










一、概述
title:Small Models are Valuable Plug-ins for Large Language Models
论文地址:https://arxiv.org/abs/2305.08848
代码:https://github.com/JetRunner/SuperICL
1.1 Motivation
- 大语言模型想GPT-3和GPT-4权重没有开放出来,他们的参数量级太大没法部署到通用的硬件上面,导致在大规模的监督数据上做tuning非常具有挑战性。
- 因为上下长度的限制,导致In-Context Learning(ICL)只能利用一小部分监督样本数据。
1.2 Methods
- 本文提出了Super In-Context Learning(SuperICL),能够让黑盒的LLMs和本地的fine-tuned小模型一起结合,在监督任务中取得优越的性能。
1.3 Conclusion
- 本文提出了SuperICL方法,可以融合llm api和本地的fine-tuned插件模型。
- SuperICL可以提高性能,超过最先进的微调模型,同时解决上下文学习的不稳定性问题。
- SuperICL可以增强小型模型的功能,例如多语言和可解释性。
1.4 limitation
- 时间和成本:时间是两个模型的和,同时调用llm api的成本也比较高。
- 本地plug-in模型对抗攻击的能力比较弱,也会被SuperICL继承下来,如果插件模型受到攻击,整个系统的效果可能也会低于ICL。
- 只评估了文本分类的效果,没在摘要,QA,semantic parsing任务上做评估。
二、详细内容
1. ICL与SuperICL对比【实现方案】
workflow of ICL
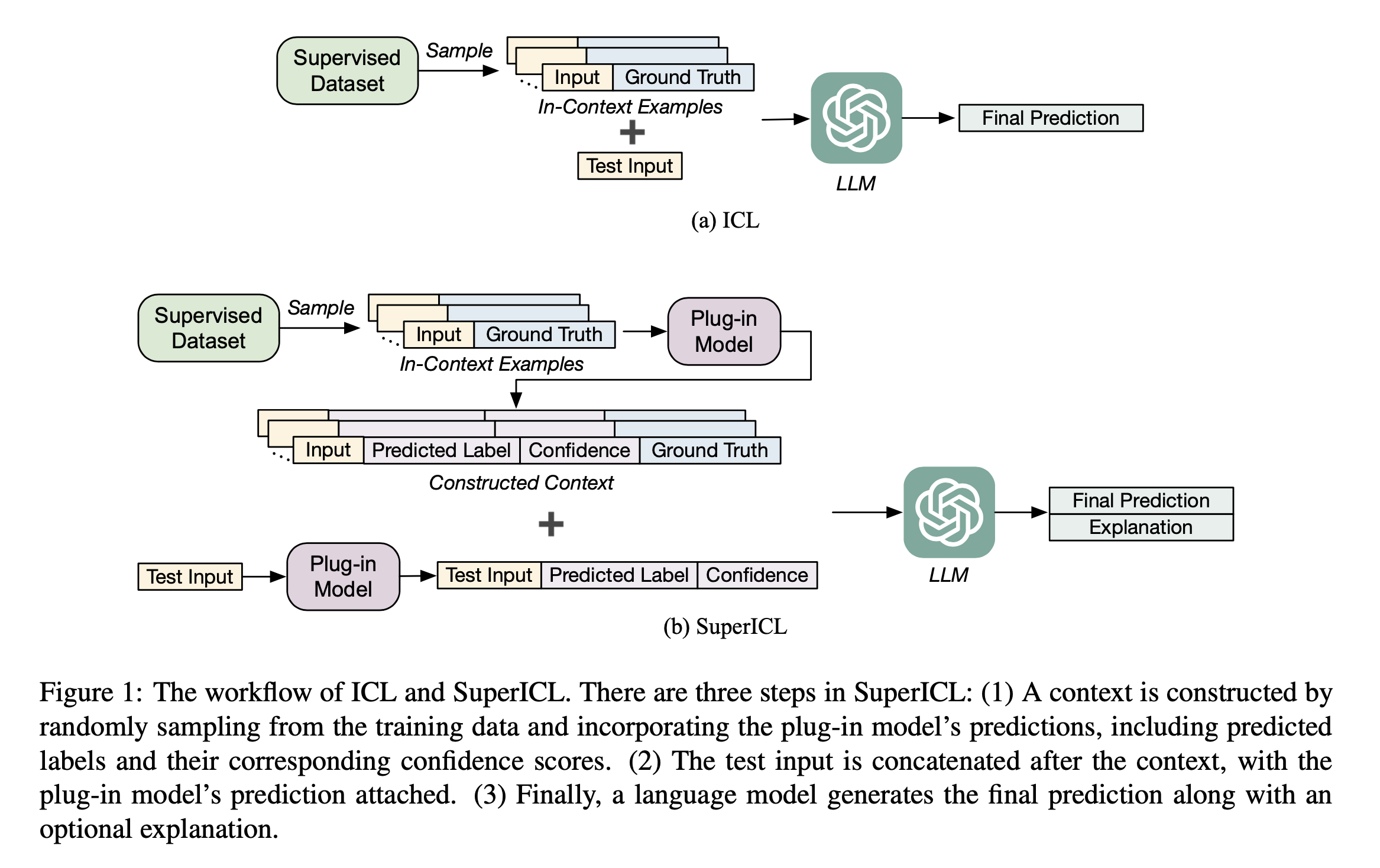
算法过程

SuperICL步骤:
- 随机sampling训练样本,并且利用plug-in models预测label和置信度
- 测试样本也通过plug-in models预测结果,然后拼接到上述context的后面
- 最后LLM模型预测最终的结果(如果最终结果和plug-in 模型的结果不一致,可以要求大模型进行解析)
2. 构造的样本举例

- 基于本地监督数据训练一个插件的模型(见过本地很多监督数据)
- 融合本地插件模型的结果进行预测
3. 在GLUE数据集上的结果
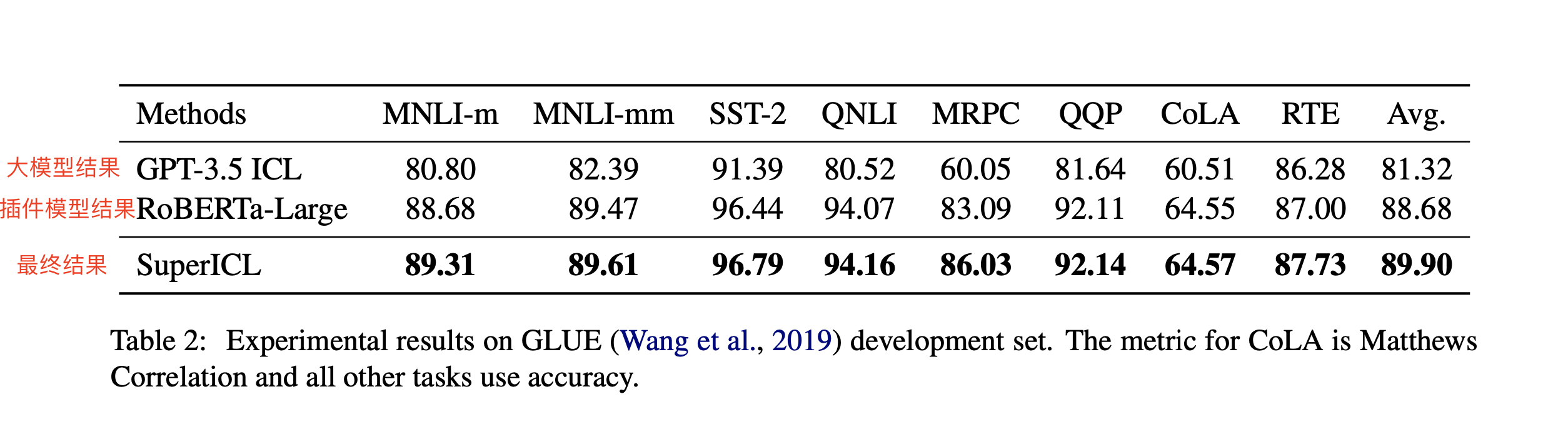
- 大模型LLM的平均分数为81.32,本地fine-tuning后模型的效果是88.68,最终SuperICL模型的结果是89.90
4. 结合跨语言插件模型在跨语言上的效果
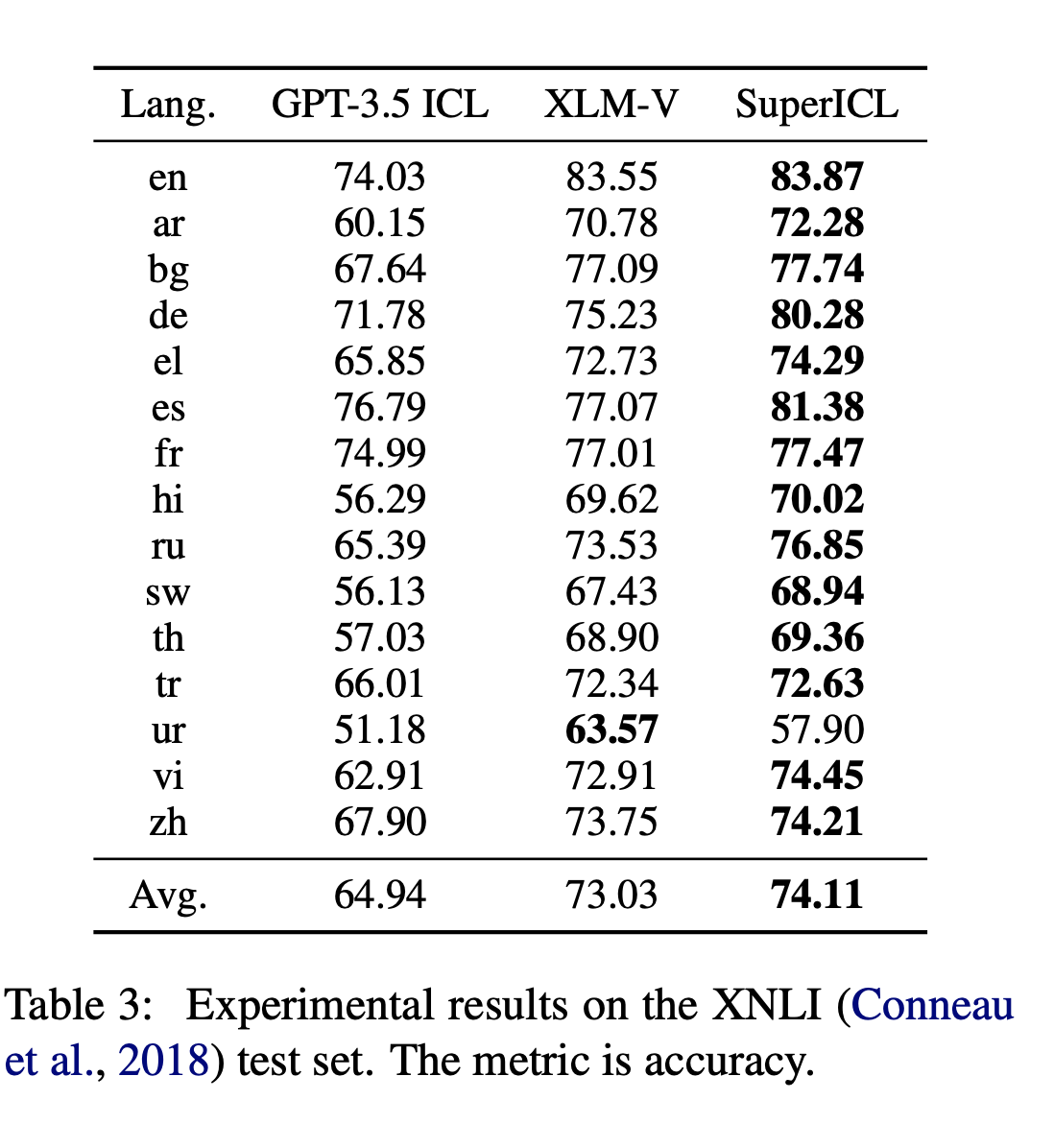
、
- 结合专门为跨语言模型设计的XML-V模型,大部分任务相对于GPT-3.5 ICL提升不错
- token的限制,导致部分语言效果比较差
5. 消融实验
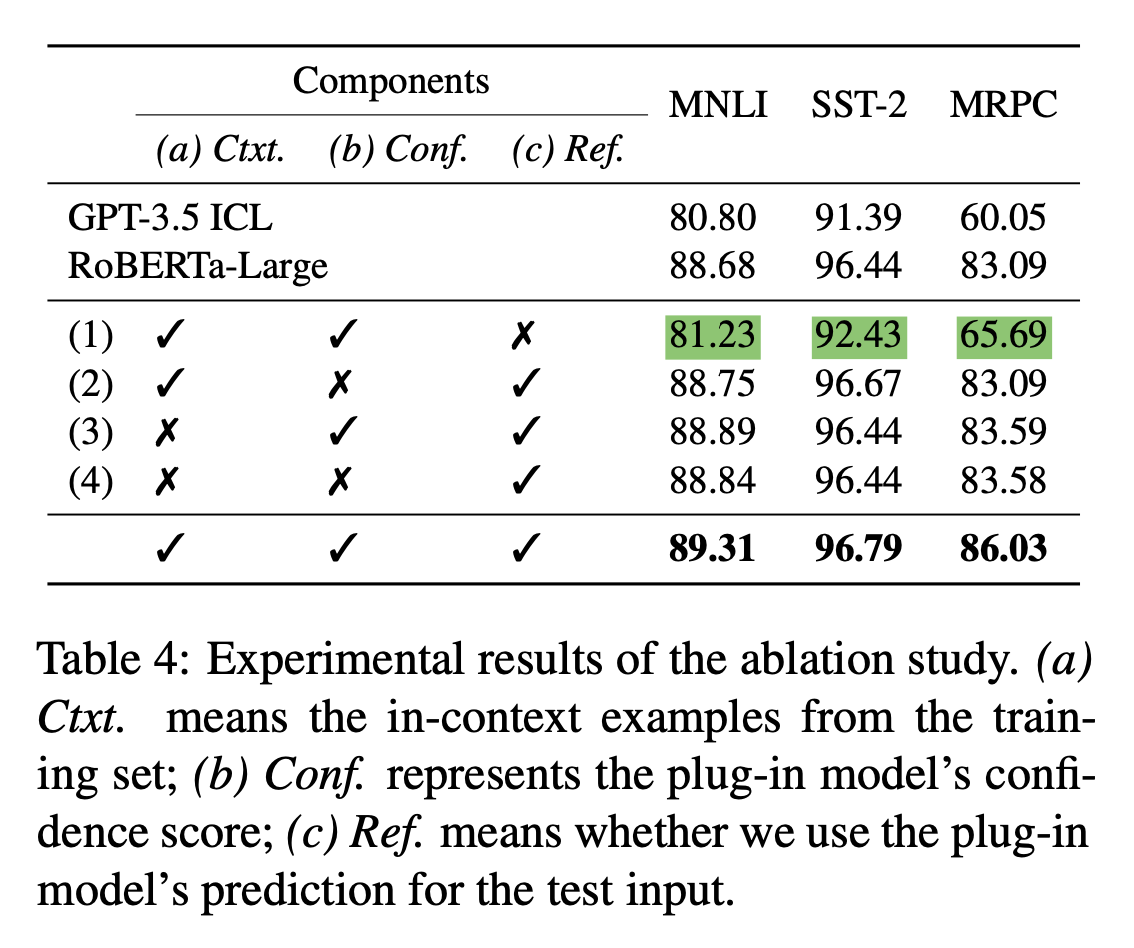
- Ctxt:上下文example
- Conf:插件模型的置信度分数
- Ref:是否在测试集中利用插件模型预测结果
6. 改写比例和正确率

- MNLI,SST-2:改写率较低,准确率高
- MRPC:改写率较高,准确率偏低
- 上述结论可能和插件模型的结果强相关
7. 改写比例和插件执行度的关系
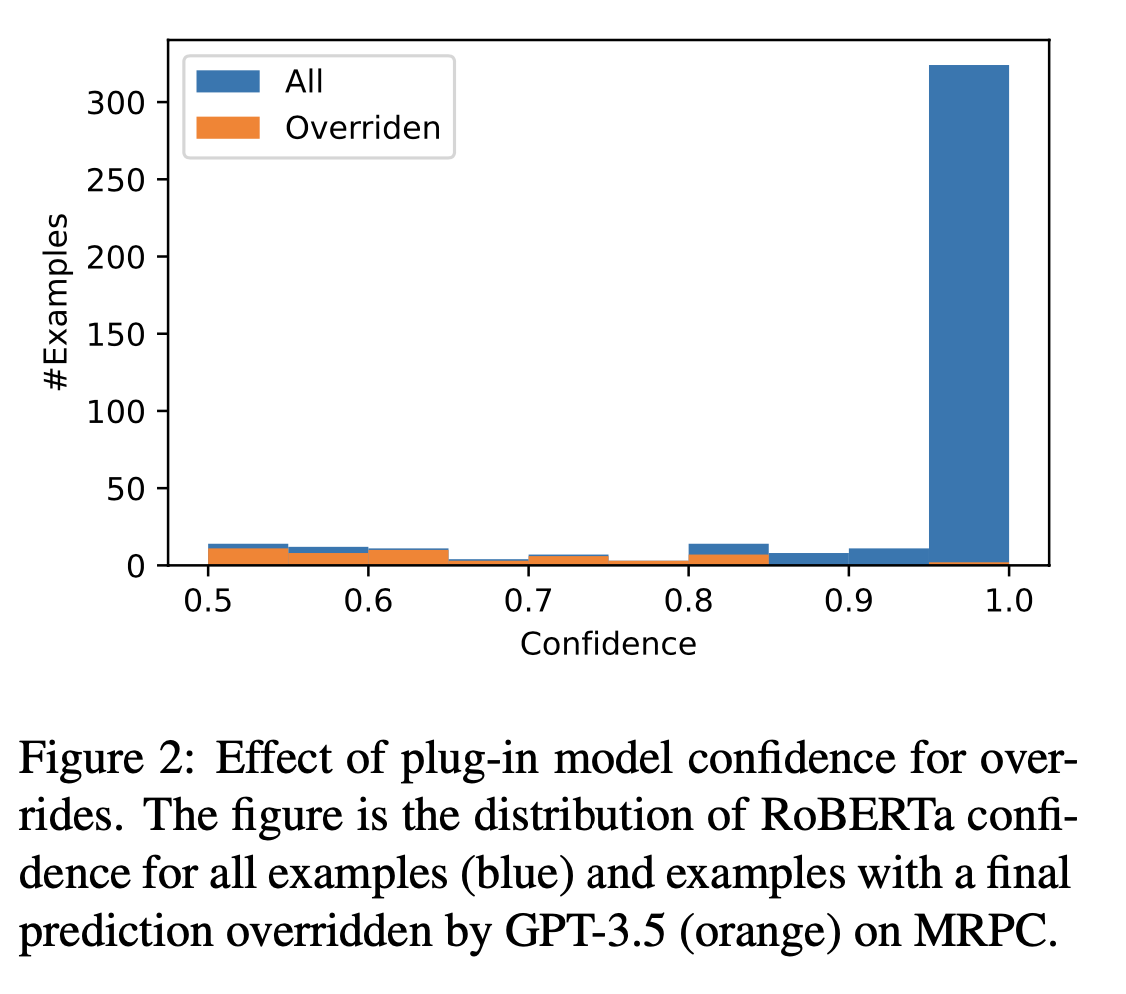
- 置信度比较低的时候,被改写的比例高















 2142
2142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









