







清华青年AI自强作业hw4:基于DNN实现狗狗二分类与梯度消失实验

一起学AI系列博客:目录索引
简述
hw4总体分为part1/part3都是用全连接网络来进行狗狗图片二分类,区别只在于网络结构的差异。part2验证梯度消失的问题。
- 相应实现源码见代码仓:https://github.com/ioMayday/Tsinghua_Youth_AI/tree/master/homework
- 相关keras使用指导:https://keras.io/zh/getting-started/sequential-model-guide/
Part1/Part3
part1
设计思路
- 获取数据,并进行预处理
- csv中读取图片路径和label结果
- opencv读取图像并转为灰度图降低计算量
- 将图像输入重整大小并展平成一维
- 基本参数设置(超参)
- 学习率lr
- 学习衰减率decay_rate
- 批量大小batch_size
- 迭代次数epochs
- 网络模型搭建
- layer1: input, 227*227=51529, relu
- layer2: fc, 5, relu
- layer3: fc, 3, relu
- layer4: output, 1, none
- 模型训练
- 总体样本分为batch进行输入
- 打印每个epoch的loss和精度
- 记录一个epoch训练耗费时间
- 打印epoch完后整体训练集精度
- 模型验证
- 评估测试集的精度
part3
与上面的差异在于网络结构,具体如下:
-
网络模型搭建
-
layer1: input, 227*227=51529, relu
-
layer2: fc, 1024, relu
-
layer3: fc, 2048, relu
-
layer4: fc, 2048, relu
-
layer5: fc, 1024, relu
-
layer6: output, 1, none
-
参考代码中,先epoch训练出模型来,再用Ttrain/Ttest来获取当前模型在训练集和测试集的正确率。如果用keras进行重构改写,可以简化此过程。
训练注意事项和trick
-
注意
- 实验使用的数据集非Imagenet原始数据集,而是处理后的3w张图,最好直接用作业提供的数据集
- keras改写时要注意添加BatchNormalization()层、设置学习率衰减、设置优化器
-
trick
-
调试框架代码时,先减小数据规模
-
先将train数据改小为100张图,将test改为10张图跑通流程先
-
将batch-size改为10个样本一个batch
-
-
两者的训练结果对比如下:
- Part1:
- 训练集:
57%,测试集:61%
- 训练集:
- Part3
- 训练集:
74%,测试集:82%(全训练集,用时9h)
- 训练集:
Part2
该部分作业为通过一条直线连接的网络模型,进行编程实现,迭代训练第二讲的小姐姐喜好分类小数据集,以直观感受每层神经元经过sigmoid函数梯度传递后,权重更新变化趋势。
由于作业基线已实现基本流程,仅填写代码几行,这里不赘述了。
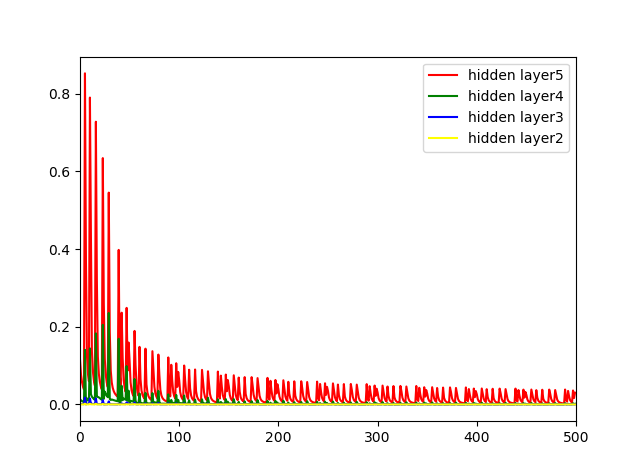
结果如下,可以看出随着横轴迭代次数增加,越靠近输入的神经元层权重更新越小,验证了梯度消失的现象。
遇到的问题
- TF中,如何分清训练和测试的流程?
- 利用train_step的传入设置是否开启训练
- part1和part3的loss无法下降收敛?
- 调整数据量大小
- 调整优化器
- 调整学习率和衰减率
- 设置合理的初始化器(避免relu导致梯度爆炸)
- 增加正则化
- 添加batch_normalization(一定正则功能,减小训练内存需求)
- 二分类问题输出层用sigmoid,不用再手动转换成0-1标签
- 报错:ModuleNotFoundError: No module named ‘pandas’ cv2
- 在启用tensorflow环境下的spyder ide对话窗里安装opencv和pandas,输入以下指令:
- pip install opencv-python
- pip install pandas
- 在启用tensorflow环境下的spyder ide对话窗里安装opencv和pandas,输入以下指令:
遗留问题:
- 为何part3实际无法达到课程目标测试集精度:94%?
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









