








一、为什么使用深度学习框架
我们逐渐熟悉使用Python和Numpy等库编写深度学习代码,但事实上从零开始实现整个过程并不现实,幸好有很多很优秀的深度学习框架,帮助你实现这些模型。学习具体实现原理对调用框架是非常有帮助的,类比你计算矩阵乘法,你学会了使用线性代数库进行运算,同时你也明白矩阵相乘到底是怎样一个计算过程,使用框架使得你的工作更加实用和高效。
二、主流深度学习框架

选择框架时需要考虑的三个原则:
- 易于编程
不论是在开发部署还是调试上,用简洁的语言编程是非常有必要的 - 运行速度
大型网络会花费大量时间训练,框架的运行速度一定需要考虑 - 真正开源
在选择框架时,要看准公司的发展状况,有些公司现在框架开源,但是未来可能将框架的功能面向公司内部,那时候你会发现自己吃了大亏。
三、TensorFlow
举个例子,我们有损失函数:
J
(
w
)
=
w
2
−
10
w
+
25.
J(w)=w^2-10w+25.
J(w)=w2−10w+25.
要计算优化得到其最小值及
w
w
w的取值。
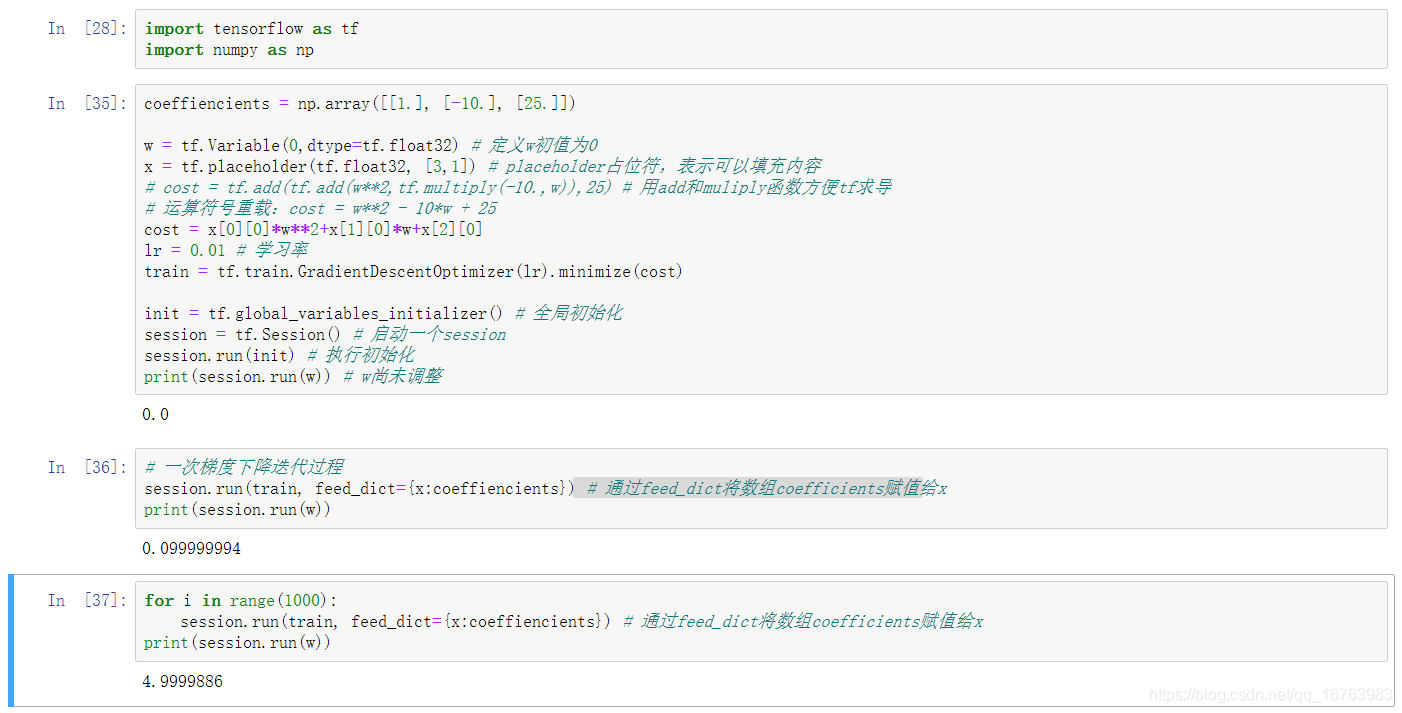
代码如下:
import tensorflow as tf
import numpy as np
coeffiencients = np.array([[1.], [-10.], [25.]])
w = tf.Variable(0,dtype=tf.float32) # 定义w初值为0
x = tf.placeholder(tf.float32, [3,1]) # placeholder占位符,表示可以填充内容
# cost = tf.add(tf.add(w**2,tf.multiply(-10.,w)),25) # 用add和muliply函数方便tf求导
# 运算符号重载:cost = w**2 - 10*w + 25
cost = x[0][0]*w**2+x[1][0]*w+x[2][0]
lr = 0.01 # 学习率
train = tf.train.GradientDescentOptimizer(lr).minimize(cost)
init = tf.global_variables_initializer() # 全局初始化
session = tf.Session() # 启动一个session
session.run(init) # 执行初始化
print(session.run(w)) # w尚未调整
# 一次梯度下降迭代过程
session.run(train, feed_dict={x:coeffiencients}) # 通过feed_dict将数组coefficients赋值给x
print(session.run(w))
for i in range(1000):
session.run(train, feed_dict={x:coeffiencients}) # 通过feed_dict将数组coefficients赋值给x
print(session.run(w))
- 通常会见到这种
with结构的语法,左右表达式的效果基本一致,with语法防止内循环出现错误
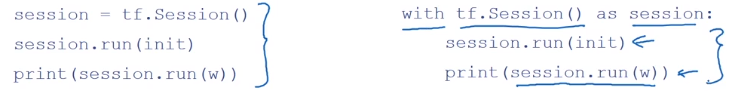
- TensorFlow已经内置了必要的反向传播函数,我们提供了前向传播计算和损失函数后可以自动求导得到反向计算结果。
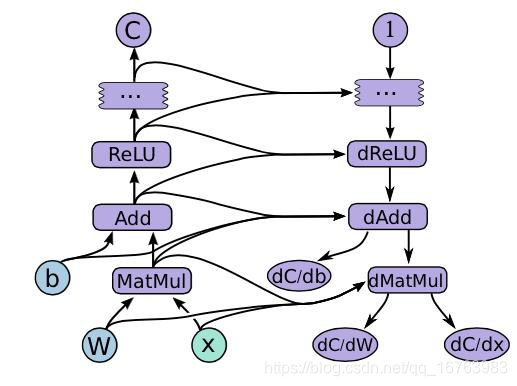
- 我们学习的计算图和TensorFlow说明中的图不太一样,计算图用值表示节点,而TensorFlow中用符号表示节点。
计算图

Tensorflow结构图















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











