









CUDA编程中全局内存分为分页内存,固定内存,零拷贝内存,统一虚拟寻址,统一内存地址。
一.分页内存
利用malloc()申请的主机内存,即可分页内存。
特点:可分页内存传输数据到设备时,首先需要分配固定内存,再传递到设备端。
对主机而言,分页内存可提高主机性能。
float* data;
malloc((void**)&data,sizeof(float)*N);
二.固定内存(pinned)- 锁页内存
利用cudaMallocHost()申请固定内存。
特点:设备可直接访问固定内存,可提高传输性能,如图所示。
float*data;
cudaMallocHost((void**)&data,sizeof(float)*N);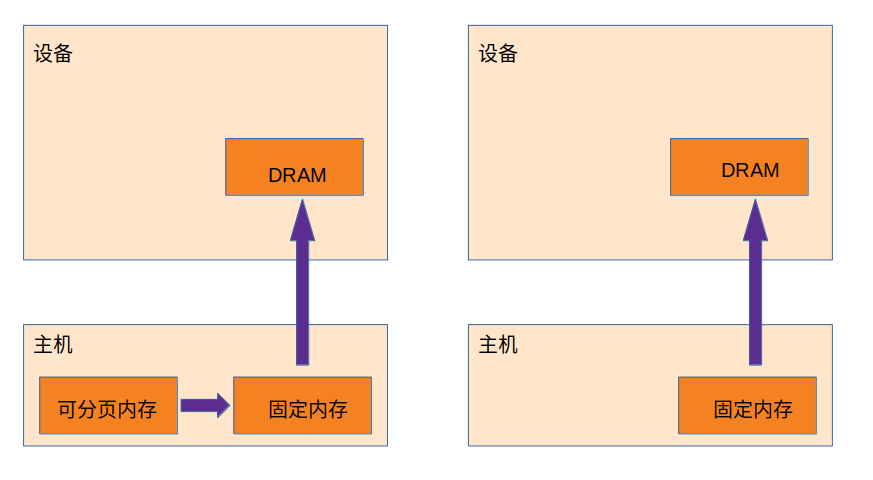
三.零拷贝内存
利用cudaHostAlloc()申请零拷贝内存。使用情况:(1)设备不足时,可利用主机内存;(2)避免设备和主机间的显式传输; (3)提高PCI-e传输率。
特点:通常,主机无法访问设备变量,设备无法访问主机变量,但主机和设备均可访问零拷贝内存。
float* data;
cudaHostAlloc((void**)&data,N*sizeof(float),unsigned int flags);最后一种标示就是零拷贝内存。
使用方式:
1.主机访问零拷贝内存:直接使用可以。
2.设备访问零拷贝内存:利用cudaGetDevicePointer((void**)&DevicePtr,void* HostPtr,unsiged int flag)获取设备零拷贝主机内存对应的设备指针,然后将设备指针传入kernel函数。设备就可直接访问主机内存了。
四.统一虚拟地址
利用cudaHostAlloc()获取的零拷贝内存,在UVA(统一虚拟地址)之前,核函数使用的指针必须为经过cudaGetDevicePointer()获得的设备指针。而有了UVA之后,则省去了这一步,核函数可直接使用主机指针。
如图所示。
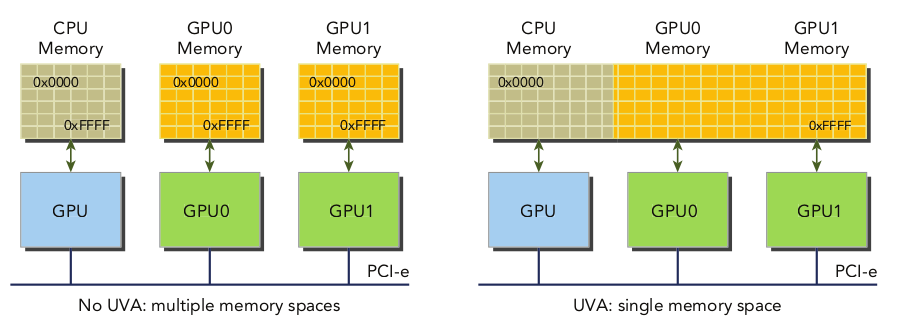
五.统一内存地址
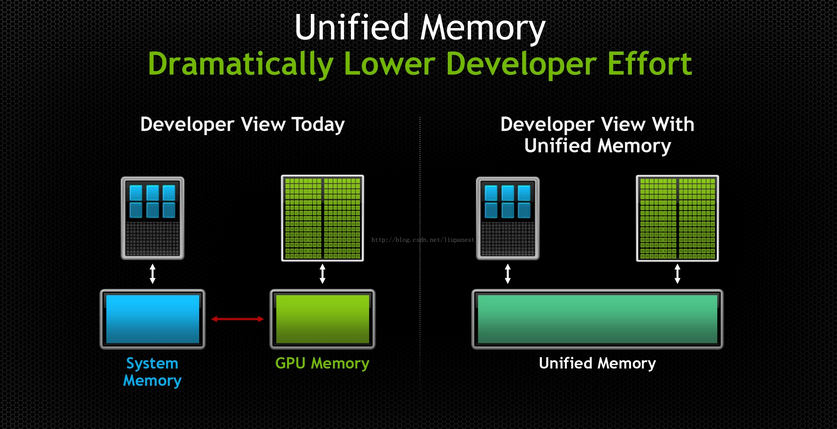
利用cudaMallocManaged()申请托管内存,“统一内存”创建了一个托管内存池,内存池中已分配的空间,可以用相同的内存地址(指针)在CPU和GPU上进行访问。
float* data;
cudaMallocManaged((void**)&data,sizeof(float)*N,unsiged int flags)特点:完成了主机与设备数据的自动拷贝,消除重复指针。















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









