









“Physics-based Deep Learning”学习笔记(1)
可微分物理模型(Differentiable physics(DP))
基于物理的深度学习,其本质是应用某个特定领域内的模型方程,将其离散化之后的方程整合进深度学习的训练过程。正如其名称中所提到的“可微分”,拥有可微分的公式对于训练神经网络至关重要。
接下来,我们通过一个粒子来了解基于DP的深度学习。
假设存在一个未知的函数
f
∗
:
X
→
Y
f^{*}:X \rightarrow Y
f∗:X→Y(通常用
∗
*
∗的上标来表示理想或者未知的函数,而可离散化或者可实现的函数则不会带此标记)。
再假设存在一个通用微分方程 P ∗ : Y → Z \mathcal{P}^{*}:Y \rightarrow Z P∗:Y→Z,这个方程可以编码一些现实世界中的属性。
如果说我们使用一个神经网络 f f f来学习这些未知函数 f ∗ f^* f∗,一般来说我们可以利用经典的监督式学习,通过收集一些数据来得出 f f f。具体来讲,就是先通过从 X X X中采样得到一些数据点 x x x和其相对应在 Y Y Y中的数据点 y y y作为数据集,这之后可以训练神经网络 f f f来拟合这个数据集。
而基于可微分物理模型的方法优势则在于,用离散化后的物理模型 P \mathcal{P} P来引导训练神经网络 f f f。也就是说,我们希望能够通过让 f f f意识到存在一个模拟器 P \mathcal{P} P,并与之产生交互。而这样则会大大提升学习效率,这之后会用一个简单的粒子来证明。
这里值得注意的是,要想基于DP的方法是有效的,则该物理模型的方程必须是可微分的。这些以梯度形式存在的差值就是驱动学习过程的重要因素。
以抛物线拟合为例
为了更好地理解监督式方法(Supervised Approach)和DP方法的区别,以一个焦点在 x x x正半轴的抛物线作为案例来说明。我们设定一个函数 P : y → y 2 , y ∈ [ 0 , 1 ] \mathcal{P}:y \rightarrow y^2, y \in [0,1] P:y→y2,y∈[0,1],目标是寻找到一个未知函数 f f f使得: P ( f ( x ) ) = x , x ∈ [ 0 , 1 ] \mathcal{P}(f(x))=x, x \in [0,1] P(f(x))=x,x∈[0,1]。
对于这个抛物线而言,我们都知道 f f f的解就是正或负的平方根函数。由于这并不是很困难,所以我们可以选择训练一个神经网络来拟合逆向映射。经典的监督式学习方法是随机生成一个在负平方根到正平方根之间的数据集作为神经网络的数据集。如下是示例代码:
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# X-Data
N = 200
X = np.random.random(N)
# Generation Y-Data
sign = (- np.ones((N,)))**np.random.randint(2,size=N)
Y = np.sqrt(X) * sign
# Neural network
act = tf.keras.layers.ReLU()
nn_sv = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation=act),
tf.keras.layers.Dense(10, activation=act),
tf.keras.layers.Dense(1,activation='linear')])
# Loss
loss_sv = tf.keras.losses.MeanSquaredError()
optimizer_sv = tf.keras.optimizers.Adam(lr=0.001)
nn_sv.compile(optimizer=optimizer_sv, loss=loss_sv)
# Training
results_sv = nn_sv.fit(X, Y, epochs=5, batch_size= 5, verbose=1)
# Results
plt.plot(X,Y,'.',label='Data points', color="lightgray")
plt.plot(X,nn_sv.predict(X),'.',label='Supervised', color="red")
plt.xlabel('y')
plt.ylabel('x')
plt.title('Standard approach')
plt.legend()
plt.show()
通过监督式方法得到的拟合结果如下:
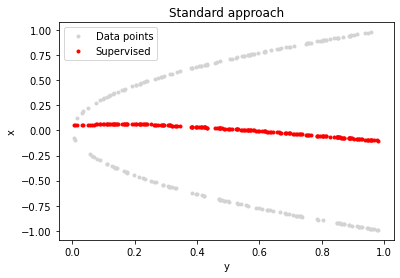
此处红色为预测的结果,而灰色为原始数据。从结果来看这远远没有达到我们灰色曲线所设定的目标。
通过Keras可视化工具我们可以很简单看到这个神经网络隐藏层的构造:
tf.keras.utils.plot_model(nn_sv, show_shapes=True)
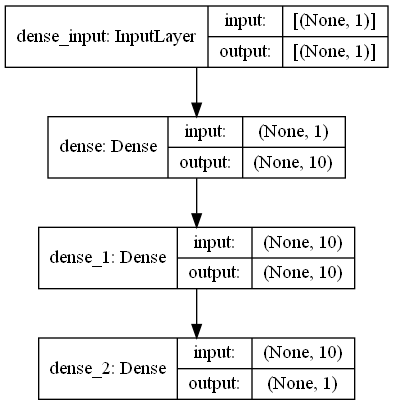
基于可微分物理模型的抛物线拟合
与监督式学习方法不同的是,基于可微分物理模型的方法是不需要生成数据集中每个点 x x x对应的真实数据 y y y的。根据上一节中所提到的" f f f的解是正或负的平方根函数"这一特性,我们可以通过一个简单的均方差形式的公式来作为损失函数 ∣ y p r e d 2 − y t r u e ∣ 2 |y^2_{pred}-y_{true}|^2 ∣ypred2−ytrue∣2,通过在训练过程中最小化这个函数便可以实现拟合效果。值得注意的是,在这里如果我们能够利用更多信息或者更好数值计算的方法,我们就能更好地去指引整个神经网络的训练。
对比一下和监督式学习方法的不同之处:
# Supervised
# Loss
loss_sv = tf.keras.losses.MeanSquaredError()
# Training
results_sv = nn_sv.fit(X, Y, epochs=5, batch_size= 5, verbose=1)
# DP
# Loss
mse = tf.keras.losses.MeanSquaredError()
def loss_dp(y_true, y_pred):
return mse(y_true,y_pred**2)
# Training
results_dp = nn_dp.fit(X, X, epochs=5, batch_size=5, verbose=1)
下面是完整的基于DP的代码:
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# X-Data
N = 200
X = np.random.random(N)
# Generation Y-Data
sign = (- np.ones((N,)))**np.random.randint(2,size=N)
Y = np.sqrt(X) * sign
act = tf.keras.layers.ReLU()
# Model
nn_dp = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation=act),
tf.keras.layers.Dense(10, activation=act),
tf.keras.layers.Dense(1, activation='linear')])
#Loss
mse = tf.keras.losses.MeanSquaredError()
def loss_dp(y_true, y_pred):
return mse(y_true,y_pred**2)
optimizer_dp = tf.keras.optimizers.Adam(learning_rate=0.001)
nn_dp.compile(optimizer=optimizer_dp, loss=loss_dp)
#Training
results_dp = nn_dp.fit(X, X, epochs=5, batch_size=5, verbose=1)
# Results
plt.plot(X,Y,'.',label='Datapoints', color="lightgray")
#plt.plot(X,nn_sv.predict(X),'.',label='Supervised', color="red")
# optional for comparison
plt.plot(X,nn_dp.predict(X),'.',label='Diff. Phys.', color="green")
plt.xlabel('x')
plt.ylabel('y')
plt.title('Differentiable physics approach')
plt.legend()
plt.show()
通过DP方法可以得到的拟合结果如下:
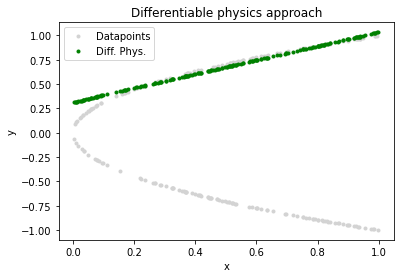
从结果上来说,DP方法要比监督式方法效果看起来更好。具体来说,DP方法是通过评估离散模型与网络的当前预测值,而不是使用预先计算出的数据用来评估,结果上DP方法防止了拟合数据结果出现平均化这一问题。
但是,从结果上看,依然存在着几个问题:
- 拟合结果依然只有目标函数的一侧被拟合出来。造成这个的原因是由于我们只使用了一个确定性函数,只能捕捉到单一的模式。为了捕捉函数中的多种模式,需要扩展这个神经网络结构并需要考虑额外的维度对其进行参数化。同时,拟合出的目标函数一侧是上侧还是下侧是由初始化权重决定的,多运行几次便可以看到不同侧的拟合结果。
- 在这个实验中, x x x轴正方向上接近零的区域还是存在着一定的偏离现象。这是由于神经网络在这里基本上是只学习到了抛物线一半的线性近似。造成这样的原因是当前使用的神经网络结构非常简单而且层数并不够多。除此之外,沿 x x x轴均匀分布的样本点使神经网络偏向于学习较大的 y y y值。因为这部分对损失函数的影响更大,结果就是神经网络为了减少这个区域的误差而投入了大量的资源。
补充实验
更好地拟合单边
为了更好地拟合抛物线一般性质,我尝试了对实验中一些参数的调整。最终可以通过以下参数获得更好拟合单边的效果,设置参数learning_rate=0.0001, epochs=3000, batch_size=20,结果如下:
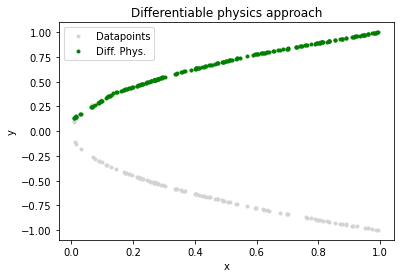
代码
https://github.com/RaymondMcGuire/PBDL_practice
TODO
- 如何拟合抛物线两侧,如何实现Multimodal target
- 抛物面拟合















 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









