







一、从函数到神经网络
所有一切的前提是,你要相信这个世界上的所有逻辑和知识,都可以用一个函数来表示。Functions describe the world !

比如输入物体的质量和加速度,根据牛顿第二定律,就可以得到物体施加的力,这就是人工智能早期的思路:符号主义。
但这条路走到头了,很多问题人类实在是想不出怎么写成一个明确的函数。比如说一个简简单单的识别,一张图片是否是猫对人类来说可能简单到爆炸,但是要让计算机运行一段程序来识别,一下子就变成了一个史诗级难题,就连有着明确语法规则和词典的翻译函数尚且没有办法做到足够丝滑,更别说复杂多变的人类智能了。

既然不知道这个函数长什么样,怎么办呢?换个思路:
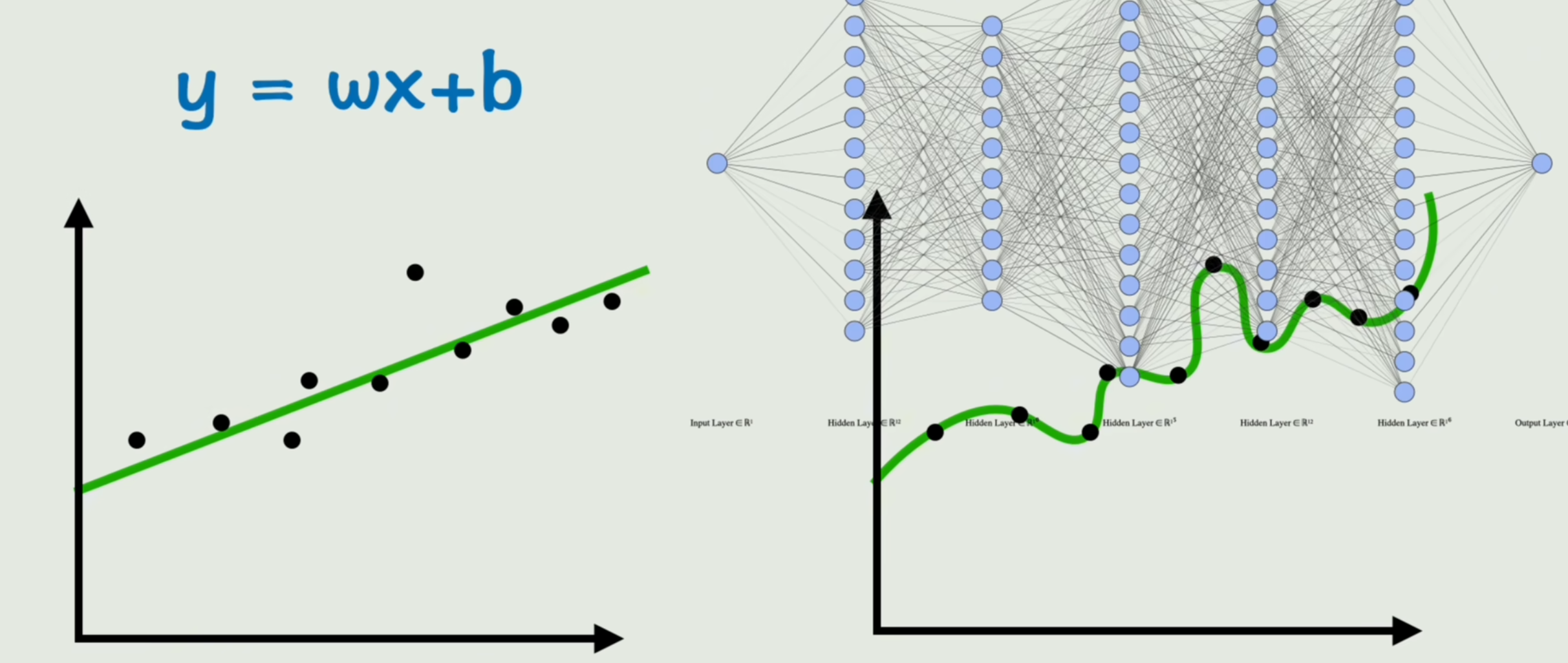
假如我们一开始没有找到这个规律,我们先把这个x、y放到坐标轴上,先随便猜一下。比如说函数关系就是y等于x,也就是这里的w和b分别是一和零,然后我们一点点调整这个w和b,使得这条直线越来越贴近真实数据。

刚刚我们举的例子比较简单,只用直线方程就可以表示了。但假如数据稍稍变化一下,就会发现,不论怎么调整都无法接近真实的数据,这个时候就需要从原来的线性函数进化到非线性函数了,我们就来研究一下,怎么把原来这个原本线性的函数变成非线性的呢?
很简单,在这个函数最外层再套一个非线性的运算就可以了。比如平方、比如sin(wx+b)、比如e^wx+b,这就是激活函数。
它的目的就是把原本死气沉沉的线性关系给盘活了,变成了变化能力更强的非线性关系。

回到这个新的函数形式,我们之前仅仅有一个输入的变量就是x,但实际上可能有很多输入。所以这里的每一个x都要对应一个w,像这样:

再者,有的时候只套一层激活函数,还是没有办法达到很好的效果。也就是说这个曲线弯的还不够灵活,这要怎么办?
我们在此基础之上再进行一次线性变换,然后再套上一个激活函数,这样就可以无限的套娃下去了。通过这样的方式,我们就可以构造出非常非常复杂的线性关系,而且理论上可以逼近任意的连续函数。当然了,这样写下去实在是太让人头大了,普通人看个两层,估计脑子就炸了,所以我们得换一种更傻瓜的、更直观的形式,我们把这样一个线性变换套一个激活函数 画成下面这样:

左边是输入层,只有输入x,右边是输出层,只有一个输出y。我们把这里的每一个小圈圈叫做一个神经元。
每套一层就相当于神经元水平方向又扩展了一个。当然扩展之后,中间这一层就不再是最终的输出了,而是包裹在了一个很复杂的函数变换之中看不到,我们管它叫做隐藏层,而整个神经元互相连接形成的网络结构,就叫做神经网络。
好,接下来我们看一下函数和神经网络的对应关系。首先有两个输入变量,一个是x1,另一个是x2,它们构成了输入层,然后x1、x2二进行一次线性变换,再进行一次激活函数就得到了隐藏层a,这个a对应的就是上面这一大坨表达式,我们把它当做一个整体,继续进行一次线性变换和一次激活函数,这就计算出了最终的输出层y。从神经网络的这个图来看的话,似乎就像是一个信号,从左到右传播了过去,这个过程就叫做神经网络的前向传播。实际上就是一点点分步骤,把一个函数的值计算出来了而已。

神经网络的每一层神经元都可以无限增加。同时,隐藏层的层数也可以无限增加,进而就可以构成一个非常非常复杂的非线性函数了。虽然这个函数可能非常复杂,但是我们的目标却非常简单和明确,就是根据已知的一组x和y的值,猜出所有w和b各是多少。

神经网络训练过程示例:
举个最简单的2维例子,即2个隐藏层神经元。将词放入神经网络输入层,神经通道上用权重w和偏置b进行线性变换,激活函数用最简单的f(x)=x。

然后同样经过线性变换+激活函数到达输出层,想要预测下一个词的概率 ,输出前直接通过一个softmax激活函数将4个输出转化为0-1之前的概率,且总和为1,最大概率就是我们的结果。

二、如何计算神经网络参数
上面解释了神经网络的本质,其实就是线性变换,套上一个非线性激活函数,不断组合,对应就是一个非常复杂的非线性函数,计算出这里的w和b。
先从最简单的线性函数入手, 每个点上的数据是真实数据,落在直线上的点表示预测数据,那么这条线段的长度就是真实值与预测值的误差。

为了评估整体的拟合效果,我们可以将所有这些线段的长度相加,得到真实数据与预测数据的总误差,这个函数就叫所示函数。

然而,这个绝对值在数学优化时不太友好,那么改造下用平方来代替,既解决了绝对值不平滑的问题,也放大了误差较大的值的影响。然后我们再根据样本的数量平均一下,消除样本数量大小的影响,最终得到的公式即均方误差。

前面我们为了找到一组w和b来拟合真是数据,定义了损失函数。下面要做的就是制定让损失函数最小这个目标来计算w和b的值。

求解的方法,要用到的就是初中学过的知识,让其导数等于0,求极值点的过程。
举个简单的例子,线性模型只保留一个w:

代入损失函数:

化简后就是一个简单的关于w的二次函数,接下来对w求导,让其导数等于0,就可以求出w=1。


刚刚的步骤其实就在寻找这条抛物线的最低点。如果再加上b,损失函数图像就是1个三维图像。而多元函数求最小值的问题就不再是导数了,而是要让每个参数的偏导数等于0来求解。

在三维图像中,就是对应w和b两个切面上的二维函数来求导。这里不再展开。
通过寻找一个线性函数来拟合x和y的关系,就是机器学习中的最基本分析方法–线性回归。

具体的,每次调整一点w或b数值,使得损失函数会变化多少,这其实就是损失函数对w或b的偏导数。

我们要做的就是不断往偏导数的反方向去变化,具体变化的快慢,用一个系数来控制,叫做学习率,这些偏导数构成的向量叫做梯度。调整w或b数值,让损失函数逐渐减小,最终得到w和b值的过程,就叫做梯度下降。

那么现在关键就在于这个偏导数怎么求。之前的线性回归问题中,偏导数就是一个一元二次函数求导,非常简单。但是在神经网络中,层数较多,函数本身就是一个及其复杂的非线性函数,更别说损失函数了,直接求偏导数非常困难。

虽然神经网络整体代表的函数很复杂,但是层与层之间的关系还是很简单的,现在关键问题就是求出l对它们的偏导数。我们可以逐层求导,比如w1变化一个单位,看a变化多少,再看a变化一个单位,y变化多少,再看y变化一个单位,l变化多少,每一个都是一个简单的偏导数,那把三者乘起来,就可以得到w变化一个单位,会使l变化多少了。
这种偏导数的计算方式,就是链式法则。其实就是微积分中的复合函数求导。

由于我们可以通过链式法则从右往左依次求导,逐步更新每一层的参数,直到把所有神经网络的参数都更新一遍,在计算前一层时,用到的一些偏导数的值,后面也会用到,并不用全部计算,而是让这些值从右往左一点点传播过来就好了,这个过程就叫做 反向传播。
总结前面的知识,我们通过前向传播,根据输入x计算输出y,然后再通过反向传播,计算出损失函数关于每个参数的梯度,每个参数都向着梯度的反方向变化一点点。不断地前向传播、反向传播,这就构成了神经网络的训练过程。

三、如何调优神经网络参数
现在我们知道,神经网络的本质就是线性变换套上一个激活函数不断组合而成的一个非常复杂的非线性函数,并且巧妙的通过梯度下降。一点点计算出神经网络中的一组合适的参数。这样看起来只要神经网络足够大,是不是什么问题都能解决?
看下面一组图,你认为是左边好还是右边好?纯从预测值与真实值误差来看,也就是损失值最小化。这个目标来看的话,显然右边这个更好,但直觉似乎告诉我们,右边这个好像有点好的太过了。结果可能是只适合训练数据,对新数据的预测,反而不如左边的准。
这种在训练数据上表现的很完美,但是在没见过的数据上表现的很糟糕的现象,就叫做过拟合。而在没见过的数据上的表现能力,我们叫它泛化能力。为什么会过拟合呢?看看刚刚这个图其实就是训练数据本身是个很简单的规律,但模型太复杂了,把那些噪声和随机波动也给学会了。
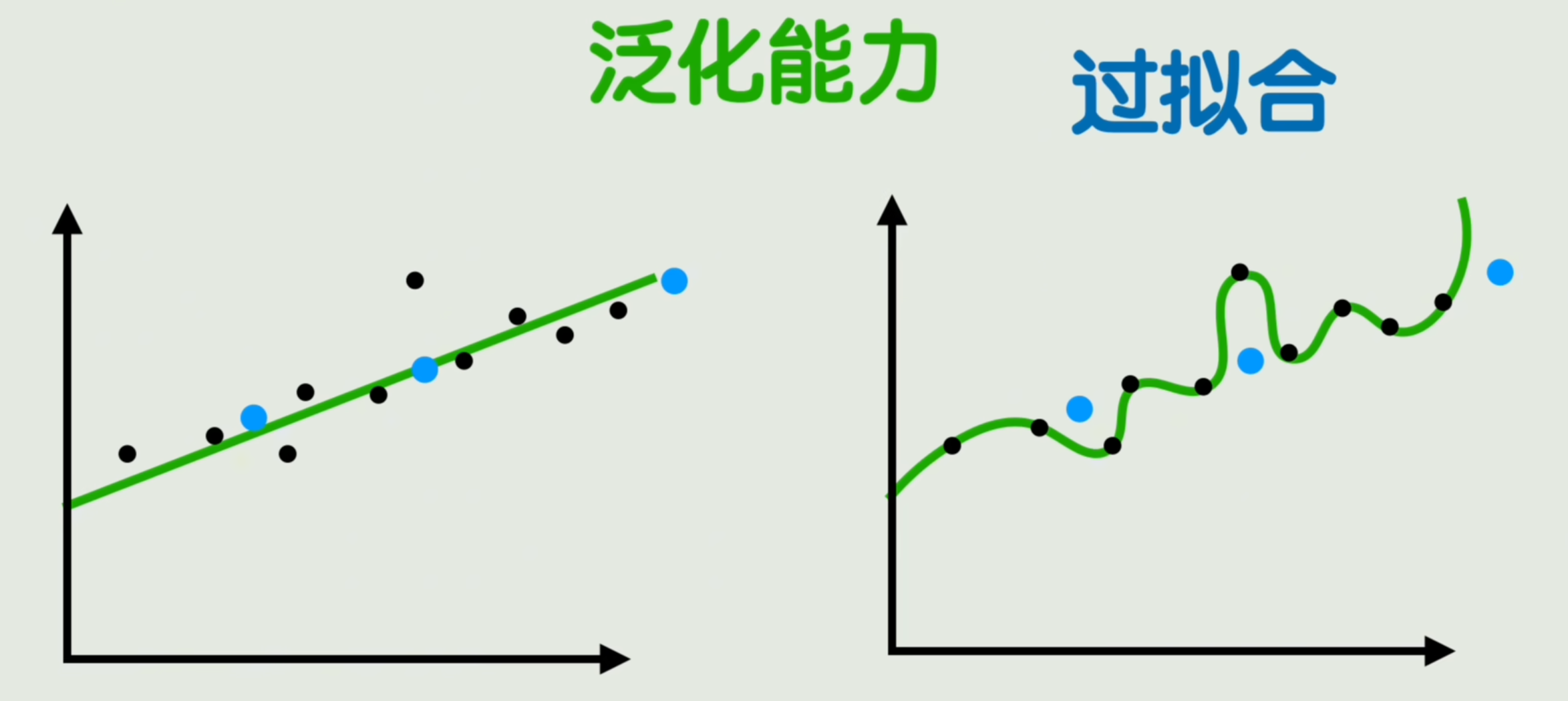
因此这个案例中,用一个非常复杂的神经网络模型来训练效果,甚至不如一个线性模型,这就告诉我们神经网络不是越大越好。简化模型复杂度有效果,与之相对的就是增加训练数据的量,数据量足够充足,原本复杂的模型也就相对变得简单了。但有的时候我们确实无法收集或者懒得收集更多的数据怎么办呢?那就在原有的数据中创造更多的数据,比如说在图像处理中,我们可以对图像进行。旋转、翻转、裁剪夹、噪声等操作,创造出更多新的训练样本,这就叫做数据增强。这样不仅仅能够产生更多的数据,还刚好训练了一个让模型不因输入的一点点小的变化,而对结果产生很大的波动,这就是增强了模型的鲁棒性。
刚刚是从数据和模型本身入手来防止过拟合,有没有可能从训练过程入手阻止过拟合的发生?其实训练过程就是不断调整各种参数的过程,只要不让参数继续过分的向着过拟合的方向发展就可以了。
回想一下参数的训练过程:通过让参数往让损失函数变小的方向不断调整,也就是梯度下降。我们可以在损失函数中把参数本身的值加上去,这样在参数往大的调整时,如果让损失函数减小的没有那么多,导致新的损失函数反而是变大的。那么此时调整就是不合适的,因此一定程度上就抑制了参数的野蛮增长。
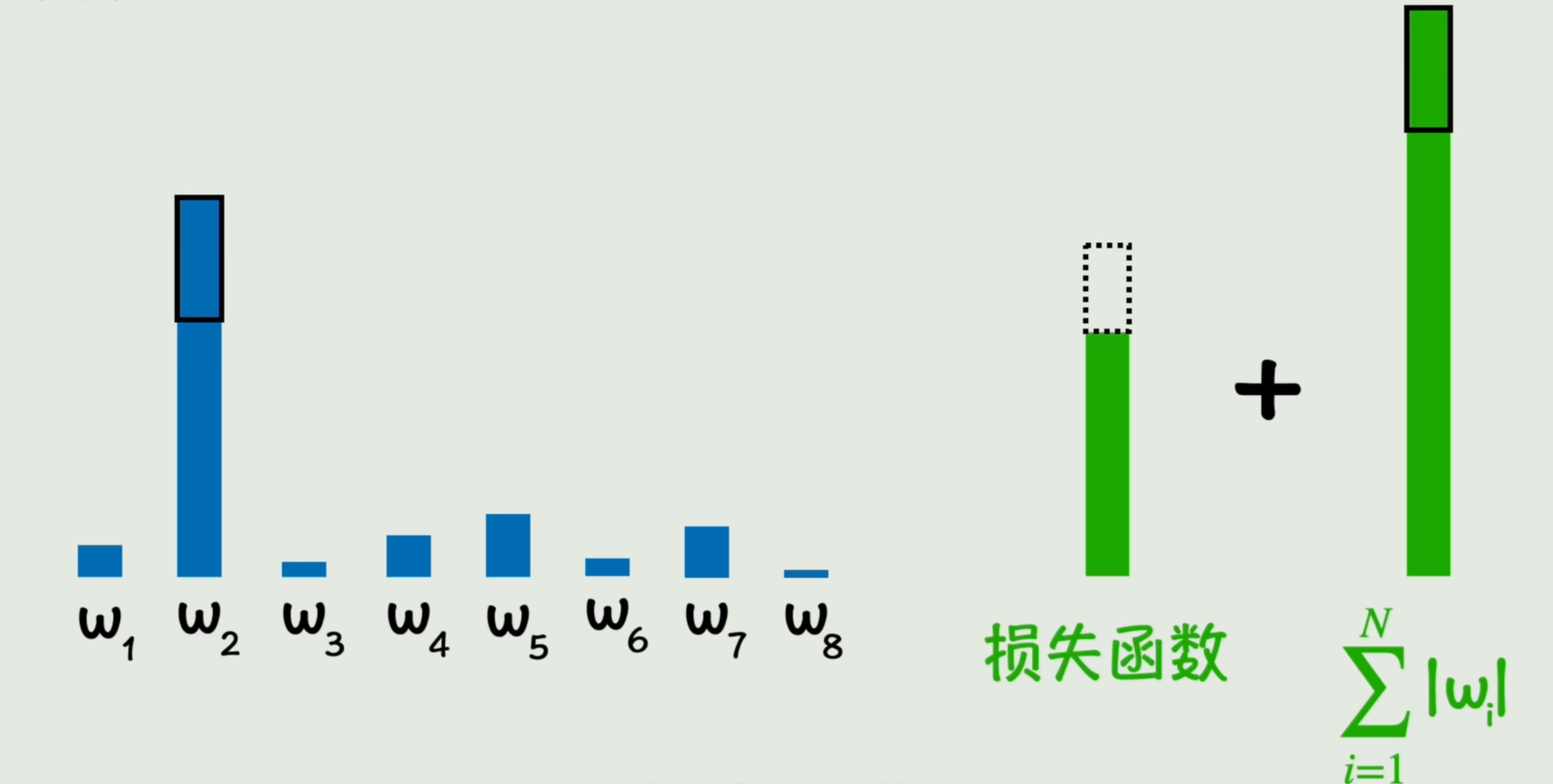
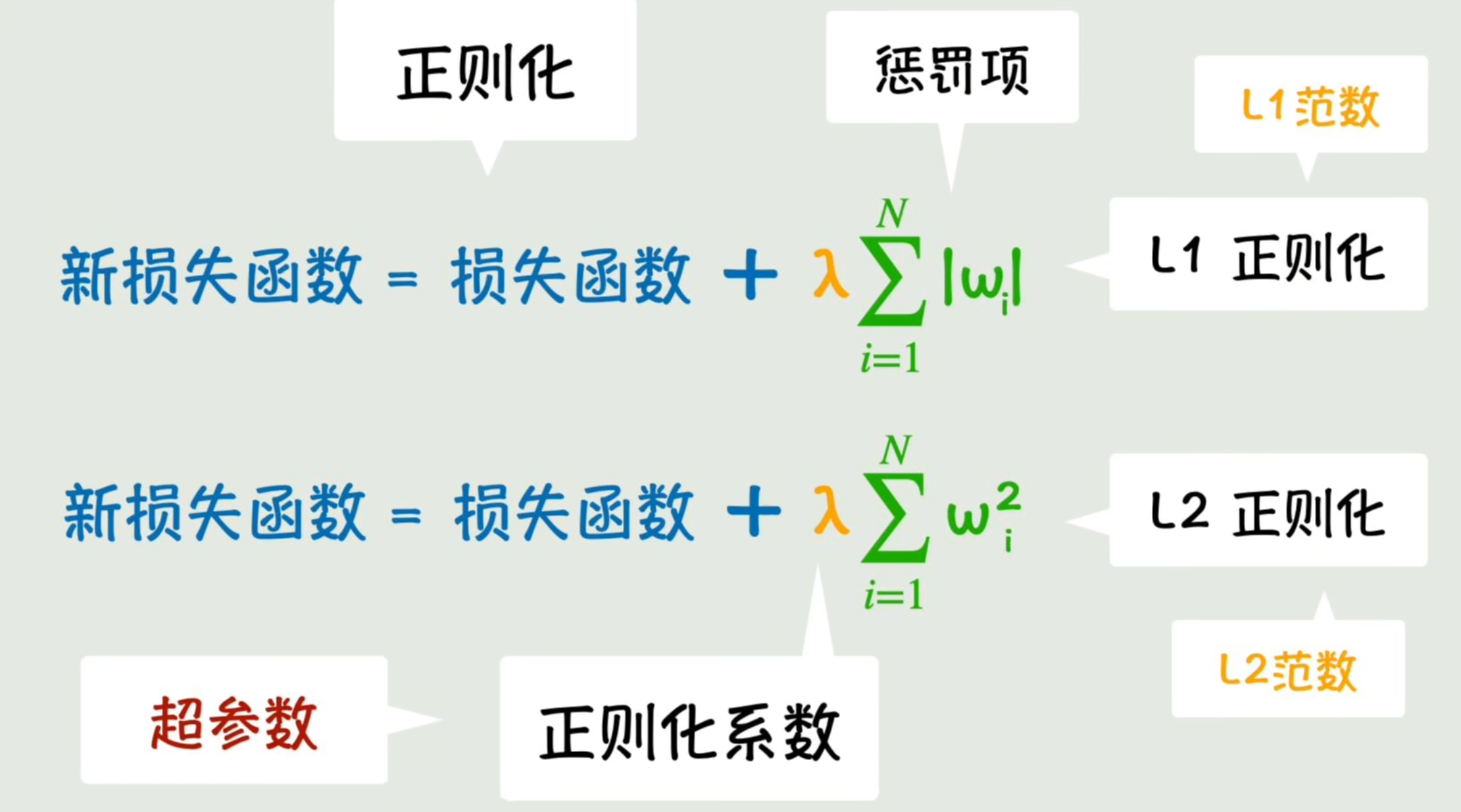
除了可以用参数的绝对值之和之外,我们还可以用参数的平方和。这样参数大的时候,抑制的效果就更强了。我们把这一项叫做惩罚项,把通过这种损失函数中添加权重惩罚项,抑制其野蛮增长的方法叫做正则化。
上面这个参数绝对值相加的叫L1正则化,这个平方项相加的叫L2正则化(因为绝对值之和叫做L1范数,而平方和的平方根叫做L2范数,这是向量空间中范数的概念),然后和之前梯度下降时增加学习率控制下降粒度一样,我们也增加一个参数来控制惩罚项的力度,我们叫它正则化系数。而这些控制参数的参数,我们以后统称为超参数。总之这个公式就只是为了抑制参数的野蛮增长。
除了这种方式外,还有一种令人简单到发指,但是就是效果显著的办法。,那就是可以在训练过程中每次都随机丢弃一部分参数,这样模型就避免了在某些关键参数上过渡依赖的风险。虽然听起来有点玄学,但确实十分有效,这种方法叫dropout,其翻译过来就是丢弃,而且这个方法是大名鼎鼎的深度学习之父星盾提出来的。

好了,上面我们了解了,在对抗过拟合这条路上,我们搅尽脑汁想了各种办法,包括增加数据量、减少模型复杂度、提前终止训练、L1正则化、L2正则化、dropout等等。除此之外,模型还会遇到其他问题,比如:
- 梯度消失,也就是网络越深,梯度反向传播时会越来越小,导致参数更新困难。
- 梯度爆炸。梯度数值越来越大,参数的调整幅度失去了控制
- 收敛速度过慢,比如可能陷入局部最优,或者来回震荡
- 计算开销过大,每次完整的前向传播和反向传播都非常耗时。

每个问题人们都想了各种办法来解决,比如:
- 用梯度裁剪来防止梯度的更新过大
- 用合理的网络结构,比如残差网络来防止深层网络的梯度衰减
- 用合理的权重初始化,和将输入数据归一化,让梯度分布更平滑
- 用动量法、RMSProp、 Adam等自适应优化器来加速收敛,减少震荡
- 用mini batch,把巨量的训练数据分割成几个小批次来降低单次的计算开销。
这里的每个概念展开都是一个全新的世界,鉴于我们这个系列是抓大放小解决主要思想的特点,这里就不一一展开了,但它们和我们今天着重讲的内容一样,都是为了让训练过程更好罢了。
参考:https://space.bilibili.com/325864133



















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











