






1. 研究背景与目标
传统单模态情感分析方法难以捕捉多模态情感表达的复杂性,尤其当不同模态信号存在冲突时。现有的多模态大模型在细粒度情绪识别(如微表情捕捉)和多样化任务泛化(如情绪归因推理)上仍有不足。M2SE 旨在通过多阶段多任务指令调优策略,提升模型对情感与情绪的统一感知能力
2. 核心方法:M2SE 策略
M2SE 是一种分阶段、多任务联合训练框架,其核心设计包括:
- 多阶段训练:
- 阶段一:跨模态对齐(如视觉-语言特征融合)
- 阶段二:多任务指令调优(覆盖情感分析、情绪识别、面部表情识别、情绪归因推理、情绪诱因提取等五类任务)
- 多任务协同:通过共享模型参数与任务间知识迁移,增强模型对复杂情绪场景的泛化能力。例如,情绪诱因提取任务的结果可为情绪识别提供上下文依据。
- 动态学习机制:根据任务难度调整损失权重,避免简单任务主导训练过程。
3. 数据集与模型
- 数据集 EMT:
包含多模态(文本、图像、视频)标注数据,支持五类任务,覆盖日常对话、社交媒体、临床访谈等场景,强调细粒度情绪标签(如“沮丧-失望-悲伤”的层级划分)和跨模态一致性标注- 模型 EmoVerse:
基于通用 MLLM 架构(未修改基础结构),通过 M2SE 策略注入多任务指令遵循能力。其创新点在于任务感知的提示词设计,例如通过指令明确区分“情绪识别”与“情绪归因推理”的目标差异4. 实验结果与优势
- 性能提升:在主流多模态情感数据集(如 CMU-MOSEI、IEMOCAP)上,EmoVerse 在情绪分类准确率(+5.2%)、细粒度表情识别(+7.8%)等指标上达到 SOTA
- 泛化能力:在少样本场景下,M2SE 的跨任务知识迁移显著优于单任务调优模型。
- 可解释性:通过情绪诱因提取任务,模型可输出“情绪-诱因”关联对(如“愤怒-评论区恶意言论”),增强决策透明性
5. 创新点与意义
- 方法论创新:首次将多阶段指令调优与多任务学习结合,解决情感分析中模态冲突与任务碎片化问题
- 技术通用性:M2SE 可迁移至其他 MLLM(如 LLaVA、Qwen-VL),为多模态理解提供通用训练范式
- 应用潜力:在心理健康评估(如抑郁检测)、人机交互(如情感机器人)等领域具实用价值
总结
M2SE 通过系统性任务设计与分阶段训练策略,推动多模态情感分析从“单任务专用模型”向“通用情绪理解引擎”演进。其代码与数据集已开源,为后续研究提供重要基线
(未完待续.....
(!!!数据没开源,没法玩,只能看看思路
摘要
情绪分析和情感识别对于人机交互和抑郁症检测等应用至关重要。传统的单模态方法由于不同模态之间存在冲突信号,往往无法捕捉到情感表达的复杂性。当前的多模态大语言模型(MLLMs)在检测微妙的面部表情以及处理广泛的情绪相关任务方面也面临挑战。为解决这些问题,我们提出了 M2SE,这是一种用于通用多模态大语言模型的多阶段多任务情感和情绪指令微调策略。该策略采用组合式方法,让模型针对多模态情感分析、情绪识别、面部表情识别、情绪原因推理和情绪因果对提取等任务进行训练。我们还推出了情绪多任务数据集(EMT),这是一个支持上述五项任务的自定义数据集。我们的模型EmoVerse基于基础的多模态大语言模型框架构建,无需进行修改,但在使用 M2SE 策略进行训练后,它在这些任务上都取得了显著的提升。大量实验表明,EmoVerse 优于现有方法,在情感和情绪任务中达到了当前最优水平。这些结果凸显了 M2SE 在增强多模态情绪感知方面的有效性。数据集和代码可在 https://github.com/xiaoyaoxinyi/M2SE 获取。
I. 引言
情绪分析和情感识别是人机交互 [1]、抑郁检测 [2] 等多个领域的关键组成部分。这些任务涉及识别人类交流中的情绪和情感状态。虽然单模态方法(依赖于面部 [3]、文本 [4] 或音频 [5] 等单个模态)在情绪和情感检测方面取得了显著的成功,但它们在充分捕捉人类情感的复杂性方面存在内在限制。每种模态单独只能提供情绪景观的部分视图,因此很难以全面和整体的方式分析数据。此外,单模态系统容易产生误解,尤其是在情绪表达间接或模糊的情况下,例如讽刺 [6]、反语或微妙的情绪线索。这些挑战凸显了对情绪和情感分析的更综合和多模态方法的需求,以克服单模态方法的局限性。
现有的融合多模态信息的方法通常依赖于跨模态交互来从不同模态中学习,并最终执行情绪分析或情感识别任务 [7]–[29]。然而,情绪和情感之间存在着内在的关系,而这些方法往往难以捕捉。简单地孤立地完成情绪或情感任务并不能有效地模拟特定情绪和相应情绪之间的复杂相互作用。
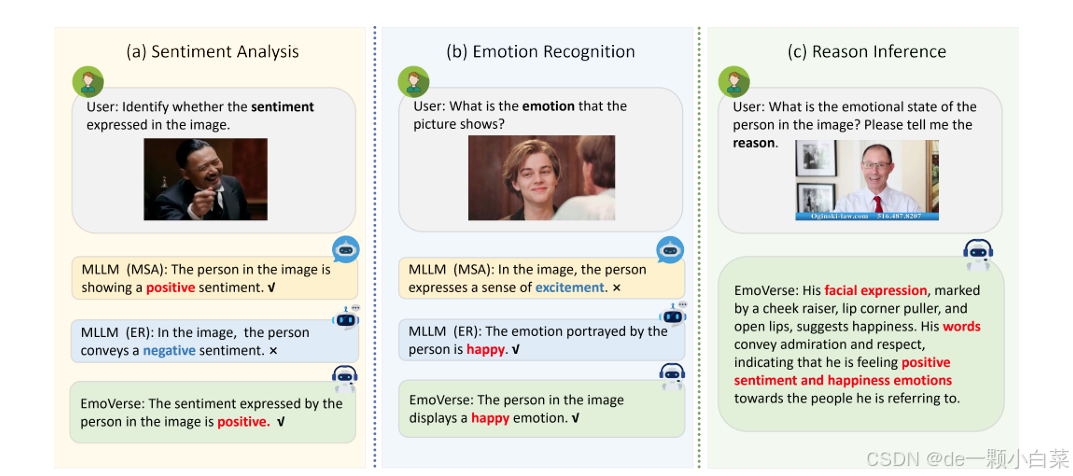
图1
a)仅在 MSA 任务上训练的 MLLM:
在 MSA 任务中,在 MSA 上训练的模型表现良好,而在 ER 上训练的模型表现不佳。
b)仅在 ER 任务上训练的 MLLM :
在 ER 任务中,在 ER 上训练的模型表现良好,而在 MSA 上训练的模型表现不佳。
c)使用 M2SE 策略训练的 MLLM :
使用 M2SE 策略训练的 EmoVerse 不仅在 MSA 和 ER 任务上表现出色,而且还成功完成了情感推理任务。
此外,尽管当前的多模态大型语言模型 (MLLM) 在视觉语言理解 [30]–[32] 等任务中表现出色,但它们在零样本设置下的多模态情绪分析和情感识别等任务中往往表现不佳。因此,微调仍然至关重要。如图 1 所示,尽管现有的 MLLM 在针对单个任务进行微调时取得了令人鼓舞的结果,但它们在其他任务上的表现却经常下降。这凸显了对通用 MLLM 的需求,这种 MLLM 能够在各种情绪和情感相关任务中表现良好,并以更综合、更全面的方式捕捉情绪和情感。
为了对具有多任务能力的任何 MLLM 进行微调,我们探索了不同任务之间的关系,并提出了一种称为 M2SE 的新策略:针对常见 MLLM 的多阶段多任务情感和情绪指令调整策略。通过探索任务关系,M2SE 采用了一种多阶段方法,在训练的每个阶段引入不同的任务,并根据每个任务的重要性为其分配不同的采样率。通过使用此策略,我们训练了EmoVerse模型,这是一个基于传统 MLLM 架构的模型,它集成了视觉和文本模态。值得注意的是,EmoVerse 在情感和情绪任务上取得了出色的表现,而无需任何专门的多任务学习模块。相反,它利用基本的 MLLM 结构和 M2SE 策略来有效地分析和推理复杂的情感背景。
此外,现有数据集往往无法提供训练模型所需的全面而细致的数据导致无法有效地处理多项任务。这凸显了对能够支持情绪分析中多任务学习的更强大数据集的迫切需求。为了弥补这一差距,我们推出了情绪多任务 (EMT) 数据集,专门设计用于支持五项不同任务的 MLLM:多模态情绪分析 (MSA)、情绪识别 (ER)、面部表情识别 (FER)、情绪推理 (ERI) 和情绪原因对提取 (ECPE) [33],[34]。通过整合多项任务,EMT 数据集促进了能够识别、推理和推断情绪原因的模型的开发。
总而言之,我们的主要贡献如下:
- 构建了 情感多任务 EMT 数据集
- 此数据集中的每条数据都包含针对五个任务的query和相应的标签
- EMT 数据集鼓励模型从不同任务的角度捕捉情绪与情感之间的关系,从而使模型能够提取更丰富的上下文信息
- 引入了 M2SE 策略: 多阶段多任务指令调优
- 该策略通过利用对各种情绪和情感相关任务的多阶段训练来实现有效的多任务学习。
- 据我们所知,这是 ECPE 任务首次作为多任务学习框架的一部分引入情绪领域。
- 开发了 EmoVerse 模型
- EmoVerse 通过采用 M2SE 策略统一了情绪和情感领域的任务
- 为了确保更好地适应边缘设备,我们使用两种不同的参数配置来训练模型:4B 和 8B
- EmoVerse 在各种任务中都表现出色
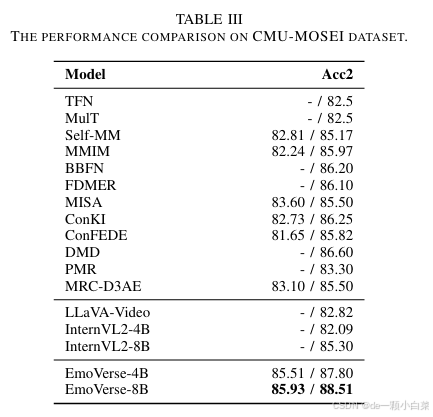
- 在 CMU-MOSEI 数据集的 MSA [35] 上,它的 Acc2 得分为 88.51%
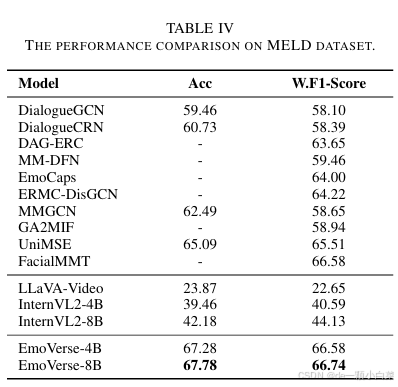
- 在 ER 的 MELD 数据集 [36] 上,它的加权 F1 得分为 66.74
- 此外,消融研究进一步验证了 M2SE 策略的有效性
II. 相关工作
A.多模态大型语言模型 (Multimodal Large Language Models,MLLM)
MLLM因其强大的推理能力而备受关注。这些模型通常使用标准框架训练以完成通用任务,该框架包括模态编码器、LLM和映射层(例如 Linear [30]、MLP [32]、[37] 或 Q-Former [38])。虽然 MLLM 在一般任务中表现出色,但由于对情绪特定数据集和情绪相关知识的训练不足,它们在 MSA 和 ER 方面表现不佳。最近的努力主要集中在通过结合多模态情绪数据集和情绪推理任务来改进 MLLM [39]、[40]。然而,这些模型在有效利用上下文信息方面仍然面临挑战,特别是在情绪分析中,理解情绪细微差别至关重要。
B. 多任务学习(multitask learning, MTL)
MTL是一种机器学习范式,它使模型能够同时学习多个相关任务,从而允许将一项任务的知识转移到其他任务 [41]。在情感计算中,多模态输入(例如文本、音频和视觉帧)携带着多样而独特的信息,MTL 框架旨在利用任务之间的协同作用来提高性能。例如,MTMM-ES 框架 [42] 联合执行情绪和情感分析,显示出比单任务模型更好的结果。UniMSE [11] 将 MSA 和 ER 统一在一个框架内。然而,它仅依靠标记数据来建立情绪和情感之间的关系,而没有充分利用多模态连接。
M2Seq2Seq [43] 提出了一种基于编码器-解码器架构的多模态多任务学习模型。最近,Emotion-LLaMA [39] 通过结合多任务学习(包括情绪推理)在 MER 中取得了令人鼓舞的结果。然而,尽管在 MER 中取得了成功,但 EmotionLLaMA 在 MSA 任务中仍然举步维艰,无法有效地合成情境信息进行情绪推理。
III. METHODOLOGY
本节介绍我们的工作,包括三个关键部分:EMT 数据集的构建、M2SE 策略的制定以及 EmoVerse 模型的开发。
A. EMT datasets
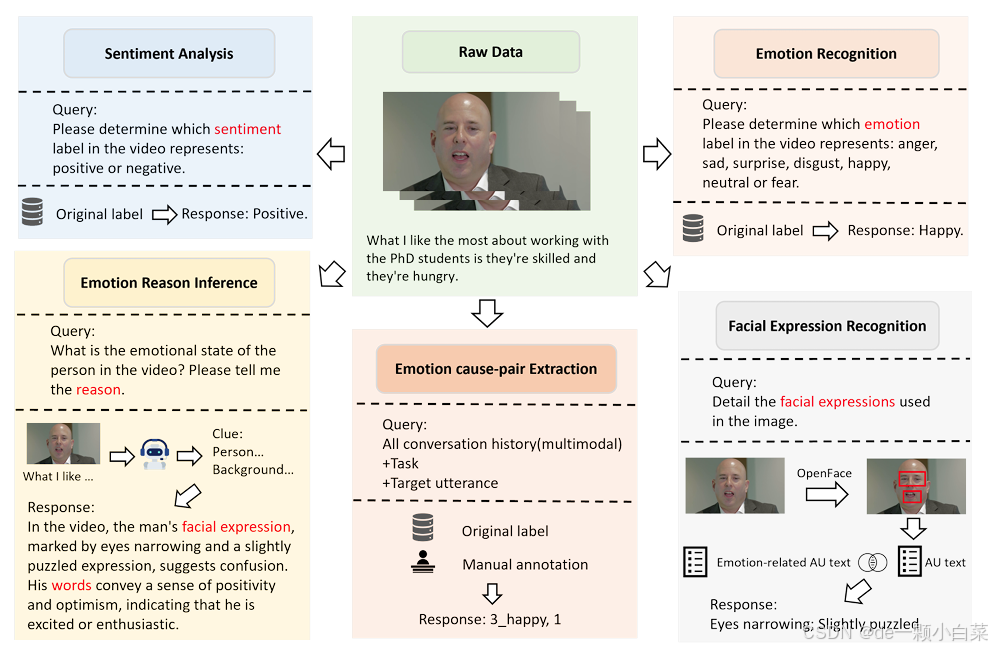
图2. EMT 数据集中的一个例子,包括情绪分析、情绪识别、情绪原因推理、面部表情识别和情绪原因对提取五项任务————及其数据构建过程。
EMT 数据集由 CMU-MOSEI、MELD 和 ECF2.0 [33] 数据集的数据整合而成,支持五项不同的任务:MSA、ER、FER、ERI 和 ECPC。图 2 展示了 EMT 数据集的一个示例
对于 MSA 和 ER 任务,我们使用源数据集中的原始情绪标签和情感注释作为任务标签。
由于注释 ECPE 任务的复杂性,我们参考 ECF 数据集的注释方法,手动注释部分数据。然后将其与现有的 ECF2.0 数据相结合,形成 EMT 数据集的 ECPE 部分,以进行进一步的情感因果关系分析。
在 FER 任务中,我们采用 MERR 数据集 [39] 中的方法,通过使用 OpenFace 工具为每个帧计算动作单元 (AU) 来提取峰值帧。每帧的综合得分由 AU 值相加确定,如下式所示:
(1)
- 其中 Sf 是帧 f 的综合得分
表示帧 f 处第 i 个面部动作单元的动作单元值. 选择得分最高的峰值帧来表示最具表现力的时刻.
- 对于包含多个角色的视频(例如 MELD 数据集中的视频),我们通过为每个角色分别提取峰值帧,然后通过比较所有角色的最高综合得分来选择最终峰值帧来改进该方法:
(2)
- 其中
是字符 i 的综合得分
- k表示帧中的字符总数
- 最终的峰值帧是所有字符中综合得分最高的帧
After selecting the peak frames, we extract the facial expression captions by combining the AUs from the peak frame with the predefined AU list corresponding to the emotion. Let represent the set of AUs from the peak frame for a given emotion, and
represent the predefined AU list for a specific emotion e. The common AUs are obtained by taking the intersection of the two sets:
(3)
where is the set of AUs common to both the peak frame and the emotion-specific AU list. These common AUs are then mapped to textual information to generate the FER annotations for the task. This approach enables the model to link the facial expressions captured in the peak frames with the corresponding emotional state.
在 ERI 任务中,我们将视频输入到 Internvl2-8B 模型中,生成人物和场景的详细描述。这些描述允许模型通过考虑面部表情、语音和环境背景来分析情绪原因。最后,我们使用LLaMA 3.18B 模型通过综合人物和场景描述来推断人物情绪的根本原因。
我们对来自三个数据集的原始数据进行了彻底的预处理和质量控制过程,系统地消除了有问题或嘈杂的数据。同时,我们按照上述方法对高质量样本进行手动整理。这涉及细化数据集以确保准确性和一致性,同时提取 FER 和 ERI 所需的标签。经过这种细致的细化后,最终的数据集在表 I 中列出,包括每个类别的任务数量。请注意,每个数据样本可以与多个任务相关联。下面的表 I 细分了可以使用的任务数量。
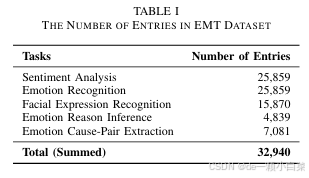
此外,我们将数据集转换为结构化格式,其中包括三个关键元素:查询query、response、image/video 。此格式有助于 MLLM 的指令调整。
B. EmoVerse
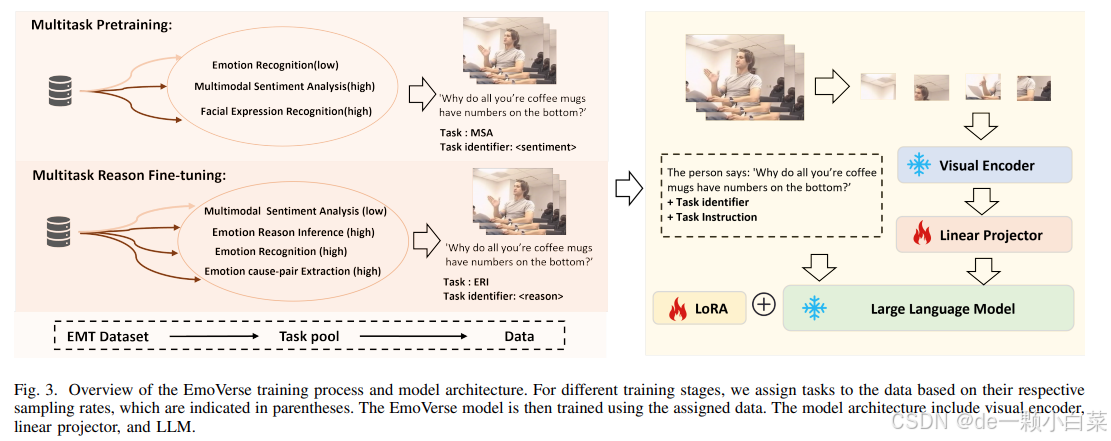
为了验证 M2SE 策略的有效性,我们选择了最广泛使用的 MLLM 框架,而不对其架构进行任何多任务修改。这确保了任何观察到的性能改进都可以直接归因于所提出的训练策略,而不是架构变化。所提出的 MLLM 架构 EmoVerse(如图 3 所示)由视觉编码器、线性投影仪和 LLM 组成。
我们使用 EMT 数据集按照 M2SE 策略训练 EmoVerse。
对于数据样本 D,输入由pair {v,t} 组成,其中 v 表示视频,t 表示文本。
首先,使用 Vision Transformer (ViT) 处理视频 v 以提取visual token,从而生成一组visual tokens Tv。然后,这些visual tokens Tv 经过线性变换 Wv,以使视觉特征与 LLM 的特征空间对齐。从数学上讲,这可以表示为:
(4)
where T′ v represents the aligned visual features.
Next, the text t, task identifiers, and instructions are tokenized and passed through the embedding layer of the LLM, producing the tokenized representation Tt. The tokenized visual features T′ v and the tokenized text Tt are then concatenated to form the final input to the model:
(5)
where X is the combined input. The model processes this concatenated input and outputs the response ˆ y, which corresponds to the task at hand:
(6)
where M is the model and ˆ y is the model’s prediction or answer.
C. 多阶段多任务情绪和情感指令调整
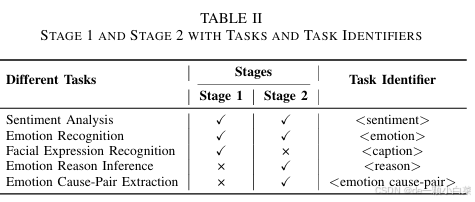
1) Stage 1 多任务预训练:
在训练的第一阶段,模型专注于三个关键任务:MSA、ER 和 FER。
- 情感分析(MSA):识别数据中表达的情感。
- 情绪识别(ER):识别所传达的情绪状态。
- 面部表情识别(FER):分析面部表情以捕捉情感线索。
我们从 EMT 数据集中随机选择了 15,000 个样本用于此阶段,为 MSA 和 FER 任务分配更高的采样率,同时为 ER 任务分配较低的采样率。此阶段的主要目标是使模型能够识别面部表情,并通过这些表情捕捉情绪和情感之间的关系。具体而言,FER 任务可帮助模型学习细粒度的面部特征,从而通过加强情绪线索和情绪之间的联系来提高 MSA 和 ER 任务的性能。
2) Stage 2 多任务推理微调:
在第一阶段,模型学习情绪和情感之间的基本关系以及面部表情识别,第二阶段引入了四个主要任务:MSA、ER、ERI 和 ECPE
- 情绪识别(ER):进一步增强模型识别情绪的能力。
- 情绪原因推理(ERI):通过考虑上下文信息分析情感表达背后的原因。
- 情绪原因对提取(ECPE):提取情绪及其潜在原因的对,促进对情感关系的更深入理解。
- 情感分析(MSA):在其他任务的同时,继续提升情感分析能力
在此阶段,我们从 EMT 数据集中选择剩余的样本,并将它们随机分布在各个任务中。值得注意的是,MSA 任务被分配了一个非常小的采样率,而其他三个任务——ER、ERI 和 ECPE——被分配了更高且相等的采样率。ERI 任务通过分析语音、面部表情和上下文信息,增强了模型推理情绪原因的能力,并建立在第一阶段学到的面部表情识别的基础上。另一方面,ECPE 任务通过将情绪反应与对话中的根本原因联系起来,提供了对情绪原因的更深入的洞察。通过提取情绪原因对,ECPE 促进了多模态和上下文信息的更好整合,帮助模型理解情绪、情感和上下文之间的复杂关系。第 1 阶段和第 2 阶段的详细信息见表 II。
IV. EXPERIMENTS
A. Experiments Setup
EmoVerse 仅在 EMT 数据集上进行训练,未添加任何外部数据,并在以下特定于任务的测试集上进行测试。
1) Sentiment Analysis:使用 CMU-MOSEI 数据集进行情感分析
数据集描述:CMU-MOSEI 数据集是 CMU-MOSI 数据集的扩展版本。它包含来自 1000 位发言者的 3228 个视频,总共包含 23453 个句子。与 CMU-MOSI 数据集类似,它涵盖多个情感维度,采用相同的注释标记方法
评估指标:基于负面/非负面(N/N)和负面/正面(N/P)方案计算的Acc-2结果
2) Emotion Recognition:使用 MELD 数据集进行 ER 分析
数据集描述:MELD 数据集是一个情感对话数据集,包含来自电影和电视节目的 1433 个对话片段和 13708 条话语。对话中的每个语句都标有七种情绪之一:愤怒、厌恶、悲伤、喜悦、中性、惊讶和恐惧。此外,MELD 数据集还为每个话语提供了情绪极性(积极、消极和中性)的注释。
评估指标:使用准确率Acc和加权F1分数进行评估
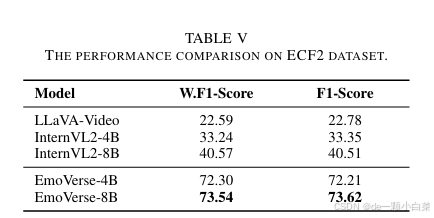
3) Emotion Cause-pair Extraction:使用 ECF2.0 数据集进行 ECPE
数据集描述:ECF2.0 数据集是一个全面的情感因果对提取资源,包含 1,715 个对话和 16,720 条话语。数据集中的每个话语都标注有情感因果对信息,有助于理解情感背景及其原因。数据集分为训练集和评估集,训练集中有 1,374 个对话和 13,619 条话语,测试集中有 341 个对话和 3,101 条话语。
评估指标:使用F1分数和加权F1分数进行评估
B. Implementation Details
For the visual encoder, we utilize pre-train ViT with input images resized to 448×448 pixels. During the fine-tuning process, the visual backbone is frozen, with the focus placed on training the linear projection layer.
For LLM, we employ Phi3-Mini [45] for EmoVerse-4B and InternLM-2.5-7B-Chat for EmoVerse-8B, both augmented with LoRA [46] for parameterefficient fine-tuning.
In each stage of training, we train for 2 epochs with LoRA hyperparameters set to r = 8 and a = 32. The learning rate is set to 1 × 10−5, and we use a warm-up cosine schedule for the learning rate decay. For EmoVerse-4B, the training is conducted on 2 NVIDIA RTX 3090 GPUs, requiring approximately 48 hours. For EmoVerse-8B, the training is executed on a NVIDIA A100 GPU, taking around 55 hours.
C. Results
1) Performance comparison
For MSA task, we compare our EmoVerse model with several SOTA baselines, including TFN[7],MulT[12],PMR[21],MISA[17],MMIM[14],SelfMM[13],BBFM[15],FDMER[16],CONKI[18],DMD[20], ConFEDE[19],andMRC-D3AE[27].In ERtask,we evaluate our model against baseline models with DialogueGCN[22], DialogueCRN[23],DAG-ERC[8],MM-DFN[24],EmoCaps [9], ERMC-DisGCN [25], MMGCN [26], GA2MIF [10], UniMSE[11], andFacialMMT[47].
此外,对于 MSA 和 ER,我们选择了能够同时处理图像和视频的高级模型。其中包括 LLaVA-Video[48] 和 InternVL2[49],它们都旨在有效处理多模态输入。表 III 和表 IV 中显示的性能比较结果清楚地表明,EmoVerse 在两个任务中都实现了 SOTA 性能,在准确性和稳健性方面超越了所有上述基线模型。
对于 ECPE 任务,我们仅对 MLLM 进行测试,因为它们更适合处理任务的复杂性和多模态性质。表 V 显示了 ECPE 的结果。
2) Analysis of EmotionReasoning
为了展示 EmoVerse 的定性性能,我们对不同模型的情感推理结果进行了详细比较。
图 4 展示了五种模型的情感推理输出:GPT-4o、Video-LLaMA2 [50]、LLaMA-Video、InternVL2 和 EmoVerse。视频中,一名女性表现出强烈的惊讶反应,突显了模型从多模态输入中推断情绪状态的能力。

















 58
58

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









