







DiffusionAD: Norm-guided One-step Denoising Diffusion for Anomaly Detection
1、Background
现代异常检测方法包括两个主要范式:基于特征嵌入的方法和基于生成模型的方法。
基于特征嵌入的方法通常依赖于在额外数据集(如ImageNet)上预训练的特征提取器来提取正常样本的特征,然后执行异常估计。
基于生成模型的方法不需要额外的数据,并且可以广泛应用于各种场景。这些方法通常使用基于自编码器的网络(AEs),其假设是编码器将输入图像压缩成低维表示后,解码器将异常区域重建为正常。
然而,基于AE的范式有其局限性:
- 它可能导致异常区域的不变重建,因为从原始图像压缩得到的低维表示仍包含异常信息,导致假阴性检测。
- AEs可能由于有限的恢复能力而对正常区域进行粗略重建,并引入许多假阳性,特别是在具有复杂结构或纹理的数据集上。
为了解决上述问题,提出了一个新颖的基于生成模型的框架,包括用于异常检测的重建子网络和分割子网络,名为DiffusionAD。首先,通过引入高斯噪声来扰动输入图像,然后通过去噪模型来预测添加的噪声,将重建过程重新定义为噪声到规范的范式。通过扩散模型来实现噪声添加和去噪,因为其出色的密度估计能力和高采样质量。
所提出的范式有两个优势:
- 异常区域在失去其可区分特征后被视为噪声,这使得异常区域无异常的重建成为可能,而不是不变的重建。
- 它旨在覆盖正常外观的整个分布,从而实现细粒度重建,而不是粗略重建。之后,分割子网络通过利用输入图像及其重建之间的不一致性和共同性来预测像素级异常分数。配备噪声到规范范式后,DiffusionAD能够重建更令人满意的结果,从而提高异常检测的性能。
然而,作为一类基于似然的模型,扩散模型通常需要大量的去噪迭代(通常约为50到1000步)才能从随机采样的高斯噪声中获得最优重建,这比实际AD场景中的实时要求要慢得多。
为了解决这个问题,引入了一种用于异常检测的单步去噪范式,该范式使用扩散模型一次预测噪声,然后直接预测重建结果。这种范式实现了比传统迭代去噪范式快数百倍的推理速度,同时保持相当的恢复质量。
尽管如此,异常检测一直是一个非平凡的挑战,主要原因是异常表现的内在多样性。这些变体包括微妙的异常以及更明显的异常,后者的特点是更大的异常区域或语义变化。不同类型的异常需要不同的噪声尺度才能有效恢复,特别是在单步去噪范式中。
具体来说,当异常相对较小时,从小噪声尺度进行的单步预测更有利,从而获得更优质的像素级恢复质量。对于更明显的异常,策略性地应用较大的噪声尺度来扰动它们,然后进行单步重建,可以增强语义级恢复质量。
因此,进一步引入了规范引导范式,利用来自较大噪声尺度的直接预测来指导较小噪声尺度的重建,从而获得更优质的重建结果。
supplement
扩散模型(Diffusion Model)是一种生成模型,它 通过逐步添加高斯噪声到数据中来模拟数据的生成过程,然后通过逆向过程从噪声中恢复出原始数据 。这个过程通常需要多次迭代去噪步骤来逐渐从噪声数据中恢复出清晰的图像。
- 单步去噪范式(One-step Denoising Paradigm) 是指在扩散模型中,不是通过多次迭代逐渐去除噪声,而是直接在一步中预测出从噪声数据到无噪声数据的映射。具体来说,就是在某个时间步,扩散模型通过一次推断直接预测出噪声,然后使用这个预测的噪声来直接恢复出无异常的重建。这种方法的速度比迭代去噪快得多,因为它避免了多次迭代计算的需要。
- 迭代去噪方法(Iterative Denoising Method) 则是扩散模型中传统的去噪方式,它需要通过多次迭代逐步去除噪声。在每次迭代中,模型都会预测当前噪声水平下的噪声成分,然后根据这个预测来更新数据,使其更接近原始无噪声的状态。这个过程通常需要数十到数千次迭代,直到数据完全恢复。
单步去噪范式与迭代去噪方法的主要区别在于:
- 速度:单步去噪范式的速度远远快于迭代去噪方法,因为它只需要一次网络推断就能完成去噪过程。
- 计算资源:由于单步去噪范式减少了迭代次数,因此它需要的计算资源也更少。
- 重建质量:尽管单步去噪范式速度快,但在某些情况下,它可能无法达到迭代去噪方法的重建质量,因为迭代方法可以通过多次精细调整来更准确地恢复数据。
- 适用场景:单步去噪范式适用于对速度要求高、对重建质量要求不是极高的实时或近实时应用场景。
规范引导范式(Norm-guided Paradigm),它结合了不同噪声水平下的单步重建的优势,以处理不同类型的异常,并预测出更优质的重建结果。该方法的核心思想是利用从较大噪声尺度预测得到的无异常图像来引导较小噪声尺度的重建过程,从而在保持快速推理速度的同时提高重建的质量。
2、Method
DiffusionAD由两个主要部分组成:重建子网络和分割子网络。重建子网络使用扩散模型将输入图像转换为噪声图像,然后预测噪声以重建无异常的图像。分割子网络接收输入图像和重建图像,预测像素级的异常分数。

- 重建子网络(Reconstruction Sub-network):
- 通过扩散模型实现,将重建过程重新定义为从噪声到规范的范式。
- 首先,输入图像被逐渐添加高斯噪声,直到变成噪声图像。
- 然后,使用U-Net架构的网络预测噪声,并使用预测的噪声重建图像。
- 分割子网络(Segmentation Sub-network):
- 使用U-Net架构,包括编码器、解码器和跳跃连接。
- 输入是输入图像和重建图像的通道级连接。
- 通过比较输入图像和重建图像之间的不一致性和共同性来预测像素级的异常分数。
- 规范引导单步去噪(Norm-guided One-step Denoising):
- 为了提高实时推理的速度,提出了单步去噪方法,通过一次网络推断直接预测噪声并重建图像。
- 引入规范引导范式,结合不同噪声尺度的优势,以处理不同类型的异常并提高重建质量。
- 训练与推理(Training & Inference):
- 训练阶段:联合训练去噪和分割子网络,使用特定的损失函数来优化模型。
- 推理阶段:使用固定的时间步进行单步规范引导估计,速度快且保持了相当的采样质量。
- 异常合成策略(Anomaly Synthetic Strategy):
- 由于训练时没有异常样本的先验信息,通过在线合成伪异常样本来进行端到端训练。
- 通过向正常样本添加视觉上不一致的区域来合成异常样本。
pseudo-code
import numpy as np
# 假设我们有一个输入图像 x_0
x_0 = ...
# 定义扩散模型
class DiffusionModel:
def __init__(self):
# 初始化模型参数
pass
def add_noise(self, image, t):
# 在图像中添加高斯噪声
noise = np.random.normal(0, 1, image.shape)
return image + noise * (t / T) ** 0.5
def predict_noise(self, noisy_image, t):
# 预测噪声图像中的噪声
# 这里使用一个简化的U-Net结构来预测噪声
return noisy_image * (1 - (t / T)) ** 0.5
def reconstruct(self, noisy_image, t):
# 重建无噪声图像
predicted_noise = self.predict_noise(noisy_image, t)
return noisy_image - predicted_noise
# 定义分割网络
class SegmentationNetwork:
def __init__(self):
# 初始化模型参数
pass
def predict_anomaly_score(self, original_image, reconstructed_image):
# 预测像素级的异常分数
# 这里使用一个简化的U-Net结构来预测异常分数
return np.abs(original_image - reconstructed_image)
# 初始化模型
diffusion_model = DiffusionModel()
segmentation_network = SegmentationNetwork()
# 设置迭代次数和时间步
T = 1000
t_s, t_b = 200, 800 # 小噪声尺度和大噪声尺度的时间步
# 第1步:噪声注入
noisy_image_s = diffusion_model.add_noise(x_0, t_s)
noisy_image_b = diffusion_model.add_noise(x_0, t_b)
# 第2步:噪声预测和重建
predicted_noise_s = diffusion_model.predict_noise(noisy_image_s, t_s)
predicted_noise_b = diffusion_model.predict_noise(noisy_image_b, t_b)
reconstructed_image_s = diffusion_model.reconstruct(noisy_image_s, t_s)
reconstructed_image_b = diffusion_model.reconstruct(noisy_image_b, t_b)
# 第3步:规范引导单步去噪
# 这里简化了规范引导的过程,直接使用大噪声尺度的重建结果
guided_reconstruction = reconstructed_image_b
# 第4步:异常分数预测
anomaly_scores = segmentation_network.predict_anomaly_score(x_0, guided_reconstruction)
# 输出异常分数
print(anomaly_scores)
3、Experiments
🐂🐎。。。
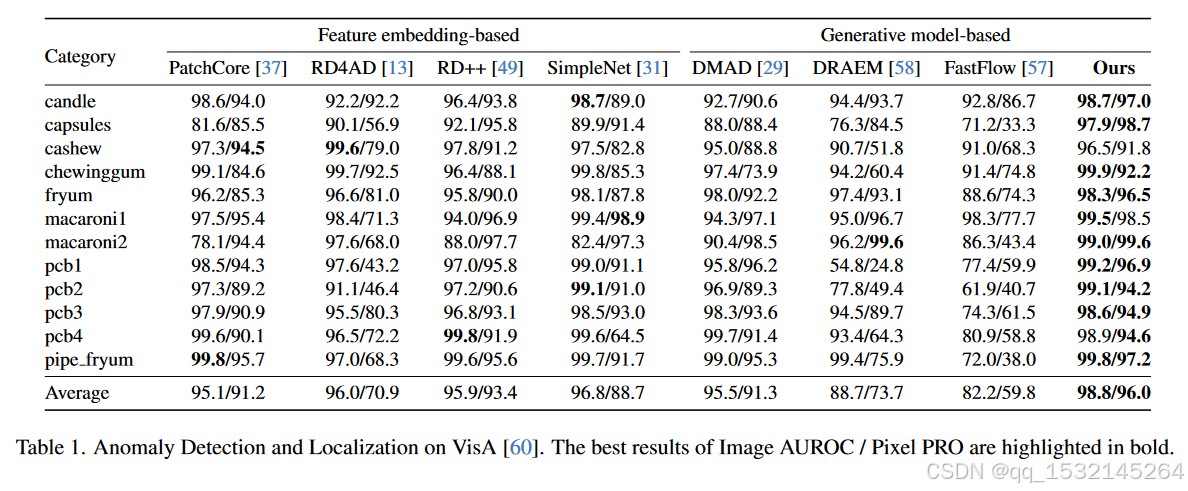
4、Conclusion
- 提出了DiffusionAD,这是一个通过噪声到规范范式重建输入图像为无异常恢复的新颖流程,并通过利用它们之间的不一致性和共同性进一步预测像素级异常分数。
- 提出了一种单步去噪范式,显著加快了去噪过程。
- 提出了规范引导范式,以实现更优质的重建结果。

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









