于是同一卷积层往往具有多个卷积核对输入图像进行特征提取,卷积核数代表了可以学习到的特征数。
同一卷积层可以设置多种卷积核学习多种不同特征,卷积神经网络可以通过增加卷积层数学习更深层特征。如2014年牛津大学视觉组提出的VGG[67]网络结构获得当年ILSRC比赛亚军,VGG网络通过降低卷积核尺寸同时增加卷积层数(网络深度),利用两层3×3卷积层达到一层5×5卷积层的感受野,同时证明了网络深度是影响卷积神经网络性能的一个关键因素。
Padding为卷积神经网络卷积核对输入图像进行卷积时遇到越过输入图像边界时的补充边界行为。研究利用tensorflow深度学习网络架构进行训练,以tensorflow中Padding分例,分为“VALID”和“SAME”两种。当padding为“VALID”时,若无法完整滑动,则输入图像或特征层右面和下面部分直接丢掉。当padding为“SAME”时,当无法完整滑动,在输入图像上下左右补0,若不够继续在右面和下面补0。如下图2.2所示。
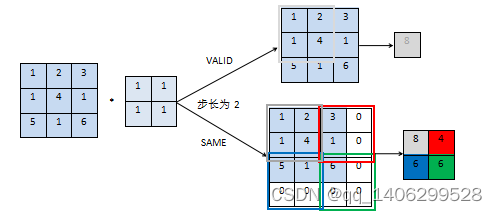
图2.2 padding操作
Figure 2.2 padding operation
2.1.2 反卷积
传统的卷积神经网络对输入图像进行卷积之后得到的特征层长和宽根据padding的不同等于或小于输入图像的长和宽,当我们需要将图像恢复到原理的尺寸的时候需要用到反卷积操作,它相当于对图像进行上采样。反卷积通过对输入图像进行补0扩大尺寸,然后进行卷积,如下图2.3所示,左边为输入图像,右边为进行反卷积时对图像进行补0扩大,然后按章2.1.1中卷积方法对图像进行卷积。
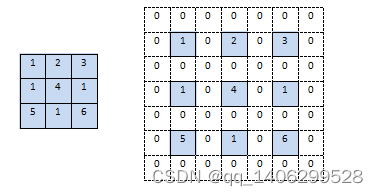
图2.3 反卷积操作
Figure 2.3 deconvolution operation
2.1.3 激活层
激活层利用激活函数把输入的线性数据转换为非线性输出给下一层,多层线性模型变换后和一层线性模型变换无本质差别,激活函数通过将线性模型转换为非线性,解决线性模型对深层卷积神经网络表达力不够的问题。常用的激活函数有Sigmoid函数、Tanh函数、ReLU和PReLU等,以下为研究涉及到的两个的激活函数。
(1)ReLU激活函数
(2-1)
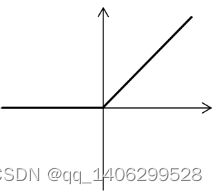
图2.4 ReLU 图像
Figure 2.4 ReLU image
ReLU[71](Rectified Linear Unit)是深度学习卷积神经网络中常用的激活函数。其数学表达式如公式(2-1),其函数图像如上图2.4所示。当x大于0时,其导数恒为1,收敛快。当x小于0时,输出为0,增强了网络稀疏性,提高了网络泛化性。
(2)PReLU激活函数
(2-2)
式中:i–代表不同通
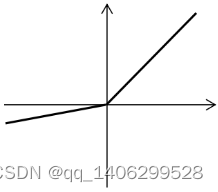
图2.5 ReLU 图像
Figure 2.5 PReLU image
ReLU激活函数对输入小于0的数据置为0,提高了网络的稀释性,这同样也将导致训练变得容易“die”,一个大的梯度经过一个ReLU神经元,参数更新后这个神经元就再也不会对任何数据有激活现象了,那么这个神经元的梯度就永远都会是0。如果学习率很高,网络中很多神经元都会“dead”。针对这种情况Kaiming he等提出的PReLU[72]激活函数,如公式(2-2)和函数图像如图2.5所示。PReLU再输入小于0时也会有一定输出,ai在采用带动量方式更新。这样PReLU仅增加极少量参数,仍保持了ReLU激活函数的优势,同时解决了其“dead”问题。
2.1.5 全连接层
全连接层(fully connected layers,FC)是一个特殊的卷积层,在整个卷积神经网络中起到“分类器”的作用。全连接层一般在卷积神经网络尾部,经卷积层等结构学习到的特征信息映射到样本标记空间,对前面学习到的特征做加权和。其激活函数常采用ReLU激活函数。
2.1.4 池化层
池化层(pooling)对图像进行下采样,减小特征层尺寸。减小网络训练计算量,提高训练速度,同时池化层会提取了图像主要特征,忽略一些特征,降低网络过拟合的可能性。均值池化和最大值池化是比较常见的池化层。最大池化将图像池化区域最大值保留,如下图2.5所示:

图2.5 池化操作
Figure 2.5 pooling operation
上图采用一个2×2的filter进行最大值池化,在每一个区域中寻找最大值,这里的stride=2,最终在原特征图中提取主要特征得到右图。均值池化是对每一个区域元素求和,再除以区域包含元素数,得到主要特征。
池化层使特征图缩小,会影响网络精度。
2.1.6 损失函数
损失函数反映了网络模型预测值与真实值之间的差距,用来评估模型性能。损失函数结果值越大模型性能越差。深度学习在训练过程中不断计算损失进行反向传播,算法以此来更新模型参数,向模型损失减小的方向训练提高模型性能。损失函数对模型训练训练具有一定指导意义,实际应用中要根据算法的差异选择合适的损失函数将算法达到最优。本文涉及损失函数有L1损失和L2损失:
(1)L1损失
L1损失即平均绝对误差(Mean Absolute Error,MAE)如公式(2-3),L1损失表达了目标值和模型预测值各个元素差的绝对值的均值,对异常有较强的鲁棒性。
(2-3)
式中:m、n——目标和预测图像的尺寸;代表绝对值。
(2)L2损失
L2损失即均方误差(MeanSquaredError ,MSE)表示是预测值和实际观测值间差的平方的均值,如公式(2-4)。由于平方的影响数学特性更好,对较大的误差比L1损失更敏感。
(2-4)
式中:m、n——目标和预测图像的尺寸。
2.1.7 优化算法
在训练神经网络模型的时候,我们希望损失函数可以降到最低,收敛越快越好,并希望损失达到最低后不会出现反弹保持稳定下降,这就要用到优化算法。目前优化算法主要有梯度下降优化算法、指数加权平均算法、动量梯度下降算法、RMSprop算法和Adam[73]优化算法。
Adam(Adaptive momentum)是一种自适应动量的随机优化方法(A method for stochastic optimization),它能基于训练动态更新神经网络权重。经常作为深度学习中的优化器算法。
2.2 相关卷积神经网络结构
2.2.1 VGG网络
VGG[74]卷积神经网络是牛津大学视觉组(Visual Geometry Group)于2014年提出的卷积神经网络,拥有较强分类性能和定位性能。其拓展性和泛化性都很好。VGG有深度不同的VGG19和VGG16两种结构。
VGG19网络包括16层卷积层,所有卷积核尺寸全部为3×3,padding均为“SAME”,激活函数全部才哦那个ReLU激活函数。其网络结构前两层卷积层均有64个卷积核,然后利用一个最大池化层进行最大池化;接下来两层卷积层有128个卷积核,然后利用最大池化层进行最大池化;第五到第八层卷积层有256个卷积核,然后利用最大池化层进行最大池化;第九到第十三层卷积层有512个卷积核,利用最大池化层进行最大池化;第十四到第十六层卷积层有256个卷积核,然后经过一个最大池化的池化层;所有池化层步长均为2,大小均为2×2,padding均为“SAME”;最后为三个全连接层,并用ReLU作为激活函数,全连接层尺寸分别为4096、4096和1000。利用softmax函数进行分类。
VGG网络通过连续的两层步长为1的3×3卷积层代替一层5×5卷积层,连续的三层步长为1的3×3卷积层代替7×7卷积层,使网络较之前的单层卷积层保持相同的感受野的情况下提升了网络的深度,每层卷积层后面均利用ReLU激活函数进行激活,这样VGG网络具有更深的非线性层结构,可以学习更复杂的模型,提升网络性能,而且计算量较之前网络大幅下降。例如原来一个5×5卷积核参数量为5×5=25,替换为两个3×3的卷积核后参数量变为2×3×3=18。
VGG网络非常简洁,整个网络卷积核尺寸均为3x3,和最大池化尺寸均为2x2,VGG取得良好成绩证明在一定程度下可以通过增加网络深度提升网络性能。
2.2.2 ResNet
VGG通过加深深度卷积神经网络深度在降低计算量的情况提高了网络性能,自此卷积神经网络设计开始把目光放到提升网络的层数。然后通过不断的加深网络深度研究者很快发现不断地增加网络层数,网络性能并没有得到预想中的提升,相反网络层数到达一定程度后网络变得很难训练,训练集损失不仅不再缩小甚至变大,训练效果甚至不如层数较少的卷积神经网络,发生退化现象。通过研究发现随着网络层数的增加,梯度反向传播到前面层距离变大,累计相乘后梯度变得无穷小造成梯度消失。
针对这种情况,2015年何凯明等[68]提出一种深度残差网络结构,这种网络通过跳跃连接来解决层次过多带来的问题,其借鉴了高速公路结构(Highway Networks)设计思路,其结构原理如下图2.6所示:
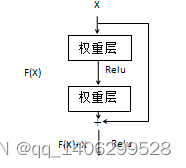
图2.6 ResNet残差连接
Figure 2.6 residual connection
假如网络输入为X,期望输出为H(X),加入残差连接后H(X)=F(X)+X。这种跳跃连接没有增加参数数量,同时将底层特征带到高层有效减少了信息丢失,有效的解决了使深层次的卷积神经网络退化问题。
2.2.3 Inception模型
2014年Christian Szegedy等提出的GoogleNet,并获得了当年ImageNet挑战赛军。VGG证明了通过增大深度学习网络深度可以提高网络性能,但是增大到一定程度会出现网络退化现象,ResNet通过添加残差连接解决了网络深度问题。GooleNet中提出的inception模型提出了另一种提高网络性能的方案,与ResNet增加网络深度不同,Inception模型通过增加网络“宽度”达到提升网络性能的效果。
Inception模块是一种优良的局部拓扑结构,通过对输入图像并行地执行多种不同尺寸的卷积核进行卷积运算或池化操作,然后将并行的所有输出结果拼接为一个特征图。
如Inception利用1×1、3×3和5×5三种尺寸卷积核对输入图像进行卷积和池化操作,然后将其获得所有不同信息综合起来获得更好的特征提取性能。如下图2.7所示:
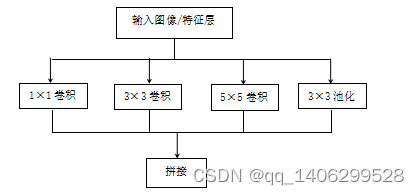
图2.7 Inception单元
Figure 2.7 Inception unit
2.2.4 生成对抗网络
生成对抗网络(GAN,Generative Adversarial Networks)[62]由Godfellow等提出的一种新的深度学习模型,近年来得到较快的发展,并衍生出多个不同版本逐步解决原始的生成对抗网络存在的问题。生成对抗网络包括两个模型:生成器(generator)和判别器(discriminator)。在网络的训练过程中生成器和判别器在博弈中同时得到性能提升。本文低剂量CT去噪研究中,生成器将低剂量CT数据去噪生成标准剂量CT数据;判别器通过不断学习正常剂量CT数据特征提高判别标准剂量CT数据的能力,判断输入数据是否为标准剂量CT数据。训练开始后,首先训练判别器,训练提升其鉴别标准剂量CT图像的能力,然后生成器利用低剂量CT数据生成去噪后数据送入判别器,判断判别器对送入数据进行判断并给出输入数据为标准剂量CT数据的评估,评估分数范围为零到一。判别器认为输入判别器的数据和标准剂量CT数据差异越小,判别器评估给出的分数越高。假如判别器性能很好,同时生成器利用低剂量CT数据生成的数据与标准剂量CT数据差别很大,判别器会给标准剂量CT数据接近一分,给生成器生成的CT数据接近零分。
生成器和判别器一起进行训练,性能也一起得到提升。开始时生成器性能较差,利用低剂量CT数据去噪生成的数据与标准剂量CT数据比较相差较大;此时判别器性能也较差,无法准确判断区分出是生成器利用低剂量CT数据生成数据还是标准剂量CT数据,会给出一定的分数并反馈给生成器,生成器根据反馈实时调整生成方向。随着训练的进行,生成器和判别器性能同时得到提升,变得越来越强。判别器判断输入数据是否为标准剂量CT数据的能力越来越强,生成器利用低剂量CT数据生成的数据也越来越接近标准剂量CT数据。生成器和判别器通过互相博弈共同提升自身性能,最终使判别器无法鉴别出输入数据为生成器生成的数据还是标准剂量CT数据,生成器模型即为我们所需模型。如下图2.8所示生成对抗网络训练原理图。
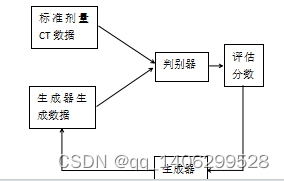
图2.8 生成对抗网络原理图
Figure 2.8 schematic diagram of generating countermeasure network
网络的的损失函数如下,整体优化如下公式(2-5),判别器优化公式如下(2-6),生成器优化公式如下(2-7)
(2-5)
(2-6)
(2-7)
式中:——代表生成器;——代表判别器。
GAN网络仍存在一些问题:训练困难,需要精心设计模型结构,并小心协调生成器和攀比其的训练程度。如判别器性能提升较生成器快,生成器生成数据总会被判别器判断为假,生成器无法正常生成去噪后的数据;相反,如果生成器较判别器性能较好,生成器在最初阶段生成数据便会“欺骗”判别器,性能不再提升,模型依然无法达到最好效果。
WGAN是基于生成对抗网络模型,用Wasserstein距离[75]代替原始生成对抗网络的JS散度。彻底解决了原始生成对抗网络训练不稳定问题,不在需要小新平衡生成器和判别器训练程度,解决了容易崩溃的问题,确保生成样本多样性。
2.3 图像质量定量评价参数
卷积神经网络性能通过网络生成的去噪后图像来评判。对于结构相同的对齐低剂量CT数据核标准剂量CT数据,研究利用生成图像与标准剂量CT图像的RMSE、PSNR和SSIM值作为评价客观标准。
(1)RMSE(Root Mean Square Error)均方根误差,反映生成图像和标准剂量CT图像之间的偏差。如公式(2-8)。
(2-8)
(2-9)
式中:m和n—— 分别代表矩阵大小;和——分别表示对比的两个矩阵对应(i,j)处元素的值。
(2)PSNR(Peak Signal to Noise Ratio)峰值信噪比,单位是dB。是一种广泛应用的图像客观评价指标。当PSNR高于30dB表示图像质量较好;如公式(2-10)。
(2-10)
式中:MAX——表示图像像素可以取到的最大值。
(3)SSIM(Structural Similarity),表示结构的相似性,如公式(2-11)。
(2-11)
式中:——图像x的均值;——图像y的均值;——图像x和y协方差;——图像x的方差;——图像y的方差。
3 基于卷积神经网络的低剂量含钙化点CT去噪研究
深度学习(Deep Learing, DL)[56]通过多层结构从底层开始不断学习组合特征,发现数据中的特征规律进行整合进行数据的相关处理。卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的的前馈神经网络,是深度学习的代表算法之一[56,66]。近年来深度学习卷积神经网络在图像处理方面受到热捧,从低剂到高级任务处理,从去噪、降低模糊、超分辨率图像重建到图像分割、检测、识别等方面都得到良好应用[56]。它可以模拟人类处理信息的方式,通过多层网络结构高效的从图像的各个像素提取高层次特征[57]。随着深度学习卷积神经网络在图像视觉领域取得良好成绩,很多研究者开始研究基于卷积神经网络的低剂量CT去噪,如Chen H等提出的RED-CNN低剂量CT去噪网络,在临床数据和合成低剂量CT数据集上均取得了良好成效,无论主管视觉观察还是客观评价指标(PSNR、SSIM、RMSE)都获得成功。
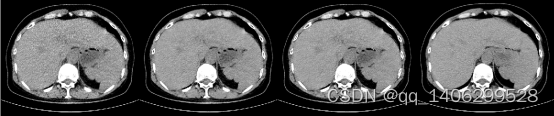
目前低剂量CT去噪仍有一些问题尚未解决,含有钙化点的低剂量CT去噪,如下图3.1所示含钙化点数据。由于钙化点很小且和噪声相似,现有低剂量CT去噪算法往往会将钙化点当作噪声点去除。
本章提出一种卷积神经网络低剂量CT去噪方法,解决带有“钙化点”的数据去噪问题,含有钙化点的低剂量CT数据去噪的同时仍能保留钙化点。本章首先含钙化点的数据进行分析及其去噪的难点及意义;然后本研究去噪网络基于残差编解码网络进行概述;接着论述提出的研究方案,最后介绍网络的训练方法并于现有的经典低剂量CT去噪算法进行对比分析总计。
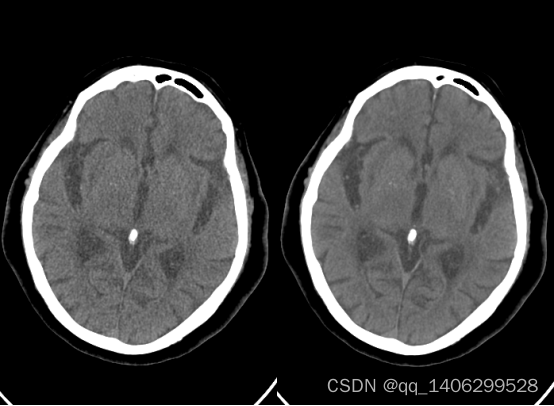
图3.1 带钙化点CT数据
Figure 3.1 CT data with calcification
3.1 低剂量含钙化点CT数据去噪意义
3.1.1 钙化点数据分析
钙化点指身体内的钙化组织,身体中的钙化点形成原因有多种,可能是人体代谢后产物,也可能身体发炎干扰甚至肿瘤导致。有的钙化点不会对人体健康造成影响,有些代表身体发生病变,成为医生诊断的依据。
由于并非每个人都有钙化点,研究收集到的数据中含钙化点的数据较少。除了不是每个人都有钙化点外,有钙化点的人也并不是每个部位都有,这样拍摄得到的CT图像总含有钙化点的数据就更少了。我们对94对低剂量CT和标准剂量CT数据进行统计,仅有5对数据具有钙化点。
通过对上图3.1带钙化点数据图像观察,发现钙化点在图像上的表现特征和噪声相似,均为白色点也很小。这就导致去噪算法很可能将钙化点当作噪声去除。
3.1.2 现有算法对含钙化点低剂量CT数据效果
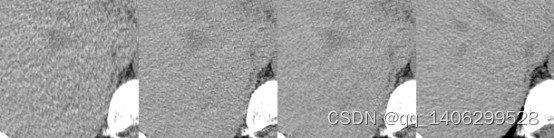
由于钙化点本身于噪声比较相似,很可能被去噪算法一起去掉。同时钙化点数据量又比较小,这又给基于深度学习卷积神经网络的低剂量CT去噪方法带来考验,研究利用卷积神经网络方法RED-CNN和传统低剂量CT去噪方法BM3D对含钙化点数据进行去噪。效果如下图3.2所示。
图3.2 经典算法对含钙化点CT去噪效果(A)低剂量CT(LDCT)(B)RED-CNN(C)BM3D(D)标准剂量CT(NDCT)
Figure 3.2 denoising effect of classical algorithm on CT with calcification(a) low dose CT (LDCT) (b) RED-CNN © BM3D (d) standard dose CT (NDCT)
从图3.2看出,无论经典卷度学习方法RED-CNN还是经典的传统方法BM3D去噪时都无法还原钙化点(图中矩形框中位置)。RED-CNN生成图像出现伪影(图中箭头部位)。由于有些钙化点非良性的,这就要求在对低剂量CT进行去噪的同时准确还原出钙化点。否则影响医务人员对病人病情的诊断可能造成无法挽回的后果。
3.2 残差编码解码低剂量CT去噪结构
3.2.1 去噪模型
假设A是标准剂量CT图像,B为与A结构相同的低剂量CT图像,N为低剂量CT图像B中噪声,则B=A+N。去噪网络模型即为A和B之间的映射,其代价函数为公式(3-1):
(3-1)
3.2.2 去噪网络结构
Chen H等提出的经典低剂量CT去噪网络RED-CNN,是一种基于残差连接的编码解码器结构卷积神经网络,编码器和解码器通过卷积神经网络和反卷积网络实现。结构如下图3.3所示。
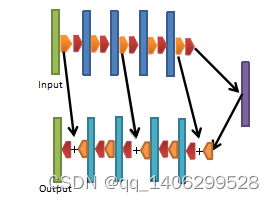
图3.3 残差编解码网络结构
Figure 3.3 residual codec network structure
去噪网络包括5层卷积层和5层反卷积层,所有卷积层后均采用ReLU激活函数进行激活。反卷积层第二层个和第四层,对特征图像进行反卷积后添加激活层含数据,剩余反卷积层反卷积操作完成后需要添加对应卷积层激活后的特征层,然后进行ReLU激活。卷积层卷积核尺寸5×5,步长为1,padding为“valid”,反卷积层卷积核尺寸为5×5,步长为1,padding为“valid”。所有卷积层和反卷积层卷积核数均为96。
卷积层为网络的编码部分,低层到高层逐步去除图像噪声。避免丢失图像细节网络舍弃池化层。反卷积为网络解码部分,通过对卷积层提取到的特征图上采样逐步恢复图像的细节。卷积层和反卷积层采用对称的结构。输入图像每经过一层卷积层尺寸减少4个像素,经过最后一层卷积层后进入反卷积层,每经过一层反卷积层特征层尺寸增大4个像素。
网络通过添加残差连接使网络的深度达到10层(5层卷积层和5层反卷积层)时仍然能保持较高的性能,避免出现网络退化现象梯度消失等问题。卷积层和反卷积层的残差连接帮助图像保留了更多结构细节并具有较好对比度,提升对低剂量CT的去噪效果。RED-CNN损失函数采用MSE,公式(2-9)。
3.3 低剂量含钙化点数据去噪研究
3.3.1 CT图像处理
鉴于带有钙化点数据量很小,研究给训练用数据添加钙化点,由于CT图像直接被医生参考进行病情诊断,加上钙化点暂无规律可循,排除直接对CT图像人工设置一个数据模拟钙化点的方法。研究剪切CT图像中的钙化点并添加到训练数据上,实验分别通过两种方式对训练数据加入钙化点:(1)将从低剂量带钙化点的CT数据中裁剪出的钙化点,添加到低剂量CT数据中;将从标准剂量带钙化点的CT数据中裁剪出的钙化点,添加到标准剂量CT数据中。(2)将从低剂量带钙化点的CT数据中裁剪出的钙化点同时添加到低剂量CT数据和标准剂量CT数据中。(3)将从标准剂量带钙化点的CT数据中裁剪出的钙化点同时添加到低剂量CT数据和标准剂量CT数据中。所有钙化点均添加在图像的固定位置。方案三中的钙化点为标准剂量添加到低剂量CT图像中无法正确反映低剂量CT数据中钙化点的噪声情况,故舍弃此种方案。钙化点添加方法如下图3.4所示:
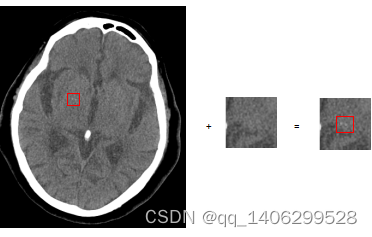
图3.4 对数据添加钙化点
Figure 3.4 Add calcification to data
RED-CNN卷积神经网络利用添加钙化点的数据进行训练效果如下图3.5、图3.6所示,图3.6为3.5对应图像剪切获得:
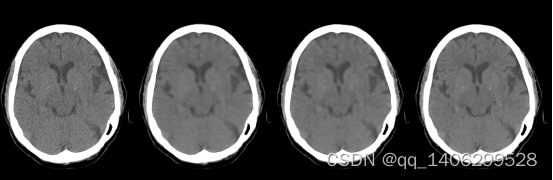
图3.5 训练生成模型效果(A)低剂量CT数据(B)添加钙化前数据训练模型生成图像(C)添加钙化点后数据训练模型生成图像(4)标准剂量CT图像。
Figure 3.5 effect of training generation model (a) low dose CT data(LDCT) (b) pre calcification data training model generation image © post calcification data training model generation image (4) normal dose CT image(NDCT).
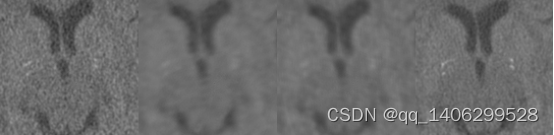
图3.6 训练生成模型效果局部细节图像(A)低剂量CT数据(B)添加钙化前数据训练模型生成图像(C)添加钙化点后数据训练模型生成图像(4)标准剂量CT图像。
Figure 3.6 Training to generate local detail image of model effect (a) low dose CT data (b) pre calcification data training model generation image © post calcification data training model generation image (4) standard dose CT image.
从上图3.5(b)、(c)可以看出加入钙化点后数钙化点部位对比度得到一定程度提升,但是仍不能还原出钙化点。
3.3.2 损失函数设计
RED-CNN采用的MSE损失计算的是去噪深度网络生成图像和标准剂量CT各个像素间差值的平方后的均值,它会扩大差值最大的点和差值最小点的差距,如差值最大点差值为1.1,差值最小点差值为0.1,经过L2损失函数后,其差值变为1.21和0.01。产生这样的差距结果后,优化函数会将更多的注意力集中到差距到大点的优化,差距较小点对损失函数影响进一步减弱使优化函数减弱对差距较小点的关注。在这种优化策略下使图像出现平滑的效果,如RED-CNN效果。由论文[76]可以看出L2损失对异常点比较敏感,在去噪和去马赛克的实验中,L2效果明显差一些。从客观数据来看L1和SSIM损失函数的组合是效果最好的。
RED-CNN损失函数采用L2损失函数,生成图像形成伪影和过于光滑,实验将损失函数更改为如下公式(3-2) :
(3-2)
SSIM考虑了亮度 (luminance)、对比度 (contrast) 和结构 (structure)指标,相比L1和L2具有更多的细节。结构相似性的范围为0到1。图像完全相同,SSIM等于1。通过训练发现网络图像对比度依然较低,无法准确还原出钙化点的效果。如下图3.7所示:
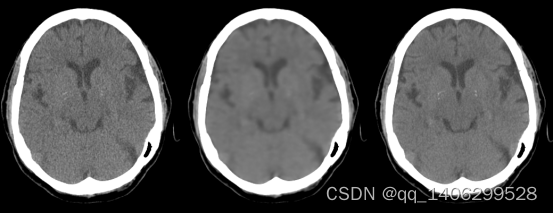
图3.7 调整损失函数后训练模型生成数据(A)LDCT(B)调整损失函数模式生成数据(C)NDCT
Figure 3.7 data generated by training model after adjustment of loss function(A)LDCT(B)generated data by adjusted loss function network(C)NDCT
通过上图可以看出生成图像伪影消失,钙化点仍未准确还原处理,同时观察到数据噪声基本去除。为进一步提高网络对钙化点还原能力添加文献[69]提出的感知损失L,如公式(3-3):
(3-3)
式中:——特征提取器;——低剂量CT数据;——标准剂量CT数据;——卷积神经网络利用低剂量CT去噪后生成的数据;——特征提取器提取到的生成数据特征矩阵;——特征提取器提取到的生成数据特征矩阵。
特征提取器选用预训练的19层VGG网络全连接层前卷积层,继续对VGG训练进行迁移学习。迁移学生是使用以用于其他目标、与训练好的模型的全部权重或部分权重作为初试值继续训练。使用预训练好的模型,模型已达到一个很好的状态,不必再从新训练,费时费力,同时避免了重新训练网络出现问题。特征层提取器值选用了VGG19网络第一层到最后一层卷积层,只需对这些层继续训练。
增加感知损失后,网络的损失函数如下公式(3-4)所示:
(3-4)
加入感知损失后卷积神经网络生成模型如下图3.8所示。
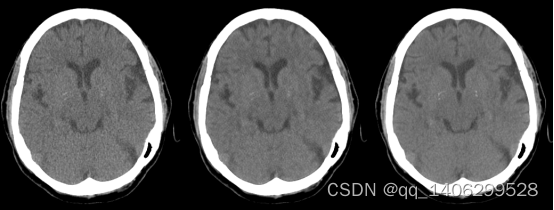
图3.8 加入感知损失后训练模型生成数据(A)LDCT(B)加入感知损失生成数据(C)NDCT
Figure 3.11 data generated by training model after adjustment of loss function(A)LDCT(B)Data generated after adding perceptual loss(C)NDCT
从上图可以看出,加入感知损失后,生成图像对比度得到提升,看看还原钙化点部位。同时看出去噪后的CT图像与标准剂量CT图像相比,仍存在轻微噪声。分析原因,由于训练用数据人工加入钙化点,使去噪网络对图像中与加入钙化点相似且稍小的噪声当作钙化点保留,使网络去噪水平下降。
通过以上实验可以看出,采用L1和SSIM组合的损失函数可以有效去除生成图像伪影等问题,无法准确还原出原低剂量CT图像中的钙化点。采用L1、SSIM和感知函数损失组合可以在一定程度上还原出钙化点,说明感知函数的有效性,同时发现图像去噪水平无法欠佳,生成图像与标准剂量CT图像质量仍存在差距。研究首先利用L1和SSIM的损失函数组合,将图像进行初级去噪。训练到网络收敛后加入感知函数的损失继续训练,感知函数可以加入感知损失前的模型加入感知损失继续训练。加入感知损失前网络已对噪声进行去噪,再加入感知损失后继续训练提高生成图像对比度获得最终图像。
训练过程效果如下图3.9所示。第一个阶段(损失函数为公式3-2):的训练噪声基本去除,仍存在生成图像对比度低,无法还原钙化点等问题;第二阶段加入感知损失(损失函数为公式3-4)继续训练。图3.10为对应3.9中图像区域放大。
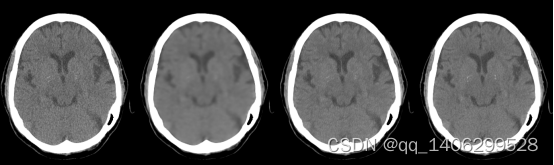
图3.9 训练过程(A)LDCT(B)第一阶段训练结果(C)第二阶段训练结果(D)NDCT
Figure 3.9 training process (A) LDCT (B) first stage training results © second stage training results (D) NDCT
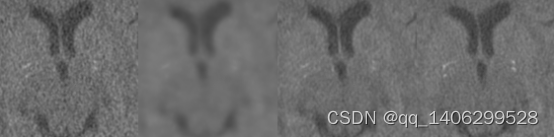
图3.10 训练过程(A)LDCT(B)第一阶段训练结果(C)第二阶段训练结果(D)NDCT
Figure 3.10 training process (A) LDCT (B) first stage training results © second stage training results (D) NDCT
上图中阶段一利用L1和SSIM结合损失函数,去除低剂量CT的噪声,第二阶段在阶段一的基础上加入感知损失还原低剂量CT图像中的钙化点。可以看出第二阶段后去噪水平较好,并成功还原出钙化点。通过观察阶段二生成CT图像与标准剂量CT对比取得了较好水平。
下面直接进行第二阶段一次性训练(损失函数3-4)的训练获得模型与两个阶段分段模型进行对比验证两个阶段训练的优势。如下图3.11和3.12所示,下面可看出3.12中(b)图像和©图像相比,红色方框内区域(c)中图像噪声较少,绿色方框内(b)图像仍存在较多噪点。
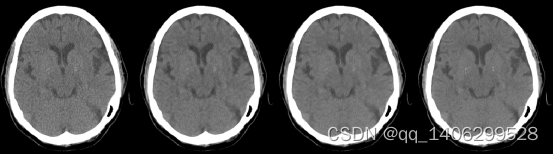
图3.11 实验对比(A)LDCT(B)一次性训练(C)分阶段训练(D)NDCT
Figure 3.11 training process (A) LDCT(B) One time training © staged training(D) NDCT
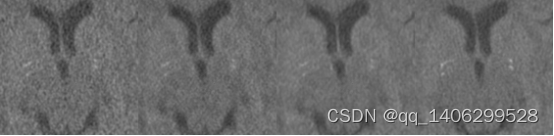
图3.12 实验对比(a)LDCT(b)一步训练(c)分阶段训练(d)NDCT
Figure 3.12 training process (a) LDCT(b) One time training © staged training(d) NDCT
两种训练方式客观指标对比如表3.1所示。通过对比两组数据PSNR、RMSE和SSIM查看客观指标,PSNR越大越好,RMSE越小越好,SSIM越接近1越好,
表3.1 两种训练方式客观指标比较
Table 3.1 comparison of objective indexes of two training methods
图3.12 PSNR RMSE SSIM
(b) 57.6757 0.0013 0.9954
(c) 59.1528 0.0011 0.9960
通过观察及客观指标,提出的通过更新损失进行两个阶段相继训练的方式可以更好的解决保留钙化点的去噪问题。
3.3.3 去噪网络设计
RED-CNN卷积核均为5×5,每层卷积核数均为96,网络庞大,训练速度较慢。下面对RED-CNN网络进行改进。通过前文对VGG网络的论述,通过两层步长为1的3×3的卷积核可以获得和一层5×5的卷积核相同的感受野。两层3×3卷积比一层5×5卷积网络更深,在残差连接的情况下可卡因学习更复杂的模型,同时由于参数的下降计算量会更小。我们选用3×3卷积核核33反卷积核代替原来网络中的5×5卷积核核55反卷积核,同时假设网络学校到更深入的特征。通过多次训练获得最佳层数。网络结构如下图3.13所示:
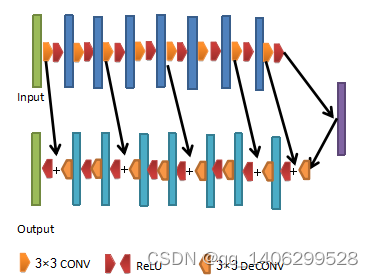
图3.13 改进后卷积神经网络结构
Figure 3.13 improved convolution neural network structure
网络包括8层卷积层和8层反卷积层,所有卷积层后均有激活层,激活层采用RELU函数进行。反卷积层第三、五和七层,对特征图像进行反卷积后添加激活层含数据,剩余反卷积层卷积操作完成后需要添加对应卷积层的特征层,然后进行激活,激活函数均为RELU。卷积层卷积层卷积核尺寸3×3,步长为1,padding为“valid”,反卷积层卷积核尺寸为3×3,步长为1,padding为“valid”。所有卷积层和反卷积层卷积核数量均为64,网络从第一个卷积层前开始,每隔两个卷积层有一个残差连接,与对应尺寸相同的反卷积相连接。通过改进网络层数加深参数减少。
如下图3.14、3.15为改进网络后与直接采用RED-CNN网络训练后对比效果,RED-CNN采用改进后损失函数进行训练。
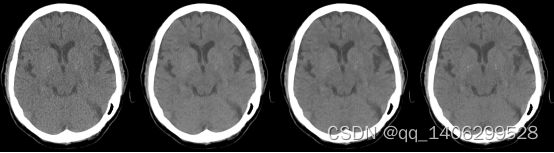
图3.14 实验对比(A)LDCT(B)RED-CNN(C)改进网络(D)NDCT
Figure 3.14 training process (A) LDCT(B) RED-CNN © improved network(D) NDCT
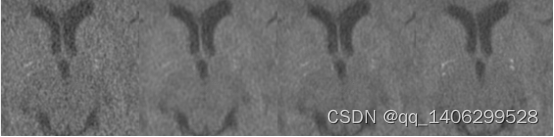
图3.15 实验对比(部分)(A)LDCT(B)RED-CNN(C)改进网络(D)NDCT
Figure 3.15 training process(part) (A) LDCT(B) RED-CNN © improved network(D) NDCT
下表3.2为两种去噪网络客观参数对比。
表3.2 两种去噪网络客观指标比较
Table 3.2 comparison of objective indexes of two denoising networks
图3.15 PSNR RMSE SSIM TIME(s)/93
RED-CNN 58.4834 0.0012 0.9965 34.7239
改进网络 59.1528 0.0011 0.9970 14.4835
从表3.2可以看出采用改进的网络后,随着网络的加深,图像质量客观指标均得到提升,同时利用规模小对93个数据进行测试总用时改进的网络随着参数量的下降,测试用时缩短到原来41.71%。
3.4 网络训练
3.3.1 训练参数
网络采用Adam[70]算法进行优化, α=e -5 , β1 =0.5 , β2 =0.9 ,λ=10 ,根据实验经验, λ1 =0.1 , λ2 =0.1 。同时网络的 BN 大小设置为 32。
第一阶段学习率10-4,a=1,b=1。第二阶段学习率10-5,a=1,b=1,c=10-4。
3.3.2 训练环境
计算机硬件:处理器:AMD R2-2600,内存:32GB,显卡核心NVIDIA GeForce1660Ti,显存:6GB。
软件环境:深度学习框架:tensorflow1.14,卷积神经网络语言:python3.6。
3.3.3 训练数据集及处理
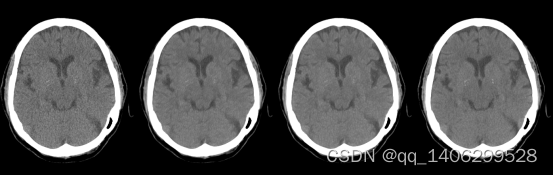
低剂量CT钙化点数据采用头部临床数据进行研究。数据集包括12个人的头部共1821对低剂量和正常剂量的CT数据。数据包含了头部不同CT 切片位置的图像,如下图3.3所示,所有数据尺寸均为512*512,其中一部分对低剂量CT图像和对应的标准剂量CT数据结构不通过,经过筛选后得到结构几乎相同的低剂量CT和标准剂量CT数据1099对,随机选择其中的11个人1005对数据作为训练集剩下1个人94对数据作为训练集。
为了方便数据处理同时确保CT数据精度,将CT dcm格式转为16位mat格式(matlab存储格式)进行存储。为保证数据方便处理及在训练时能够加快收敛将所有数据进行归一化到0和1之间,头部数据查看窗口为[0.24 0.28]。
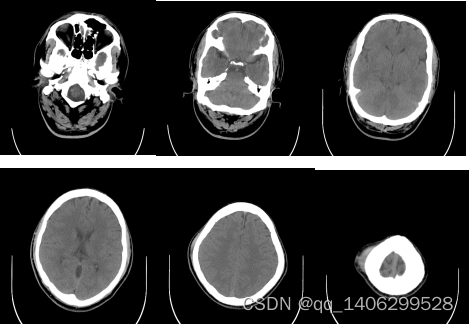
图3.16 头部数据
Figure 3.16 head data
针对数据集数量较小,深度学习卷积神经网络训练需要大量数据的特点,训练数据通过在原图像滑动裁剪获得。研究利用卷积神经网络进行训练并通过GPU并行计算能力进行加速,利用GPU加速使需要将网络和训练数据加载到GPU的显存中。研究采用GPU型号为NVIDIA Geforce 1660Ti,显存为6GB,为避免显存溢出采用6464尺寸的数据进行训练。考虑到CT图像有效区域位于图像中心位置,如果从原图像边界开始剪切数据,会使一些数据有效区域比例较小,研究采用从距离与图像上下边界64的位置开始裁剪数据,由左到右、由上到下,每隔32个像素裁剪出一张数据,知道距离图像右侧边界和下部边界64像素除为止,通过滑动裁剪方式,生成约12万对尺寸为6464的低剂量和标准剂量CT对。裁剪方式如下图3.17所示:
图3.17 数据滑动剪切
Figure 3.17 data sliding shear
3.5 实验结果及分析
3.5.1 数据处理方案效果对比
实验分别对两种数据处理方案进行训练:(1)对低剂量CT数据和标准剂量CT数据均加入裁剪自低剂量CT的钙化点;(2)对低剂量CT数据和标准剂量CT数据中均加入从低剂量带钙化点的CT数据中裁剪出的钙化点。效果如下图3.18和3.19所示:LLCT代表方案一生成数据,LNCT代表方案二生成数据。
(A) (B) (C) (D)
图3.18 数据处理方案对比(A)LDCT(B)LLCT(C)LNCT(D)NDCT
Figure 3.18 comparison of data processing schemes(A)LDCT(B)LLCT(C)LNCT(D)NDCT
(a) (b) (c) (d)
图3.19 数据处理方案对比(a)LDCT(b)LLCT(c)LNCT(d)NDCT
Figure 3.19 comparison of data processing schemes(a)LDCT(b)LLCT©LNCT(d)NDCT
从上图可以看出LNCT去噪效果相比LLCT较差,与标准剂量CT图像相比偏白。分析由于采集钙化点的低剂量CT和标准剂量CT图像没有严格对齐,因为钙化点本身就很小,如果不能够完全对齐就会影响去噪效果。两种数据处理方式客观参数对比如表3.3所示。通过对比两组数据PSNR、RMSE和SSIM查看客观指标,证实了LLCT的方案更佳。
表3.3 两种数据处理方式客观指标比较
Table 3.3 comparison of objective indicators of two data processing methods
图3.19 PSNR RMSE SSIM
LLCT 59.1528 0.0011 0.9960
LNCT 59.2181 0.0011 0.9964
3.5.2 实验结果
分别利用RED-CNN、BM3D[78]经典传统去噪算法和研究提出的算法(proposed)进行比较。通过主观观察生成数据和客观参数比较两种方式对比验证提出的算法的优势。如下图3.20和3.21所示。
(A) (B) (C) (D) (E)
图3.20 去噪方案方案对比1(A)LDCT(B)RED-CNN(C)BM3D(D)PROPOSED(D)NDCT
Figure 3.20 comparison of Noise Removal Schemes1(A)LDCT(B)RED-CNN(C)BM3D(D)PROPOSED(D)NDCT

(a) (b) (c) (d) (e)
图3.21 去噪方案方案对比1(a)LDCT(b)RED-CNN(c)BM3D(d)PROPOSED(e)NDCT
Figure 3.21 comparison of Noise Removal Schemes1(a)LDCT(b)RED-CNN(c)BM3D(d)PROPOSED(e)NDCT
从图中可以看出,研究提出的方法完成了对剂量CT数据的去噪的同时准确还原了低剂量CT数据中的钙化点。RED-CNN钙化点不够清晰,BM3D算法去除噪音的同时也导致了图像的模糊。去噪方案的客观参数对比如下表3.4所示。
表3.4 去噪方案客观指标比较1
Table 3.4 Comparison of objective indexes of denoising schemes
图3.18 图3.19
PNSR RMSE SSIM PNSR RMSE SSIM
LDCT 24.0948 0.0624 0.9628 0.0018 55.0717 0.9933
RED-CNN 23.8552 0.0642 0.9625 57.8442 0.0013 0.9949
BM3D 24.1592 0.0619 0.9646 59.6750 0.0010 0.9964
PROPOSED 25.8114 0.0615 0.9660 59.7250 0.0008 0.9977
从客观参数对比表可以看出提出的算法仍然具有较好的效果。如下图3.22和3.23所示。
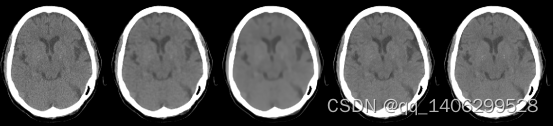
(A) (B) (C) (D) (E)
图3.22 去噪方案方案对比2(A)LDCT(B)RED-CNN(C)BM3D(D)PROPOSED(D)NDCT
Figure 3.22 comparison of Noise Removal Schemes2(A)LDCT(B)RED-CNN(C)BM3D(D)PROPOSED(D)NDCT

(a) (b) (c) (d) (e)
图3.23 去噪方案方案对比2(a)LDCT(b)RED-CNN(c)BM3D(d)PROPOSED(e)NDCT
Figure 3.23 comparison of Noise Removal Schemes2(a)LDCT(b)RED-CNN(c)BM3D(d)PROPOSED(e)NDCT
通过对图3.23进行观察,提出方法和图3.21情况基本相同,提出方法可以保留钙化点的情况完成低剂量CT的去噪工作,达到了研究目标。RED-CNN钙化点部位仍然模糊,BM3D去噪算法无法应对钙化点问题。
去噪方案的客观参数对比如下表3.5所示。提出的方案在客观参数取得较好水平。
表3.5 去噪方案客观指标比较2
Table 3.5 Comparison of objective indexes of denoising schemes2
Figure 6 Figure 7
PNSR RMSE SSIM PNSR RMSE SSIM
LDCT 30.1084 0.0312 0.9846 56.7506 0.0015 0.9949
RED-CNN 30.3768 0.0303 0.9866 60.5588 0.0001 0.9965
BM3D 30.1671 0.0310 0.9836 60.5776 0.0001 0.9971
PROPOSED 20.7744 0.0301 0.9871 61.1528 0.0001 0.9980
3.6 本章小结
本章提出一种低剂量含钙化点CT数据的卷积神经网络去噪方法,通过对现有低剂量CT卷积神经网络的研究及数据分析。首先针对钙化点数据较少影响网络训练的状况,设计人工添加钙化点的数据处理方案。然后设计低剂量CT去噪网络并针对网络仍然存在的问题,改进去噪网络的损失函数,并将网络训练过程分为两步进行,分别选择一种损失函数,最终得到较好的实验效果。
4 基于生成对抗网络的无监督低剂量CT去噪研究
研究者们基于深度学习卷积神经网络提出多种有效的低剂量CT去噪算法网络,如Chen H等提出的RED-CNN。生成对抗网络(GAN)[62]深度学习网络框架的提出,为基于深度学习卷积神经网络的CT去噪方法研究提供了新的思路,如徐曾春等[55]利用改进的WGAN在低剂量CT去噪研究中获得良好效果。以上这些卷积神经网络的的低剂量CT去噪方法均需要大量结构相同的成对低剂量CT和标准剂量CT数据训练。
4.1 无监督的剂量CT去噪意义
获得相同结构的成对低剂量CT数据和标准剂量CT数据需要采用CT设备对被拍摄者分别用低剂量和标准剂量方式拍摄两次CT数据,分别获得低剂量CT数据和标准剂量CT数据,并要求被拍摄者在两次拍摄时姿势保持不变。对于头部等刚性部位,获取成对且对齐的低剂量CT和标准剂量CT相对容易实现。只要让拍摄者保持不动,对同一切面使用低剂量和标准剂量连续拍摄两次便可以获得对齐的低剂量CT和标准剂量CT数据。如果胸腹部等非刚性部位,由于被拍摄者呼吸和心跳的影响,很难获得结构相同的对齐低剂量CT和标准剂量CT。如下图4.1所示非对齐的CT数据。无法得到对齐的低剂量CT和标准剂量CT数据的部位就无法深度学习低剂量CT去噪的相关监督算法。目前基于深度学习的低剂量CT去噪的无监督算法只有Kang Eunhee等[51]提出的CCADN(Cycle-consistent adversarial denosing networ),实验发现其性能无法达到理想效果。
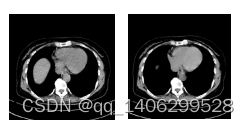
图4.1 结构不相同的非对齐数据
Figure 4.1 Unaligned Data with Different Structures
由于真实环境下低剂量CT噪声情况复杂,传统的低剂量CT去噪算法无法保证对所有噪声情况均有高效的去噪效果。如下图4.2、4.3所示几种算法对非对齐低剂量CT数据的去噪效果。
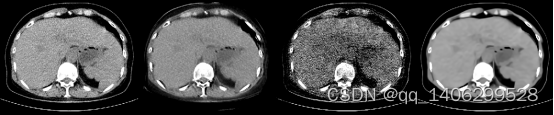
(A) (B) (C) (D)
图4.2 现有算法对比(A)LDCT(B)RED-CNN(C)CCADN(D)BM3D
Figure 4.2 comparison of existing algorithms (A) LDCT (B) RED-CNN © CCADN (D) BM3D
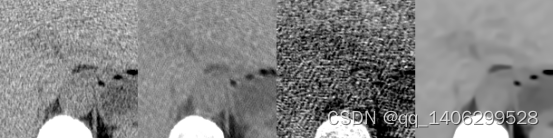
(a) (b) (c) (d)
图4.3 现有算法对比(部分区域)(a)LDCT(b)RED-CNN(c)CCADN(d)BM3D
Figure 4.3 comparison of existing algorithms(part) (a) LDCT (b) RED-CNN © CCADN (d) BM3D
通过图4.3可以看出,现有深度学习低剂量CT去噪算法无法应用非对其低剂量CT数据和标准剂量CT数据获得理想的效果,如图4.3(b)RED-CNN生成图像仍然较模糊,图4.3(c)生成图像出现过多黑色斑点。传统低剂量CT去噪算法BM3D生成图像清晰度较差。
2017年Zhu J等提出生成对抗网络CycleGAN[58],CycleGAN可以利用风格、结构不同的两类数据进行无监督训练,完成图像风格迁移任务。研究利用基于CycleGAN生成对抗网络框架进行非对齐低剂量CT和标准剂量CT图像的去噪网络训练方法。
4.2 CycleGAN生成对抗网络框架介绍
CycleGAN[58]本质可以看作具有两组生成方向相反的生成对抗网络,CycleGAN具有两个生成器G、F和与之对应的两个判别器DX、DY。生成器G将X域的数据生成到Y域,生成器F将Y域的数据生成到X域。判别器DX用判断输入网络的数据是否为X域,然后和标准生成对抗网络的判别器一样反馈0到1之间的判断值,判断值大小与生成器生成的图像质量和判别器识别X域数据的性能均有关,值越大说明判别器DX认为输入图像越可能是X域数据,判别器DY用判断输入网络的数据是否为X域,然后和DX一样给出判断反馈。CycleGAN结构图[58]如下图4.4所示。
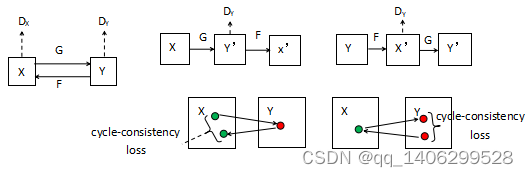
图4.4 CycleGAN网络结构图
Figure 4.4 CycleGAN Network Structure Diagram
CycleGAN网络损失函数包括两个对抗损失和一个循环损失,如下公式(4-1、4-2、4-3):
(4-1)
(4-2)
(4-3)
CycleGAN生成器由编码器、转码器和解码器构成。(1)编码:利用卷积神经网络从输入图像中提取特征。(2)转码:通过组合图像的不相近特征,将图像在DA域中的特征向量转换为DB域中的特征向量。(3)解码:利用反卷积层从特征向量中还原出低级特征得到生成图像。
CycleGAN判别器采用PatchGAN生成对抗网络判别器,其输出是一个N*N的矩阵,矩阵的每个元素值为0或者1,代表着判别器网络对其输入图像的感受野的判断。
4.3 基于生成对抗网络的非监督低剂量CT去噪网络
目前利用深度学习卷积神经网络进行低剂量CT去噪的研究已有很多,这些研究也取得良好成绩,证明卷积神经网络在低剂量CT去噪强大的性能。目前已提出的算法大多需要大量的成对对齐低剂量CT数据和标准剂量CT数据,这样的数据获取比较困难。CycleGAN生成对抗网络具有两个生成器、两个判别器和两个周期损失(Cycle_loss),可以利用非成对对齐的数据进行训练,成功实现图像风格转移。研究利用CycleGAN生成对抗网络,设计低剂量CT去噪网络作为生成器,随着生成器的变化需要重新选用适当的判别器,使新的生成器和判别器组合性能和增长性能达到同一水平,避免出现最初生成对抗网络训练困难等问题。
如下图所示,在低剂量CT去噪研究中规定低剂量CT数据为X域,标准剂量CT数据为Y域,非对齐数据训练网络整体结构如下图4.5所示。
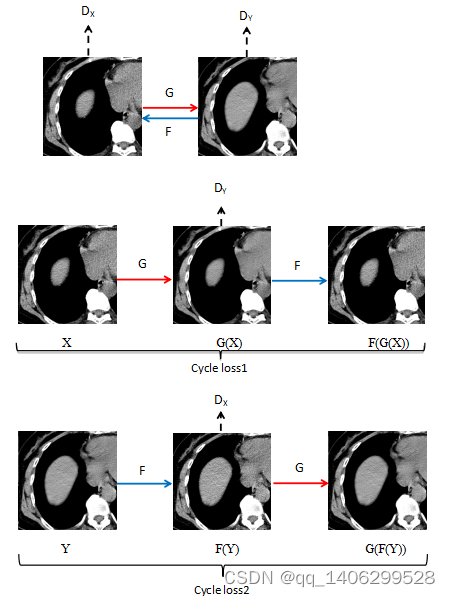
图4.5 非对齐低剂量CT去噪网络结构图
Figure 4.5 Structure Diagram of Non-aligned Low Dose CT Noise Removal Network
4.3.1 生成器设计
首先选用RED-CNN和原始的CycleGAN生成对抗网络对非对齐的低剂量CT和标准剂量CT数据进行训练,研究RED-CNN和CycleGAN利用非对齐CT图像训练的效果。效果如下图4.6、4.7所示:
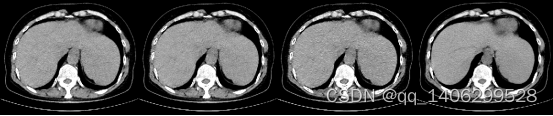
(A) (B) (C) (D)
图4.6 初试方案方案对比(A)LDCT(B)RED-CNN(B)CycleGAN(D)NDCT
Figure 4.6 Scheme Comparison for Initial Trial (A) LDCT (B) RED-CNN (B) CycleGAN (D) NDCT
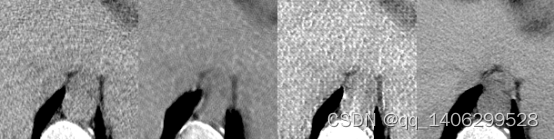
(a) (b) (c) (d)
图4.7 初试方案方案对比(部分区域)(a)LDCT(b)RED-CNN(d)CycleGAN(d)NDCT
Figure 4.7 Scheme Comparison for Initial Trial (partial areas)(a) LDCT (b) RED-CNN © CycleGAN (d) NDCT
上图可以看出RED-CNN生成图像比较平滑,如上图红色方框中部位对比度较低,细节比较模糊。分析产生这样的原因是由于RED-CNN需要用结构相同的成对低剂量CT和标准剂量CT数据进行训练,从其损失函数看出RED-CNN通过计算标准剂量CT数据和相应低剂量CT数据生成数据差作为评价标准,如果低剂量CT数据和与其对应标准剂量CT数据结构不同,则无法正确反映网络训练的模型的性能,导致RED-CNN模型训练出现问题,生成图像出现平滑效果。无法利用低剂量CT数据去噪生成高质量CT数据,这也是目前大多深度学习卷积神经网络低剂量CT去噪算法无法直接应用非对齐低剂量CT数据和标准剂量CT数据进行训练获得理想去噪模型的原因。
原始CycleGAN生成对抗网络获得的图像可以看出图像轮廓相比RED-CNN生成数据变得清晰,结构相比低剂量CT数据没有发生大的变化,说明CycleGAN生成对抗网络利用非对齐CT数据进行训练时可以保证图像的结构不变,避免其它低剂量CT去噪网络使图像模糊的问题。同时可以看到CycleGAN生成数据出现大量的白色噪点,分析由于CycleGAN生成对抗网络目前应该较多为图像风格迁移,仅仅对两种不同的风格之间进行切换,如利用苹果和橘子之间的转转,并且生成的转换后图像质量也并非高质量图像,CT是高精度图像质量,原始CycleGAN生成对抗网络无法完成低剂量CT去噪的目的。
研究利用前文低剂量CT去噪网络替换原始CycleGAN生成对抗网络中生成器,通过调试网络生成器采用9层卷积层和9层反卷积层如下图4.8所示,但仍存在一些问题。受Inception网络结构启发,在两层3×3卷积并性添加一层5×5卷积提高网络的性能,网络结构如下图4.9所示:
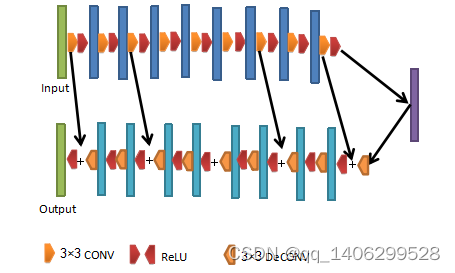
图4.8 改进方案一生成器结构
Figure 4.8 Improvement of Scheme One Generator Structure
改进生成器方案一卷积核和反卷积尺寸均为3×3,步长为1,padding为VALID,所有卷积层卷积核数量为64,相对本文第四章低剂量CT去噪网络,通过加深网络深度进一步增强网络性能。
改进生成器方案二如下图4.9所示。
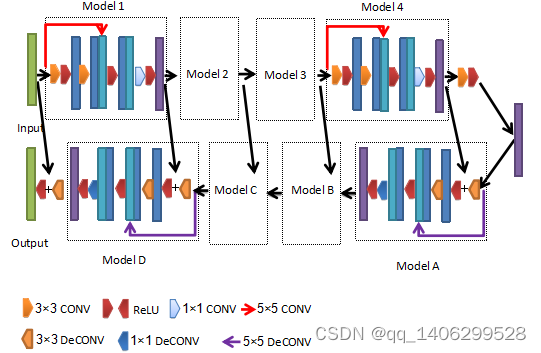
图4.9 改进方案二生成器结构
Figure 4.9 Improved Scheme 2 Generator Structure
GoogleNet的Inception结构通过增加使用不同的卷积对输入图像并行提取特征取得了良好成绩,研究利用一层具有5×5卷积核的卷积和两层步长为1的3×3卷积的卷积同时对输入数据提取特征,由于两种不同尺度的卷积核,解决低剂量CT中噪声分布不均和复杂多变的情况,提升完了的去噪能力。
两种生成器改进方案对比效果如下图4.10、4.11所示:
(A) (B) (C) (D)
图4.10 生成器改进方案对比(A)LDCT(B)方案一(C)方案二(D)NDCT
Figure 4.10 Generator Improvement Scheme Comparison (A) LDCT (B) Scheme I © Scheme II (D) NDCT
(a) (b) (c) (d)
图4.11 生成器改进方案对比(部分区域)(a)LDCT(b)方案一(c)方案二(d)NDCT
Figure 4.11 Generator Improvement Scheme Comparison(partial areas) (a) LDCT (b) Scheme I © Scheme II (d) NDCT
如上图所示,图4.11(b)和4.11(c)分别为改进方案一和改进方案二利用非对齐数据生成效果,两个网络除了生成器不同外其它参数,如判别器、损失函数等均相同。在图4.11中,方案二生成的(c)整体去噪情况良好和标准剂量NDCT数据很接近,方案一生成的(b)数据与(c)比较仍有可观察到噪声。
下表4.1为图4.11区域客观参数比较。
表4.1 生成器两种方案客观指标对比
Table 4.1 Generator Comparison of Objective Indicators of Two Schemes
图4.11 PSNR RMSE SSIM
方案一 48.9130 0.0036 0.9564
方案二 49.0073 0.0035 0.9595
从上层图像可以看出方案一和方案二生成图像相对前文RED-CNN和CycleGAN生成对抗网络生成图像效果都更好,改进网络B的效果相对改进网络A效果无论从视觉角度还是客观参数统计都较好,改进网络A生成数据有轻微颗粒感降低了去噪水平,改进网络二生成图像与标准剂量CT图像(NDCT)更接近,对局部位置的PNSR、RMSE、SSIM客观参数也相对较好。
4.3.2 判别器结构
前文通过对CycleGAN生成对抗网络框架生成器进行改进,改进后的网络利用非对齐的低剂量CT和标准剂量CT数据进行训练,获得模型对低剂量CT数据进行去噪,并取得了较好的水平。
通过对原始CycleGAN生成对抗网络判别器进行研究,原始CycleGAN生成对抗网络判别器采用PatchGAN[61]生成对抗的判别器。一般的GAN是输出一个评估值的矢量,这是代表对整张图像的评价;PatchGAN输出的是一个N x N的矩阵,这个N x N的矩阵的每一个元素,比如a(i,j) 只有0或1 这两个选择(label 是 N x N的矩阵,每一个元素是0或者1),这个矩阵中每一个元素,代表着原图中的一个比较大的感受野,即原图中的一个Patch。PatchGAN判别器的这些特性使其适合高分辨率图像的训练重建,研究训练采用数据尺寸均为64*64,分辨率相对较低,本部分通过改进判别器提升利用非对齐低剂量CT数据和标准剂量CT数据训练模型的去噪效果。
WGAN的提出解决了原始生成对抗网络难以训练、不稳定和模型崩塌等诸多问题,研究利用WGAN的判别器作为研究判别器,网络包括6层卷积层核2层全连接层。连接层卷积核尺寸均为3×3,利用leaky_relu函数进行激活,前两层卷积层卷积核数为64,接下来两层卷积层卷积核数位128,最后两层卷积层卷积核数位256。两个全连接层输出分别位1024和1,网络结构如下图4.12所示。
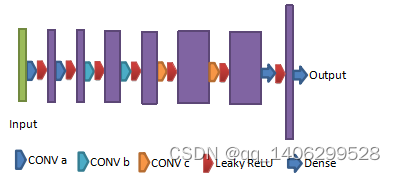
图4.12 判别器改进方案
Figure 4.12 Discriminator Improvement Scheme
生成器采用前文方案二网络,生成器分别采用CycleGAN生成对抗网络原始判别器和WGAN生成对抗网络判别器利用非对齐低剂量CT数据和标准剂量CT数据进行训练,效果如下图4.13、4.14所示:
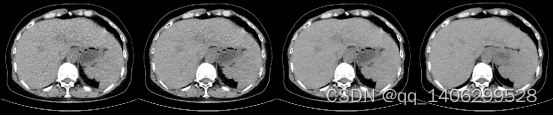
(A) (B) (C) (D)
图4.13 判别器改进方案对比(A)LDCT(B)改进前(C)改进后(D)NDCT
Figure 4.13 Comparison of Discriminator Improvement (A) LDCT (B) Improvement © Improvement (D) NDCT
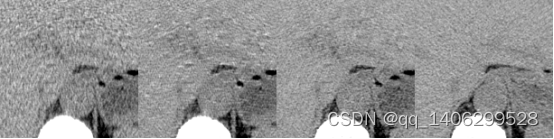
(a) (b) (c) (d)
图4.14 判别改进方案对比(部分区域)(a)LDCT(b)改进前(c)改进后(d)NDCT
Figure 4.14 Comparison of Discriminant Improvement Schemes (Partial Areas) (a) LDCT(b) Improved before © Improved after (d) NDCT
下表4.2为判别器改进前后生成图像客观评价指标。
表4.2 判别器改进前后客观指标对比
Table 4.2 Comparison of objective indexes before and after discriminator improvement
图4.12 PNSR RMSE SSIM
改进前 52.6076 0.0023 0.9618
改进后 52.7576 0.0023 0.9625
在使用相同生成器的情况下,图4.14(b)判别器采用CycleGAN生成对抗网络的判别器,图4.14(c)判别器采用WGAN生成对抗网络的判别器。从图中可以看出,图4.14(b)数据出现白色斑点块,白色斑点外的其它区域相比低剂量CT数据噪声减弱。4.14(c)数据取得了相对较好效果。说明WGAN判别器相对CycleGAN判别器更适合作为研究提出的低剂量CT去噪网络。原因分析如下:
(1)CycleGAN判别器采用PatchGAN判别器,最大特点是针对高分辨图像进行优化,训练用数据分别仅为64×64,不能发挥PatchGAN判别器优势。
(2)从实验可以看出去噪网络在生成器等其它条件均相同的情况下,判别器的差异导致生成的图像质量存在差异。说明生成器和判别器组合需要匹配才能发挥出最好的性能,WGAN的判别器与提出的生成器更加契合,训练过程中判别器和生成器性能同步得到提升并一起达到最优,这样训练得到的模型获得了最佳性能。而CycleGAN生成对抗网络的判别器与提出的生成器组合时,两者性能没有一起得到提升,两者中的一个提升相比另一个更快,导致训练。或者两者性能同时提升过程中,判别器性能达到最大值导致生成器性能不再提升导致生成器生成图像效果较差。
4.3.3 损失函数调整
CycleGAN属于一种生成对抗网络,其优化的总体优化函数如下公式(4-4):
(4-4)
总体损失函数如下公式(4-5、4-6、4-7):
(4-5)
(4-6)
(4-7)
生成器损失采用LSGAN[77]的形式增加稳定性,两个生成器损失函数如下公式(4-8、4-9、4-10、4-11)
(4-8)
(4-9)
(4-10)
(4-11)
上式中表示模型训练完成后判别器给出的理想评分,研究将设置为0.9代替1.0。下图分别为为0.9和1.0时生成图像,生成器和判别器采用改进后网络。下图4.15、4.15为取不同值时生成数据。
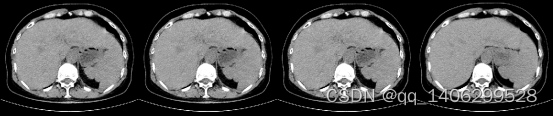
(A) (B) (C) (D)
图4.15 不同值结果对比(A)LDCT(B)=0.9(C)=1.0(D)NDCT
Figure 4.15 Comparison of different values (A) LDCT (B)= 0.9 ©= 1.0 (D) NDCT
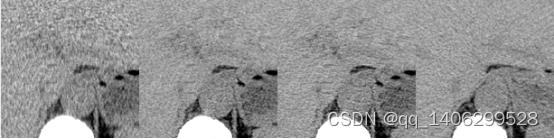
(a) (b) (c) (d)
图4.16 判别改进方案对比(部分区域)(a)LDCT(b)=0.9(c)=1.0(d)NDCT
Figure 4.16 Comparison of Discriminant Improvement Schemes (Partial Areas) (a) LDCT(b)=0.9©=1.0(d) NDCT
下表4.3为不同值生成图像客观评价指标。
表4.3 不同值生成图像客观指标对比
Table 4.3 Comparison of objective indexes of image generated by different values
图4.13 PSNR RMSE SSIM
=0.9 52.6076 0.0023 0.9618
=1.0 52.5419 0.0024 0.9604
从上图可以看出,=0.9时生成图像去噪效果较好,=1.0时生成图像出现轻微“颗粒状”,并处先轻微暗条纹。从上表客观参数也可以看出=0.9在PSNR、RMSE和SSIM参数均取得较好效果。
从损失函数可以看出直接影响训练过程中生成器和判别器大小,降低可以降低两个生成器和两个判别器值。训练用CT数据是16位高精数据,与8位图像数据相比,图像的生成和降噪需要更强的网络性能。在训练开始时损失相对会较大,如果采用=1.0,网络可能会因为较大的损失导致模式崩塌,训练困难,无法达到理想效果。采用=0.9降低开始训练时的损失,使网络更容易训练到理想值。
4.4 网络训练
4.4.1 训练参数说明
网络采用Adam[70]算法进行优化,训练开始学习率为2*10-4,之后没迭代10000学习率缩小为原理十分之一。为10,训练输入数据batch_size为16。
4.4.2 训练环境
计算机硬件:处理器:Intel i7 6700K,内存:64GB,显卡核心NVIDIA GeForce TITAN X,显存:12GB。
软件环境:深度学习框架:tensorflow1.8,卷积神经网络语言:python3.6。
4.4.3 训练数据集及处理
实验选择两种数据对方案验证研究:(1)胸腹部数据,数据均为非对齐数据,低剂量CT数据和对应标准剂量CT数据结构不同。(2)MAYO数据,对齐数据,用来验证网络的鲁棒性,同时验证提出的无监督训练方法与经典监督学习方法的性能差距。
(1)胸腹部数据包括11个人胸腹部不同部位数据,如图4.17所示。其中低剂量CT数据数量为658,标准剂量CT数据数量为657,所有数据分辨率均为512×512,其它参数如下表所示1。训练随机选取其中10人作为训练集,剩余1人作为测试集。
胸腹部数据为非对齐数据,即低剂量CT图像和与其成对的标准剂量CT图像结构存在差异,如下图所示:
表4.4 中国临床数据参数
Table 4.4 Mingfeng clinical data parameters
low/
normal 扫描部位 Thickness Kvp ma filter kernel r/s Exposure
low chest 5 120 50 Large CHEST_STND+ 0.5 25
normal chest 5 120 240 Large CHEST_STND+ 0.5 120
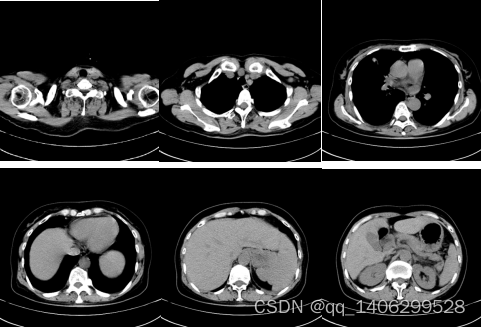
图4.17 中国临床数据不同部位CT实例
Figure 4.17 CT Examples of Different Locations of Clinical Data in China
(2)MAYO数据来自MAYO诊所,其曾应用于“2016年mayo低剂量CT挑战赛”,包括10个人共5940对(低剂量和对应正常剂量)3mm厚度,四分之一标准剂量的CT图像,数据尺寸为512*512,MAYO数据集部位如下图4.18所示。训练时随机选取其中9人为训练数据集,剩余1人作测试集。
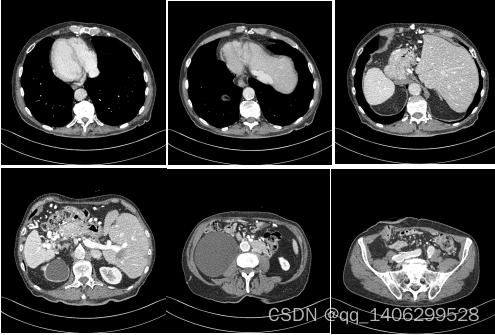
图4.18 MAYO临床数据不同部位CT实例
Figure 4.18 CT Examples of Different Locations of MAYO Clinical Data
数据采用3.3.3相同方式进行处理,从原图像中滑动切割出尺寸位64×64的数据进行训练,同时扩大了训练数据量。
鉴于本章研究方法利用非对齐的低剂量CT数据和标准剂量CT数据,在训练时将数据随机乱序。研究基于tensorflow深度学习框架进行训练,选择CT图像所有像素和扩大255倍大于6数据作为训练集,随机打乱顺序后生成tfrecords格式数据,训练时低剂量CT数据对应可能是任意一张标准剂量CT数据中剪裁出的任一张标准剂量CT数据。由于低剂量CT数据和标准剂量CT数据像素值的不同导致筛选后低剂量CT数据量和标准剂量CT数据量存在差异。中国临床胸腹部数据剪切筛选后低剂量CT数据数量为86878,标准剂量CT数据数量为86877。MAYO临床数据剪切筛选后低剂量CT数据和标准剂量CT数量为265090。
4.5 实验结果
实验对两个数据分开进行训练和测试,通过加入多种对比实验验证提出的方法,方法为包括由Chen H等提出的经典低剂量CT去噪方法RED-CNN,Kang Eunhee等[51]提出的CCADN(Cycle-consistent adversarial denosing networ),BM3D进行对比。
CCDAN[51]由Kang Eunhee等人提出,该网络利用心脏部位非对齐CT数据进行训练,心脏部位由于心跳等原因无法获取完全的对齐的CT数据,其利用CycleGAN[58]和DiscoGAN[59]思想,将生成器更换为其前期工作的低剂量CT去噪网络[60],判别器采用PatchGAN[61]网络判别器,加入consistency-loss保证模型的生成效果。CCDAN是目前唯一针对非对齐CT进行去噪的深度学习卷积神经网络方法。
(1)中国临床数据集:中国临床数据均为非对齐数,无法采用客观标准(PSNR、RMSE、SSIM)评估,这里仅进行视觉观察来判断生成图像的质量好坏。数据集包括胸腹多个部位,实验选取两个部位进行展示分析。
部位一:
下图4.19、4.20分布为对比低剂量CT去噪算法生成图像。

(A) (B) (C) (D) (E)
图4.19 去噪算法对比1(A)LDCT(B)RED-CNN(C)CCDAN(D)BM3D(E)PROPOSED
Figure 4.19 comparison of denoising algorithms(A)LDCT(B)RED-CNN(C)CCDAN(D)BM3D(E)PROPOSED

(a) (b) (c) (d) (d)
图4.20 去噪算法对比1(部分区域)(A)LDCT(B)RED-CNN(C)CCDAN(D)BM3D(E)PROPOSED
Figure 4.20 comparison of denoising algorithms1(Partial Areas)(A)LDCT(B)RED-CNN(C)CCDAN(D)BM3D(E)PROPOSED
从上图可以看出,由于胸腹部临床数据噪声分布比较复杂,并且其低剂量CT数据和标准剂量CT数据是非对齐导致参与对比的卷积神经网络方法无法达到理想性能。从红色方框和蓝色箭头指的方位可以看出,RED-CNN生成数据比较模糊,细节表现较差;CCDAN出现暗点,同样无法完成去噪效果;BM3D有一定的去噪性能,但是整体过于平滑导致模糊;提出的方法在参与对比的方法中表现较好,生成图像去噪效果较好,边缘处细节还原较好。
部位二:

(A) (B) (C) (D) (E)
图4.21 去噪算法对比2(A)LDCT(B)RED-CNN(C)CCDAN(D)BM3D(E)PROPOSED
Figure 4.21 comparison of denoising algorithms(A)LDCT(B)RED-CNN(C)CCDAN(D)BM3D(E)PROPOSED

(a) (b) (c) (d) (d)
图4.22 去噪算法对比2(部分区域)(a)LDCT(b)RED-CNN(c)CCDAN(d)BM3D(e)PROPOSED
Figure 4.22 comparison of denoising algorithms1(Partial Areas)(a)LDCT(b)RED-CNN(c)CCDAN(d)BM3D(e)PROPOSED
从图4.22可以看出提出的方法细节是保留最好的(图中红色矩形框数据),其它方法细节均出现缺失现象。
(2)MAYO诊所数据
MAYO诊所临床数据具有对齐的低剂量CT和标准剂量CT数据,为了验证提出方法利用非对齐数据进行训练,与监督深度学习方法利用对齐数据进行训练性能差异。RED-CNN利用对齐的数据训练RED-CNN,其它方法用随机打乱的非对齐数据进行训练。效果如下图所示:
部位一:

(A) (B) (C) (D) (E)
图4.23 去噪算法对比1(A)LDCT(B)RED-CNN(C)CCDAN(D)PROPOSED(E)NDCT
Figure 4.23 comparison of denoising algorithms1(A)LDCT(B)RED-CNN(C)CCDAN(D)PROPOSED(E)NDCT
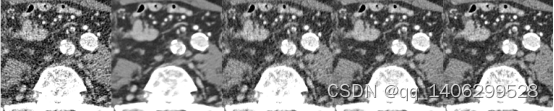
(a) (b) (c) (d) (e)
图4.24 去噪算法对比2(部分区域)(A)LDCT(B)RED-CNN(D)CCDAN(D)PROPOSED(E)NDCT
Figure 4.24 comparison of denoising algorithms1(Partial Areas)(A)LDCT(B)RED-CNN(D)CCDAN(D)PROPOSED(E)NDCT
从红色方框和黄色箭头指的方位可以看出,RED-CNN生成数据视觉效果较好,边界也很清晰,相对标准剂量CT数据一定平滑效果;CCDAN生成数数产生一定去噪效果,但在边界处细节变现不佳;提出的方法生成数据边缘处细节还原较好;
接下来各种方法生成数据与标准剂量CT的绝对差异(Absolutely Different)图像观察各种方法去噪水平,理论情况下低剂量CT数据和对应的标准剂量CT数据仅由噪声差异,两者做差只留下噪声图像。各种绝对差异图像噪声越少说明去噪越好。如图4.25所示。

(a) (b) (c) (d)
图4.25 与标准剂量CT绝对差异1(a)LDCT(b)RED-CNN(c)CCDAN(d)PROPOSED
Figure 4.25 absolute difference with standard dose CT(a)LDCT(b)RED-CNN(c)CCDAN(d)PROPOSED
通过观察各种方法的绝对差异图像,低剂量CT图像与标准剂量CT图像做差后留下大量噪声,提出方方法与标准剂量CT图像绝对差异噪声相对较少;RED-CNN方法生成图像与标准剂量CT图像绝对差异噪声水平噪声稍多;CCDAN方法生成图像噪声最多。从各种方法生成图像与标准剂量CT图像卷对差异图像可以看出提出方法效果最佳。下表4.5为几种算法客观指标对比。
表4.5 去噪算法客观指标评价
Table 4.5 objective index evaluation of denoising algorithm
图4.21 图4.22
PNSR RMSE SSIM PNSR RMSE SSIM
LDCT 40.4029 0.0095 0.9348 37.2264 0.0138 0.9041
REDCNN 43.6835 0.0065 0.9668 40.0188 0.0100 0.9527
CycleGAN 35.3252 0.0171 0.8777 34.6700 0.0185 0.9104
CCADN 41.6770 0.0082 0.9518 38.6685 0.0117 0.9364
Proposed 43.1041 0.0070 0.9622 39.9616 0.0100 0.9505
部位二:

(A) (B) (C) (D) (E)
图4.26 去噪算法对比2(A)LDCT(B)RED-CNN(C)CCDAN(D)PROPOSED(E)NDCT
Figure 4.26 comparison of denoising algorithms2(A)LDCT(B)RED-CNN(C)CCDAN(D)PROPOSED(E)NDCT

(a) (b) (c) (d) (e)
图4.27 去噪算法对比2(部分区域)(a)LDCT(b)RED-CNN(c)CCDAN(d)PROPOSED(e)NDCT
Figure 4.27 comparison of denoising algorithms1(Partial Areas)(a)LDCT(b)RED-CNN(c)CCDAN(d)PROPOSED(e)NDCT
通过观察图4.25几种算法生成图像,RED-CNN视觉效果相对较好,研究提出的算法与标准剂量CT数据最接近,CCDAN也由一定的去噪效果但整体与我们提出算法弱一些。下表4.6为几种算法客观指标对比2。
表4.7 去噪算法客观指标评价2
Table 4.7 objective index evaluation of denoising algorithm2
图4.24 图4.25
PNSR RMSE SSIM PNSR RMSE SSIM
LDCT 30.6264 0.0294 0.9419 31.4330 0.0268 0.9342
REDCNN 34.0790 0.0198 0.9743 34.9124 0.0180 0.9725
CCADN 31.6489 0.0262 0.9575 32.6286 0.0234 0.9546
Proposed 33.3004 0.0216 0.9672 0.0194 34.2275 0.9655
从客观评价指标来看,使用对齐数据进行训练的RED-CNN取得最好的成绩,用非对齐数据进行训练的网络中我们的方法是最好的。下图为与标准剂量CT的绝对差异图,从图中可以看出我们的方法与标准剂量CT差异最小。

(a) (b) (c) (d)
图4.28 与标准剂量CT绝对差异2(a)LDCT(b)RED-CNN(c)CCDAN(d)PROPOSED
Figure 4.28 absolute difference with standard dose CT2(a)LDCT(b)RED-CNN(c)CCDAN(d)PROPOSED
为了避免测试数据的片面性,将所有测试数据(共526对数据)全部测试计算PSNR、RMSE和SSIM,计算整体均值的偏差,如下表4.7所示。
表4.7 测试集整体客观评价指标(均值±偏差)
Table 4.7 overall objective evaluation index of test set (mean ± deviation)
PNSR RMSE SSIM
LDCT 39.6462±1.7938 0.0107±0.0025 0.9156±0.0337
REDCNN 43.3272±1.5857 0.0069±0.0014 0.9621±0.0142
CCADN 41.1395±1.4650 0.0089±0.0017 0.9393±0.0227
Proposed 42.5520±1.6284 0.0076±0.0016 0.9517±0.0195
从上表客观指标参数可以看出,当用对齐数据时,无论单张CT图像、从图像中截取的部分区域还是整个测试集,监督学习方法RED-CNN取得了最好的成绩,研究提出的方法在用非对齐低剂量CT数据和标准剂量CT数据训练的网络中取得最好水平。
5.5 本章小结
为了让深度学习卷积神经网络方法可以利用非对齐的低剂量CT数据和标准剂量CT数据进行训练,本章提出一种基于CycleGAN生成对抗网络的低剂量CT去噪方法,通过设计生成对抗网络生成器和判别器解决了非对齐数据训练问题。与多种方法对比,获得非监督方法的最佳性能。
5 全文总结及展望
5.1 全文总结
本文以低剂量CT去噪为研究背景,基于深度学习卷积神经网络方法开展研究。分析了卷积神经网络低剂量CT去噪中遇到的问题:(1)低剂量CT图像中钙化点问题。由于钙化点图像数量占比很少,同时钙化点与噪声类似,只与噪声稍大。一起的低剂量去噪网络很容易将其一起去除,本文提出一种可以保留钙化点的低剂量CT去噪方法,通过数据、设计去噪网络并通过设计不同的损失函数分两次训练去噪网络达到保留钙化点的模型。(2)非对齐低剂量CT和标准剂量CT数据的训练问题。现有基于深度学习卷积神经网络的低剂量CT去噪方法需要结构相同的对齐低剂量CT数据和标准剂量CT数据训练,胸腹部等部位较难获得对齐数据。本文通过利用CycleGAN生成对抗网络模型重新设计生成器和判别器获得一种基于深度学习的低剂量CT去噪方法,可以利用非对齐数据进行训练并获得较好水平。
5.2 展望
本文提出的低剂量CT去噪方法还有需要改进的地方。
首先,针对基于深度学习的低剂量CT去噪保留钙化点方法,虽然方法取得了较好的效果,当仍存在一些问题。1、钙化点不能量化,提出的方法仅能保证数据处理时添加的钙化点及更大的钙化点。这样每次都要选取需要大小的钙化点。2、网络训练需要分为两步,增大了训练的复杂度。如果可以获得大量的含有钙化点数据集,进行分析量化钙化点,可以通过更好的保留钙化点去噪模型。
其次,针对非对齐低剂量CT和标准剂量CT训练问题,网络运用的了CycleGAN生成对抗网络框架,包括了两个生成器和两个判别器,网络训练速度较慢。目前针对非对齐CT训练网络得到的模型与用对齐数据训练效果相比,生成图像的效果还有一定差距,后期可以设计更加高效的高性能可以利用非对齐低剂量CT数据和标准剂量CT数据进行训练的网络。
参考文献
[1]崔宝成.浅析医学影像技术学-CT[J/OL].世界最新医学信息文摘(连续型电子期),2015, 15(72):111-112.
[2]Hounsfield and G. N. Computerized transverse axial scanning (tomography): Part 1.Description of system[J]. The British Journal of Radiology, 1973, 46(552):1016-1022.
[3]Ambrose and James. Computerized transverse axial scanning (tomography). Part 2.Clinical application*[J]. The British Journal of Radiology, 1973, 46(552):1023-1047.
[4]Kalender W A, Seissler W, Klotz E, et al. Spiral volumetric CT with single-breath-hold technique, continuous transport, and continuous scanner rotation [J]. Radiology, 1990,176(1):181-183.
[5]Boyd D P, Lipton M J. Cardiac computed tomography[J]. Proceedings of the IEEE, 1983,71(3):298-307.
[6]罗立民. 低剂量 CT 成像的研究现状与展望 [J]. 数据采集与处理,2015, 30(1):24-34.
[7]李豪杰 浅谈科学技术的两面性[J].商情,2013,17:222-222.
[8]王燕玲 低剂量CT投影恢复方法及后处理算法研究[D]. 中北大学,2018.
[9]Giles J. Study warns of ‘avoidable’ risks of CT scans [J]. Nature, 2004, 431(7007): 391.
[10]Rothenberg L N , Pentlow K S.Radiation dose in CT [ J ] .Radio Graphics , 1992 , 12 , 1225 - 1243.
[11]Gartenschlager M , Schweden F , Gast K , et al.Pulmonary nodules:Detection with low - dose vsconventional- dose spiral CT[ J ] .European Radiology,1998,8:609-614.
[12]Jung K , Lee K , Kim S Y , et al.Low - dose , volumetric helical CT : Image quality , radiation dose , and usefulnessfor evalua -tion of bronchiectasis [ J ] .Invest Radiology , 2000 , 35 : 557 - 563.
[13]Diederich S , Windmann R , Windmann R , et al.Pulmonary nodules : Experimental and clinical studies at low - dose CT [ J ] .Radiology , 1999 , 213 : 289 - 298.
[14]Shrimpton P C , Miller H C , Lewis M A , et al.Doses from computed tomography ( CT ) examinations in the UK - 2003review[ R ] .UK : National Radiological Protection Board , 2005.
[15]Brenner D J , Hall E J.Computed tomographyan increasing source of radiation exposure [ J ] .New England Journal of Medi -cine , 2007 , 357 ( 22 ): 2277 - 2284.
[16]Pierce D A,Preston D L.Radiation-related cancer risks at low doses among atomic bomb survivors[J].Radiat Res,2000,154(2):178-186.
[17]Mettler FA Jr,Bhargavan M,Faulkner K,et al.Radiologic and nuclear medicine studies in theUnited States and worldwide:frequency,radiation dose,and comparison with other radiation sources-1950-2007[J].Radiology,2009,253(2):520-531.
[18]Hricak H,Brenner DJ,Adelstein SJ,et al.Managing radiation use in medical imaging:a multifaceted challenge[J].Radiology,2011,258(3):889-905.
[19]BerringtondeGonzalez,Amy.ProjectedCancerRisksfromComputedTomographicScansPerformedintheUnitedStatesin2007[J].ArchivesofInternalMedicine,2009,169(22):2071.
[20]Goo HW.CT radiation dose optimization and estimation:an update for radiologists[J].Korean J Radiol,2012,13(1):1-11.
[21]Naidich D P, Marshall C H, Gribbin C, et al. Low-dose CT of the lungs: preliminary observations [J]. Radiology, 1990, 175(3): 729-731.
[22] Kalra M K , Maher M M , Toth T L , et al.Strategies for CT radiation dose optimization [ J ] .Radiology , 2004 , 230 : 619 -628.
[23]Jung K , Lee K , Kim S , et al.Low - dose , volumetric helical CT : Image quality , radiation dose , and usefulness for evaluation of bronchiectasis [ J ] .Invest Radiology , 2000 , 35 : 557 - 563.
[24]林少春. 基于有序子集的惩罚加权最小二乘低剂量CT优质重建算法研究 [D].广州:南方医科大学,2008.
[25]Hsieh J. Adaptive streak artifact reduction in computed tomography resulting from excessive x-ray photon noise [J]. Medical Physics, 1998, 25(11): 2139-2147.
[26]Yu L, Manduca A, Trzasko J D, et al. Sinogram smoothing with bilateral filtering for low-dose CT [C]. The International Society for Optical Engineering, 2008(6913):1605-7422.
[27]Zhang Y, Zhang J, Lu H. Statistical sinogram smoothing for low-dose CT with segmentation-based adaptive filtering [J]. IEEE Transactions on Nuclear Science, 2010, 57(5): 2587-2598.
[28]Gui Z, Liu Y. Noise reduction for low-dose X-ray computed tomography with fuzzy filter [J]. Optik, 2012, 123(13): 1207-1211.
[29]许琼. X 线 CT 不完备投影数据统计重建研究[D]: 西安交通大学, 2012.
[30]崔学英.低剂量CT的投影域去噪算法和后处理算法研究[D]:中北大学,2015.
[31]高上凯. 医学成像系统[M]. 北京, 清华大学出版社. 2010.
[32]顾本力, 万遂人, 赵兴群. 医学成像原理[M]. 北京, 科学出版社. 2012.
[33]Geyer L L, Schoepf U J, Meinel F G, et al. State of the art: iterative CT reconstruction techniques [J]. Radiology, 2015, 276(2):339-357.
[34]张权. 低剂量 X 线 CT 重建若干问题研究[D]. 东南大学, 2015.
[35]上官宏. 低剂量 X 线 CT 统计迭代重建方法研究[D]. 中北大学, 2016.
[36]刘进. 特征稀疏表示的低剂量 CT 成像方法研究[D]. 东南大学, 2018.
[37]Kak A C, Slaney M, Wang G. Principles of computerized tomographic imaging [J]. Medical Physics, 2002, 29(1):106-108.
[38]董继伟.CT迭代重建技术原理及其研究进展[J].中国医学装备,2016,vol.13(10),128-133
[39]Wang G,Yu H,De Man B.An outlook on x-ray CT research and development[J].Medical physics,2008,35(3):1051-1064.
[40]Thibault J B, Sauer K D, Bouman C A, et al. A three-dimensional statistical approach to improved image quality for multislice helical CT [J]. Medical Physics, 2007, 34(11):4526.
[41]Zhang R, Ye D, Pal D, et al. A gaussian mixture MRF for model-based iterative reconstruction with applications to low-dose X-ray CT [J]. IEEE Transactions on Computational Imaging, 2016, 2(3): 359-374.
[42]朱永成,陈阳,罗立民,基于字典学习的低剂量 X-ray CT 图像去噪[J].东 南 大 学 学 报,2012,42(5):864-868.
[43]郝立巍,程远雄,汪天富,陈思平.采用局部相位的 N onlocal低剂量CT图像去噪[J],华 中 科 技 大 学 学 报 (自 然 科 学 版).2012,40(7):42-46.
[44]Zamyatin A, Krylov R, Shi B, et al. Adaptive multi-scale total variation minimization filter for low dose CT imaging [C]. SPIE Medical Imaging. 2014: 903426.
[45]Chen Y, Chen W, Yin X, et al. Improving low-dose abdominal CT images by weighted intensity averaging over large-scale neighborhoods [J]. European Journal of Radiology,2011, 80(2): e42-e49.
[46]Kang D, Slomka P, Nakazato R, et al. Image denoising of low-radiation dose coronary CT angiography by an adaptive block-matching 3D algorithm [C]. SPIE Medical Imaging, 2013: 86692G.
[47]Chen H , Zhang Y , Zhang W H , et al .Low - dose CT denoising with convolutional neural network[ C ].Proceedings of IEEE 14th International Symposium on Biomedical Imaging , 2017 : 143 - 146.
[48]Chen H, Zhang Y, Zhang W, et al. Low-dose CT via convolutional neural network [J].Biomedical Optics Express, 2017, 8(2): 679.
[49]Chen H, Zhang Y, Kalra M K, et al. Low-dose CT with a residual encoder-decoder convolutional neural network(RED-CNN) [J]. IEEE Trans Med Imaging, 2017, PP(99):1-1.
[50]Eunhee K, Chang W, Yoo J, Ye JC. Deep convolutional framelet denosing for low dose CT via wavelet residual network. IEEE Trans Med Imaging.2018;37:1358–1369.
[51]E.Kang, et al. Cycle-consistent adversarial denoising network for multiphase coronary CT angiography[J].Medical physics, 2019,46(2):550-562.
[52]章云港,易本顺,吴晨玥,冯雨.基于卷积神经网络的低剂量CT图像去噪方法[J].光学学报,2018,38(4):
[53]He K M , Zhang X Y , Ren S Q , et al .Deep residual learning for image recognition [ C ] Processing of IEEE Conference on Computer Vision and Pattern Recognition , 2016:770 - 778.
[54]吕晓琪,吴 凉,谷 宇,张 明,李 菁. 基于深度卷积神经网络的低剂量 CT 肺部去噪[J].电子与信息学报.2018,40(6):1353-1359.
[55]徐曾春,叶 超,杜振龙,李晓丽.基于改进型 WGAN的低剂量CT图像去噪方法[J].光学与广电技术.2019.17(3):101-107.
[56]I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning. Cambridge,MA: The MIT Press, 2016.
[57]Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature 521(7553),436–444 (2015).
[58]Zhu J-Y, Park T, Isola P, Efros AA. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: IEEE International Conference on omputer Vision (ICCV), 2242–2251; 2017.
[59]Kim T, Cha M, Kim H, Lee JK, Kim J. Learning to discover cross-domain relations with generative adversarial networks. In: International Conference on Machine Learning (ICML),1857–1865; 2017.
[60]Kang E, Chang W, Yoo J, Ye JC. Deep convolutional framelet denosing for low dose CT via wavelet residual network. IEEE Trans Med Imaging.2018;37:1358–1369.
[61]Isola P, Zhu J-Y, Zhou T, Efros AA. Image-to-image translation with conditional adversarial networks. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5967–5976; 2017.
[62]Goodfellow I J,Pouget-Abadie J,Mirza M,et al. Generative adversarial networks[J]. Advances in Neural Information Processing Systems,2014,3(2):2672-2680.
[63]LeCun, B.Boser, J.S.Denker, D.Henderson, R.E.Howard, W.Hubbard, and L.D.Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989.
[64]Alex Krizhevsky, Ilya Sutskever, Geoffrey E.Hinton. ImageNet Classification with Deep Convolutional Neural Networks.
[65]Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, november 1998.
[66] Gu, J., Wang, Z., Kuen, J., Ma, L., Shahroudy, A., Shuai, B., Liu, T., Wang, X., Wang, L., Wang, G. and Cai, J., 2015. Recent advances in convolutional neural networks. arXiv preprint arXiv:1512.07108.
[67]K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition.
[68]HEK, ZHANGX, RENS, etal. Deep Res idual Learning for Image Recognition[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016:770-778.
[69] Johnson J,Alahi A,Li F F. Perceptual losses for real-time style transfer and super-resolution[C]. Proceedings of European Conference on Computer Vision2016(ECCV 2016). Springer International Publishing,2016:694-711.
[70] Kingma D P,Ba J. Adam:a method for stochastic optimization[C]. Proceedings of the 3rd International Conference on Learning Representations,2015.
[71] A. Krizhevsky, I. Sutskever, G. E. Hinton. ImageNet classification with deep convolutional neural networks[C]. Neural Information Processing Systems, 2012, 1097-1105.
[72]HE K, ZHANG X, REN S, et al. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification: 2015 IEEE International Conference on Computer Vision[C], Santiago, 2015.
[73]D. Kingma, J. Ba. Adam: A Method for Stochastic Optimization. International Conference for Learning Representations, 2015.
[74]K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition.
[75]Champion T,Pascale L D,Juutinen P. The Wasserstein distance:local solutions and existence of optimal transport maps [J]. SIAM Journal on MathematicalAnalysis,2008,40(1):1-20.
[76]Hang Zhao , Gallo, Orazio, Frosio, Iuri, Kautz, Jan. IEEE Transactions on Computational Imaging, March 2017, Vol.3(1), pp.47-57.
[77]Mao X, Li Q, Xie H, Lau RY, Wang Z, Smolley SP. Least squares generative adversarial networks. In: IEEE International Conference on Computer Vision (ICCV), 2813-2821; 2017.
[78]
















 7486
7486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











