







HAT
论文
HAT: Hybrid Attention Transformer for Image Restoration
模型结构
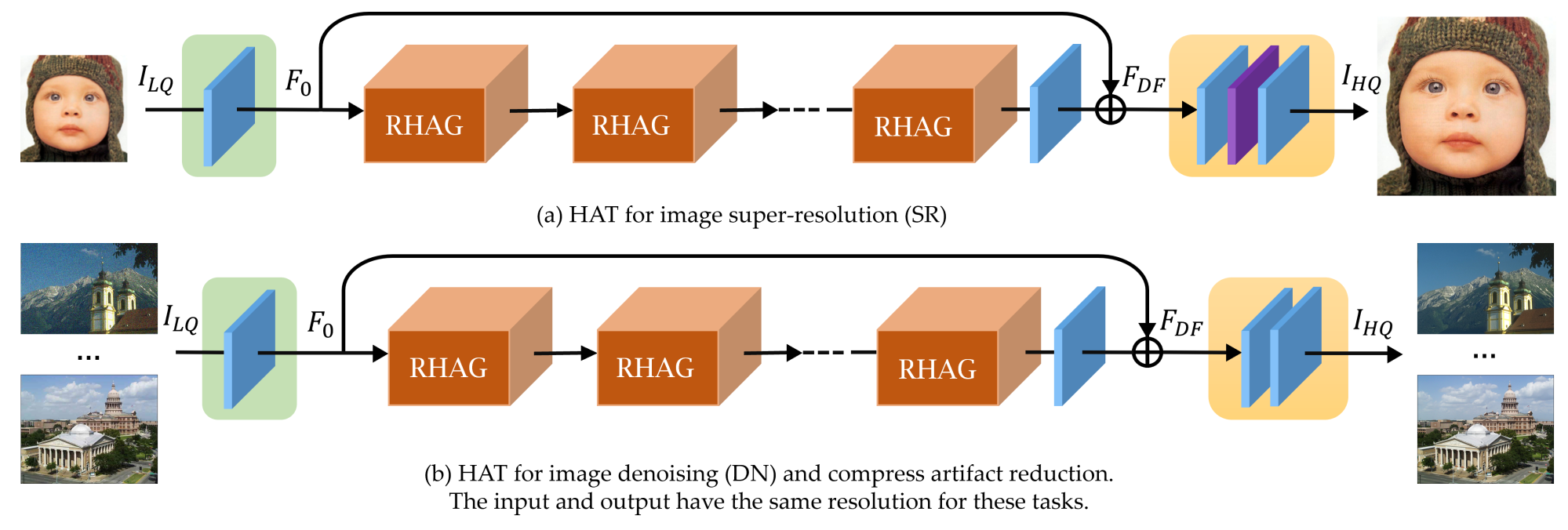
HAT包括三个部分,包括浅层特征提取、深层特征提取和图像重建。
算法原理
HAT方法结合了通道注意力和基于窗口的自注意力方案,利用两者的互补优势。此外,引入了重叠的跨注意力模块来增强相邻窗口特征之间的交互, 更好地聚合跨窗口信息。在训练阶段,HAT还采用了相同的任务预训练策略,以进一步挖掘模型的潜力进行进一步改进。得益于这些设计,HAT可以激活更多的像素进行重建,从而显著提高性能。
环境配置
-v 路径、docker_name和imageID根据实际情况修改
Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk23.10-py38
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/hat_pytorch
pip install -r requirements.txt
python setup.py develop
Dockerfile(方法二)
cd ./docker
cp ../requirements.txt requirements.txt
docker build --no-cache -t hat:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/hat_pytorch
python setup.py develop
Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
DTK软件栈:dtk23.10
python:python3.8
torch:1.13.1
torchvision:0.14.1
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2、其他非特殊库直接按照requirements.txt安装
pip install -r requirements.txt
python setup.py develop
数据集
训练: ImageNet dataset DIV2K Flickr2K
Tips: DF2K: DIV2K 和 Flickr2 数据的整合 训练数据处理请参考BasicSR
数据准备具体步骤如下:
-
将数据存放在datasets目录下;
-
BSD100和urban100需要再各自目录下新GTmod4、LRbicx4两个新目录,并把原始图片存放进GTmod4目录下,然后再datasets目录下分别执行下面两条命令:
python gen_LRbicx4.py --file_name ./BSD100
python gen_LRbicx4.py --file_name ./urban100
- 建数据集的目录结构如下:
├── DF2K
│ ├── DF2K_HR # HR 数据
│ ├── DF2K_HR_sub # 生成的
│ ├── DF2K_bicx4 # train_LR_bicubic_X4 数据
│ ├── DF2K_bicx4_sub # 生成的
├── Set5
│ ├── GTmod12
│ ├── LRbicx2
│ ├── LRbicx3
│ ├── LRbicx4
├── Set14
│ ├── GTmod12
│ ├── LRbicx2
│ ├── LRbicx3
│ ├── LRbicx4
├── BSDS100
│ ├── GTmod4 # 原始图像
│ ├── LRbicx4
├── urban100
│ ├── GTmod4 # 原始图像
│ ├── LRbicx4
Tips: 项目提供了tiny_datasets用于快速上手学习, 如果实用tiny_datasets, 需要对下面的代码内的地址进行替换, 当前默认完整数据集的处理地址。
- 因为 DF2K 数据集是 2K 分辨率的 (比如: 2048x1080), 而我们在训练的时候往往并不要那么大 (常见的是 128x128 或者 192x192 的训练patch). 因此我们可以先把2K的图片裁剪成有overlap的 480x480 的子图像块. 然后再由 dataloader 从这个 480x480 的子图像块中随机crop出 128x128 或者 192x192 的训练patch.
python extract_subimages.py # 将图片进行sub
- 生成 meta_info_file
python generate_meta_info.py
训练
预训练模型下载地址:Google Drive or 百度网盘 (access code: qyrl)。
训练日志及weights保存在./experiments文件中
单机多卡
# 默认 train_HAT_SRx4_finetune_from_ImageNet_pretrain.yml
bash train.sh
多机多卡
使用多节点的情况下,需要将使用节点写入hostfile文件, 多节点每个节点一行, 例如: c1xxxxxx slots=4。
-
run_train_multi.sh中18行所需虚拟环境变量地址;
-
修改single_process.sh中22行所需训练的yaml文件地址,如与默认一致,可不修改。
执行命令如下, 训练日志保存在logs文件夹下
# 默认 train_HAT_SRx4_finetune_from_ImageNet_pretrain.yml
bash run_train_multi.sh
推理
预训练模型下载地址:Google Drive or 百度网盘 (access code: qyrl)。
测试结果将保存到 ./results 路径下。options/test/HAT_SRx4_ImageNet-LR.yml 适用于不使用 ground truth image 的推理过程。
# 默认 HAT_SRx4_ImageNet-pretrain.yml
bash val.sh
result
基于 Real_HAT_GAN_SRx4_sharper.pth 的测试结果展示
精度
HAT
| Model | Params(M) | Multi-Adds(G) | Set5 | Set14 | BSD100 | Urban100 |
|---|---|---|---|---|---|---|
| Z100L | 20.8 | 102.4 | 33.1486 | 29.3587 | 25.4074 | 21.2687 |
应用场景
算法类别
图像重建
热点应用行业
交通,公安,制造
















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











