







前段时间在业务中应用POSO[1]做了一些工作,进行了一些尝试和思考,放在这篇里分享,主要包括两部分:(1) POSO原理;(2) 实际应用中的尝试、效果和分析思考,欢迎大家对工作中的尝试和思考来交流。
多说一句:初看论文和在业务中应用的时候,觉得这个思路简单优雅,并未深入体会其中的精妙,在写这篇分享的时候,多次看论文中的一些细节,不得不惊叹作者的巧思。
推荐领域常用的方法是监督学习,本质是拟合数据的分布,不管是简单还是复杂的监督学习模型,数据限定了其效果的天花板。因此,监督学习的方法,存在一个共同的问题,对训练集中从未出现过的分布,拟合效果大打折扣。在推荐场景,新用户和新物品非常常见,他们没有历史数据,模型在训练过程中缺少对应样本,因此难以学到其分布,从而可发挥的作用有限。这类问题,在推荐领域是一个很大也很重要的方向,即冷启动。
针对用户冷启问题,快手于2021年提出POSO(Personalized Cold Start Modules)模型,以一种优雅的方式缓解新浅用户样本稀疏的问题,在对新浅用户带来显著效果的同时,对非新浅用户也有一定效果。
1 提出背景
推荐场景中,新用户的留存对业务发展非常重要,新用户留存依赖于新用户冷启效果,而由于新用户的一些特点,用户冷启一直是业界的难点问题。
1.1 行为数据稀少
其特点包括:(1) 新用户历史行为数据非常稀少,导致模型难以捕捉其兴趣,从而难以进行有效的个性化推荐;(2) 新用户耐心差,对推荐结果敏感,给系统试错的机会少,初期一两次不好的推荐结果有很高的概率导致用户停止在该场景继续消费,从而造成用户流失。
已有的用户冷启方法大致可分为两类:(1) 元学习(meta learning),这种方法的思路是利用先验知识的共性,通过多个数据集学习f,使其可以用于新的场景,从而实现利用非冷启用户的数据来得到适用于冷启用户的模型;(2) id embedding生成,这种方法利用其他特征生成id embedding,从而缓解冷启用户历史数据稀少的问题。
1.2 样本分布极度不均衡
上述方法虽然可以一定程度解决冷启用户缺少数据带来的问题,但忽略了冷启问题中样本分布极度不均衡的问题,导致模型受主体样本的影响。推荐场景中,冷启用户的样本在全量样本中占比不足5%,绝大多数样本来自非冷启用户。
1.3 用户行为模式差异
冷启用户和非冷启用户的行为模式存在明显差异,其行为模式差异的后验数据如图1所示,以非冷启用户行为的后验数据为原点,冷启用户行为的后验数据和原点存在明显偏差。在样本分布极度不均衡的情况下,模型受非冷启用户主导,而非冷启用户和冷启用户的行为模式差异明显,导致模型无法捕捉到冷启用户的行为模式。
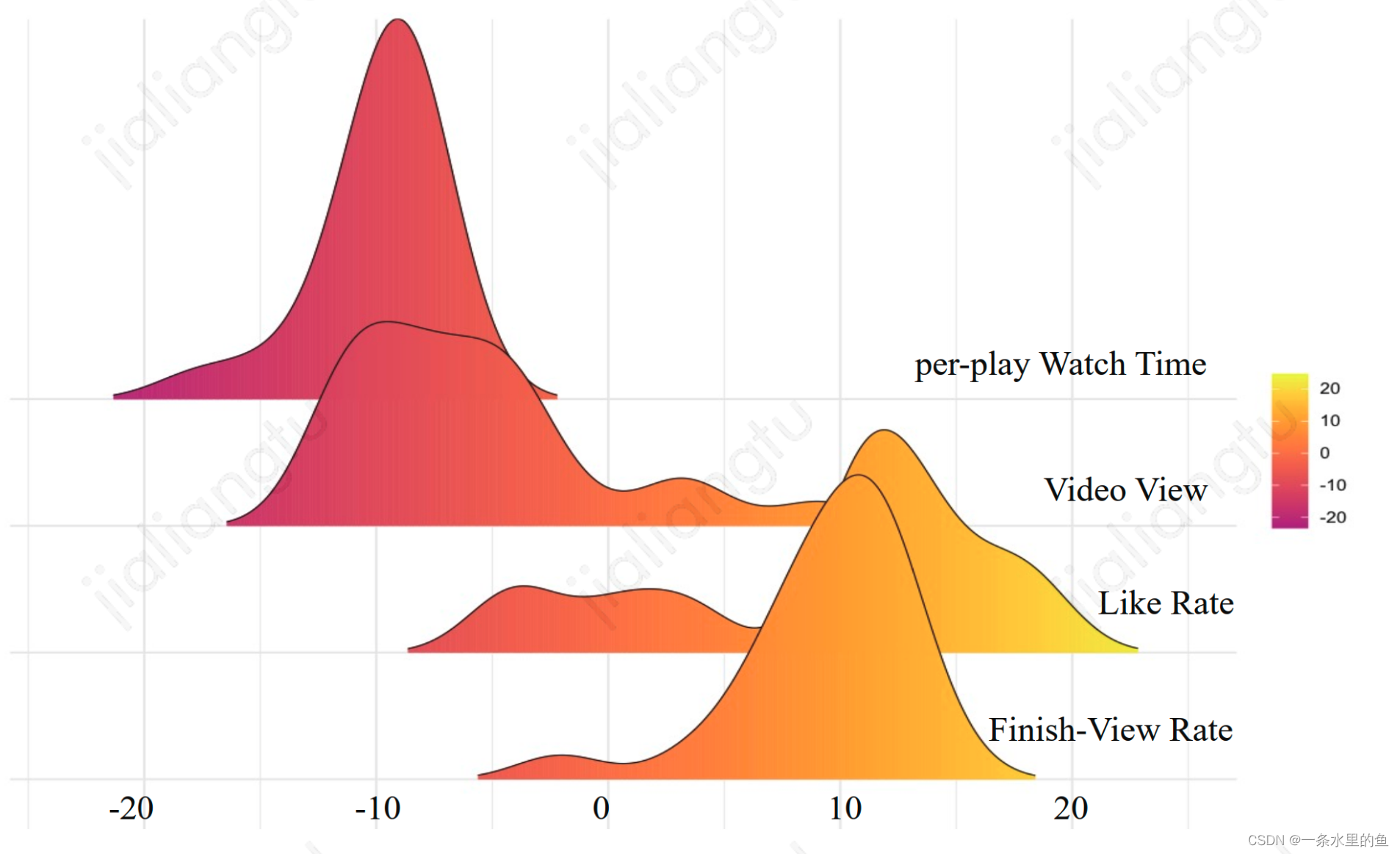
图1 冷启用户行为后验数据对非冷启用户行为后验数据的偏差
对于样本分布不均衡问题,直观的做法是在特征中使用相关的特征,在冷启问题中,该特征可以用是否为冷启用户表示,从而帮助模型学到其偏差。实际上,论文通过实验验证,模型很难利用这类特征捕捉到不同样本之间的偏差。图2表示了在模型中分别mask掉(置0)非均衡和均衡特征之后各个task最后一层dense层输出的平均值,可以看出,mask掉是否为新用户这个特征,dense层输出基本不变,而mask掉country这个特征,dense层输出变化明显。由于是否为新用户这个特征分布极度不均衡,当mask掉这个特征后(原模型新用户该特征值为1,非新用户特征值为0),仅有不到5%的样本受影响,对模型的影响非常有限,导致模型更新基本不变;而mask均衡分布的特征则不一样,大量样本受到影响,导致模型也受到较大影响。
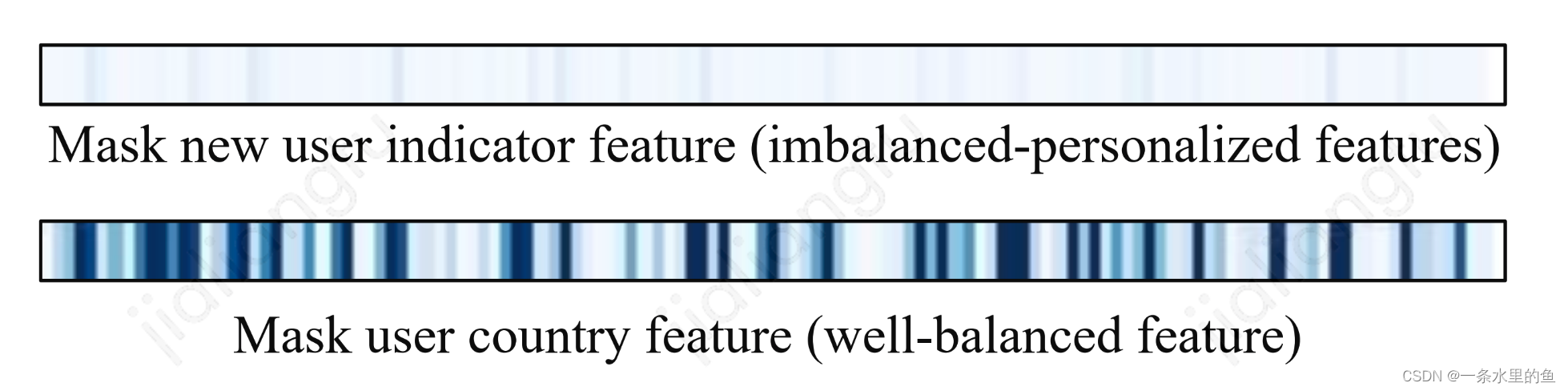
图2 模型对均衡分布和非均衡分布特征的敏感性
针对冷启用户样本稀疏导致的样本分布极度不均衡问题,POSO利用对每个用户学习其模型的思路,从模型层面加强非均衡特征的学习,从而缓解冷启面临的模型被主体样本主导的问题。
2 POSO详解
POSO模型的思路非常朴素,即对每个用户学习对应的模型,不受其他用户样本的影响,做到完全基于用户自己的个性化。基于此思路,进行简化和近似等价,在基础的单个模型中引入个性化模块,使模型对每个用户在模型结构层面进行个性化响应,实现模型结构的个性化。
2.1 原理
2.1.1 基础设计思路
POSO模型设计的出发点是对每个用户学习其模型,如式子(1)所示,其中u表示用户,x为输入,y为输出,fu则表示了这个用户对应的模型。这个思路直观简单,但由于推荐场景用户量庞大,因此在落地层面不可行。
(1)
2.1.2 用户分群表征
沿着模型最初设计思路,对用户分群,每个用户群学习其对应模型,则可解决单个用户对应一个模型带来的数据量庞大而无法落地实现的问题。单个用户可以看成是不同用户群的组合,比如一个用户可以看成是活跃用户和非活跃用户的组合。式子(2)表示了该思路,其中N表示用户群数量,wi表示第i个用户群对应模型对用户u的权重,通过gate网络计算得到,如式子(3)所示,其中表示用户的个性化编码特征(Personalization Code),如用户群属性、是否新用户之类的特征,这类特征在全局样本中分布不均衡。
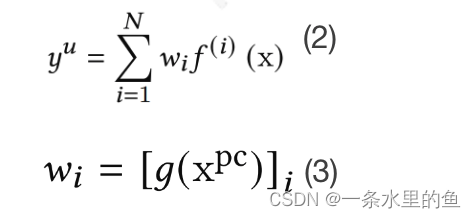
2.1.3 当前模型利用
通过用户分群的方法,虽然实际落地可行,但依然需要学习N个模型,参数量随着用户群数量线性增长,因此巧妙利用gate的作用,对模型数量简化,仅使用业务当前模型即可。既然需要不同用户群模型,那就以业务当前模型为基础,通过加权得到某个用户群的模型,再进行加权得到某个用户的模型,两次加权可以通过一个gate网络合并。这种简化方式不仅减少了模型数量,而且由于使用业务当前模型,无需重新训练模型,对落地非常友好。
利用gate作用简化后,再对当前模型按模块拆解,则可表示为式子(4),其中f表示业务当前所使用的模型,x和x拔分别表示模型某层的输入和输出,C为修正因子,引入C的原因是gate求和没有归一化的约束,输出期望存在缩放偏移。
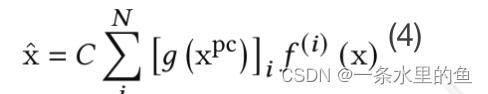
2.1.4 按位乘近似等价
模型中的主要模块是全连接层,将式子(4)运用在全连接层,则可表示为式子(5),对于输表征的第p维,计算过程可表示为式子(6),其中为输入x的维度,为输出的维度,表示全连接层对应输入输出在维度(p, q)的参数。对式子(6)中的参数进行适当的设置,则可对其进行有效的简化,当N=,在 i !=p时取0,i=p时保持原值时,式子(6)则可表示为式子(7),其中表示按位乘。
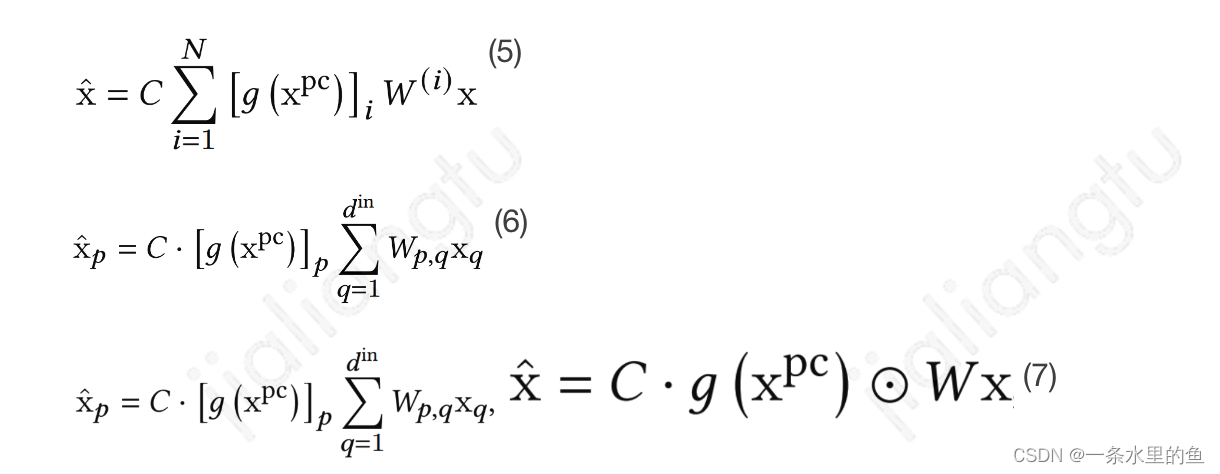
这种参数设置巧妙地对式子进行了简化和等价,通过gate输出和原有模型输出按位乘则实现了模型结构层面的用户个性化,计算简单、效率高,可以称得上实现优雅。
2.2 模型结构
从POSO模型的朴素设计思路出发,经过一系列有效的简化和近似操作,最终通过在全连接层点乘的方式,实现了模型结构的个性化。这种方式使得模型在使用POSO思路时结构简单清洗,且各种模型结构均适用,也适用于模型中单个或多个模块,包括但不限于简单的全连接结构、multi-head attention结构、MMoE结构。
2.2.1 全连接结构
全连接结构使用POSO使,全连接的每层输出和gate的输出按位相乘,如图3所示。
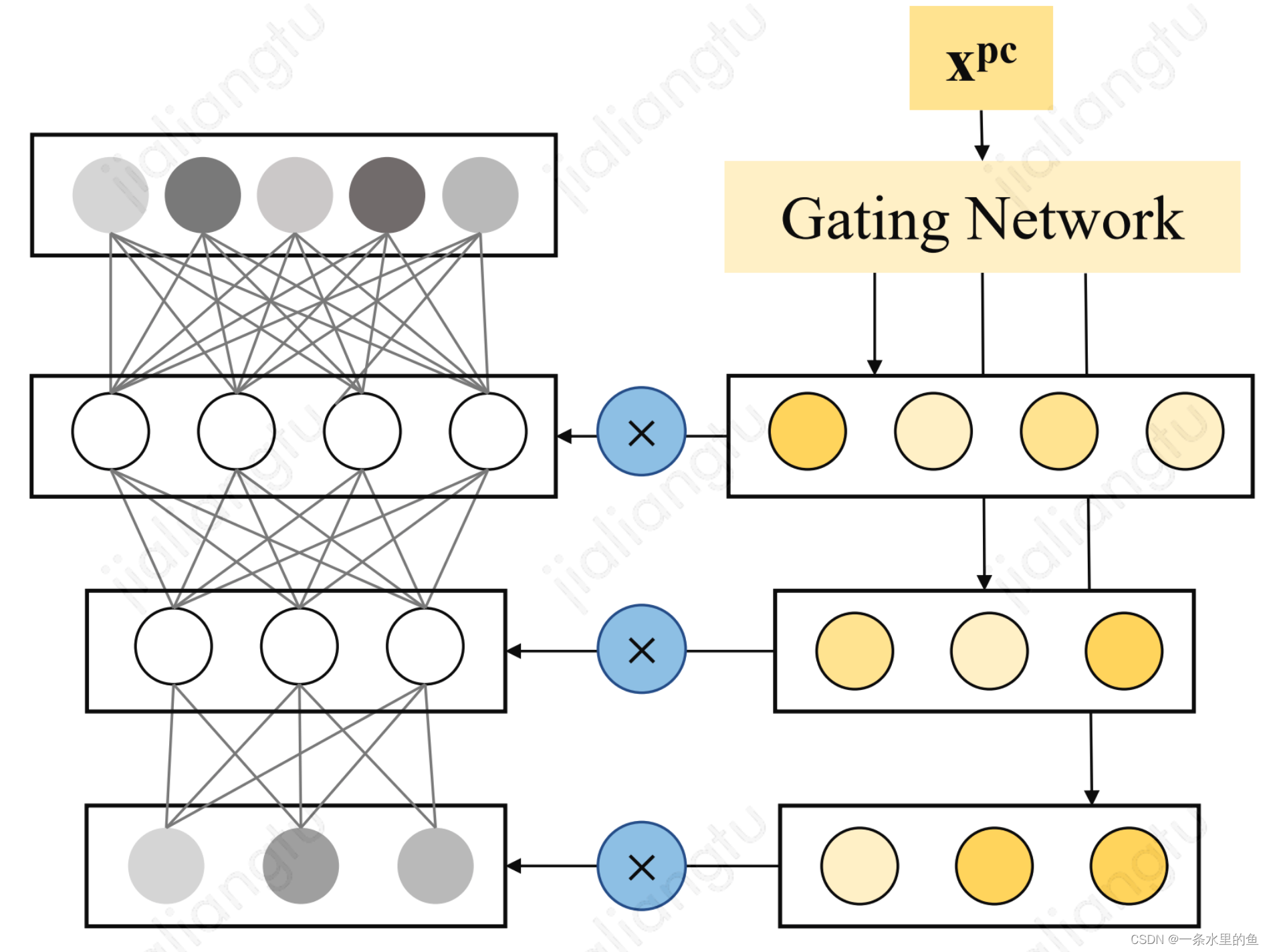
图3 全连接结构使用POSO
2.2.2 multi-head attention结构
multi-head attention中,单head的attention计算如式子(8)所示,使用POSO的原始计算过程如式子(9)所示,这种计算方式复杂,因此把对attention最后结果引入gate,转化到对attention中Q, K, V上。根据Q, K, V的角色不同,引入gate的程度也不同。由于快手在实现时,qurey的输入为除用户历史行为外的所有特征,包括了个性化编码特征在内,因此对其不引入gate;对于V,其值对attention的结果影响大,因此对V中的每个元素都引入gate;对于K,为了方便计算,仅引入一个gate,可以和Q直接计算进行softmax操作。单head的attention使用POSO的计算最终可表示为式子(10),其结构如图4所示。
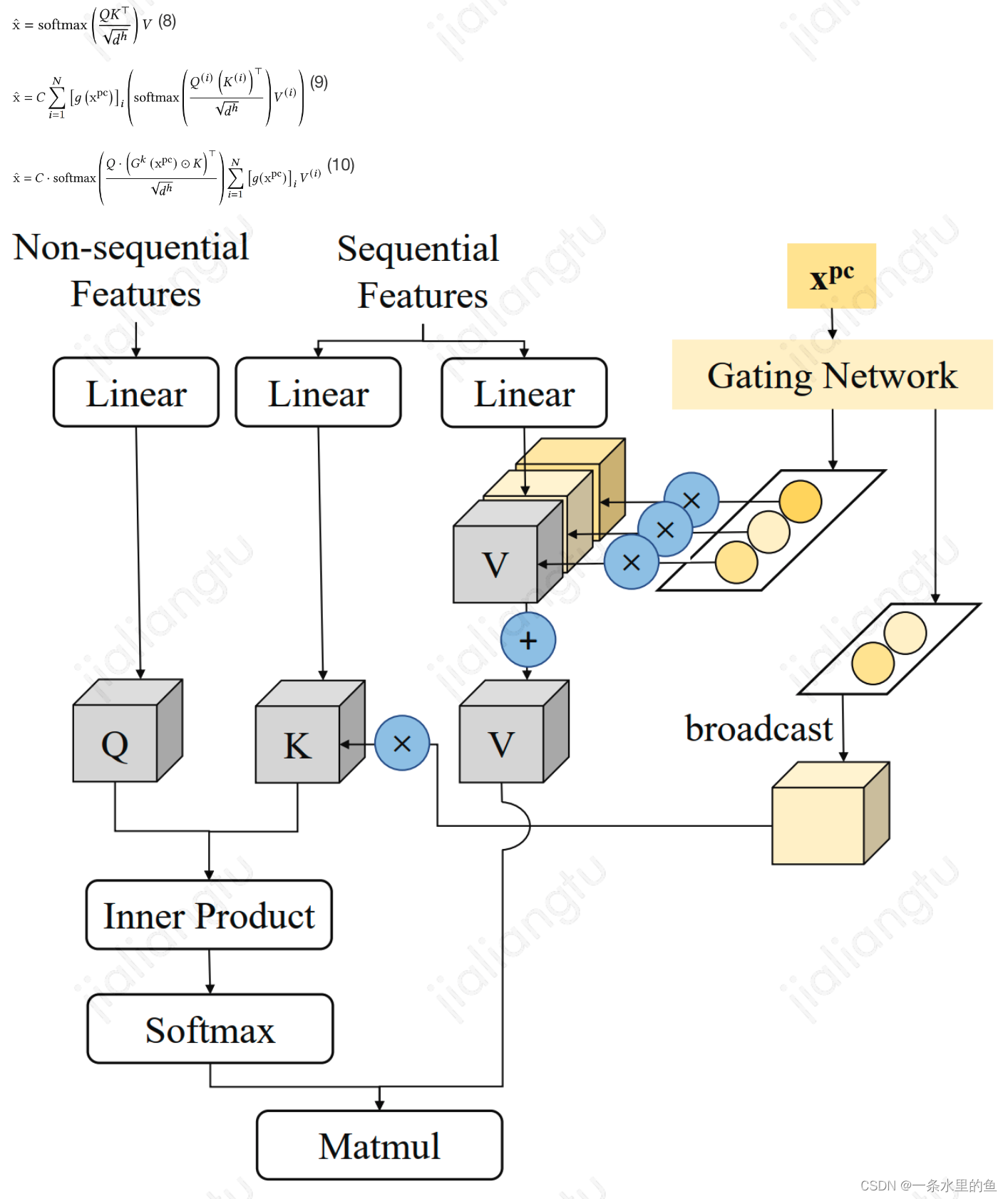
图4 multi-head attention结构使用POSO
2.2.3 MMoE结构
MMoE结构中使用POSO的原始计算如式子(11)所示,其中i、j、t分别为个性化gate、expert和task的下标。可以看出,所有expert共享个性化gate,对此不妨令每个expert有其各自的个性化gate,因此计算过程可表示为式子(12);令,则计算过程可表示为式子(13), 取值N时,则可利用按位乘提高计算效率,此时模型结构如图5所示。在实际使用过程中,可根据式子(11)对MMoE进行非简化的POSO方式,也可使用图5所示的方式。
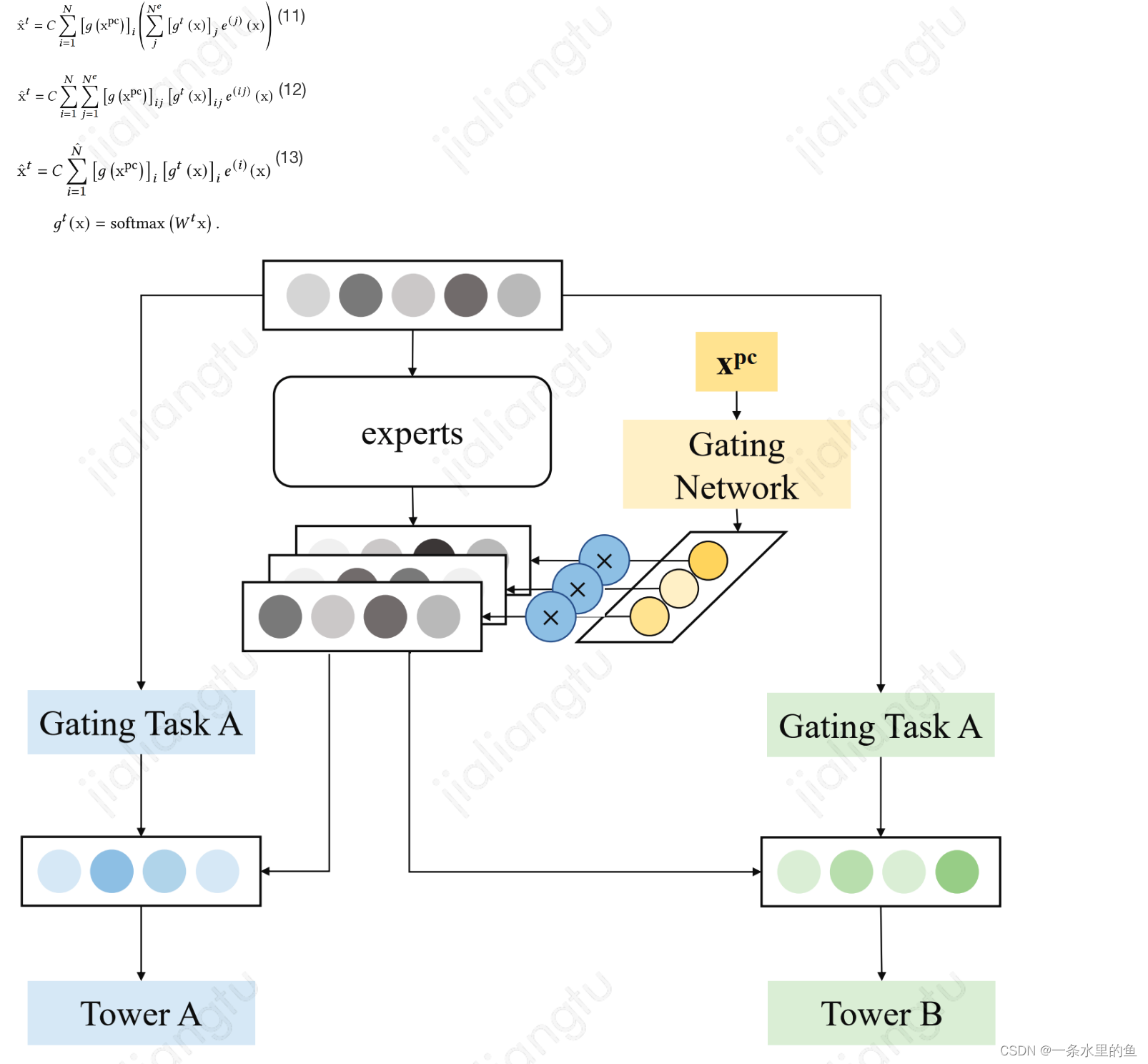
图5 MMoE结构使用POSO
论文以全连接、multi-head attention和MMoE为例,对其使用POSO思路,业界还有很多其它模型结构和模块,都可采用类似的推导过程,得到使用POSO后的计算方式。
2.3 优缺点
POSO的设计和实现简单优雅,具备以下优点:
- 实现了模型结构的个性化;
- 不仅对用户冷启问题有效,还可扩展到其它业务维度带来的非均衡分布样本问题;
- 灵活性好,适用于各种模型结构和模型中单个或多个模块;
- 实现成本低,可复用业务当前使用的模型,且通过按位乘实现,代码实现简单,计算消耗资源少;
- 对上下游友好,其输入输出和原有模型保持一致,不需要进行模型架构的调整。
至于POSO的缺点,我还没想到什么明显的点,欢迎有想法的朋友补充。
3 实际应用
我在工作中应用POSO思路,取得了明显的效果,期间有一些尝试和思考,是论文中没有提及的,也是大多数论文的风格,很少提到在实际应用中的一些落地经验和思考。
3.1 实现细节
POSO的代码实现很简单,只需要把对应gate的输出和模型已有输出按位相乘即可。
3.1.1 gate输出层函数
POSO中gate的输出层函数使用sigmoid。不同于一般gate输出会使用softmax,这种情况往往是输出维度少且需要归一化,如MMoE中task的对expert的gate。POSO中维度多,使用softmax容易导致权重集中到某些维度,也容易造成每个维度的权重小,模型难学的问题。Sigmoid函数输出在0-1之间,和权重输出的要求相符,且各个维度独立,不受其他维度影响。
3.1.2 输出期望
模型中使用POSO的每层的输出,由gate输出和原有输出按位相乘,由于gate输出是经过sigmoid函数得到,其期望为0.5,因此层输出的期望也会相应缩小一倍,为了保持输出期望和原有保持一致,在按位乘后,再乘以2,以解决期望缩放的问题。
3.2 gate优化
POSO的核心在于gate的使用,实现不同,带来的效果存在很大的差异。我在具体应用过程中,对于gate做了一些优化尝试,有些有效果,有些没有明显效果。
3.2.1 gate网络
实际应用过程中,gate的网络学习的效果好坏,对整个模型效果有非常关键的作用。大多数论文在应用gate时,网络非常简单,一般是使用一层线性变化,然后接softmax或sigmoid输出。这时候gate的非线性能力弱,如果模型需要学习复杂的函数,这时候线性能力往往不够,需要加强gate的非线性,以提高gate网络的能力,减小模型学习难度。
在POSO应用过程中,gate仅使用一层线性变换,带来的效果微弱,不显著。通过使用一层非线性变换,增加gate网络的非线性,模型带来的线上效果显著提升。
3.2.2 field-wise or bit-wise
POSO中的个性化gate可以作用于任何层,对于field-wise还是bit-wise的探索,仅限于embedding到第一层dense层这部分。
除去embedding层之外的其它层,实际含义已经消失,不存在field的概念,均使用bit-wise按位相乘,而embedding层输入给第一层dense层,embedding存在field的概念,在输入到dense层之前,是按field-wise对其相乘,还是bit-wise对其相乘,其中涉及到field信息和模型容量两个方面对模型的影响。
使用field-wise相乘,可以保留embedding的field信息,需要的参数量少,因此模型容量小,而使用bit-wise相乘,需要的参数量大,模型容量增加,两者对模型的影响来自不同方面。实验结果表明,使用field-wise效果更好,虽然相比bit-wise的模型容量减小,但其底层保留的field信息量,可以弥补模型容量带来的损失。
3.2.3 gate输入
根据论文的思路,gate的输入是用户个性化编码相关的特征,其核心在于需要体现用户的差异性。
3.2.3.1 非均衡和均衡
对于非均衡分布的特征,最直观的想法则是类似是否新用户、用户活跃度之类的特征。
1) 用户活跃度
我最初使用用户活跃度特征,没有明显效果,这里的问题可能和用户活跃度特征与用户真实活跃情况之间的gap,也就是用户活跃度的特征表达准确性的问题,而对于这类没有标准答案的特征,其准确性也很难评判,要修正特征计算也没有标准,因此换一种思路,利用uid特征。
2) uid
使用uid特征时,我最初担心新浅用户的uid特征没学好,将其作为gate输入,模型不好学,但实验证明,我的担心是多余的,这里我的分析是,uid没学好也是一种信息,模型可以顺利捕捉到这种信息。gate输入使用uid的效果很明显,带来了显著的线上提升。
3) uid+用户基础信息
在应用POSO时,我还没有体会到非均衡特征的重要性,因此在gate输入为uid取得效果之后,想进一步在gate输入中加入用户基础信息,以增加模型结构对用户的个性化响应,但效果不仅没有加强,反而削弱了。
这里就体现出gate输入中,特征在总体样本中非均衡分布的重要性。
这是从宏观层面讲,而从模型具体运作角度分析,我对gate经过sigmoid在embedding层的输出做了分析,发现加入用户基础信息后,多个维度的输出均趋向饱和,相当于这些维度已经学不出区分度。根据此,再对gate输入的uid和基础信息的norm做分析,发现基础信息的norm是uid的norm的几个数量级,因此采用了两种思路缓解gate输出饱和的问题。
一种思路是对基础信息,在gate输入中新学embedding,不和主网络共享。另一种思路是对gate输入使用Layer normlization,两种方法对gate输出的饱和度均有所缓解,但离线训练auc始终没有gate仅使用uid高,因此就没有进行线上对比,有兴趣的朋友可以上线试一试。
在gate中使用用户基础信息,预期是想让模型学到不同基础画像用户群的个性化响应,但从实际效果看,加上均衡分布的特征后,会减弱非均衡特征所表征的个性化信息编码能力,从而导致效果变差。
3.2.3.2 输入多维度
在gate输入为非均衡特征的思路下,其不仅仅局限于用户侧,对作者侧也是可行的。用户有冷启问题,作者也有冷启问题,而且作者冷启对于内容消费场景的生态,是非常重要的。
在这种思路下,对gate的输入新增作者id,实际没有带来收益。而其他同事在另一个数据量大很多的场景,取得了相应的收益。
在gate输入中新增作者id,相当于增加了模型的学习维度,只有uid时只需要学对于用户的个性化响应,而增加作者id时,既需要学用户侧,也需要学作者侧,假设用户数量为M,作者数量为N,则模型需要学的个性化响应数量级从M增加到M*N,模型学习难度增加。
另一个场景取得效果,和该场景数据量有关,数据量决定了模型的天花板。在我这个场景下,当前的数据量可能还无法支撑模型学习多维度的个性化响应,之后数据量增加到一定阶段,可以尝试。
除了数据量层面,在gate层面也可以做对应的调整,可以加强gate网络的能力,多引入一层非线性操作,这种思路也需要线上验证。
3.2.4 gate作用层
gate可以作用于多层和多个模块,在实际使用过程中,可根据具体需要而定。
3.2.4.1 task层
我在实际应用时,基础模型为share-bottom的多目标结构,仅针对于sharebottom层做了POSO操作,而task层没有。
这种实现进行了实验对比,在task层也加上POSO操作后,提升非常微弱,相比于新增的参数量,收益非常小,聊胜于无,因此最终并未在task层作用。这和论文中提到的,POSO希望通过原始特征而非二手加工后的特征来加强个性化,是吻合的。特征到task层时,经过了多层的提取,得到的是更高级的表征,其作用效果不如在底层粗糙特征时。
3.2.4.2 attention模块
attention模块也可使用POSO,我这里没有进行尝试,依据我对自己业务的仅有经验,在attention部分使用POSO,收益会非常微弱,因此就没有投入精力进行,有兴趣的朋友可以试一试。
3.3 冷启和非冷启用户效果对比
POSO的使用,不仅对冷启用户有效果,对非冷启用户也有效果,论文中也提到了这点。这得益于模型本身的设计,其效果是模型结构对用户的个性化响应,因此不管用户是冷启还是非冷启,利用POSO都可以使模型结构产生个性化的响应。
两者效果对比,之所以冷启用户效果明显,是因为冷启用户效果提升的空间大,而非冷启用户的空间小,类似于从90分到100分和从20分到60分的难度差异。
3.4 attention的query
快手使用的attention是multi-head的形式,其输入是用户行为历史除外的所有特征。我在POSO相关工作中并未对attention的query调整,而是在另一个工作中,ctr模型特征交叉结构总结与业务应用和思考,在attention的query中加入用户基础信息特征,线上有相应的收益,但因为一些其它原因,对query这部分的改动并未上线。
在attention的query中加入用户的一些相关特征,为什么会有效果?这里主要和用户兴趣表征有关系。对单个用户单次推荐而言,query中不管增加user的什么信息都不影响其结果,因为对这个用户而言,query是确定的,不存在差异;但对多个用户或者用户的多次请求而言,则有差异了,因为用户的兴趣表征发生了变化。通过在query中增加一些用户侧的信息,可以利用基础信息的泛化,补充一些用户兴趣,尤其在历史行为序列长度短的情况下,用户的历史有限,表达出的兴趣也有限,而通过具有相同特征的用户的兴趣补充,可以捕捉到由于长度限制而没有表达出来的用户兴趣。
reference
[1] POSO: Personalized Cold Start Modules for Large-scale Recommender Systems https://arxiv.org/abs/2108.04690.
















 3014
3014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









