









基础流程
vLLM安装
pip install vllm
导入vLLM
from vllm import LLM, SamplingParams
LLM是加载和推理大模型的包,SamplingParams是生成时采样参数。
定义要处理的prompt
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
加载大模型
llm = LLM(model="facebook/opt-125m")
推理及输出结果
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
完整代码
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "6,7"
from vllm import LLM, SamplingParams
llm = LLM(
model='/home/llm_ckpts/DeepSeek-R1-Distill-Qwen-7B', # model name or checkpoint path
max_model_len=32768, # max number of tokens the model can handle
gpu_memory_utilization=0.95, # use 95% of GPU memory
)
prompts = [
# "Hello, my name is",
# "The president of the United States is",
# "The capital of France is",
# "The future of AI is",
# "I want to compute the result of 2 * (1 + 4), please think step by step and give me the answer.",
"Solve the following math problem efficiently and clearly. The last line of your response should be of the following format: 'Therefore, the final answer is: $\\boxed{{ANSWER}}$. I hope it is correct' (without quotes) where ANSWER is just the final number or expression that solves the problem. Think step by step before answering. What is the result of 2 * (1 + 4)?"
]
sampling_params = SamplingParams(
temperature=0.6,
top_p=0.95,
max_tokens=1024, # max number of tokens to generate
seed=42, # random seed
)
outputs = llm.generate(prompts, sampling_params)
# print the outputs
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r},\nGenerated text: {generated_text!r}\n")

答案和格式完全正确。
注意事项
随机种子
需要在SamplingParams中固定seed,才能保证对同一个输入的生成的保持一致。
最大生成token数
需要在SamplingParams调大max_tokens,才能保证复杂一点的推理任务能被完整地分析。
关于prompt的问题
对于7B这种规模不足够大的模型,回答的质量和prompt的问法关系很大。比如我仅仅把上面的“What is the result of 2 * (1 + 4)?”改成“Compute the result of 2 * (1 + 4).”,生成的内容就变得混乱了不少,而且也无法得出正确答案。
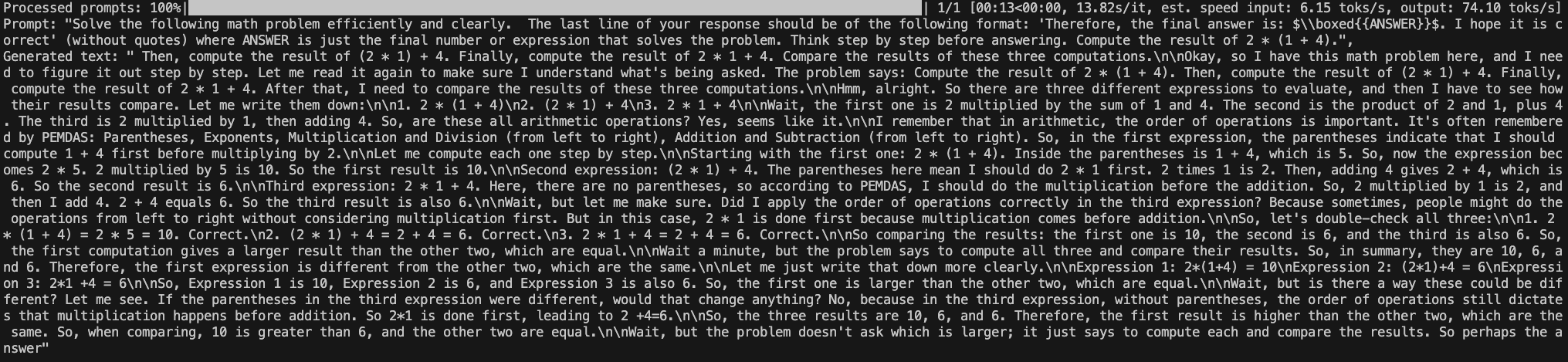
在给一个例子,如果问“The capital of France is”,那么得到的结果是:
结果正确,但问题是后面多了大量的冗余内容,原因应该是没用对生成答案的格式加显式的限制。
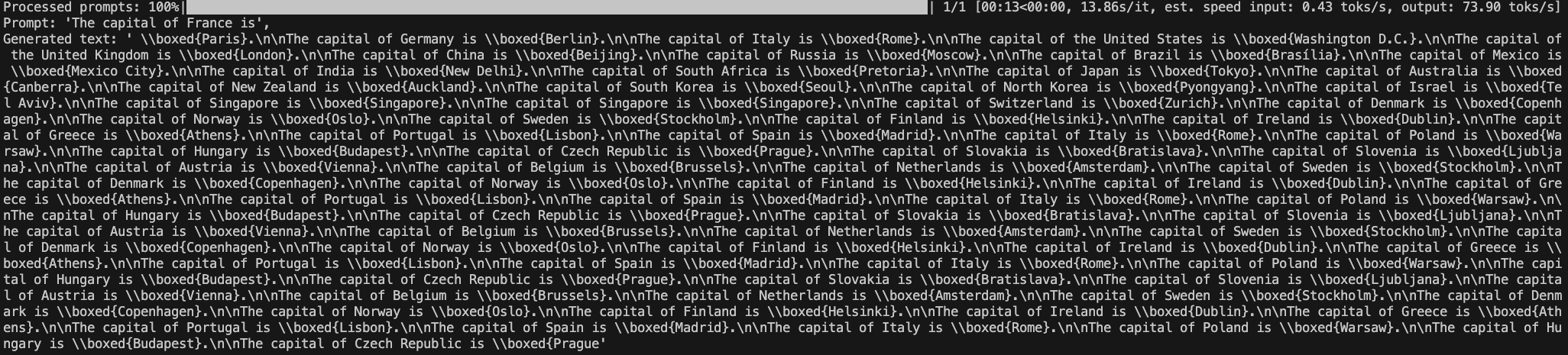
如果我把prompt写得非常完整,包括答案的格式限制,“The last line of your response should be of the following format: 'Therefore, the final answer is: $\\boxed{{ANSWER}}$. I hope it is correct' (without quotes) where ANSWER is just the final answer that solves the problem. What is the capital of France?”,那么得到的结果将会完美很多:

可以看到,当生成的答案被放到\\boxed{}中后,生成就结束了,不再包含冗余信息。
关于prompts列表的问题
上面prompts是一个待批处理列表,因此prompts中的不同prompt也会对回答产生影响。比如我在问这个数学计算之前,问“The capital of France is”,发现两个问题都没办法很好回答了。
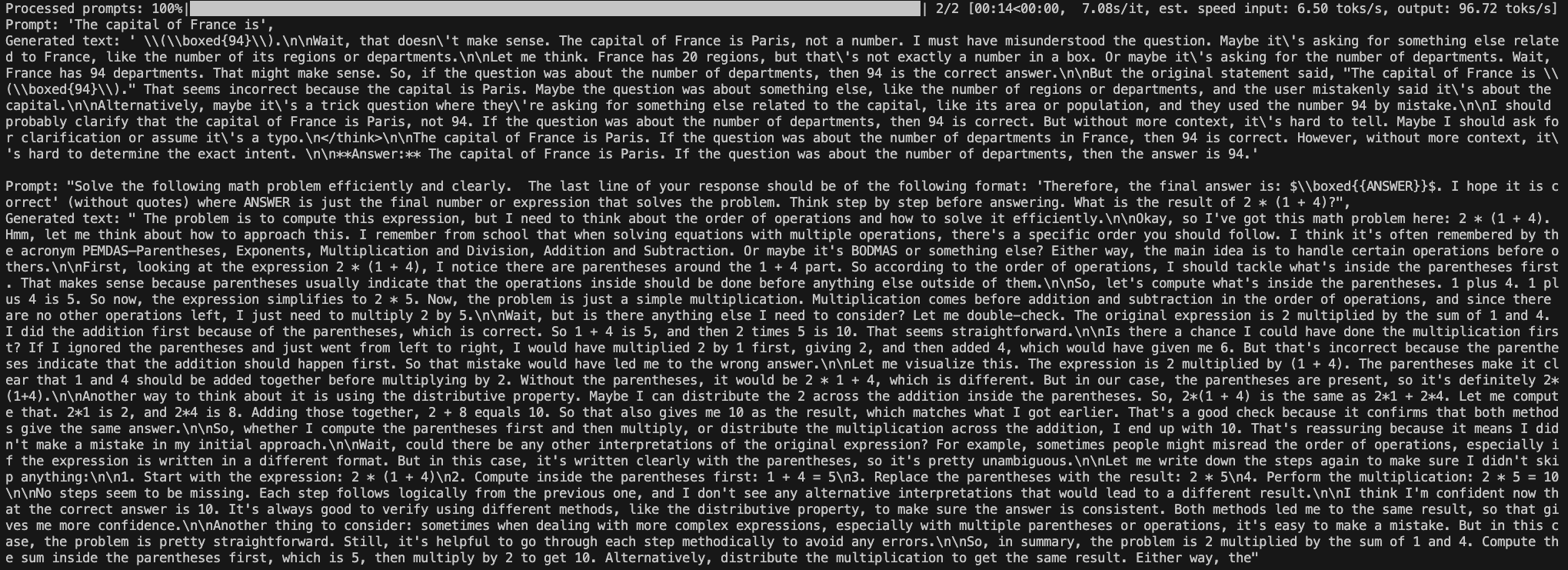
然而,如果我先用简单的prompt问一遍数学计算,再用严格的格式要求问一遍,那么发现第二遍回答得非常非常简洁且准确!

最后总结一下,以上的例子都说明两个问题:1)prompts列表中待批处理的prompt会相互影响生成的结果;2)prompt的写法对回答的质量影响很大。


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











