






这本关于 Llama.cpp 的全面指南将带你一步步探索设置开发环境、了解其核心功能以及利用其功能解决现实世界问题的必要知识。
2023年11月
原文 :Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and Implementation | DataCamp
译文:
大型语言模型(LLM)正在彻底改变各个行业。从客户服务聊天机器人到复杂的数据分析工具,这项强大技术的潜力正在重塑数字互动和自动化的格局。
然而,LLM 的实际应用可能会受到对高性能计算的需求或对快速响应时间的需求的限制。这些模型通常需要复杂的硬件和广泛的依赖项,这使得它们难以在更受限制的环境中采用。
这就是 LLaMa.cpp(或 LLaMa C++)发挥作用的地方,它提供了一个更轻量级、更便携的替代方案,可以替代那些重量级的框架。

Llama.cpp logo (source)
Llama.cpp 是什么?
LLaMa.cpp 是由 Georgi Gerganov 开发的。它用高效的 C/C++ 实现了 Meta 的 LLaMa 架构,并且是 LLM 推理领域最活跃的开源社区之一,拥有 390 多位贡献者,官方 GitHub 仓库拥有 43000 多颗星,以及 930 多个版本。
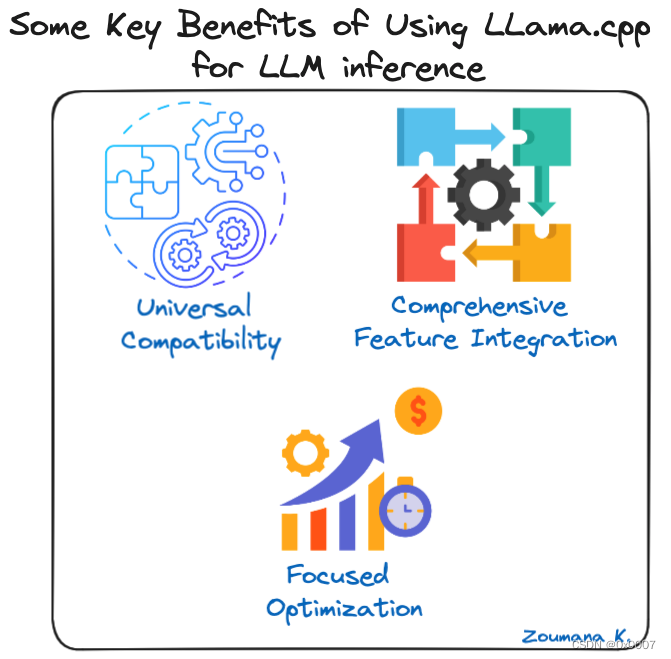
使用 LLaMa.cpp 进行 LLM 推理的一些主要优势
- 通用兼容性:Llama.cpp 作为一款以 CPU 为首的 C++ 库,设计简洁,可无缝集成到其他编程环境中。这种广泛的兼容性加速了其在各种平台上的应用。
- 全面功能集成:作为关键底层功能的集合,Llama.cpp 模仿了 LangChain 的高级功能方法,简化了开发流程,尽管可能会面临未来可扩展性的挑战。
- 重点优化:Llama.cpp 专注于单一模型架构,从而实现精确有效的改进。它通过 GGML 和 GGUF 等格式对 Llama 模型的承诺,已经取得了显著的效率提升。
了解了 Llama.cpp 后,本教程的接下来的部分将逐步介绍实现文本生成用例的过程。我们首先探讨 LLaMa.cpp 的基础知识,了解当前项目的整体端到端工作流程,并分析它在不同行业的一些应用。
Llama.cpp 架构
Llama.cpp 的核心是原始的 Llama 模型,该模型也基于 Transformer 架构。Llama 的作者利用了后来提出的各种改进,并使用了不同的模型,例如 PaLM。
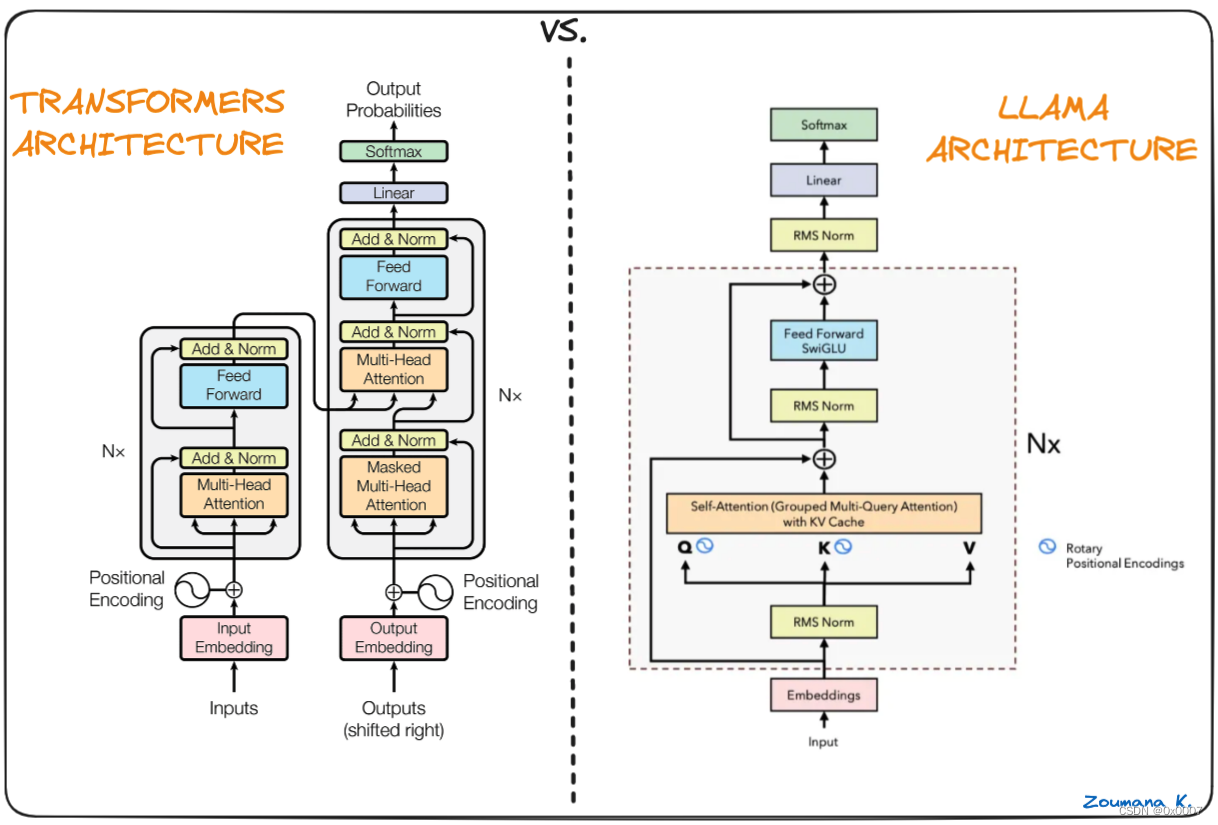
Transformer 和 Llama 架构的区别(Umar Jamil的 Llama 架构)
LLaMa 架构和 Transformer 架构的主要区别:
- 预归一化 (GPT3):通过使用 RMSNorm 方法对每个 Transformer 子层的输入进行归一化,而不是对输出进行归一化,从而提高了训练稳定性。
- SwigGLU 激活函数 (PaLM):原始的非线性 ReLU 激活函数被 SwiGLU 激活函数取代,从而提高了性能。
- 旋转嵌入 (GPTNeao):在移除绝对位置嵌入后,在网络的每一层都添加了旋转位置嵌入 (RoPE)。
环境配置
要开始使用 LLaMa.cpp,你需要以下先决条件:
- Python:以便运行 pip,即 Python 包管理器
- Llama-cpp-python:llama.cpp 的 Python 绑定
创建虚拟环境
建议创建一个虚拟环境,以避免安装过程中出现任何问题,而 conda 可以作为创建环境的良好选择。
本节中的所有命令都在终端中运行。使用 conda create 语句,我们创建一个名为 llama-cpp-env 的虚拟环境。
conda create --name llama-cpp-env成功创建虚拟环境后,我们使用 conda activate 语句激活上述虚拟环境,如下所示:
conda activate llama-cpp-env上述语句应该在终端开头显示括号中包含的环境变量名称,如下所示:

激活后的虚拟环境名称
现在,我们可以安装 Llama-cpp-python 包,如下所示:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48llama_cpp_script.py 的成功执行意味着库已正确安装。
为了确保安装成功,让我们创建并添加导入语句,然后执行脚本。
- 首先,将 from llama_cpp import Llama 添加到 llama_cpp_script.py 文件中,然后
- 运行 python llama_cpp_script.py 执行该文件。如果库无法导入,则会抛出错误;因此,需要对安装过程进行进一步诊断。
了解 Llama.cpp 基础知识
在这个阶段,安装过程应该已经成功,让我们深入了解 LLama.cpp 的基础知识。
上面导入的 Llama 类是使用 Llama.cpp 时利用的主要构造函数,它接受几个参数,并不局限于以下参数。完整的参数列表在官方文档中提供:
- model_path: 使用的 Llama 模型文件路径
- prompt: 输入模型的提示。此文本将被标记化并传递给模型。
- device: 用于运行 Llama 模型的设备;此类设备可以是 CPU 或 GPU。
- max_tokens: 模型响应中要生成的令牌的最大数量
- stop: 导致模型生成过程停止的字符串列表
- temperature: 此值介于 0 和 1 之间。值越低,最终结果越确定性。另一方面,较高的值会导致更大的随机性,从而导致更多样化和更有创意的输出。
- top_p: 用于控制预测的多样性,这意味着它选择累计概率超过给定阈值的最高概率令牌。从零开始,较高的值会增加找到更好输出的机会,但需要额外的计算。
- echo: 一个布尔值,用于确定模型是否在开头包含原始提示(True)或不包含原始提示(False)
例如,假设我们要使用一个名为 <MY_AWESOME_MODEL> 的大型语言模型,该模型存储在当前工作目录中,实例化过程如下所示:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()代码不言自明,可以很容易地从最初的要点中理解每个参数的含义。
模型的结果是一个字典,其中包含生成的响应以及一些额外的元数据。输出的格式将在本文的下一节中探讨。
你的第一个 Llama.cpp 项目
现在,是时候开始实现文本生成项目了。开始一个新的 Llama.cpp 项目不过是在遵循上面的 Python 代码模板,该模板解释了从加载感兴趣的大型语言模型到生成最终响应的所有步骤。
该项目利用了来自 Hugging Face 的 Zephyr-7B-Beta 的 GGUF 版本。它是 mistralai/Mistral-7B-v0.1的微调版本,在使用Direct Preference Optimization (DPO)的公开可用合成数据集混合上训练。
我们的《使用 Transformers 和 Hugging Face 的介绍》提供了对 Transformers 以及如何利用其强大功能来解决现实问题更好的理解。我们还有一个Mistral 7B教程。
Hugging Face 的 Zephyr 模型 (source)
模型下载到本地后,我们可以将其移动到模型文件夹中的项目位置。在深入实现之前,让我们了解一下项目结构:

项目结构
第一步是使用 Llama 构造函数加载模型。由于这是一个大型模型,因此必须指定要加载的模型的最大上下文大小。在这个特定项目中,我们使用 512 个标记。
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE) 加载模型后,下一步就是文本生成阶段,我们使用原始代码模板,但使用了一个名为 generate_text_from_prompt 的辅助函数。
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_output在 __main__ 子句中,可以使用给定的提示执行函数。
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)模型响应如下:

模型的响应
模型生成的回复是 <What do you think about the inclusion policies in Tech companies?>>,模型的准确回复突出显示在橙色框中。
- 原始提示有 12 个标记
- 回答或完成令牌有 10 个和、
- 代币总数是上述两个代币的总和,即 22
尽管这个完整的输出结果对进一步使用很有用,但我们可能只对模型的文本响应感兴趣。我们可以通过选择 "选择 "元素的 "文本 "字段来格式化响应,以获得这样的结果,具体如下:
final_result = model_output["choices"][0]["text"].strip()strip() 函数用于删除字符串中的前导空格和尾部空格,结果如下:
Tech companies want diverse workforces to build better products.
Llama.CPP 实际应用
本节将介绍 LLama.cpp 在现实世界中的应用,并提供基本问题、可能的解决方案以及使用 Llama.cpp 的好处。
需求
想象一下,ETP4Africa 是一家科技初创公司,他们的教育应用程序需要一个能在各种设备上高效运行而不会造成延迟的语言模型。
使用 Llama.cpp 的解决方案
他们实施了 Llama.cpp,利用其 CPU 优化性能和与基于 Go 的后台接口的能力。
优点
- 便携性和速度:Llama.cpp 的轻量级设计可确保快速响应并兼容多种设备。
- 自定义:量身定制的底层功能可让应用程序有效提供实时编码帮助。
Llama.cpp 的集成使 ETP4Africa 应用程序能够提供即时、互动的编程指导,从而改善用户体验和参与度。
数据工程是任何数据科学和人工智能项目的关键组成部分,我们的《数据工程和数据应用的LangChain入门教程》为将人工智能从大型语言模型纳入数据管道和应用提供了完整的指导。
结论
总之,本文全面概述了如何使用 LLama.cpp 建立和使用大型语言模型。
本文提供了详细的说明,帮助读者了解 Llama.cpp 的基础知识、设置工作环境、安装所需的库以及实现文本生成(问题解答)用例。
最后,还就实际应用以及如何使用 Llama.cpp 有效解决根本问题提供了实用见解。
准备好深入大型语言模型的世界了吗?通过我们的《如何使用 LangChain 构建 LLM 应用程序》教程和《如何使用 PyTorch 训练 LLM》教程,利用人工智能专业人员使用的强大深度学习框架 LangChain 和 Pytorch 提高您的技能。
作者

Zoumana 开发了 LLM 人工智能工具,帮助公司开展可持续发展尽职调查和风险评估。他曾在 Axionable 和 IBM 担任数据科学家和机器学习工程师。Zoumana 是同侪学习教育技术平台 ETP4Africa 的创始人。他为 DataCamp 编写了 20 多篇教程。















 2607
2607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









