






一、前言
在自监督单目深度估计中,我们常常见到这样一个损失函数作为Final Loss的一部分存在:
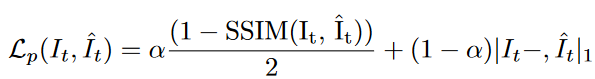
这个loss看起来比较复杂,网上资料也比较少,那么下面我们就来探讨一下photometric loss。
二、自监督单目深度估计原理
聊photometric loss之前,我们得大致了解自监督单目深度估计的原理。几乎所有的自监督任务是利用深度预测和相机姿态估计两个模块联合进行的:
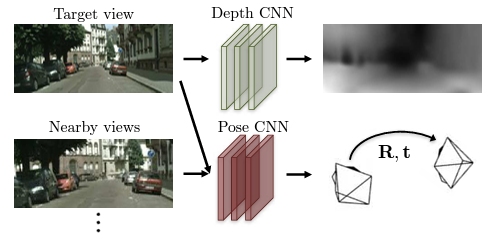
既然是自监督,那么就意味着输入的图像是没有深度标签的,所以我们就无法利用ground truth这个"标准答案”对输出的深度图进行优化。于是,我们利用联合训练的方法,通过输入相邻帧图像对相对位姿网络进行训练,从而经过变换得到重建帧,以重建帧与输入到深度预测网络的目标帧的差值作为训练信号,达到自监督的效果。
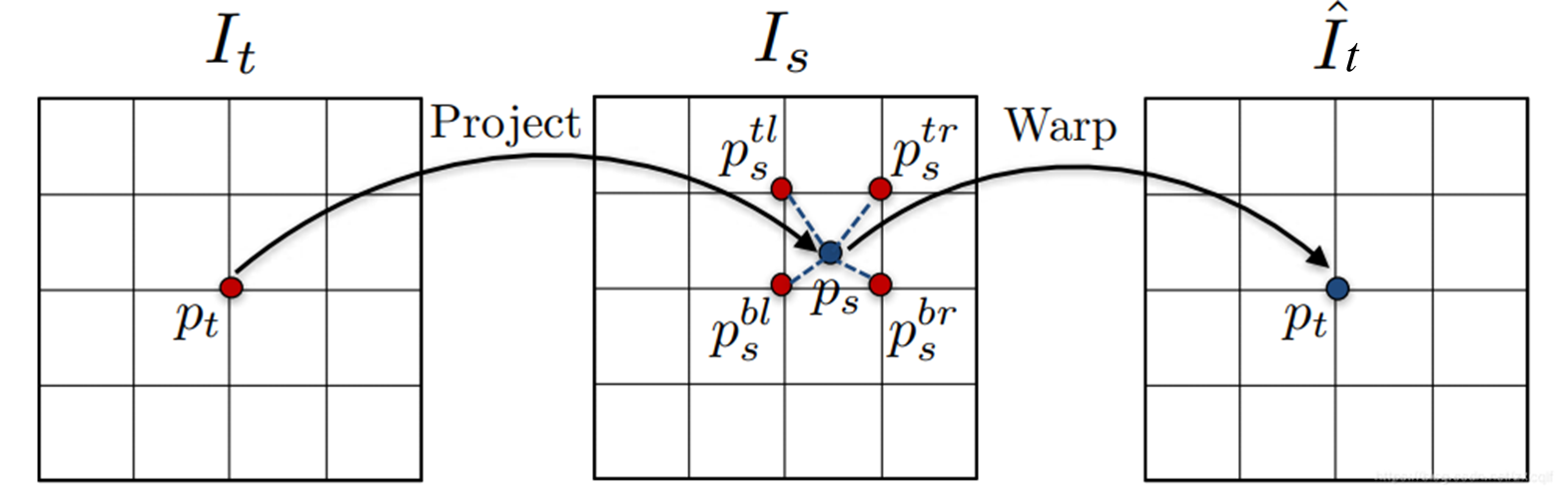
首先介绍以下前置知识:
- I t I_t It:目标帧Target frame;
- I t ^ \hat{I_t} It^:重构后的目标帧;
- I s I_s Is:源帧Source frame,若以目标帧为基准,则源帧为目标帧±1的相邻帧;
- D t D_t Dt = Φ d ( I t ) \Phi_d(I_t) Φd(It):深度预测网络,输入 I t I_t It,输出深度图 D t D_t Dt;
- T t − > s {T}_{t->s} Tt−>s = Φ p ( I t , I s ) \Phi_p(I_t, I_s) Φp(It,Is):相对位姿估计网络,输出相对位姿矩阵 T t − > s {T}_{t->s} Tt−>s;
- p s p_ {s} ps ∼ \sim ∼ K T t → s KT_ {t\rightarrow s} KTt→s D t D_ {t} Dt( p t p_ {t} pt) K − 1 K^ {-1} K−1 p t p_ {t} pt : I t I_t It的像素 p t p_t pt与 I s I_s Is的像素 p s p_s ps的转换关系, K K K为相机内参。
辅助上面两张图片理解,自监督估计具体流程如下:
- 将目标帧 I t I_t It输入深度预测网络 Φ d \Phi_d Φd,得到深度图 D t D_t Dt;
- 将目标帧 I t I_t It和源帧 I s I_s Is同时输入相对位姿估计网络 Φ p \Phi_p Φp,得到相对位姿矩阵 T t − > s {T}_{t->s} Tt−>s;
- 利用 p s p_ {s} ps ∼ \sim ∼ K T t → s KT_ {t\rightarrow s} KTt→s D t D_ {t} Dt( p t p_ {t} pt) K − 1 K^ {-1} K−1 p t p_ {t} pt这样的转换关系,由 p t p_t pt计算出 p s p_s ps;
- 由于 p s p_s ps不一定为整数,故利用双线性插值算法计算该点的像素值,然后将该点采样到 I t ^ \hat{I_t} It^图像上的对应位置,通过借助投影不断采样填充,最终实现利用 I s I_s Is 的像素信息重构出来 I t ^ \hat{I_t} It^;
- 利用 I t {I_t} It和 I t ^ \hat{I_t} It^计算光度损失。
三、光度损失
我们将
l
1
l_1
l1和
S
S
I
M
SSIM
SSIM两者组合作为光度损失来计算目标帧
I
t
I_t
It和重构帧
I
t
^
\hat{I_t}
It^之间的差异,即:
此函数由两部分相加而成,前面用于计算结构相似度
S
S
I
M
SSIM
SSIM,后面用于计算光度损失(photometric loss)。很多论文直接把整个函数叫光度损失(photometric loss),严格意义上不那么准确,应该称作图像重构损失(reprojection loss)。
参考文献
- 浅谈无监督单目深度估计框架的局限性:http://t.csdn.cn/3oaKQ
- 强大的自监督深度估计monodepth2:https://zhuanlan.zhihu.com/p/101533728















 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









