






llama - batched-bench
1、下载编译llamap.cpp
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# rm -rf build; cmake -S . -B build -DLLAMA_CUBLAS=ON && cmake --build build --config Release
2、在如下地址下载模型
https://hf-mirror.com/TinyLlama/TinyLlama-1.1B-Chat-v0.2-GGUF/tree/main
3、运行测试
usage: ./batched-bench MODEL_PATH [N_KV_MAX] [IS_PP_SHARED] [NGL] <PP> <TG> <PL>
<PP>, <TG> and PL are comma-separated lists of numbers without spaces
example: ./batched-bench ggml-model-f16.gguf 2048 0 999 128,256,512 128,256 1,2,4,8,16,32
例子:./batched-bench ./models/llama-7b/ggml-model-q4_0.gguf 2048 0 99
main: n_kv_max = 2048, is_pp_shared = 0, n_gpu_layers = 99, n_threads = 4, n_threads_batch = 4
| PP | TG | B | N_KV | T_PP s | S_PP t/s | T_TG s | S_TG t/s | T s | S t/s |
|-------|--------|------|--------|----------|----------|----------|----------|----------|----------|
| 128 | 128 | 1 | 256 | 0.056 | 2306.14 | 1.022 | 125.20 | 1.078 | 237.51 |
| 128 | 128 | 2 | 512 | 0.060 | 4232.94 | 1.018 | 251.49 | 1.078 | 474.77 |
| 128 | 128 | 4 | 1024 | 0.106 | 4838.77 | 1.211 | 422.71 | 1.317 | 777.49 |
| 128 | 128 | 8 | 2048 | 0.248 | 4135.55 | 1.977 | 517.87 | 2.225 | 920.47 |
| 128 | 256 | 1 | 384 | 0.043 | 2990.44 | 2.024 | 126.47 | 2.067 | 185.77 |
| 128 | 256 | 2 | 768 | 0.058 | 4380.94 | 2.010 | 254.69 | 2.069 | 371.24 |
| 128 | 256 | 4 | 1536 | 0.107 | 4790.19 | 2.517 | 406.85 | 2.624 | 585.42 |
| 256 | 128 | 1 | 384 | 0.060 | 4250.87 | 1.008 | 127.00 | 1.068 | 359.50 |
| 256 | 128 | 2 | 768 | 0.107 | 4806.20 | 1.005 | 254.61 | 1.112 | 690.64 |
| 256 | 128 | 4 | 1536 | 0.247 | 4149.39 | 1.320 | 387.95 | 1.567 | 980.50 |
| 256 | 256 | 1 | 512 | 0.060 | 4248.96 | 2.013 | 127.18 | 2.073 | 246.97 |
| 256 | 256 | 2 | 1024 | 0.108 | 4761.68 | 2.009 | 254.85 | 2.117 | 483.81 |
| 256 | 256 | 4 | 2048 | 0.250 | 4092.33 | 2.751 | 372.21 | 3.001 | 682.36 |
| 512 | 128 | 1 | 640 | 0.112 | 4574.08 | 1.008 | 127.01 | 1.120 | 571.55 |
| 512 | 128 | 2 | 1280 | 0.247 | 4142.86 | 1.032 | 248.11 | 1.279 | 1000.80 |
| 512 | 256 | 1 | 768 | 0.111 | 4622.02 | 2.016 | 127.00 | 2.127 | 361.15 |
| 512 | 256 | 2 | 1536 | 0.248 | 4134.78 | 2.096 | 244.30 | 2.343 | 655.44 |
| 1024 | 128 | 1 | 1152 | 0.254 | 4029.31 | 1.006 | 127.20 | 1.260 | 914.00 |
| 1024 | 256 | 1 | 1280 | 0.253 | 4041.34 | 2.008 | 127.48 | 2.262 | 565.97 |
llama_print_timings: load time = 693.46 ms
llama_print_timings: sample time = 0.00 ms / 1 runs ( 0.00 ms per token, inf tokens per second)
llama_print_timings: prompt eval time = 21770.83 ms / 17936 tokens ( 1.21 ms per token, 823.85 tokens per second)
llama_print_timings: eval time = 12101.92 ms / 1536 runs ( 7.88 ms per token, 126.92 tokens per second)
llama_print_timings: total time = 34486.78 ms / 19472 tokens
结果数据说明:
- `PP` - prompt tokens per batch
- `TG` - generated tokens per batch
- `B` - number of batches
- `N_KV` - required KV cache size
- `T_PP` - prompt processing time (i.e. time to first token)
- `S_PP` - prompt processing speed (`(B*PP)/T_PP` or `PP/T_PP`)
- `T_TG` - time to generate all batches
- `S_TG` - text generation speed (`(B*TG)/T_TG`)
- `T` - total time
- `S` - total speed (i.e. all tokens / total time)
问题记录
推理正常运行,但是没有offload到GPU
1、查看日志显示找不到GPU设备

2、查看GPU设备正常
(base) root@node06[/root]# nvidia-smi
Tue Mar 19 09:27:34 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:04:00.0 Off | 0 |
| N/A 30C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
3、分析代码文件,

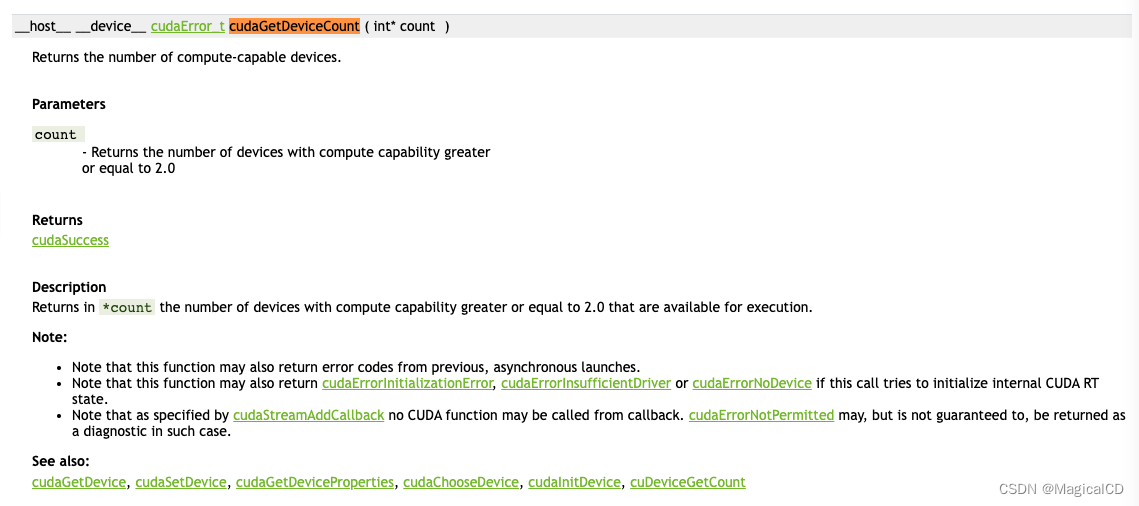
4、报错是cuda和驱动版本不匹配
(base) root@node06[/root]# /usr/local/cuda-12.0/extras/demo_suite/deviceQuery
/usr/local/cuda-12.0/extras/demo_suite/deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
cudaGetDeviceCount returned 35
-> CUDA driver version is insufficient for CUDA runtime version
Result = FAIL
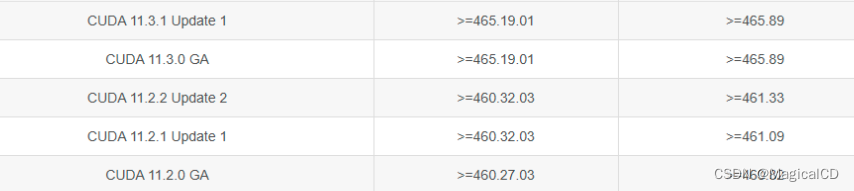
官网查询对应关系
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
5、安装旧版本cuda 重新编译运行
wget https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo
yum -y install cuda-toolkit-11-2
(base) root@node06[/usr/local/cuda-11.2/samples/1_Utilities/deviceQuery]# ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla T4"
CUDA Driver Version / Runtime Version 11.2 / 11.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 15110 MBytes (15843721216 bytes)
(40) Multiprocessors, ( 64) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 5001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 65536 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 4 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.2, CUDA Runtime Version = 11.2, NumDevs = 1
Result = PASS
llama.cpp编译问题
低cuda版本编译报错:
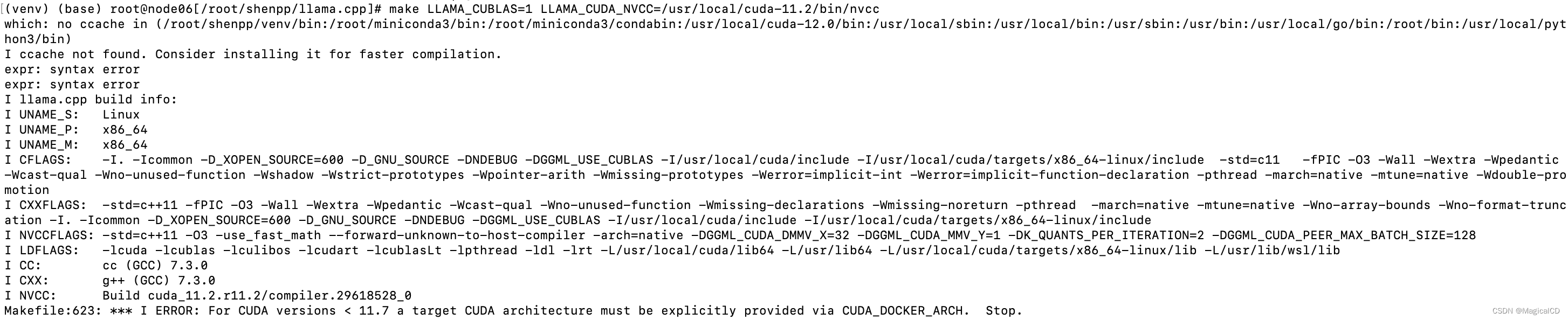
添加 CUDA_DOCKER_ARCH参数,尝试改为=all,无法解决

其他参数值自行对应cuda尝试,如:compute_75(实测成功)
‘all’,‘all-major’,‘compute_35’,‘compute_37’, ‘compute_50’,‘compute_52’,‘compute_53’,‘compute_60’,‘compute_61’,‘compute_62’, ‘compute_70’,‘compute_72’,‘compute_75’,‘compute_80’,‘compute_86’,‘compute_87’, ‘lto_35’,‘lto_37’,‘lto_50’,‘lto_52’,‘lto_53’,‘lto_60’,‘lto_61’,‘lto_62’, ‘lto_70’,‘lto_72’,‘lto_75’,‘lto_80’,‘lto_86’,‘lto_87’,‘sm_35’,‘sm_37’,‘sm_50’, ‘sm_52’,‘sm_53’,‘sm_60’,‘sm_61’,‘sm_62’,‘sm_70’,‘sm_72’,‘sm_75’,‘sm_80’, ‘sm_86’,‘sm_87’.
最佳解决方案是部署高版本的驱动,驱动向前兼容,高版本驱动可以使用低版本的cuda

















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









