






论文pdf
introduction
冷启问题都被认为是缺乏数据,论文从两个维度上重新定义了冷启问题:1. 新用户和老用户的行为分布不一致。2. 样本不均衡,导致模型很难平衡新老用户的分布。论文将这种问题定义为个性化淹没问题(submergence of personalization)。此外,论文提出了POSO(Personalized cold start modules)模型去解决个性化淹没的问题,两个层面理解POSO:a. 无论样本是否均衡,对应的人群最终都会流入到对应的子模块。b. 门控网络权重完全是根据所选择的个性化特征决定的,在一定程度上避免了个性化淹没。
motivation
针对下面四个指标(per-play watch time, video view, like rate, finish-view rate),论文将新用户与老用户的差值(老用户采用了均值作为基准)进行分布展示,如下图所示,可以看出新用户较老用户更喜欢点赞(对很大范围的视频具有新鲜感)和看完整个视频,新用户的per-play watch time指标更低,说明他们更倾向于短视频。并且新用户和老用户的分布是不一样的。所以期望模型能使用一些个性化的特征去区分不同的用户人群。
实际上在现有的模型中, 一些个性化的特征被用做平衡不同的用户群体,但是因为数据样本的不均衡采样,导致了这些特征被冲掉。比如下图b所示,将一些特征mask掉,然后将最后一层激活函数的状态与不mask的状态做差。可以看到的是,用于区分用户人群的特征(分布不均衡)mask掉之后激活函数状态没有太大变化,但是用户城市的特征(均衡的特征)mask掉之后激活函数状态有明显的变化。这主要是因为新用户只占5%的比例,在训练过程中,大部分的时间这些特征都不改变,所以这些特征变得可有可无。

contribution
- 论文揭露了冷启问题是个性化淹没问题,即如果没有专门设计的结构,个性化特征将会被淹没,这也是为什么冷启场景表现较差的原因
- 论文提出了一种新的方法叫POSO(Personalized cold start modules)去解决个性化淹没的问题。POSO并不是一个孤立的方法,他可以快速的融合到很多现有的其他模型中,比如MLP,MHA和MMoE,并且不会带来额外的计算开销。
model
理论情况下,如下式所示,针对每一个用户,都可以创建一个模型去预测
![]()
但是由于用户数太多,实际上这种方式是不可行的。一种可能的解决方案是将用户分成若干个簇,比如新用户,老用户,回流用户等,去建模这些用户簇的兴趣偏好即可。需要注意的是一个特定的用户可以被认为是不同用户簇共同决定,因此一个用户的兴趣表达可以由下式 计算(其中N表示一共有N个用户簇)

POSO使用了一个门控网络去产生权重wi,门控网络的输入是个性化的特征(称为personalization code)。这些特征可以被用来识别用户人群。此外,POSO直接将中间层模块视作N个用户簇的模型并维持其他网络结构不变,因此没有增加其他的额外开销。由于对门控机制g(.)结果的和没有其他限制,为了避免overal scale drifting,poso增加了一个修正变量C,如下式所示,这就是POSO的整体思路。
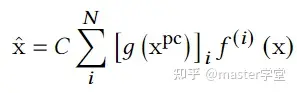
对POSO结构的理解可以从以下三方方面:
- 个性化。POSO从两个方面解决了个性化淹没的问题:a. 通过门控机制和多个模块,特征被均衡化了。尽管新用户样本很少,因为POSO会针对新用户有“单独的模型”进行训练,所以他们也不会被淹没。b. 无论POSO被应用到哪一层,都是基于用户最原始的个性化特征,而不是“二手的”特征(second-hand),“二手的”特征很难被自学习技术学习到。
- 灵活性。POSO不是一个孤立的模型,而是一种解决个性化问题的通用解决方案。它可以很轻易的融合到MLP,MHA,MMoE等个性化模型中。
- 没有后顾之忧(去耦合)。POSO的各个子模块都使用了的相同的输入(个性化特征),输出都会被融合到对应的模块中。事实上,各个子模块都是结构独立的。上下游模块是没有直接依赖的。
poso可以很自然的应用到MLP,MHA(mult-head attention),MMoE中,其结构如下图所示。

需要注意以下几点:
- 在MLP中每一层都使用了POSO结构。但是层与层之间的POSO结构是相互独立的。
- 在MHA中,很直观的一种处理便是三个矩阵Q,K,V都采用POSO结构融入个性化特征,尽管实验效果不错,但是计算开销增加了。考虑到实际应用过程中,Q一般都是无序列特征的用户个性化特征,所以Q部分不用POSO处理。V基本上都是用户历史行为数据,不包含用户个性化特征(personalization code),并且直接决定MHA的输出,所以论文对V加入了多头的POSO结构。如果对K矩阵使用多头POSO结构,将会增加冗余的参数,因为Q和K相乘所产生的注意力权重比K有更低的维度,所以论文对K矩阵只使用了单头的POSO结构就足够了。如下式所示:

- 在MMoE中,只针对每个专家网络使用POSO优化,即对专家网络进行门控上的加权求和即可。如下式所示















 7040
7040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









