







一、聚类的基本知识
1、基本概念
1、聚类算法的类型:无监督学习
2、聚类的概念:对于大量未知标签的数据集,根据数据的特征属性X划分为不同的类别(蔟),类别(蔟)内数据相似度高,类别
间的相似度较小。
3、聚类样本的相似度:样本项之间的相似度,有时候也称为样本间的距离。
4、聚类算法与分类算法的区别:
• 分类算法是有监督学习,基于有标注的历史数据进行算法模型构建
• 聚类算法是无监督学习,数据集中的数据是没有标注的
2、样本相似度的计算
(1)闵可夫斯基距离(Minkowski)
闵可夫斯基距离(Minkowski)
•当p为1的时候是曼哈顿距离(Manhattan)
•当p为2的时候是欧式距离(Euclidean)
•当p为无穷大的时候是切比雪夫距离(Chebyshev)

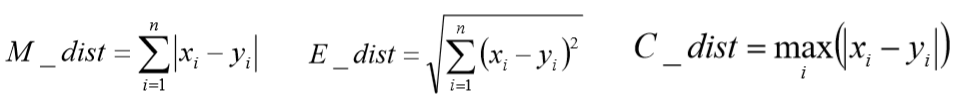
(2)夹角余弦相似度(Cosine) --------------- 为了解决欧几里得距离局限性

- 夹角余弦相似度

(3)杰卡德相似系数(Jaccard)、Pearson相关系数

3、各个聚类方法的区别

二、KMeans聚类算法
- KMeans算法的理解

1、基本的KMeans聚类算法
1、KMeans算法的特点:
给定一个有M个对象的数据集,构建一个具有k个簇的模型,其中k<=M。
满 足以下条件:
• 每个簇至少包含一个对象
• 每个对象属于且仅属于一个簇
• 将满足上述条件的k个簇成为一个合理的聚类划分
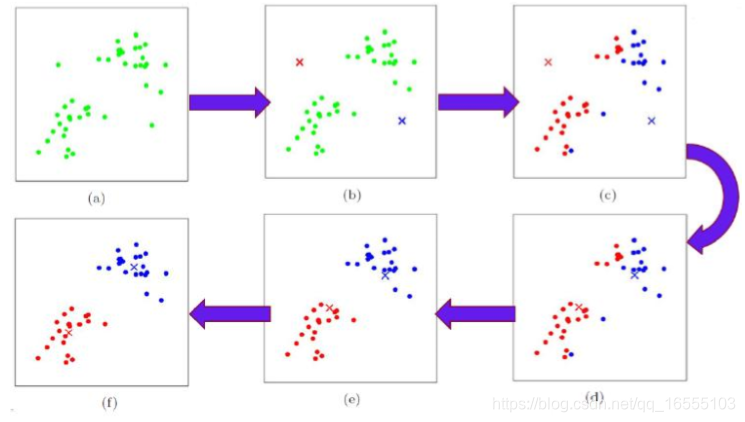
2、KMeans算法的步骤:
1、给定k值(通过手肘法+轮廓系数+实际业务确实)和 k个蔟中心点的初始值(普通KMeans算法是随机选择的)
2、计算每一个样本与这k个蔟中心点的距离(一般是欧几里得距离),取最小的那个蔟中心点的距离,将该样本划分到该蔟内
,计算所有的样本并划分蔟类型,将每一个蔟中心点用该蔟内部的样本坐标的均值来代替。 ----- 因为蔟中心点更新为
均值可以使得当前情况的损失函数最小
3、循环迭代上述步骤2,直至达到终止条件。
3、KMeans算法的终止条件:
1、迭代次数
2、最小平方误差MSE(样本到中心的距离平方和)
3、簇中心点变化率
4、K值的选择:
-1. 基于手肘法选择出一个K值的范围,也就是在这个K数字之前,变化剧烈,但是之后,变化平缓
-2. 结合轮廓系数确定一个相对比较明确的K值
sklearn.metrics.silhouette_score
-3. 结合业务选择适合的K值- KMeans聚类算法迭代图解:
- KMeans聚类算法损失函数:

2、KMeans的适用场景与优缺点
1、KMeans算法的适用场景:它比较适合服从高斯分布的样本数据集的划分
2、KMeans算法的优缺点:
优点:
• 理解容易,聚类效果不错
• 处理大数据集的时候,该算法可以保证较好的伸缩性和高效率
• 当簇近似高斯分布的时候,效果非常不错(也就是说它对于圆环数据或月牙数据 等 聚类较差)
缺点:
• KMeans聚类算法对异常数据比较敏感
• KMeans对初始值敏感:① k值(初始蔟的数量) ② 蔟中心点初始值(造成差异的原因是由于随机了多个蔟中心点落在一个蔟内部)
• 不适合发现非凸形状的簇或者大小差别较大的簇
• 不适合蔟与蔟相离较近的聚类
3、注意:
• KMeans算法的结果(蔟类型下标)可能不会遵循原数据样本所属蔟的下标 - KMeans对异常数据敏感

- KMeans对初始值敏感


3、KMeans的伪代码
https://blog.csdn.net/qq_16555103/article/details/88957307#t28 ------------- KMeans的伪代码
4、KMeans的优化算法
优化目的:
1、为了解决初始值影响的问题 ------ 二分KMeans、KMeans++(1)二分K-Means算法
1、二分KMeans特点:解决K-Means算法对初始簇心比较敏感的问题,二分K-Means算法是一种弱化初 始质心的一种算法
2、二分KMeans 具体思路步骤:
1、 将所有样本数据放回到一个蔟队列中
2、 队列中的一个蔟进行 k = 2 的KMeans算法聚类形成两个子蔟,将他们放回到蔟队列中
3、重复这个步骤,直到中止条件达到(主要是聚簇数量)
3、选取队列蔟二划分的条件:
1、 选取蔟距离平方和SSE 最大的蔟进行二划分(优先)。
2、 选取样本较多的蔟进行二划分。
- 二分K-Means算法图解:

(2)K-Means++算法
1、K-Means++算法优化目的:
解决K-Means算法对初始簇心比较敏感的问题。
2、与普通KMeans算法的区别:
K-Means++算法和KMeans算法的区别主要在于初始的K个中心点的选择方面,K-Means算法使用随机给定的方式。
3. K-Means++算法采用下列步骤给定K个蔟初始点:
k-means++算法选择初始聚类中心的基本原则是:初始的聚类中心之间的相互距离要尽可能的远。它选择初始聚类中心的步骤是:
(1)从输入的数据点集合中随机选择一个点作为第一个聚类中心;
(2)对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x),并根据以下概率选择新的聚类中心。
(3)重复过程(2)直到找到k个聚类中心。
第(2)步中,依次计算每个数据点与最近的种子点(聚类中心)的距离,依次得到D(1)、D(2)、...、D(n)构成的集合D,其中n表
示数据集的大小。在D中,为了避免噪声,不能直接选取值最大的元素,应该选择值较大的元素,然后将其对应的数据点作为种子
点。 如何选择值较大的元素呢,下面是spark中实现的思路。
求所有的距离和Sum(D(x))
取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先用Sum(D(x))乘以随机值Random得到值r,
然后用currSum += D(x),直到其currSum>r,此时的点就是下一个“种子点”。
为什么用这样的方式呢?
我们换一种比较好理解的方式来说明。把集合D中的每个元素D(x)想象为一根线L(x),线的长度就是元素的值。将这些线
依次按照L(1)、L(2)、...、L(n)的顺序连接起来,组成长线L。L(1)、L(2)、…、L(n)称为L的子线。 根据概率的相关知识,如
果我们在L上随机选择一个点,那么这个点所在的子线很有可能是比较长的子线,而这个子线对应的数据点就可以作为种子点。
4、K-Means++算法的优缺点:
优点:
1、解决了KMeans的K个中心点初始化敏感问题
缺点:
1、计算量较大
2、由于聚类中心点选择过程中的内在有序性,在扩展方面存在着性能方 面的问题(第k个聚类中心点的选择依赖前k-1个
聚类中心点的值)
(3)K-Means||算法 ------------- 在KMeans++算法上的变种
1、K-Means||算法优化方向:虽然k-means++算法可以确定地初始化聚类中心,但是从可扩展性来看,它存在一个缺点,那就是它内
在的有序性特性:下一个中心点的选择依赖于已经选择的中心点。 针对这种缺陷,k-means||算法提供了解决方法。
2、K-Means||算法优缺点:
优点:
缺点:
3、 解决K-Means++算法缺点而产生的一种算法;
k-means∥ 主要思路在于改变每次遍历时的取样策略,并非按照 k-means++ 那样每次遍历只取样一个样本,而是每次遍历取样 O(k) 个
样本,重复该取样过程大约 O(log n) 次,重复取样过后共得到 O(k log n) 个样本点组成的集合,该集合以常数因子近似于最优解,
然后再聚类这O(klogn) 个点成 k 个点,最后将这 k 个点作为初始聚类中心送入Lloyd迭代中,实际实验证明 O(logn) 次重复取
样是不需要的,一般5次重复取样就可以得到一个较好的聚类初始中心。
(4)Canopy算法
1、Canopy算法的优缺点:
优点:
• 执行速度快(先进行了一次聚簇中心点选择的预处理)
• 不需要给定K值,应用场景多
• 能够缓解K-Means算法对于初始聚类中心点敏感的问题
缺点:
Canopy算法属于一种“粗”聚类算法,精度较低
2、Canopy算法的适用场景: ---------- 常常用于初次确定蔟中心点
• 先使用canopy算法进行“粗”聚类得到K个聚类中心点
• K-Means算法使用Canopy算法得到的K个聚类中心点作为初始中心点,进行“细” 聚类 - Canopy算法的具体过程

- Canopy算法的图解


三、 Mini Batch K-Means算法
1、Mini Batch K-Means基本概念:
Mini Batch K-Means算法是K-Means算法的一种优化变种,采用小规模的数据子集(每次 训练使用的数据集是在训练算法的时候
随机抽取的数据子集)减少计算时间,同时试图优化 目标函数;Mini Batch K-Means算法可以减少K-Means算法的收敛时间,而
且产生的结果效果只是略差于标准K-Means算法
2、算法步骤如下:
• 首先抽取部分数据集,使用K-Means算法构建出K个聚簇点的模型
• 继续抽取训练数据集中的部分数据集样本数据,并将其添加到模型中,分配给距离最近的聚簇中心点
• 更新聚簇的中心点值(每次更新都只用抽取出来的部分数据集)
• 循环迭代第二步和第三步操作,直到中心点稳定或者达到迭代次数,停止计算操作 ------- 注意:这个算法思想类似于SGD算法,
每次都是使用与上一次不同的抽样数据进行更新蔟中心点,可以重复更新循环多次
3、Mini Batch K-Means优缺点:
优点:
1、减少K-Means算法的收敛时间,而且产生的结 果效果只是略差于标准K-Means算法
2、
缺点:
4、Mini Batch K-Means适用场景:大量数据KMeans分类(效果比KMeans差一些)
四、聚类算法的衡量指标

1、聚类算法的衡量指标1

2、聚类算法的衡量指标-ARI

3、聚类算法的衡量指标-AMI

4、聚类算法的衡量指标-轮廓系数

五、其他聚类方法
1、层次聚类
凝聚的层次聚类:AGNES算法
分裂的层次聚类:DIANA算法2、层次聚类的优化算法:BIRCH算法
1、BIRCH算法(平衡迭代削减聚类法):
聚类特征使用3元组进行一个簇的相关 信息,通过构建满足分枝因子和簇直径限制的聚类特征树来求聚类, 聚类特征树其实
是一个具有两个超参数分枝因子和类/簇直径的高度平衡树;分枝 因子规定了树的每个节点的子女/样本的最多个数,而类直径
体现了对这一 类点的距离范围;非叶子节点为它子女的最大特征值;
2、Birch算法的特点:
1、由于三元组中包含 样本数与各个维度样本的特征值的和,因此该算法可以获得蔟中心点,可以预测新的数据。
2、Birch算法的优缺点:
优点:
• 适合大规模数据集,线性效率;
• 聚类特征树的构建可 以是动态过程的,可以随时根据数据对模型进行更新操作。
缺点:
• 只适合分布呈凸形或者球形的数据集、需要给定聚类个数和簇之间的相关参数;
- Birch图解
https://blog.csdn.net/qq_16555103/article/details/88957307#t29 ------- Birch图解
- Birch算法案例

3、密度聚类方法:
1、DBSCAN 算法
2、密度最大值聚类算法(MDCA)
4、谱聚类
1、谱分类的优缺点:
优点:
1、适用于任何形状的数据聚类
缺点:
1、计算时间较长六、KMeans的伪代码
聚类
=================================================
KMeans聚类伪代码
def fit(X, K, max_iter):
# 基于给定的X数据(X是一个m行n列的特征属性矩阵)和K值(数字)计算出各个簇的中心点
# 1. 随机K个簇中心点
centers = X[:K]
# 循环迭代更新
for iter in range(max_iter):
# 2. 计算样本属于哪个簇(需要遍历所有样本、需要计算每个样本到所有簇的距离、选择距离最小的簇作为当前样本的隶属簇)
T_K = {} # 以簇id为key,以属于这个簇的所有样本组合在一起的list集合做value
for x in X:
min_distance = inf
min_idx = None
# 遍历所有簇获取和当前样本距离最小的簇id
for idx in range(K):
# 获取idx对应的簇中心点
center = centers[idx]
# 计算簇中心到样本x的距离
distance = calc_distance(center, x)
# 和之前临时保存的样本距离进行比较,选择距离最近的数据进行缓存
if distance < min_distance:
min_distance = distance
min_idx = idx
# 将这个样本添加到这个簇中
T_K[min_idx].append(x)
# 3. 更新簇中心
for k in range(K):
# a. 获取属于当前簇的所有样本, tmp_x是list的集合
tmp_x = T_K[k]
# b. 遍历所有样本计算均值
center = tmp_x[0]
number = 1
for x in tmp_x[1:]:
center = center + x
number += 1
center = center / number
# c. 更新簇中心
centers[k] = center
return centers
基于python代码实现 KMeans聚类代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# 构建数据
datas,labels = make_blobs(n_samples=1000,n_features=2,centers=5,cluster_std=1.0,center_box=(-40,40),random_state=10)
# print(datas,datas.shape)
# print('数据对应的蔟的下标为:{}'.format(labels))
# fig = plt.figure()
# plt.scatter(datas[:,0],datas[:,1],c=labels,marker='o')
# plt.show()
print('代码开始 '+ '='*120)
# 1、给定k值,获取k个蔟的初始中心点
class K_means():
def __init__(self):
pass
def fit(self,X,k = 5,max_iter = 300,y=None,random = True,log = False):
'''
训练对象
:param X: 数据
:param k: 蔟的个数
:param max_iter: 迭代次数
:param y: 标签
:param random:
:param log: 是否显示过程
:return:
'''
X = np.array(X)
self.X = X
self.k = k
self.max_iter = max_iter
self.log = log
# 1、对应给定的k值,获得k个蔟的初始化中心点
ran_idx = np.random.randint(0,len(X),k)
center_init = X[ran_idx]
self.center = center_init
print('蔟中心的初始值为:{}'.format(self.center))
def get_distance(sample,center):
'''
计算样本得到中心点的距离
:return: 距离值
'''
sample = np.array(sample)
center = np.array(center)
distance = sum((sample - center)**2)
return distance
def update_center(samples):
'''
samples是一个蔟类型的value列表,内部元素全是numpy类型的数组样本,利用这些样本
更新当前蔟中心点坐标 为 蔟内样本的均值
:return: 当前蔟中心坐标的一维数组
'''
center = np.ones(samples[0].shape[0])
for sample in samples:
center += sample
center = center/len(samples)
return center
# 3、重复更新迭代max_iter次,可以得到最终的结果
for iter in range(self.max_iter):
# 2、计算每一个样本到每一个蔟中心的距离且取最小值,保存至字典中,key是蔟的索引,values是该蔟样本构成的列表
cluster = {}
for key in range(k): ------------- 创建字典,value是空的 []
cluster[key] = []
# print(cluster)
# 遍历所有样本的值,计算它与所有蔟中心的距离中的最小值,并保存到key为该蔟索引的列表中。
for sample in X:
for idx,center in enumerate(self.center):
# 计算该样本到蔟中心的距离
distance = get_distance(sample,center)
if idx == 0:
distance_min = [distance,idx] ------- 核心代码:初始化第一个距离值用于比较,同时保存它对应的蔟类型下标。
continue
if distance < distance_min[0]:
distance_min = [distance,idx] ------- 核心代码:与初始化距离值进行比较,同时保存它对应的蔟类型下标。
cluster[distance_min[1]].append(sample) ------- 核心代码:将改值添加到key为该蔟下标的字典的value的列表中。
# 更新蔟中心为样本的均值
for key in cluster:
# 跟新坐标点
self.center[key] = update_center(cluster[key])
if self.log:
print('KMeans算法更新迭代第{}次 时蔟中心的坐标结果是{}'.format(iter+1,self.center))
print('KMeans算法更新迭代第{}次时 蔟中心的坐标结果是{}'.format(self.max_iter,self.center))
def predict(self,X_test):
pass
def score(self):
pass
if __name__ == '__main__':
k_means = K_means()
k_means.fit(datas,k=5)七、聚类算法API使用:

1、KMeans算法API使用
from sklearn.cluster import KMeans
"""
def __init__(self, n_clusters=8, init='k-means++', n_init=10,
max_iter=300, tol=1e-4, precompute_distances='auto',
verbose=0, random_state=None, copy_x=True,
n_jobs=None, algorithm='auto')
参数:
n_clusters:给定簇的数目,也就是K值
init:给定初始化的方式,默认为kmeans++,可选k-means++和random,或者初始中心点的坐标。
n_init: 每次kmeans模型算法构建的时候,初始化多少组中心点
max_iter: 最大迭代次数
tol: 损失函数两次更新之间变化值小于该值的时候,结束模型训练
precompute_distances:是否在模型构建之前计算样本与样本之间的距离
"""
algo = KMeans(n_clusters=n_centers)
algo.fit(x)================================== Kmeans sklearn 代码 ========================================
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
# 创建高斯分布数据
x,y = make_blobs(n_samples=10000,n_features=10,centers=5,cluster_std=1.0,center_box=(-100,100),random_state=100)
print(x.shape,y.shape)
# 数据分割
x_train,x_test = train_test_split(x,test_size=0.2,random_state=0)
print(x_train.shape,x_test.shape)
# 构建模型
k_mean = KMeans(n_clusters=5)
# 训练模型
k_mean.fit(x_train)
# 模型评估
print('模型测试集预测值属于哪个蔟的id:{}'.format(k_mean.predict(x_test))) ------- 结果是一个一维数组,
可用作 k_mean.cluster_centers_ 的索引 用于取当前样本的蔟中心坐标点
print('模型测试集损失函数的相反数:{}'.format(k_mean.score(x)))
print('将测试集的每一个样本到蔟中心的距离:{}'.format(k_mean.transform(x_test)))
print('模型中心值:{}'.format(k_mean.cluster_centers_)) -------- 结果是一个二维数组
print('模型训练数据据对应的蔟下标:{}'.format(k_mean.labels_)) -------- 结果是训练集下标一维数组
print('模型训练数据损失函数最小值:{}'.format(k_mean.inertia_))
# 手肘法选择k值
distinct = []
for k in [2,3,4,5,6,7,8,9,10]:
k_means = KMeans(n_clusters=k)
k_means.fit(x)
distinct.append(k_means.inertia_)
print(distinct)
fig = plt.figure()
plt.plot([2,3,4,5,6,7,8,9,10],distinct,'ro-',label = 'k_distinct')
plt.legend()
plt.show()2、 MiniBatchKMeans 算法 API
class sklearn.cluster.MiniBatchKMeans(n_clusters=8, init='k-means++', max_iter=100,
batch_size=100, verbose=0, compute_labels=True, random_state=None, tol=0.0,
max_no_improvement=10, init_size=None, n_init=3, reassignment_ratio=0.01)
'''
batch_size=100 --------- 抽样小批量 更新蔟中心点的 样本数
'''
3、层次聚类API
========================== 凝聚的层次聚类 ===================================
class sklearn.cluster.AgglomerativeClustering(n_clusters=2, affinity='euclidean',
memory=Memory(cachedir=None), connectivity=None, compute_full_tree='auto', linkage='ward',
pooling_func=<function mean>)
4、BIRCH ------ 凝聚层次聚类的优化算法
========================== 凝聚的层次聚类优化算法 Brich算法 ==================
class sklearn.cluster.Birch(threshold=0.5, branching_factor=50, n_clusters=3,
compute_labels=True, copy=True)- BIRCH 算法图解

5、密度聚类算法 (DBSCAN) API
class sklearn.cluster.DBSCAN(eps=0.5, min_samples=5, metric='euclidean', algorithm='auto',
leaf_size=30, p=None, n_jobs=1)
6、谱分解的API
对象形式:
class sklearn.cluster.SpectralClustering(n_clusters=8, eigen_solver=None,
random_state=None, n_init=10, gamma=1.0, affinity='rbf', n_neighbors=10, eigen_tol=0.0,
assign_labels='kmeans', degree=3, coef0=1, kernel_params=None, n_jobs=1)
函数形式:
sklearn.cluster.spectral_clustering(affinity, n_clusters=8, n_components=None, eigen_solver=None,
random_state=None, n_init=10, eigen_tol=0.0, assign_labels='kmeans')















 2268
2268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









