







算法简介
Isolation Forest算法将分布稀疏,且距离高密度群体较远的点定义为异常点。从统计学角度来看,在数据空间里,若数据点在一个区域内的分布都很稀疏,表示此区域内数据点存在的可能性很小,因此可以认为落在此区域内的数据点都是异常点。由于监控时序数据是连续型结构化数据,异常发生的概率很低,且异常点的特征值与正常点的特征值差异很大,所以适合用Isolation Forest 算法进行异常检测。隔离森林属于无监督异常检测算法。
算法流程
隔离森林是由多棵树组成的,其基本思想是
- 随机选取一个特征,并从样本中随机选取一个值,建立树,对于随机选取的一个值P,当前节点的左分支存放小于p所选维度的数据点,当前节点的右分支存放大于或等于p所选维度的数据点;
- 递归的不断构造树,直到所有样本都在树中,或者树的高度达到了指定值。对于那些异常的点可以认为其很早的就会被分到叶子节点,故计算每个节点到根节点的距离,计算路径长度。
- 建立多棵隔离树,计算每个特征值的平均路径长度。根据孤立森林的异常分数计算公式,计算每个样本数据其中n为样本数,二叉搜索树的平均路径长度。计算公式如下
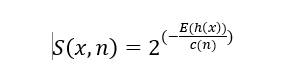
sklearn isolation forest实现
- 导入sklearn的包
from sklearn.ensemble import IsolationForest
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









