






机器视觉---ANN
目录
前言
本文通过opencv提供的ANN-MLP训练水果识别模型,样本为苹果、香蕉、梨、葡萄、橙,训练集为5种水果各100个样本(共500个),测试集为每类水果10个样本(共50个)。
一、简化训练样本
原样本为尺寸不一的图片,大部分图片的宽高比例范围在3:2~2:1,为将图片拉成同等长度的向量,生成训练集时将读取的图片统一为3:2的宽高比例,本文样本宽高选取45:30。(src原图像为灰度图片)
void MainWindow::FruitAnnPrePro(cv::Mat &src, cv::Mat &dst)
{
using namespace cv;
src.convertTo(src,CV_32FC1);
cv::resize(src,src,Size(45,30));
dst.push_back(src.reshape(0,1));
}二、生成训练数据
1.读取样本
样本存储在5个文件夹下,先将文件夹名称和文件名称以字符串数组形式保存,以便逐项读取。读取后将经预处理函数简化并拉成长度为45*30=1350的行向量,然后将向量压入trainData中形成符合要求的训练集。


代码如下(示例):
string fruits[5] = {"apple","banana","grape","pear","orange"};
string path = "/home/ghoson-x/Downloads/fruits/";//样本所在文件夹
string * filePath = new string;
filePath->append(path).append(fruits[i]).append("/");//i文件夹序号,对应文件夹名
for(int j=0;j<100;++j){
string * imagePath = new string; imagePath->append(filePath->data()).append(QString::number(j).toStdString()).append(".jpg");//形成完整读取路径
Mat temp = imread(imagePath->data(),IMREAD_GRAYSCALE);
if(temp.empty()){
break;
}
FruitAnnPrePro(temp,trainData);//自定义图像预处理函数
trainLabel.push_back(Label.row(i));//构造标签矩阵
delete imagePath;
}2.读取标签
标签矩阵要求行向量对应样本类别,例如第0行~99行为苹果的标签,本文定义【1,0,0,0,0】行向量为苹果的标签。
代码如下(示例):
Mat Label = Mat::eye(5,5,CV_32FC1);
trainLabel.push_back(Label.row(i));//读取样本时同时生成对应标签同理测试集和测试标签也可如法炮制。
三、训练模型
1、转换数据集
Ptr<TrainData> trainData=TrainData::create(trainDataMat,ROW_SAMPLE,trainLabelMat);2、创建模型
Ptr<cv::ml::ANN_MLP> ANN_model = ANN_MLP::create();3、设置参数
根据数据集特点设置参数,特征数为1350,隐藏层设为10,输出层为5;选择Sigmoid函数作为激活函数
Mat layerSize = (cv::Mat_<int>(1,3) << 1350, 10, 5);
ANN_model->setLayerSizes(layerSize);
ANN_model->setActivationFunction(ANN_MLP::SIGMOID_SYM,1,1);
ANN_model->setTermCriteria(cv::TermCriteria(cv::TermCriteria::MAX_ITER + cv::TermCriteria::EPS,300,0.95));
ANN_model->setTrainMethod(ANN_MLP::RPROP,0.1);4、训练模型
ANN_model->train(trainData);5、测试模型
通过判断预测输出向量最大值位置是否与测试标签向量最大值位置对应,例如【1,0,0,0,0】,最大值位置为(0,0),0行0列处。
ANN_model->predict(testDataMat.row(i),Response);
cv::minMaxLoc(Response,&MinVal,&MaxVal,&Minloc,&Maxloc);
cv::minMaxLoc(testLabelMat.row(i),&MinVal,&MaxVal,&Minloc,&Maxlab); if(Maxloc.y == Maxlab.y){
cout << "Y" << endl;
++rightNum;
}
else{
cout << "N" << endl;
++errorNum;
}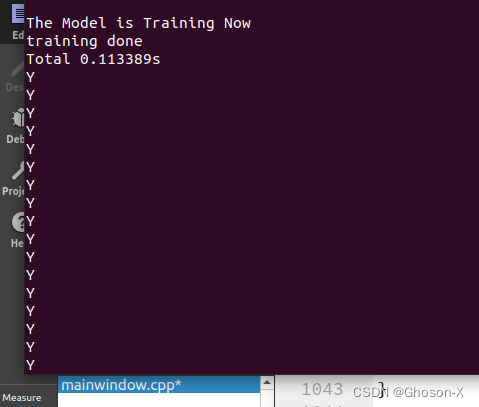

最终预测准确率为100%
6、保存模型
ANN_model->save("FruitsRecogModel.xml");7、测试保存的模型
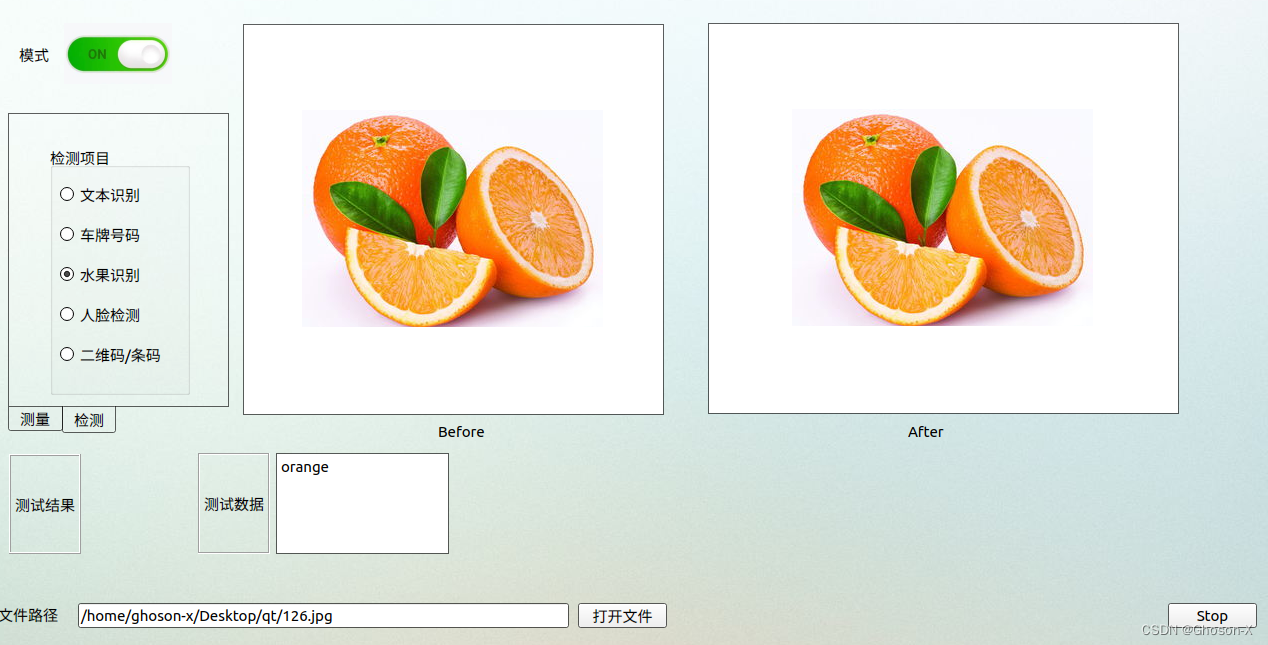
预处理读取的图片,然后加载模型,将要预测的数据传入模型,得到预测结果向量,整理预测结果,输出。
Ptr<ANN_MLP> annModel = ANN_MLP::load("FruitsRecogModel.xml");
annModel->predict(dst,result);
std::cout << format(result,Formatter::FMT_NUMPY) << std::endl;
输出向量中易见,各个类别的可能性,最大可能为橘子,因此输出结果orange.

总结
1、需要注意的是训练数据集和训练标签Mat数据类型必须为CV_32F,否则报错。
2、要注意数据集的大小,行数对应样本数,列数对应特征数(这里为45*30=1350),标签矩阵行数为样本数,列数为5(5种水果)。
3、参数设置,层的尺寸要对应好输入为1350,输出为5
4、若出现trainData相关报错,先输出Mat查看其数据类型或尺寸,看是否有不匹配的地方。















 8464
8464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









