







目录
1、初识设计模式
1.1、什么是设计模式
软件设计模式(Software Design pattern),又称设计模式,是一套被反复使用、多数人知晓的、经过分类编目的代码设计经验的总结。
设计模式描述了在软件设计过程中的一些不断重复发生的问题,以及这些问题的解决方案。
设计模式是前辈们代码设计经验的总结
设计模式最大的魅力在于,不管在哪种编程语言中,它思想和表现都是一样的,只是代码语法略有不同而已。
1.2、为什么使用设计模式
设计模式的本质是面向对象设计原则的实际运用,是对类的封装性、继承性和多态性以及类的关联关系和组合关系的充分理解。
正确使用设计模式具有以下优点:
-
提高我们的思维能力、编码能力和设计能力。
-
使程序设计更加标准化、代码编制更加工程化、使软件开发效率大大提高,从而缩短软件的开发周期。
-
使设计的代码可重用性高、可读性强、可靠性高、灵活性好、可维护性强。
1.3、设计模式的分类
总体来说设计模式分为三大类:
-
创建型模式,共5种:
-
用于描述“怎样创建对象”,主要特点是“将对象的创建与使用分离”。
-
工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
-
-
结构型模式,共7种:
-
用于描述如何将类或对象按某种布局组成更大的结构。
-
适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
-
-
行为型模式,共11种:
-
用于描述类或对象之间怎样相互协作,共同完成单个对象无法单独完成的任务,以及怎样分配职责。
-
策略模式、模板方法模式、观察者模式、迭代器模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
-
2、UML
2.1、什么是UML
UML是统一建模语言(Unified Modeling Language, UML),是一种可视化的面向对象建模语言,特点是简单,统一,图形化,能表达软件设计中的动态与静态信息。
UML从目标系统的不同角度出发,定义了用例图、类图、对象图、状态图、构件图、部署图、协作图、交互序列图、活动图等9种图。
2.2、类图概述
类图(Class Diagram)显示了模型的静态结构,特别是模型中存在的类、类的内部结构以及它们与其他类的关系等。类图不显示暂时性的信息。类图是面向对象建模的主要组成部分。
2.3、类图的作用
-
在软件工程中,类图是一种静态的结构图,描述了系统的类的集合,类的属性和类之间的关系,简化了人们对系统的理解。
-
类图是系统分析和设计阶段的重要产物,是系统编码和测试的重要模型。
2.4、类图表示法
4.1、类的表示方式
在UML类图中,类使用包含类名、属性和方法,且带有分割线的矩形来表示。
比如下图表示一个Student类,它包含name,age和address三个属性,以及study()方法。
属性或方法名称前的+和-,表示了这个属性或方法的可见性。UML类图中表示可见性的符号有三种:
-
+: 表示public
-
-: 表示private
-
#: 表示protected
属性的完整表示方式是: 可见性 名称 : 类型 [ = 缺省值]
方法的完整表示方式是: 可见性 名称(参数列表) [ : 返回类型]
例如:
上图Demo类定义了三个方法:
-
method()方法:修饰符为public,没有参数,没有返回值。
-
method1()方法:修饰符为private,没有参数,返回值类型为String。
-
method2()方法:修饰符为protected,接收两个参数,第一个参数类型为int,第二个参数类型为String,返回值类型为int。
4.2、类与类之间关系的表示方式
2.1、关联关系
关联关系是对象之间的一种引用关系,用于表示一类对象与另一类对象之间的联系。
关联关系是类与类之间最常用的一种关系,分为一般关联关系、聚合关系和组合关系。先介绍一般关联关系。
关联又可以分为单向关联,双向关联,自关联。
(1)单向关联
单向关联就是某个类持有另一个类型的成员变量。
在UML类图中,单向关联用一个箭头表示。
上图表示每个顾客都有一个地址,这通过让Customer类持有一个类型为Address的成员变量类实现。
(2)双向关联
所谓的双向关联就是双方各自持有对方类型的成员变量。
在UML类图中,双向关联用一条直线表示。
上图中在Customer类中维护一个List<Product>,表示一个顾客可以购买多个产品;在Product类中维护一个Customer类型的成员变量,表示这个产品被哪个顾客所购买。
(3)自关联
自关联在UML类图中,用一个指向自身的箭头表示。
上图的意思是,Node类包含类型为Node的成员变量,也就是“自己包含自己”。
2.2、聚合关系
聚合关系是关联关系的一种,而且是强关联关系。它体现了整体与部分的关系。
关联和聚合在语法上无法区分,必须考察具体的逻辑关系。
聚合关系也是通过成员对象实现的,其中成员对象是整体对象的一部分,但是成员对象可以脱离整体对象而独立存在。
比如组织和个人是整体和部分的关系,组织解散了,个人依然存在。
在UML类图中,聚合关系用带空心菱形的实线表示,菱形指向整体。
2.3、组合关系
组合关系是关联关系的一种,是比聚合关系还要强的关系。组合关系表示类之间的整体与部分的关系。
在组合关系中,整体对象可以控制部分对象的生命周期,一旦整体对象不存在,那么部分对象也将不存在。部分对象不能脱离整体而存在。
如公司和部门是整体和部分的关系,没有公司就不存在部门。
在UML类图中,组合关系用带实心菱形的实线表示,菱形指向整体。
2.4、依赖关系
依赖关系是一种使用关系,即一个类的实现需要另一个类的协助,所以要尽量不使用双向的互相依赖。
它是对象之间耦合度最弱的一种关联方式,是临时性的关联。依赖关系很常用。
在代码中,某个类的方法通过局部变量、方法的参数或者对静态方法的调用,来访问另一个类(被使用类)中的某些方法,来完成一些任务。
比如司机与汽车,汽车依赖司机,才能完成行驶的任务。
在UML类图中,依赖关系使用带箭头的虚线来表示,箭头指向被使用的类。
2.5、泛化关系
泛化关系就是继承关系。是对象之间耦合度最大的一种关系,表示一般与特殊的关系,是父类和子类之间的关系,是一种继承关系。
在代码中,使用面向对象的继承机制来实现泛化关系。
比如仓鼠是动物的一种,即有仓鼠的特性,也有动物的共性。
在UML类图中,泛化关系使用带空心三角箭头的实线来表示,箭头指向父类。
2.6、实现关系
实现关系是一种接口与实现类的关系。在这种关系中,类实现了接口,类中的操作实现了接口中所声明的所有抽象操作。
例如,汽车类实现了载具接口。
在UML类图中,实现关系使用带空心三角箭头的虚线来表示,箭头指向接口。
2.7、各种关系的强弱顺序
泛化(继承) = 实现(实现接口) > 组合(整体与部分的关系) > 聚合(整体与部分的关系) > 关联(拥有的关系) > 依赖(使用的关系)
3、软件设计原则
在软件开发者中,为了提高软件系统的可维护性和可复用性,增加软件的可扩展性和灵活性,程序员要尽量根据以下原则来开发程序,从而提高软件开发效率、节约软件开发成本和维护成本。
软件设计原则思维导图
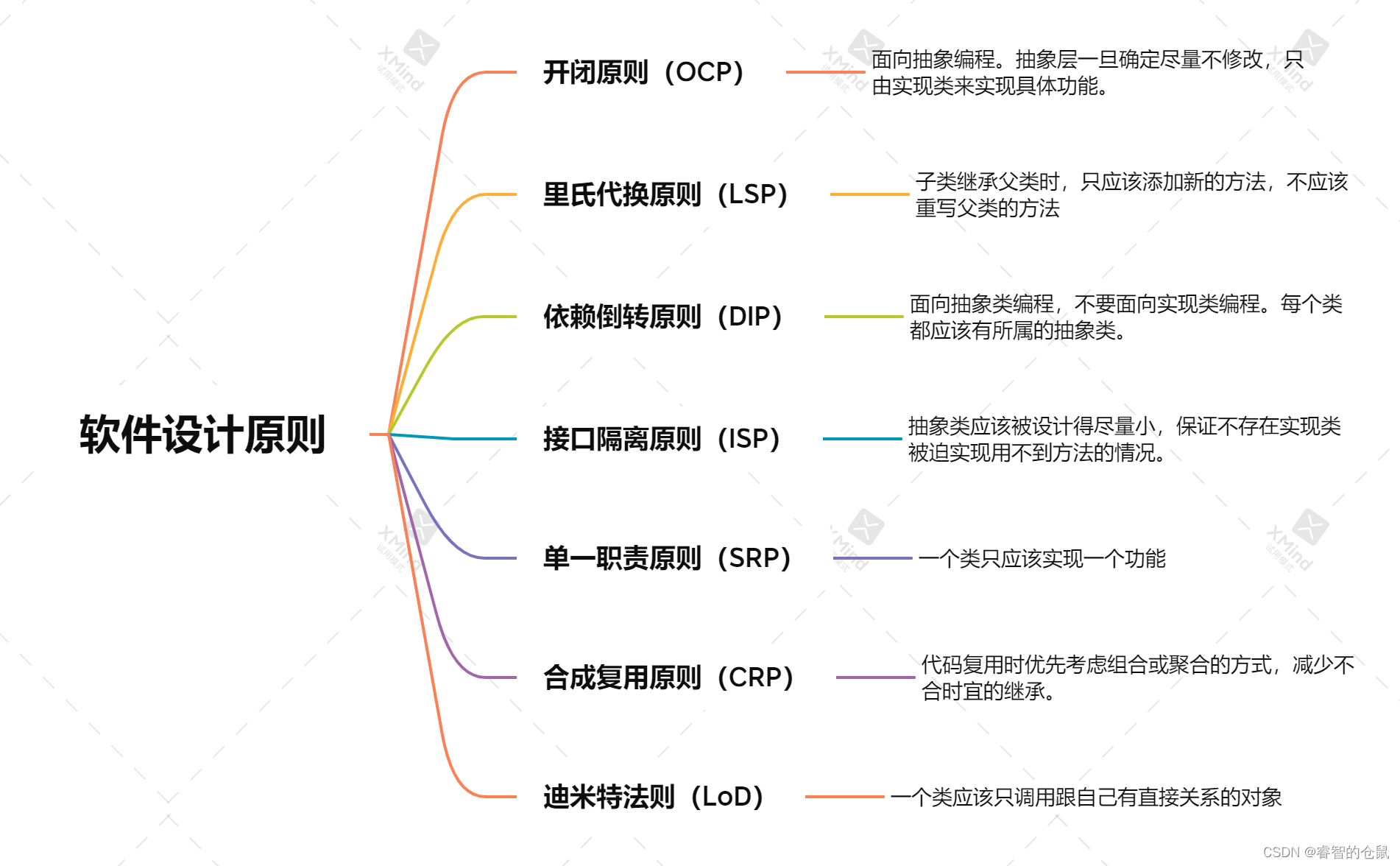
1、开闭原则(OCP)
什么叫开闭
对扩展开放,对修改关闭。 即在程序需要进行拓展的时候,不能去修改原有的代码,只能增加新的代码。
为什么这么设计
增强程序的拓展性,易于维护升级。
这是程序设计的终极目标,其他所有的设计模式、设计原则,都是为了实现开闭原则而努力。
如何在代码中实现
使用接口和抽象类。
因为抽象的灵活性好,适应性广,只要抽象设计合理,基本可以保持软件架构的稳定。
软件中易变的细节可以从抽象派生来的实现类当中进行扩展。当软件需要发生变化时,只需要根据需求重新派生一个新的实现类来拓展即可。
简单说,相当于电脑提供了USB接口,插入不同的设备可以实现不同的功能。
USB接口就是抽象类或接口,而不同的设备就是指不同的实现类。
开闭原则其实就是"插拔"原则,插拔的是不同的实现类!
举例理解
比如搜狗输入法的皮肤系统。
搜狗输入法的皮肤是输入法背景图片,窗口颜色,声音等元素的组合。用户可以根据自己的喜好来更换皮肤。
这些皮肤有共同的特点,可以定义成一个抽象类(AbstractSkin),而每个具体的皮肤,例如默认皮肤(defaultSkin)和小狐狸皮肤(FoxSkin)是其子类。用户窗体可以根据需要选择新的主题,而不需要修改源代码,所以它满足了开闭原则。
深入理解
-
开闭原则是设计原则中最基础,最纲领性的原则。实现了其他设计原则,就相当于实现了开闭原则。
-
开闭原则应用在项目中,需要注意至关重要的一点:
抽象约束抽象是对一组事物的通用描述,没有具体的实现,也就表示它可以有非常多的可能性,可以跟随需求的变化而变化。
因此,通过接口或抽象类可以约束一组可能变化的行为,并且能够实现对扩展开放,其包含三层含义:
-
通过接口或抽象类约束扩展,对扩展进行边界限定,
不允许出现在接口或抽象类中不存在的public方法 -
参数类型、引用对象尽量使用接口或者抽象类,而不是实现类 -
抽象层尽量保持稳定,一旦确定即不允许修改
-
2、里氏代换原则(LSP)
里氏代换原则是面向对象设计的基本原则之一。
解释
里氏代换原则:任何父类可以出现的地方,子类一定可以出现。
如何实现?进一步解释
子类可以扩展父类的功能,但不能改变父类原有的功能。
简单说,意思是子类继承父类的时候,除了添加新方法实现新的功能之外,不应该重写父类的方法!
如果子类重写了父类的方法,那么子类一定无法完全替代父类,不符合里氏代换原则。所以这么理解没有问题。
为什么这么设计
如果一味通过重写父类的方法来实现新的功能,整个继承体系的可复用性非常差,特别是运用多态比较频繁时,程序运行出错的概率非常大,结构也比较混乱。
举例理解
里氏代换原则有一个经典的例子:正方形不是长方形。
在数学领域里,正方形就是一个长宽相等的长方形,所以我们开发几何图形相关的软件时,就可以顺理成章地让正方形继承自长方形。
用代码实现比较简单,只需要体会其中逻辑即可。
让正方形继承长方形这个操作,可能带来哪些隐患?
一定要注意,继承的意思是(is a),正方形继承了长方形,在引用类型上,一个正方形对象就是一个长方形类型的实例!如果正方形继承了长方形,它就需要重写长方形的set方法,比如重写setWidth(),设置传入的数据为正方形的变长,对setLehgth()作空实现。
那么在需要长方形类型的方法中,正方形也可以被传入。如果这个方法只针对长方形有效,那么正方形传入后,系统就会出现问题,严重的话会直接崩溃!
哪些操作是长方形独有,而正方形会出问题的?其实有很多,比如利用它们的唯一不同点:长方形长和宽不相等。我写了一个方法,目的是增加长方形的原有的宽度,直到变成长度+1的值。
如果传入长方形,就会看到长方形的宽度逐渐增长的效果,一旦宽度大于长度,系统就会停止。
如果传入的是正方形,那么系统将持续执行下去,正方形的边长会越来越大,直到内存溢出!
所以,普通的长方形适合这段代码,而正方形不适合。我们得出结论,在上面写的方法中,长方形类型的参数,不能被正方形类型的参数代替,如果代替了就得不到预期结果。
长方形是父类,正方形是子类,子类无法代替父类,所以这段继承关系不符合里氏代换原则!它们之间的继承关系不成立,正方形不是长方形。非常精彩的例子。如何改进?
很简单,让正方形和长方形符合里氏代换原则。
我们抽象一个四边形接口,再分别让正方形和长方形实现接口即可。
在实际操作中,可能当前系统结构下,在某些地方子类重写了某些方法后,使用时确实可以代替父类。但也要避免不符合里氏代换原则。因为系统升级过程中,总会有一些时刻,由于错误继承导致系统异常。
深入理解
-
在类中调用其他类时务必要使用父类或接口。如果不能使用父类或接口, 则说明类的设计已经违背了里氏代换原则 -
如果子类不能完整地实现父类的方法,或者父类的某些方法在子类中必须要重写,则建议断开父子继承关系, 采用依赖、 聚集、 组合等关系代替继承
3、依赖倒转原则(DIP)
解释
依赖倒转原则:高层模块不应该依赖低层模块,两者都应该依赖其抽象。抽象不应该依赖细节,细节应该依赖抽象。
这个定义不太说人话。
说人话
抽象就是指接口或抽象类,细节就是实现类。
在Java代码中的体现:
-
模块间的依赖通过抽象发生,实现类之间不发生直接的依赖关系,其依赖关系是通过接口或抽象类产生的 -
接口或抽象类不依赖于实现类
-
实现类依赖于接口或抽象类
简单来说:要求我们对抽象进行编程,即面向接口编程,而不要面对实现编程。
为什么这么设计
减少类间的耦合性,提高系统的稳定性,降低并行开发引起的风险,提高代码的可读性和可维护性。
举例理解
举一个司机开车的例子,先来看不遵守依赖倒转原则的情况
我定义一个司机类,定义一个宝马车类,让宝马车类依赖于司机类。
司机类和宝马车类都属于细节,并没有实现或继承抽象,它们是对象级别的耦合。
宝马车怎么依赖于司机类?实现方法也很简单粗暴,如下:
//司机类 public class Driver { public void drive(BMW bmw){ bmw.run(); } } //宝马车类 public class BMW { public void run(){ System.out.println("宝马汽车行驶ing..."); } }很明显,这属于面向实现编程。这有一个很明显的问题。
如果司机不想开宝马了,想开个奔驰车,怎么操作?
新建一个奔驰车类,再去司机类中添加奔驰车的依赖,司机才能开奔驰车。
可以发现,模块与模块之间耦合度太高,生产力太低,只要需求一变就需要大面积重构,说明这样的设计不合理。引入依赖倒置原则,重新设计
//将司机模块抽象为一个接口 public interface IDriver { //是司机就应该会驾驶汽车 public void drive(ICar car); } public class Driver implements IDriver{ //司机的主要职责就是驾驶汽车 public void drive(ICar car){ car.run(); } } //将汽车模块抽象为一个接口:可以是奔驰汽车,也可以是宝马汽车 public interface ICar { //是汽车就应该能跑 public void run(); } public class Benz implements ICar{ //汽车肯定会跑 public void run(){ System.out.println("奔驰汽车开始运行..."); } } public class BMW implements ICar{ //宝马车当然也可以开动了 public void run(){ System.out.println("宝马汽车开始运行..."); } }这样做的好处就是,司机的驾驶方法传入的类型,从宝马车变成了汽车接口的实现类,传入宝马就开宝马,传入奔驰就开奔驰,即他可以开任何汽车了。
这就体现了,
高层模块(司机)不依赖于低层模块(宝马车),而是依赖于其抽象(汽车接口),符合依赖倒转原则。在新增低层模块时,只修改了高层模块(业务场景类),对其他低层模块(Driver类)不需要做任何修改,可以把"变更"的风险降低到最低。
深入理解
依赖倒置原则的本质就是通过抽象(抽象类或接口)使各个类或模块实现彼此独立,不互相影响,实现模块间的松耦合。
在Java中,只要定义变量就必然有类型,并且可以有两种类型:表面类型和实际类型
-
表面类型是在定义时赋予的类型(接口类型或抽象类类型)
-
实际类型是对象的类型。
比如
Car car = new BMW();
car对象的表面类型是car,实际类型是BMW。
在项目中使用这个规则需要以下原则:
-
每个类尽量都要有接口或抽象类,或者抽象类和接口都有(依赖倒置原则的基本要求,有抽象才能去依赖倒置) -
变量的表面类型尽量是接口或者抽象类 -
任何类都不应该从具体类派生 -
尽量不要重写基类已经写好的方法(里式替换原则)
-
结合里式替换原则和依赖倒置原则我们可以得出一个通俗的规则:
-
接口负责定义public属性和方法,并且声明与其他对象的依赖关系;
-
抽象类负责公共构造部分的实现;
-
实现类准确地实现业务逻辑,同时在适当的时候对父类进行细化,增加方法实现具体功能。
-
4、接口隔离原则(ISP)
什么是接口
接口是抽象的代名词。之前学习的其实是狭义上的接口,即一个interface类型的类。在这里,对接口的定义进行延伸。
接口分为以下两种:
类接口:
这就是我们经常使用的用interface定义的接口
实例接口:
在Java中声明一个类,然后用new关键字产生一个实例,其实是对一个类型的事物的描述,这就是一种接口。
我们都知道,在Java中有一个Class类,表示正在运行的类和接口,换句话说每一个正在运行时的类或接口都是Class类的对象,这是一种向上的抽象。
接口是一种更为抽象的定义,类是一类相同事物的描述集合,那为什么不可以抽象为一个接口呢?
注意:这种实例接口的说法原理上经不起推敲。只是在逻辑层面理解!
总之:
接口隔离原则中所说的接口,并不是狭义的在Java中用interface定义的接口,而是一种更为宽泛的概念,可以是接口,抽象类或者实体类。它的思想是存在于接口这个抽象概念之中的,而不是单纯的接口类中的。
什么是接口隔离原则
客户端不应该被迫依赖它不使用的方法,类间的依赖关系应该建立在最小的接口上。
通俗理解
不要在一个接口中放太多方法,会显得这个类很臃肿,结构混乱。
接口应该尽量细化,设计多个专门的接口,一个接口对应一个功能模块,每个接口中的方法应该尽可能的少。
这里涉及到一个“封装过度”的概念。
如果我们单纯的为了封装而封装,把一个类中所有的方法都抽象到一个接口中,再找一个实现类继承这个接口,再让我们的类去继承实现类。这一套操作下来,使用了接口吗?使用了。使用了封装吗?也使用了。代码层面一点问题都没有,但谁看了都说傻逼。
为什么傻逼?因为这就是典型的为了封装而封装,完全没有体现出封装的价值。
真正合理而优秀的封装,应该是做好合理的功能划分的。
前三个原则,都对我们的行为做出了明确的要求,比如使用抽象类,不要重写父类方法,面向抽象编程等。
但接口隔离原则需要我们做出合理的功能划分,细化每个接口的功能。如果系统非常庞大,我们操作的难度会比较大。
举个例子
奇怪的小太阳
故事是,一个太阳的走路方式是,蹦蹦跳跳,眨眼睛。蹦一下就会眨一下眼睛,应该是有什么大病。
先不遵守接口隔离原则试一试。
一个小太阳要走路。它是个太阳类的实例。
我定义了一个接口叫太阳走路接口,里面的两个抽象方法分别是:蹦蹦跳跳,眨眼睛。
小太阳实现了这个接口,实现了其中的两个方法。
但我又想创造另一个比较听话的小仓鼠物种。仓鼠的走路方式是,蹦蹦跳跳。它没有大病,不随便眨眼睛。
如果重新写一个蹦蹦跳跳接口,显然不合理。如果让仓鼠类继承太阳走路接口,显然仓鼠不乐意。
这就属于客户端被迫依赖它不使用的方法。
合理的做法是,遵守接口隔离原则。
将太阳走路接口重构,简化成两个接口:蹦蹦跳跳接口和眨眼睛接口。作出合理的功能划分之后,客户端只需要按需实现即可。
太阳类实现两个接口,仓鼠类只实现它需要的蹦蹦跳跳接口。代码结构非常合理。
经过重新设计,程序变得更加灵活,这就是接口隔离原则的强大之处。
接口隔离原则的使用原则
-
根据接口隔离原则拆分接口时,首先必须满足单一职责原则:
-
没有哪个设计可以十全十美的考虑到所有的设计原则,有些设计原则之间就可能出现冲突,就如同单一职责原则和接口隔离原则。
-
一个考虑的是接口的职责的单一性,一个考虑的是方法设计的专业性(尽可能的少),必然是会出现冲突。
-
在出现冲突时,尽量以单一职责为主,当然这也要考虑具体的情况。
-
-
高内聚:
-
提高接口,类,模块的处理能力,减少对外的交互。
-
比如你给杀手提交了一个订单,要求他在一周之内杀一个人,一周后杀手完成了任务,这种不讲条件完成任务的表现就是高内聚。
-
具体来说就是:要求在接口中尽量少公布public方法,接口是对外的承诺,承诺越少对系统的开发越有利,变更的风险就越小,也有利于降低成本。
-
-
定制服务:
-
单独为每个个体提供优良服务(只提供访问者需要的方法)。
-
-
接口设计要有限度:
-
接口的意义是抽象,它再简化,也应该代表了一个功能。如果不停简化或不停抽象,都失去了它的意义。
-
5、单一职责原则(SRP)
什么是职责
职责就是这个类实现的功能。这个功能可能会导致这个类发生改变。
什么是单一职责原则
不要存在多于一个导致类变更的原因。
简单来说
单一职责,其实就要求我们,一个类(接口,抽象类)中,只应该实现一个功能。
如果一个接口中有多个功能,运行后会改变这个类,而且功能之间不会相互影响的话,我们应该拆分、重构成多个接口。
这样设计的好处
-
可以降低类的复杂度,一个类只负责一项职责,其逻辑肯定要比负责多项职责简单的多;
-
提高类的可读性,提高系统的可维护性;
-
变更引起的风险降低,变更是必然的,如果单一职责原则遵守的好,当修改一个功能时,可以显著降低对其他功能的影响。
单一职责原则的使用原则
-
我们应该在接口中,尽量体现单一职责原则。
-
在实现类中,只能追求尽量实现。
接口隔离原则和单一职责原则的区别
在接口层面,它们有一定相似性,都是要求我们去细分接口,但细分的规则却不一样。
接口隔离,要求我们尽量做到设计专门的功能接口,避免存在实现类必须实现它不需要的方法。
从根源上,遵守它只是为了优化代码结构,避免因为代码阅读难度大而产生人为的编码错误。当细分后的接口体量足够小巧后,尽管可能仍有小部分实现类不得不实现它不需要的方法,整个程序其实还是违背接口隔离原则的,但其实我们的目的已经达到了。单一职责,要求我们分割接口功能,避免一个接口中存在两个会影响到它的功能存在。这个原则主要体现在接口的设计上,反应在接口的实现类上。毕竟是实现类中写了实现接口的方法。
如果接口设计失误,在实现类写实现方法时,多个功能之间就有可能相互干扰。相比起接口隔离带来的阅读不便问题,不遵守单一职责可能是致命的,它会降低你代码的健壮性,并有可能在未来的某一天因为某些功能相互干扰而崩溃。这两个原则其实或多或少有那么一些含糊。我们大多数时候并不清楚进行这个原则的度在哪,因为未来的功能是不可控的,我们也不可能把接口负责的功能细化到原子级别。所以,在实际生产中,这两项原则往往并不会被百分之百落实,而是根据实际情况,去尽力遵守。
如果这两个原则发生冲突,则先考虑单一职责原则。
6、合成复用原则(CRP)
什么叫合成复用
意思是,在复用时,最好使用合成的方式。
什么叫合成
合成其实就是指关联关系,也包括组合和聚合。
什么是合成复用原则
复用时要尽量使用组合/聚合关系(关联关系),少用继承。
简单来说
类的复用有两种实现方式,继承复用和合成复用
-
继承复用:
-
继承复用的优点是简单,容易操作。既然简单,那肯定有它的不妥之处。
-
继承复用存在以下缺点:
-
继承复用破坏了类的封装性。因为继承会将父类的实现细节暴露给子类,父类对子类是透明的,所以这种复用又被称为“白盒复用”。
-
子类与父类的耦合度高。父类的实现的任何改变,都会导致子类的实现发生变化,不利于类的扩展和维护。
-
继承限制了复用的灵活性。从父类继承而来的实现是静态的,在编译时就已经定义,所以在运行时不可能发生变化。
-
-
-
合成复用:
-
使用组合或聚合进行复用时,可以将已有对象纳入新对象中,使之成为新对象的一部分,新对象可以调用已有对象的功能
-
组合或聚合复用有以下优点:
-
它维持了类的封装性。因为成分对象的内部细节,新对象是看不到的,所以这种复用又被称为“黑盒复用”。
-
对象间的耦合度低。可以在类的成员位置声明抽象。
-
复用的灵活性高。这种复用可以在运行时动态进行,新对象可以动态地引用与成分对象类型相同的对象。
-
-
在使用继承时,需要严格遵循里氏代换原则,有效使用继承会有助于对问题的理解,降低复杂度,而滥用继承反而会增加系统构建和维护的难度以及系统的复杂度,因此需要慎重使用继承复用。
深入理解
复用是什么意思?它体现的不是接口等抽象设计层面的复用,而是具体代码实现层面的复用。既然复用的是具体代码,那么就要考虑复用的这部分功能,在将归属的类中,占有什么地位。
一般而言,
如果两个类之间是“Has-A”的关系应使用组合或聚合,如果是“Is-A”关系可使用继承。"Is-A"是严格的分类学意义上的定义,意思是一个类是另一个类的"一种";而"Has-A"则不同,它表示某一个角色具有某一项责任。我们不能一味地摒弃继承,而是应该参照上面的原则,去判断何时使用继承,何时使用组合或聚合。这个原则之所以被提出来,是因为大多数情况下,简单的继承不能解决问题,反而会使继承结构变得不像样子。
比如我设计了一个汽车类,设计了一个中控台类,设计了一个奔驰车类。奔驰车属于汽车,是“Is A”的关系,所以奔驰车继承汽车是没有问题的。奔驰车对中控台是“Has A”的关系,而汽车对中控台也是“Has A”的关系,所以中控台类应该注入汽车类。这样就构成了一套合理的类关系结构。
7、迪米特法则(LoD)
什么是迪米特法则
迪米特法则也可以称为最少知识法则。
意思是,一个对象应该对其他对象有最少的了解。
简单来说
一个类只和它的朋友交谈,不跟陌生人说话。
两个对象之间的耦合关系称之为朋友,通常有依赖,关联,聚合,组成等。
而直接朋友通常表现为关联,聚合和组成关系,即两个对象之间联系更为紧密,通常以成员变量,方法参数和返回值的形式出现。
举例
饲养员与仓鼠
有仓鼠类,饲养员类,顾客类
仓鼠类依赖于饲养员类,饲养员类和仓鼠类是朋友关系。顾客类也依赖于饲养员类。饲养员类和顾客类是朋友关系。但仓鼠类和顾客类不认识。
顾客类想要给仓鼠喂食,不能直接对仓鼠类进行操作,而是通过饲养员提供的方法,间接达到喂食的目的。
饲养员提供的喂食方法,也不能直接操作仓鼠类的属性,而是调用仓鼠类提供的吃东西方法,参数是顾客的喂东西方法的值。
迪米特法则的使用原则
迪米特法则的目的是让类之间解耦,降低耦合度,提高类的复用性。
但是设计原则并非有利无弊,使用迪米特法则会产生大量的中转类或跳转类,导致系统复杂度提高。
在实际的项目中,需要适度的考虑这个原则,不能因为套用原则而反而使项目设计变得复杂。
8、简述设计模式六大原则
设计模式存在的根本原因是为了更好地复用代码,增加代码可维护性。
-
开闭原则
-
对扩展开放,对修改关闭。即在程序需要进行拓展的时候,不要去修改原有的代码,而是增加新的代码。
-
这是软件设计的终极目标,其他原则都是为实现开闭原则而服务。
-
-
里氏代换原则
-
任何父类出现的地方,最好可以用子类替代。即子类是对父类的扩展,不要重写父类的方法,而是增加自己的方法。
-
-
依赖倒转原则
-
高层模块不应该依赖低层模块,二者都应该依赖其抽象。
-
高层的消费者不应该依赖于底层的具体实现,而是应该依赖一个接口,由接口屏蔽底层实现类的差异。
-
-
接口隔离原则
-
对接口做好合理的功能划分,一个实现类不应该被强迫实现它不需要的方法。
-
-
单一职责原则
-
一个类只负责一项职责,应该仅有一个引起它变化的原因。
-
比如,业务处理的逻辑一般是不变的,而业务展示的逻辑经常变动,这两类需求最好在不同的类中实现。
-
-
合成复用原则
-
要尽量的使用合成和聚合,而不是继承关系达到复用的目的
-
-
迪米特法则
-
多个对象之间应该尽量避免有任何关联,低耦合。
-
9、这些原则之间的关系
这些软件设计原则,包括各种设计模式,需要组合起来使用。只实现其中的某几项原则没什么收益。
开闭原则是软件设计的终极目标,即想要实现任何功能,最好都不要重构代码,而是通过扩展来解决。这样以往对于软件的各种依赖,都不需要做修改。
其他软件设计原则都为开闭原则服务,比如里氏代换原则。它是开闭原则的一种解决方案:通过子类来实现扩展,同时不要重写父类的方法。
而为了实现里氏代换原则,需要接口隔离原则。因为如果接口内方法过多,就不满足单一职责原则,同时实现类不得不针对不适合自己实现的方法做出抛出异常的实现,由子类去完成具体实现。那么这个接口就不满足里氏代换原则了。
实现接口隔离,需要分解接口的方法。对接口进行分解的需求,不应该由实现类提出,而是由消费者提出。比如一个消费者需要1号方法,另一个需要2、3号方法,那么就根据需要,将接口拆成两个接口。
接口隔离原则是单一职责的体现,同时服务于里氏代换原则。
而依赖倒转原则,可以指导接口隔离原则的实现。依赖倒转原则指出,高层的消费者不应该依赖于底层的具体实现,而是应该依赖一个接口,由接口屏蔽底层实现类的差异。
这个接口,是由高层的消费者定义的,它需要什么方法,就给它定义什么接口。
单一职责是所有设计原则的基础,因为只有实现了单一原则,才能做到最好的复用。
4、单例模式
单例模式详细思维导图
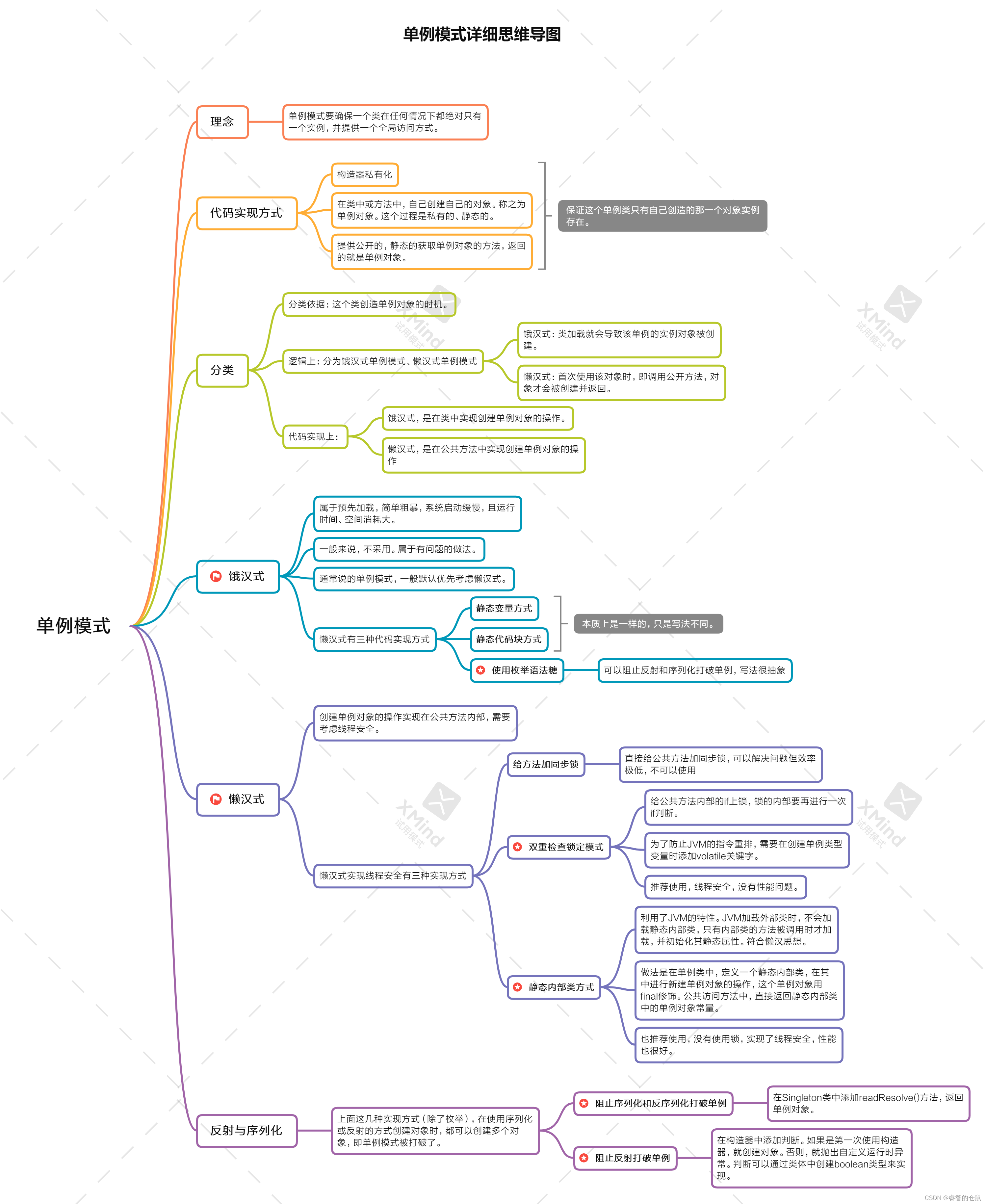
单例模式的概念
单例模式是最简单的设计模式之一,它提供了一种创建对象的最佳方式。
单例模式要确保一个类在任何情况下都绝对只有一个实例,并提供一个全局访问方式。
如何实现单例模式
该模式有三个基本要点:
-
这个类
只能有一个实例(构造器私有化); -
它必须
自行创建这个实例(自己创建自己的对象,这个过程是私有的、静态的); -
它必须
提供公开的获取这个对象的方法(public static的getInstance()方法,return instance)。
单例模式的结构
单例模式中,有两种角色:
-
单例类。只能自己创建一个实例的类
-
访问类。使用单例类
单例模式的分类
单例模式在实现时,分为两种:
-
饿汉式:
-
类加载就会导致该单例的实例对象被创建。
-
-
懒汉式:
-
而是等到
首次使用该对象时,即调用公开方法,对象才会被创建并返回,而且从始至终只创建一个对象。
-
可以看到,一个饿一个懒,各有各的大病。
饿汉式的好处是直接创建对象,不用考虑线程安全的问题。坏处也很明显,系统启动时的开销太大,不管是空间还是时间。
饿汉式属于集体预先加载。懒汉式的好处是比较灵活,节约资源,需要他了才出来。坏处是需要考虑线程安全问题。
懒汉式属于使用时才加载。
1、饿汉式
1、静态变量方式
单例类:
//饿汉式:静态成员变量方式
public final class Singleton {
//1.私有构造方法
private Singleton() {}
//2.在本类中创建自己的对象
private static final Singleton INSTANCE = new Singleton();
//3.提供该对象的一个公共访问方法
public static Singleton getInstance() {
return INSTANCE;
}
}
常见问题:
-
为什么定义成final类?
-
防止被继承后子类破坏单例
-
-
如果实现了序列化接口,如何防止反序列化破坏单例?
-
加一个方法:public Object readResolve(),返回单例对象即可
-
-
为什么设置构造器私有?能够防止反射创建新的对象?
-
构造器私有,外界就不能new出对象。不能防止反射,因为反射可以暴力反射
-
-
private static final Singleton INSTANCE = new Singleton() 是否存在单例对象创建时的线程安全问题?
-
不存在线程安全问题,因为静态成员变量的初始化操作是在类加载阶段完成的,类加载阶段由JVM保证线程安全性。
-
-
为什么选择向外提供一个public方法来获取单例对象,而不是把单例对象设置成public的?
-
更好的封装性
-
后续可以扩展更多细节,比如初始化赋值、懒加载
-
-
为什么把方法和实例属性都定义成静态?
-
因为外部无法new出对象,只能通过类名调用方法
-
静态方法只能操作静态成员变量
-
2、静态代码块方式
单例类
//饿汉式:静态代码块方式
public final class Singleton {
private static final Singleton INSTANCE;
static {
INSTANCE = new Singleton();
}
private Singleton(){}
public static Singleton getInstance(){
return INSTANCE;
}
}
访问类和上面一样。
两种写法,在逻辑上是一样的,只不过不是在声明时创建对象,而是在静态代码块中创建对象。
3、枚举方式
枚举类实现单例模式是极力推荐的单例实现模式。不考虑内存空间时应该首选使用枚举方式。
因为枚举类是线程安全的,并且只会装载一次。而且不会被反射和序列化打破。
单例类
//饿汉式:枚举方式
public enum Singleton {
INSTANCE;
}
这个枚举类本身就是单例类。
可以像普通的类一样正常使用:
public enum Singleton06 {
INSTANCE;
private String name;
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
}
public static void main(String[] args) {
Singleton06 instance = Singleton06.INSTANCE;
instance.setName("hello");
System.out.println(instance.getName());
}
常见问题:
-
枚举类如何限制实例个数?
-
枚举类定义的属性相当于静态成员变量,保证只被实例化一次
-
枚举类的构造方法是private的,外部不允许实例化
-
-
这种方式有没有线程安全问题?
-
没有,静态成员变量是在类加载阶段赋值的,由JVM保证线程安全
-
-
这种方式是否能被反射破坏单例?
-
不能,枚举类型不能通过newInstance反射
-
-
这种方式是否能被反序列化破坏单例?
-
不能,枚举类默认是实现了序列化接口的,但不用自己写readResolve,不用担心这个问题
-
-
枚举单例属于懒汉式还是饿汉式?
-
饿汉式,单例对象是在枚举类被加载的时候进行初始化的
-
-
枚举单例如果希望加入一些单例创建时的初始化逻辑该如何做?
-
加一个构造方法即可
-
2、懒汉式
1、线程不安全
单例类
//懒汉式:线程不安全
public final class Singleton {
//1.私有构造方法
private Singleton() {
}
//2.声明Singleton类型的变量
private static Singleton INSTANCE;
//3.提供该对象的一个公共访问方法
public static Singleton getInstance() {
//判断instance是否为null。如果为null,说明instance还没有被创建,就创建它。
//如果已经创建了,那就直接返回,不能新创建一个。
if (INSTANCE == null) {
INSTANCE = new Singleton();
}
return INSTANCE;
}
}
为什么这样会线程不安全?
-
比如,INSTANCE为null时,有一个线程执行了getInstance(),判断INSTANCE为null,准备new一个对象,此时发生了线程上下文切换
另一个线程也执行了getInstance(),判断INSTANCE为null,new了一个对象,将它返回。
之前的线程再次被运行,又会new一个对象,将它返回。这显然不是单例的,因为创建了多次对象。
2、同步方法
单例类
public final class Singleton {
private Singleton() {}
private static Singleton INSTANCE;
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
注意
这里的锁只能用Singleton.class,而不能用INSTANCE对象。因为它刚开始是null,null不能作为锁。
为什么这种方式不太好
单例的线程安全问题只体现在创建对象时。对于getInstance()方法来说,大部分的操作都是读操作,直接返回现有的对象,没必要加锁。
所以应该加锁,但只应该去同步创建对象的方法,而不应该对获取对象的动作上锁。
3、双重检查锁
单例类
//懒汉式:双重检查锁方式
public final class Singleton {
//1.私有构造方法
private Singleton() {
}
//2.创建Singleton类型的变量
private static volatile Singleton INSTANCE;
//3.提供该对象的一个公共访问方法
public static Singleton getInstance() {
//第一次判断,如果instance的值不为null,不需要抢占锁,直接返回对象。
if (INSTANCE != null) {
return INSTANCE;
}
synchronized (Singleton.class) {
//第二次判断
if (INSTANCE != null) {
return INSTANCE;
}
INSTANCE = new Singleton();
return INSTANCE;
}
}
}
注意:最好使用类对象 Singleton.class 作为锁
为什么要加volatile
禁用实例化时的指令重排序,否则可能出现空指针问题。
创建对象的操作可以分为三个步骤:分配内存空间、初始化对象、将引用指向内存空间。
经过指令重排后,顺序有可能变成:分配内存空间、将引用指向内存空间、初始化对象。也就是说,构造和赋值的操作顺序可能会重排。
如果一个线程已经执行完前两步,有一个其他线程来执行判断,发现INSTANCE不为null,就会返回INSTANCE。
但此时INSTANCE还尚未初始化,就会出现问题。
使用了volatile之后,instance对象的引用要么指向null,要么指向一个初始化完毕的Instance,而不会出现某个中间态,保证了安全。
为什么需要两次判空
第一次判断,是为了存在对象时快速返回,不用竞争锁。第二次判断是为了防止首次创建对象时,多个线程并发引起的问题。
首次创建对象时,INSTANCE为null。一个线程进来,获取了锁,它检查INSTANCE为null,准备创建对象。
此时另一个线程也访问该方法,发现INSTANCE为null,也参与了竞争锁。
等到前一个线程创建出了对象,释放锁,后来的这个线程拿到锁后先执行判断,发现INSTANCE不为null了,就直接返回现有的实例。
简单来说,后面的这个判断是必须的,前一个判断是额外的,用于提高效率。
4、静态内部类方式
静态内部类单例模式中,对象由内部类创建。
由于JVM在加载外部类的过程中,不会加载静态内部类,只有内部类的属性/方法被调用时才会被加载,并初始化其静态属性。
静态属性由于被static修饰,保证只被实例化一次,并且严格保证实例化顺序。
静态内部类单例模式是一种优秀的单例模式,也很常用。在没有加任何锁的前提下,保证了多线程下的安全,并且没有任何性能影响和空间的浪费。
//懒汉式:静态内部类
public class Singleton {
//私有构造方法
private Singleton() {}
//定义一个静态内部类
private static class SingletonHolder{
//在内部类中声明并初始化外部类的对象
private static final Singleton INSTANCE = new Singleton();
}
//提供公共访问方式
public static Singleton getInstance(){
return SingletonHolder.INSTANCE;
}
}
注意:
-
从外部无法访问静态内部类SingletonHolder,只有当调用Singleton.getInstance方法的时候,才能得到单例对象INSTANCE。
-
INSTANCE对象初始化的时机并不是在单例类Singleton被加载的时候,而是在调用getInstance方法,JVM加载SingletonHolder并初始化INSTANCE。
-
这种实现方式是利用classloader的加载机制来实现懒汉加载,JVM保证构建单例的线程安全,也能保证Singleton对象的唯一性。
3、反射与序列化打破单例
上面这些方法,除了枚举,都是使用private关键字来确保对象私有的。
反射可以打破private的权限检测,所以我们还是可以使用反射来强行重复构建单例对象。
不仅如此,我们也可以使用序列化和反序列化来打破单例。所以,普通的单例类是经不起反射和序列化的。
利用反射打破单例
public class Cilent1 {
public static void main(String[] args) throws Exception {
//获取Singleton的字节码对象
Class singletonClass = Singleton.class;
//获取无参构造方法对象
Constructor cons = singletonClass.getDeclaredConstructor();
//取消访问检查
cons.setAccessible(true);
//创建对象
Singleton instance = (Singleton) cons.newInstance();
Singleton instance1 = (Singleton) cons.newInstance();
//验证是否是不同对象
System.out.println(instance == instance1); //false
}
}
利用序列化与反序列化打破单例
public class Cilent {
public static void main(String[] args) throws Exception {
//writeObjectToFile();
readObjectFromFile();
readObjectFromFile();
}
//向文件中写数据
private static void writeObjectToFile() throws Exception {
//获取对象
Singleton instance = Singleton.getInstance();
//创建对象输出流对象
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("obj.txt"));
//写对象
oos.writeObject(instance);
//释放资源
oos.close();
}
//从文件中读取数据
public static void readObjectFromFile() throws Exception {
//创建对象输入流对象
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("obj.txt"));
//读取对象
Singleton instance = (Singleton) ois.readObject();
//输出对象地址
System.out.println(instance);
//释放资源
ois.close();
}
}
注意,被序列化的类要实现Serializable标记接口。
在上面的程序中,我们多次反序列化,已经序列化的instance对象,会返回多个对象,也就打破了单例模式。
如何阻止单例被强行打破
不需要多复杂,我们可以使用java自带的语法糖:enum(枚举)
如果我们确实需要使用别的方式,就使用下面的做法。
阻止序列化打破单例的解决方法
在Singleton类中添加readResolve()方法,在反序列化时被反射调用,如果定义了这个方法,就返回这个方法的值。如果没有定义,就返回新new出来的对象。
//当进行反序列化时,会自动调用该方法,将该方法的返回值直接返回。
public Object readResolve(){
return instance;
}
把这个方法添加到Singleton中即可。这样可以阻止序列化与反序列化打破单例。但无法阻止反射打破单例。
阻止反射打破单例的解决方法
反射多次创建对象的原因是,“劫持”了Singleton的构造器。之前构造器确保唯一的实现方法是,使用private阻止外部访问。但反射能关闭权限检查,一旦获取到构造器,就可以创建对象。我们要避免这种情况,就需要在构造器中添加判断。
//添加状态
private static boolean flag = false;
//1.私有构造方法
private Singleton() {
synchronized (Singleton.class) {
//判断flag的值是否为true,如果是,说明不是第一次访问了,不创建对象,抛出异常。
//如果是false,说明是第一次创建对象。
if (flag == true) {
throw new RuntimeException("不能创建多个对象!");
}
//将flag的值设置为true
flag = true;
}
}
这样,反射在多次使用构造器创建对象时,就会被异常劝退。加了同步代码块,这个做法是线程安全的。
另外,上面这两种方法可以同时使用,避免序列化和反射打破单例。
4、JDK源码中的单例模式
JDK中的Runtime类,就是使用的单例模式。
部分源码:
public class Runtime {
//饿汉式
private static Runtime currentRuntime = new Runtime();
//公共访问方法
public static Runtime getRuntime() {
return currentRuntime;
}
//私有构造方法
private Runtime() {}
}
可以看出,Runtime类使用的是饿汉式,静态属性的方式来实现单例模式的。
Runtime类是Java程序和它运行环境的桥梁,所以采用了单例模式,保证单例对象的唯一性。
5、工厂模式
2.1、工厂模式的概念
它提供了一种创建对象的最佳方式。 在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,而是通过使用一个共同的接口来指向新创建的对象。
通过工厂模式,将创建产品实例的权利移交工厂。不再通过new来创建我们所需的对象,而是通过工厂来获取我们需要的产品。降低了产品使用者与使用者之间的耦合关系。
2.2、工厂模式的分类
工厂模式下包含两种设计模式
-
工厂方法模式 -
抽象工厂模式
其中,工厂方法模式 是由简单工厂模式的基础上,增加对软件设计原则的思想,改进而来的。所以简单工厂模式并不属于23种设计模式之一。
2.3、简单工厂模式
3.1、简单工厂的思想
简单工厂模式的思想是,实例化对象时不再使用new Object这种耦合死的方式,而是通过工厂类的方法,获取工厂返回的对象。
new对象的操作,在工厂类内完成。在这个阶段,还可以修改这个对象,比如初始化赋值。
3.2、简单工厂的实现
示例 猫鼠工厂。
定义一个Animal接口,Cat和Mouse都实现了Animal接口
public interface Animal {
public void make();
}
public class Cat implements Animal{
public Cat() {
this.make();
}
@Override
public void make() {
System.out.println("you got a Cat");
}
}
public class Mouse implements Animal{
public Mouse() {
this.make();
}
@Override
public void make() {
System.out.println("you got a Mouse");
}
}
对象被创建后,会输出信息
定义一个简单工厂,用于生产Animal类型的对象
public class SimpleFactory {
public Animal getAnimal(String name) {
if (name.equalsIgnoreCase("Cat")) {
return new Cat();
} else if (name.equalsIgnoreCase("Mouse")) {
return new Mouse();
}
return null;
}
}
测试
public class doMain {
public static void main(String[] args) {
SimpleFactory simpleFactory = new SimpleFactory();
simpleFactory.getAnimal("Cat");
simpleFactory.getAnimal("Mouse");
}
}
输出
you got a Cat you got a Mouse
说明工厂成功生产了一只猫和一只老鼠。
3.3、简单工厂的设计思想
简单工厂模式的组成:简单工厂类、“产品”接口。简单工厂类用于“生产”接口类型的实例。
产品接口相当于增加了一层抽象,目的是消除实现类间的差异。
这里参照的是依赖倒转原则。
3.4、简单工厂目前存在的问题
第一,耦合
可以看到,虽然在调用时解除了耦合,但耦合转移到了工厂类中,因为还是存在直接new的操作。
如何彻底解耦?反射+配置文件。
这样,简单工厂的耦合就被彻底解决了。只需要修改配置文件,就可以设置工厂产出的具体对象的派生类。
第二,结构复杂
简单工厂彻底解除了耦合,很优秀。但它只有一个工厂类,里面存放着一堆get对象的方法,过于庞大不易维护阅读。
而且,如果要新增产品,必须重构简单工厂类,去增加响应的获取方法,严重违反开闭原则。
3.5、关于简单工厂与通用方法
简单工厂类中,每个get方法结构都非常类似,只有少部分不同。造成冗余过大。
我们可以提供一个通用方法,来获取所有对象,只需要传入该对象的派生类在配置文件中的键名即可。
解决了这个问题,简单工厂可以被称为通用工厂。
小规模下,这种通用工厂的模式可以完全解耦且非常独立,只需要修改配置文件就可以创建新的对象,适合框架这种半自动系统来使用。
但如果在大规模开发时,面向编码人员,这种做法是不合理的。因为这属于顶层架构,如果将所有实现类的配置统统放在一个配置文件中,存在着配置文件过大且杂乱,不易阅读,不易查找的问题。
结论是,在普通的开发中,配置文件只应该用于最基础工厂的解耦操作,而不应该用于主要的对象管理,因为人员不是框架,很难精准操作。那么,简单工厂的冗余问题就不能通过缩减整合方法来实现,而应该去分门别类成不同的小工厂类来实现。很自然的,这些小工厂需要一个抽象层,也就是一个抽象的工厂接口。
3.6、简单工厂的优缺点
简单工厂的好处:
-
解耦,便于升级维护 -
可以
隐藏对象创建和修改的细节,客户端只需要接收对象即可
简单工厂的缺陷:
-
简单工厂类内部结构臃肿
-
每次增加对象的创建都需要重构简单工厂类,违反了开闭原则
2.4、工厂方法模式
工厂方法模式是对简单工厂模式进一步的去除冗余。
工厂方法模式,里面直接产出的不是对象,而是工厂方法。类似一个分配中心。
4.1、简单工厂存在的问题
只有一个简单工厂类来产出所有对象,结构复杂。急需分类。
4.2、工厂方法模式的思想
在工厂方法模式中,一个产品类对应一个工厂类,而这些工厂类都实现于一个抽象接口。
也就是定义一个抽象工厂,其定义了产品的生产接口,但不负责具体的产品,而是将生产任务交给不同的派生类工厂。
相当于是把原本会因为业务代码而庞大的简单工厂类,拆分成了一个个的工厂类,这样代码就不会都整合在同一个类里了。
拆分的依据,应该是产出的不同实现类。所以,一个产品对应一个工厂,抽象的工厂接口用于屏蔽小工厂间的实现差异,方便调用。
工厂接口应该提供,用于获取该产品类的抽象方法。小工厂实现这个方法,生成指定的对象并返回。
上面的猫鼠简单工厂转换为工厂方法模式的UML类图
4.3、工厂方法模式的实现
猫猫和老鼠不变,拆分简单工厂,目的是获得一个猫猫工厂和一个老鼠工厂。
编写一个抽象的工厂接口,提供生产动物的方法
public interface Factory {
Animal getAnimal();
}
编写猫猫工厂,实现生产动物的方法,返回一只新的猫猫
public class CatFactory implements AbstractFactory{
@Override
public Animal getAnimal() {
return new Cat();
}
}
编写老鼠工厂,实现生产动物的方法,返回一只新的老鼠
public class MouseFactory implements AbstractFactory{
@Override
public Animal getAnimal() {
return new Mouse();
}
}
测试
public class doMain {
public static void main(String[] args) {
Factory factory = new CatFactory();
catFactory.getAnimal();
Factory factory = new MouseFactory();
mouseFactory.getAnimal();
}
}
输出
you got a Cat you got a Mouse
说明成功通过工厂方法模式获取到了对象
4.4、工厂方法模式的优缺点
工厂方法模式中,要增加产品类时也要相应地增加工厂类。
客户端调用时,需要指明调用的小工厂,调用其内部的方法。
优点
-
各个不同功能的实例对象的创建代码,没有整合在同一个工厂类里。实现了对简单工厂的拆分
-
克服了简单工厂会违背开闭原则的缺点,又保持了封装对象创建过程的优点
缺点
-
每增加一个产品类,就需要增加一个对应的工厂类,增加了额外的开发量。
2.5、抽象工厂模式
抽象工厂模式与工厂方法模式是两种不同的设计模式,对应不同的场景,没有简单的孰优孰劣。
注意:
1、一个项目中,可以设计多个工厂,根据实际需要来定。
2、有时,工厂方法模式和抽象工厂模式可以很轻易地转换。常常是添加了一个抽象之后,才发现此时的结构从工厂方法变成了抽象工厂。
5、结构型模式
5.1、代理模式
1.1、代理模式的概念
代理模式中,存在代理类和委托类的关系。代理类相当于房产中介,而委托类相当于房东。
代理类与委托类有同样的接口,代理类主要负责为委托类 预处理消息、过滤消息、把消息转发给委托类,以及事后处理消息等。
代理类的对象本身并不真正实现服务,而是通过调用委托类的对象的相关方法,来提供特定的服务。
简单的说就是,我们在访问实际对象时,是通过代理对象来访问的,代理模式就是在访问实际对象时引入一定程度的间接性,因为这种间接性,可以附加多种用途。
具体见spring里的代理模式

















 5596
5596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









