









1、安装anaconda
1.1 下载安装包
Anaconda 官网:https://www.anaconda.com/download/
镜像网站:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
1.2 安装
Install for 选择 just me 即可;
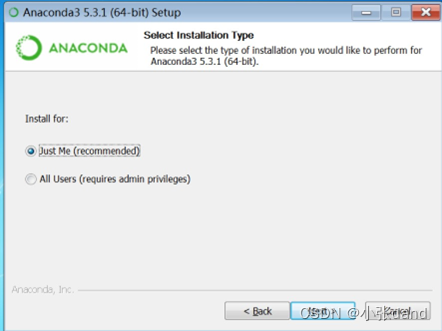
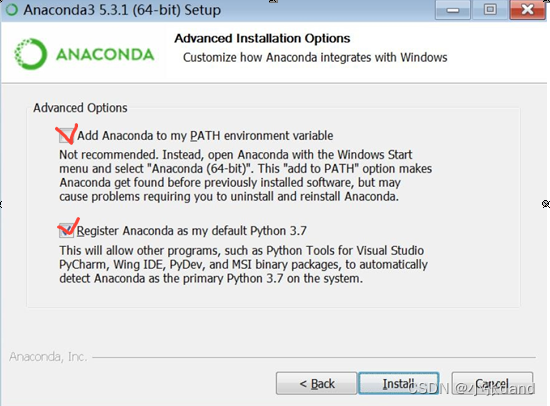
第一个选项是添加环境变量,可以选择勾选(我这里直接勾选),之后在 cmd 中可直接运行 conda 命令,调出python 等。之后点击 install 进行安装;
1.3 anaconda打不开怎么办
step1:conda update conda
step2:conda update --all
1.4 配置环境
也可以在页面进行操作
# 在anaconda prompt中使用以下命令查看已有的虚拟环境
conda info -e
# 使用以下命令新建一个虚拟环境(your_env_name自己命名,python版本号要对应):如果不想用命令行创建也可以在图像化界面中直接创建一个
conda create -n py37 python=3.7.16
# 使用一下命令激活虚拟环境,并将相应的pytorch包放入其中或者下载到对应文件夹下
conda activate py37
# 调整一下你的下载源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
2 源码下载
下载链接:https://github.com/yeyupiaoling/PaddlePaddle-DeepSpeech
3 搭建环境
3.1 安装PaddlePaddle-GPU版本
conda activate py37 #为与其它环境相互干扰,创建的虚拟环境,进入虚拟环境下,进行以下操作
conda install paddlepaddle-gpu==2.1.3 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
3.2 安装其它依赖库
cd xxxx#进入源代码目录下
python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
在此过程中,pyaudio会安装失败,故在下面链接找到python3.7对应的依赖包下载离线安装:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
3.3 解决error: Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools“:
安装Microsoft C++ 生成工具 - Visual Studio:https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/

然后勾选使用c++的桌面开发:
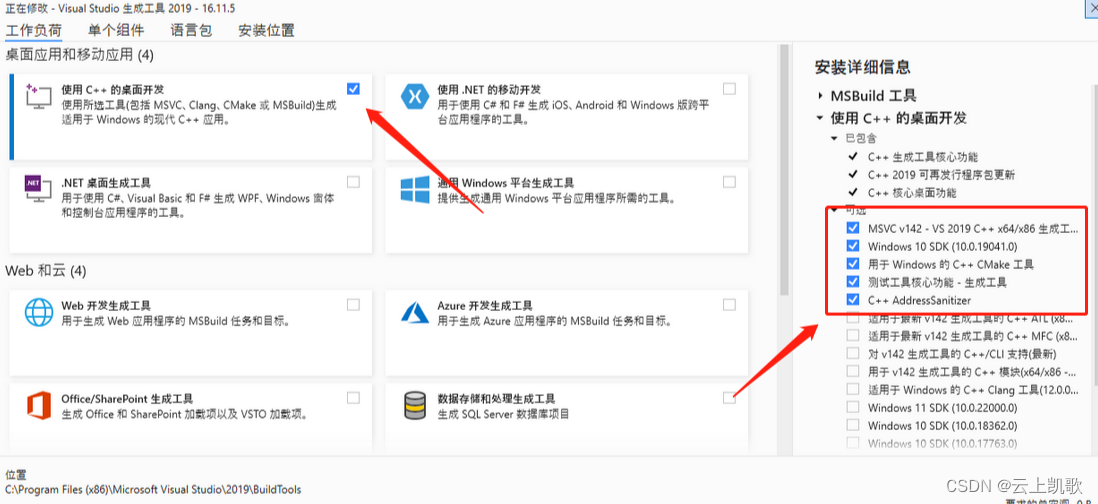
等待下载安装成功
4.下载模型
| 数据集 | 卷积层数量 | 循环神经网络的数量 | 循环神经网络的大小 | 测试集字错率 | 下载地址 |
|---|---|---|---|---|---|
| aishell(179小时) | 2 | 3 | 1024 | 0.084532 | 点击下载 |
| free_st_chinese_mandarin_corpus(109小时) | 2 | 3 | 1024 | 0.170260 | 点击下载 |
| thchs_30(34小时) | 2 | 3 | 1024 | 0.026838 | 点击下载 |
实践中选择字错率最低的下载,下载完成后解压,将dataset文件夹中mean_std.npz与zh_vocab.txt拷贝至源码**./dataset**目录下,将models文件夹拷贝至源码根目录下。
5、导出预测模型
python export_model.py --resume_model=./models/param/50.pdparams
5.1 解决报错:
pip install --upgrade setuptools
pip install --upgrade Pillow
5.2 安装Cuda和Cudnn
注意:Cudnn的版本需要与Cuda对应
win11+anaconda3+python3.7+cuda10.0+cudnn7.6.0+PaddlePaddle 2.1.3
-
Cuda安装
-
运行exe安装包
-
自定义安装
-
安装Cuda即可(驱动等其他东西一般windows已经安装了最新版)
-
-
安装Cudnn
- 解压zip压缩包,复制所有文件到Cuda安装目录下,如:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
-
验证安装
-
Cuda:
nvcc -V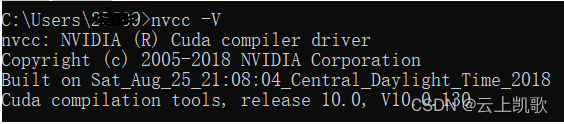
-
Cudnn:
nvidia-smi
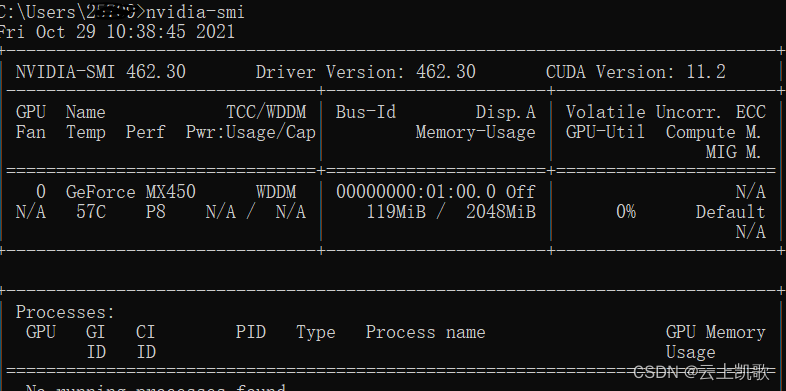
-
如果没有nvida的GPU是安装不成功的,需要根据提示修改源码,改为使用cpu
6、使用语音文件测试
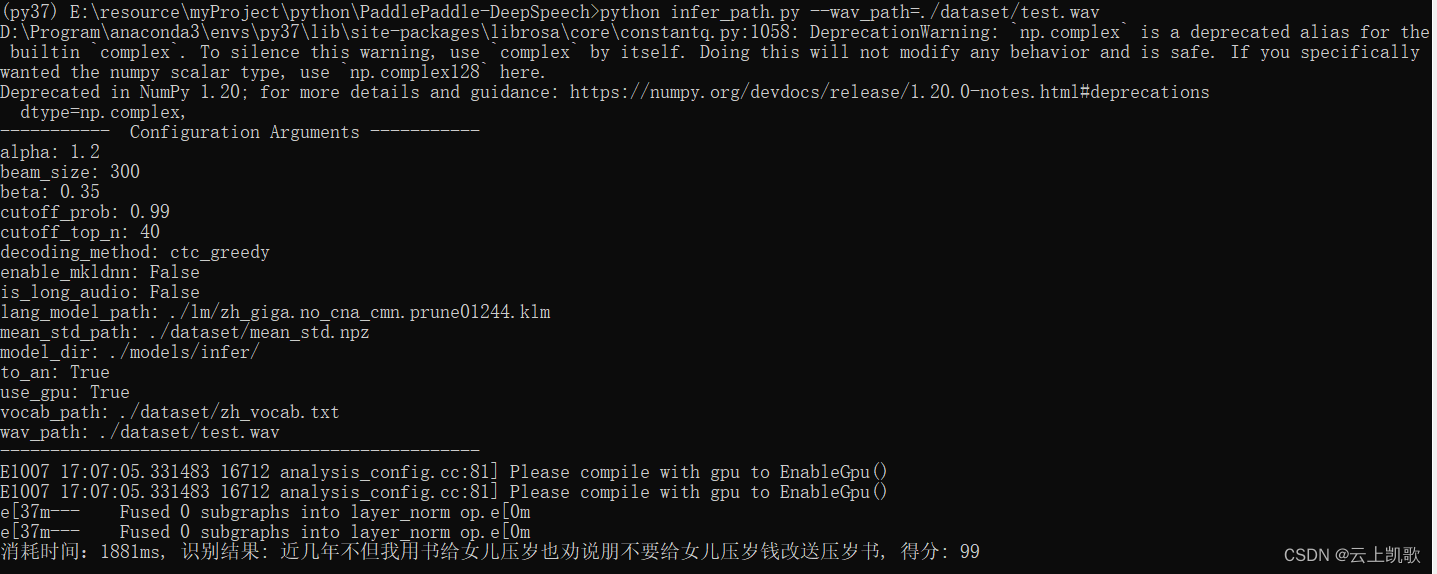
python infer_path.py --wav_path=./dataset/test.wav
长语音预测执行以下命令:
python infer_path.py --wav_path=./dataset/test_vad.wav --is_long_audio=True
7、服务端部署
如果本地运行,实现录音功能,将IP地址改成localhost,录音完成点击上传,支持中文数字转阿拉伯数字,将参数–to_an设置为True即可,默认为True
8、GUI界面部署
python infer_gui.py


















 3957
3957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











