






论文阅读:Domain-Invariant Stereo Matching Networks
ECCV2020 Oral

Abstract
现有SOTA立体匹配网络很难泛化到未见场景,这是因为不同的数据集之间有显著的差异(如颜色、照明、对比度和纹理)。在本文中,作者的目标是设计一个域不变(Domain-Invariant)的立体匹配网络(DSMNet),它能很好地泛化到未见的场景。 为了实现这一目标,作者提出了
-
i)一种新型的 "domain normalization "方法,将学习到的表征的分布归一化,使其对域差异保持不变;
-
ii)一种基于图的端到端可训练的结构保存滤波器(SGF),用于提取稳健的结构和几何表征,以进一步增强域不变的泛化。
当在合成数据上进行训练并泛化到真实测试集时,本文的模型表现明显优于STOA模型,甚至优于一些在测试集上进行微调的网络(如MC-CNN)。
Introduction
现有的监督\无监督立体匹配网络在没有微调或适应的情况下都难以泛化到没有见过的场景。

如图所示,一个特定数据集上预训练的模型在其他未见场景上产生的结果很差。
领域适应方法和迁移学习方法尝试从一个源域转移或适应到另一个新域。 通常情况下,需要大量来自新域的立体图像进行适配。 然而,这些在很多实际场景中都不能轻易获得。因此,我们仍然需要一个在没有来自新域的数据的情况下来进行视差估计的方法。
本文专注于更具挑战性但又至关重要的域泛化问题,即假设无法获得目标域数据以进行适应或微调。 也就是说要设计一个模型,可以很好地泛化到未见的数据,而不需要任何重新训练或微调。
开发域不变网络的难点在于不同域之间的差异很大,这些差异可以被分为四类:
1.图像级别的风格差异(如颜色,光照等)
2.局部差异(如对比度)
3.纹理、细节和噪音的差异
4.其它非线性的复杂的差异
上述的差异可以被近似的表示成下面一个式子:
f
(
p
)
=
α
I
(
α
p
⋅
ϕ
(
p
)
+
β
p
)
+
β
I
f(p)=\alpha_{I}\left(\alpha_{p} \cdot \phi(p)+\beta_{p}\right)+\beta_{I}
f(p)=αI(αp⋅ϕ(p)+βp)+βI
p是每个像素的特征,在不进行域转移的情况下,对于不同的数据集,f§=p。 在实际中,不同的数据集之间有不同的域偏移。其中,图像层面风格的差异(1)可以被表示为
α
I
\alpha_{I}
αI 和 $ \beta_{I}
,局部差异(
2
)被表示为
,局部差异(2)被表示为
,局部差异(2)被表示为\alpha_{p}$ ,
β
p
\beta_{p}
βp表示图像细节和噪音的差异(3),$ \phi$ 代表其他非线性的复杂差异(4)。对于同一副图像,每个像素有相同的
α
I
\alpha_{I}
αI 和 $ \beta_{I}
;不同的区域有不同的
;不同的区域有不同的
;不同的区域有不同的\alpha_{p}$ 和
β
p
\beta_{p}
βp。
在本文中,作者提出了两种新型的可训练的神经网络层,用于构建不需要进行微调或适应即可跨域泛化的DSMNet,分别是domain normalization (DN)和structure-preserving graph-based filtering (SGF)。
其中DN层归一化了特征在图像级空间维度和像素级通道维度上特征的分布。因此DN层可以减少1)图像级的风格差异和2)局部对比差异。
SGF可以进一步平滑和减少3)局部细节和噪音的差异,同时SGF还有利于捕获更加鲁棒的结构和几何表达,因此对于4)其他复杂的域差异更加鲁棒。
Proposed DSMNet
Batch Normalization
Batch Normalization已成为构建端到端深度立体匹配网络的默认特征归一化操作。 虽然在训练深度网络的过程中可以降低internal covariate shift effect,但它具有领域依赖性,对跨域泛化能力有负面影响。
BN对特征进行标准化处理如下:
x
^
i
=
1
σ
(
x
i
−
μ
i
)
\hat{x}_{i}=\frac{1}{\sigma}\left(x_{i}-\mu_{i}\right)
x^i=σ1(xi−μi)
μ i = 1 m ∑ k ∈ S i x k , σ i = 1 m ∑ k ∈ S i ( x k − μ i ) 2 + ϵ \mu_{i}=\frac{1}{m} \sum_{k \in S_{i}} x_{k}, \quad \sigma_{i}=\sqrt{\frac{1}{m} \sum_{k \in S_{i}}\left(x_{k}-\mu_{i}\right)^{2}+\epsilon} μi=m1k∈Si∑xk,σi=m1k∈Si∑(xk−μi)2+ϵ
其中x和ˆx 是输入和输出特征,i是特征的序列,μi 和σi 是对应的逐通道的平均值和标准差。在训练中每批计算平均值μ和标准差σ。 然而,不同的数据集有不同的μ和σ。因此,为一个数据集计算的μ和σ不能转移到其他数据集。
Instance Normalization
IN通过对每个样本分别进行归一化处理,克服了对数据集统计学的依赖性,计算平均值和标准差的元素来自同一个样本。因此理论上,IN是域不变的,跨空间维度(H,W)的归一化可以减少图像层面的风格变化。然而,立体匹配是在像素层面上利用其C通道的特征向量为每个像素建立准确的对应关系。 任何特征规范和缩放的不一致都将显著影响匹配成本和相似度测量结果。
Domain Normalization
本文提出的DN的公式如下:
x
^
i
′
=
x
^
i
∑
i
∈
S
i
′
∣
x
^
i
∣
2
+
ϵ
\hat{x}_{i}^{\prime}=\frac{\hat{x}_{i}}{\sqrt{\sum_{i \in S_{i}^{\prime}}\left|\hat{x}_{i}\right|^{2}+\epsilon}}
x^i′=∑i∈Si′∣x^i∣2+ϵx^i
其中
x
^
i
\hat{x}_{i}
x^i来自于IN 的结果,DN就是讲IN的结果在通道维度上做了一个L2正则化。最后在L2正则化的基础上添加了一个逐通道的缩放系数γ和偏移系数β以增加区别程度。
y
i
=
γ
i
x
^
i
′
+
β
i
y_{i}=\gamma_{i} \hat{x}_{i}^{\prime}+\beta_{i}
yi=γix^i′+βi
DN、IN、DN的差异可以通过这幅图看出来:
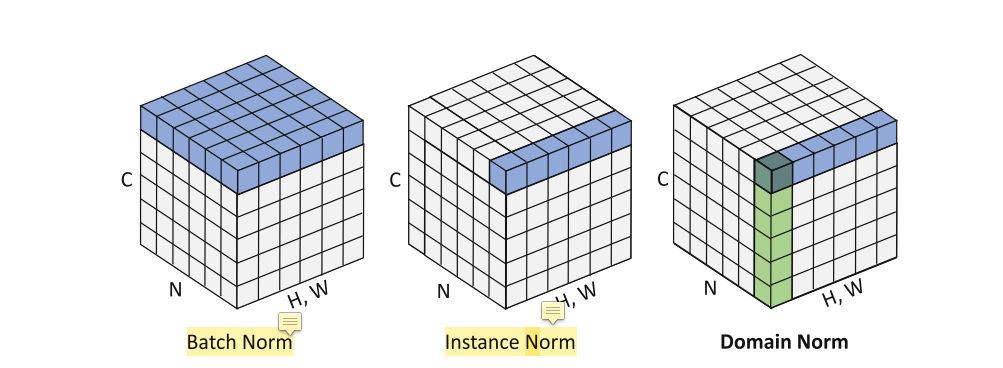
其中BN 就是 N ∗ H ∗ W N*H*W N∗H∗W个元素做Normalization,IN就是 H ∗ W H*W H∗W个元素做Normalization,而DN就是在IN的基础上在通道维度上添加了一个L2正则化。
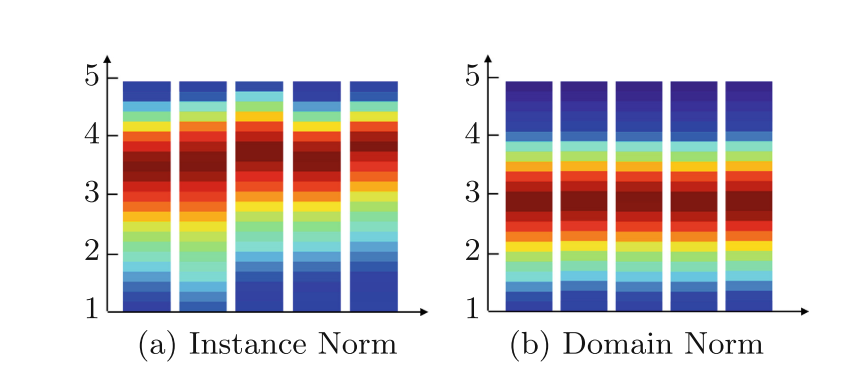
为了展示DN 的效果,作者做了一幅图,展示了N和DN后的特征向量的范数 α p \alpha_{p} αp在不同数据集上的分布,不同数据集的特征分布从左到右(合成SceneFlow、KITTI、Middlebury、CityScapes和ETH 3D) ,对每个像素处的特征向量的范数 α p \alpha_{p} αp进行统计。发现IN只能缩小图像级的差异,不同数据集的特征向量的 α p \alpha_{p} αp不一样,而DN后的不同数据级之间的 α p \alpha_{p} αp基本保持一致。
Structure-Preserving Graph-Based Filtering
本文提出了一种可训练的基于图的结构保存滤波器(SGF),它利用上下文信息,避免只记忆局部敏感的纹理、细节或噪声以增强立体匹配的健壮性。我们的灵感来自于传统的基于图的滤波器,它能有效地利用结构和几何信息来保存结构和去除/平滑细节、去噪。
Formulation
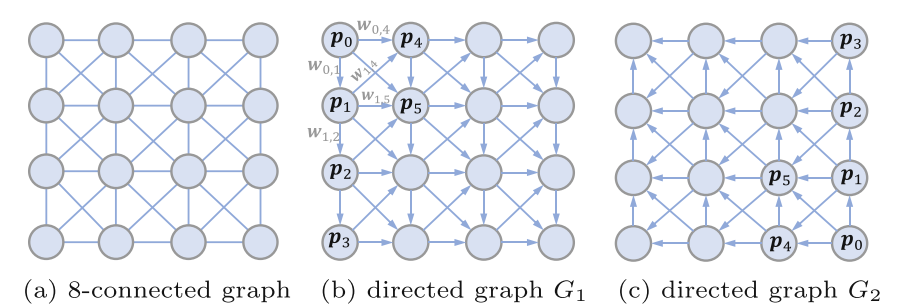
对于一副特征图I,我们通过将像素p与它的八个邻域连接起来,构建一个8连通图。为了避免循环,实现对图的快速信息聚合,我们将图分成相反的有向图G1和G2。
设置每一个边的权重为
ω
e
\omega_{e}
ωe,每一个节点的特征向量为
C
(
p
)
C(\mathbf{p})
C(p),p和自己本身的权重为
ω
e
(
p
,
p
)
\omega_{e}(\mathbf{p}, \mathbf{p})
ωe(p,p),对于图
G
i
(
i
=
0
,
1
)
G_{i}(i=0,1)
Gi(i=0,1),SGF的计算就可以表示为如下:
C
i
A
(
p
)
=
∑
q
∈
G
i
W
(
q
,
p
)
⋅
C
(
q
)
∑
q
∈
G
i
W
(
q
,
p
)
,
W
(
q
,
p
)
=
∑
l
q
,
p
∈
G
i
∏
e
∈
l
q
,
p
ω
e
C_{i}^{A}(\mathbf{p})=\frac{\sum_{\mathbf{q} \in G_{i}} W(\mathbf{q}, \mathbf{p}) \cdot C(\mathbf{q})}{\sum_{\mathbf{q} \in G_{i}} W(\mathbf{q}, \mathbf{p})}, \quad W(\mathbf{q}, \mathbf{p})=\sum_{l_{\mathbf{q}, \mathbf{p}} \in G_{i}} \prod_{e \in l_{\mathbf{q}, \mathbf{p}}} \omega_{e}
CiA(p)=∑q∈GiW(q,p)∑q∈GiW(q,p)⋅C(q),W(q,p)=lq,p∈Gi∑e∈lq,p∏ωe
其中
l
q
,
p
l_{\mathbf{q}, \mathbf{p}}
lq,p是从q到p的可行路径,
e
(
q
,
q
)
e(\mathbf{q}, \mathbf{q})
e(q,q)也被包含在路径之中,并作为路径的开始。
W
(
q
,
p
)
W(\mathbf{q}, \mathbf{p})
W(q,p)实际定义了q扩散到p的信息量的多少。边缘权重的计算方式如下:
ω e ( q , p ) = x p T x q ∥ x p ∥ 2 ⋅ ∥ x q ∥ 2 \omega_{e}(\mathbf{q}, \mathbf{p})=\frac{\mathbf{x}_{\mathbf{p}}^{T} \mathbf{x}_{\mathbf{q}}}{\left\|\mathbf{x}_{\mathbf{p}}\right\|_{2} \cdot\left\|\mathbf{x}_{\mathbf{q}}\right\|_{2}} ωe(q,p)=∥xp∥2⋅∥xq∥2xpTxq
与其它有固定kernel size的局部滤波器相比,SGF能在整张图片上长距离的传播信息。为了稳定的训练和避免极端值,我们进一步对图Gi中与p相关联的权重增加一个归一化约束 ∑ q ∈ N p ω e ( q , p ) = 1 \sum_{\mathbf{q} \in N_{\mathbf{p}}} \omega_{e(\mathbf{q}, \mathbf{p})}=1 ∑q∈Npωe(q,p)=1
增加了归一化约束后,SGF的计算公式就可以进一步被简化为:
C
i
A
(
p
)
=
∑
q
∈
G
i
W
(
q
,
p
)
⋅
C
(
q
)
,
W
(
q
,
p
)
=
∑
l
q
,
p
∈
G
i
∏
e
∈
l
q
,
p
ω
e
C_{i}^{A}(\mathbf{p})=\sum_{\mathbf{q} \in G_{i}} W(\mathbf{q}, \mathbf{p}) \cdot C(\mathbf{q}), \quad W(\mathbf{q}, \mathbf{p})=\sum_{l_{\mathbf{q}, \mathbf{p}} \in G_{i}} \prod_{e \in l_{\mathbf{q}, \mathbf{p}}} \omega_{e}
CiA(p)=q∈Gi∑W(q,p)⋅C(q),W(q,p)=lq,p∈Gi∑e∈lq,p∏ωe
Linear Implementation
SGF可以实现为迭代线性聚合,其中节点按照图的方向依次更新(如在G1中,更新方向就是从上到下,再从左到右) ,在每一步中,p更新为:
C
i
A
(
p
)
=
ω
e
(
p
,
p
)
⋅
C
(
p
)
+
∑
q
∈
N
p
,
q
≠
p
ω
e
(
q
,
p
)
⋅
C
i
A
(
q
)
s.t.
∑
q
∈
N
p
ω
e
(
q
,
p
)
=
1
\begin{aligned} C_{i}^{A}(\mathbf{p}) &=\omega_{e(\mathbf{p}, \mathbf{p})} \cdot C(\mathbf{p})+\sum_{\mathbf{q} \in N_{\mathbf{p}}, \mathbf{q} \neq \mathbf{p}} \omega_{e(\mathbf{q}, \mathbf{p})} \cdot C_{i}^{A}(\mathbf{q}) \\ \text { s.t. } & \sum_{\mathbf{q} \in N_{\mathbf{p}}} \omega_{e(\mathbf{q}, \mathbf{p})}=1 \end{aligned}
CiA(p) s.t. =ωe(p,p)⋅C(p)+q∈Np,q=p∑ωe(q,p)⋅CiA(q)q∈Np∑ωe(q,p)=1
通过重复G1和G2的聚合过程,其中更新后的用G1表示,作为G2聚合的输入。
Relations to Existing Approaches
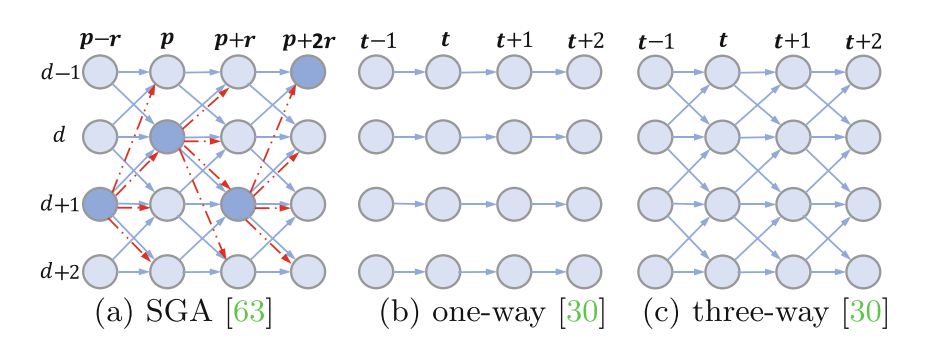
GA-Net的SGA层和基于亲和力的空间传播方法是SGF的特例。
Semi-global Aggregation (SGA)
SGA是GANet中提出的一种代价聚合方式:
C
r
A
(
p
,
d
)
=
sum
{
ω
0
(
p
,
r
)
⋅
C
(
p
,
d
)
ω
1
(
p
,
r
)
⋅
C
r
A
(
p
−
r
,
d
)
ω
2
(
p
,
r
)
⋅
C
r
A
(
p
−
r
,
d
−
1
)
ω
3
(
p
,
r
)
⋅
C
r
A
(
p
−
r
,
d
+
1
)
ω
4
(
p
,
r
)
⋅
max
i
C
r
A
(
p
−
r
,
i
)
.t.
∑
i
=
0
,
1
,
2
,
3
,
4
ω
i
(
p
,
r
)
=
1
C_{\mathbf{r}}^{A}(\mathbf{p}, d)=\operatorname{sum}\left\{\begin{array}{l} \omega_{0}(\mathbf{p}, \mathbf{r}) \cdot C(\mathbf{p}, d) \\ \omega_{1}(\mathbf{p}, \mathbf{r}) \cdot C_{\mathbf{r}}^{A}(\mathbf{p}-\mathbf{r}, d) \\ \omega_{2}(\mathbf{p}, \mathbf{r}) \cdot C_{\mathbf{r}}^{A}(\mathbf{p}-\mathbf{r}, d-1) \\ \omega_{3}(\mathbf{p}, \mathbf{r}) \cdot C_{\mathbf{r}}^{A}(\mathbf{p}-\mathbf{r}, d+1) \\ \omega_{4}(\mathbf{p}, \mathbf{r}) \cdot \max _{i} C_{\mathbf{r}}^{A}(\mathbf{p}-\mathbf{r}, i) \end{array}\right. \text { .t. } \sum_{i=0,1,2,3,4} \omega_{i}(\mathbf{p}, \mathbf{r})=1
CrA(p,d)=sum⎩
⎨
⎧ω0(p,r)⋅C(p,d)ω1(p,r)⋅CrA(p−r,d)ω2(p,r)⋅CrA(p−r,d−1)ω3(p,r)⋅CrA(p−r,d+1)ω4(p,r)⋅maxiCrA(p−r,i) .t. i=0,1,2,3,4∑ωi(p,r)=1
SGA在四个方向上进行聚合,即r={(0,1),(0,-1),(1,0),(-1,0)},并且在不同的视差上也进行了聚合。(p - r,d±1)为p的邻域节点,ω0,…4为对应的权重。
Affinity-based Spatial Propagation
基于亲和力的空间传播方法:
C
A
(
p
,
d
)
=
(
1
−
∑
q
∈
N
p
,
q
≠
p
ω
e
(
q
,
p
)
)
C
(
p
)
+
∑
q
∈
N
p
,
q
≠
p
ω
e
(
q
,
p
)
C
A
(
q
)
C^{A}(\mathbf{p}, d)=\left(1-\sum_{\mathbf{q} \in N_{\mathbf{p}}, \mathbf{q} \neq \mathbf{p}} \omega_{e(\mathbf{q}, \mathbf{p})}\right) C(\mathbf{p})+\sum_{\mathbf{q} \in N_{\mathbf{p}}, \mathbf{q} \neq \mathbf{p}} \omega_{e(\mathbf{q}, \mathbf{p})} C^{A}(\mathbf{q})
CA(p,d)=
1−q∈Np,q=p∑ωe(q,p)
C(p)+q∈Np,q=p∑ωe(q,p)CA(q)
其中
ω
e
(
q
,
p
)
\omega_{e}(\mathbf{q}, \mathbf{p})
ωe(q,p)是学习到的亲和力,类似于SGF中的不同节点之间的权重,而
1
−
∑
q
∈
N
p
ω
e
(
q
,
p
)
1-\sum_{\mathbf{q} \in N_{\mathbf{p}}} \omega_{e(\mathbf{q}, \mathbf{p})}
1−q∈Np∑ωe(q,p)就类似于SGF中节点自己到自己权重
ω
e
(
p
,
p
)
\omega_{\mathbf{e}(\mathbf{p}, \mathbf{p})}
ωe(p,p)
Non-local Strategies, Graph Neural Networks and Attentions
非全局策略、图网络和注意力机制用于非局部的特征聚合的常用方式,现有的注意力和GNNs只考虑了特征相似性进行聚合,它对像素位置一视同仁。
在几何问题中(如 立体匹配),空间上的接近性对于学习准确的深度至关重要,因为同一对象/类(具有相似特征)的像素必须在空间上足够接近,才能具有相似的深度值。 因此,这些基于相似性/亲和力的关注和非局部网络将很容易地平滑深度边缘和薄结构。 SGF利用特征亲和力和空间接近性进行非局部图的过滤。 它将沿路径的特征进行空间聚合,可以更好地保存差异图的结构。 更重要的是,由于SGF是通过线性空间传播实现的,而且权重矩阵只有5×N,因此在内存需求和计算上都具有较低的(线性)复杂性。
Network Architecture
网络结构以GANet作为Backbone,移除了GANet中的LGA层(因为它依赖于域,并捕捉到了很多对域变化非常敏感的局部图案),并且把BatchNormal层替换成了本文提出的Domain Nomal层。在特征提取阶段有七个SGF层,在3D代价体聚合层有两个SGF层,分别用于通道维度和深度维度。

Experimental Results
KITTI 2012年和2015年的数据集提供了约400个户外驾驶场景的图像对进行训练,其中的视差标签是由Velodyne LiDAR转化而来。 Cityscapes数据集提供了大量从城市驾驶场景中收集的高分辨率(1k×2k)立体图像。 视差标签是由SGM预先计算出来的,这对于训练深度神经网络模型来说不够准确。 Middlebury立体数据集是为具有较高分辨率(最高2k×3k)的室内场景设计的。 但它提供的图像对不超过50个,不足以训练强大的深度神经网络。 这些现有的真实数据集都受到数量少或GT标签的限制,使得它们不足以用于训练。 因此,本文将它们作为测试集来评估我们模型的跨域泛化能力。
本文的网络只用合成数据训练(Scene Flow synthetic dataset,35k个训练图像对,分辨率为540×960),同时还用CARLA生成了一个新合成数据集(有2万对图像对)。使用合成数据的两个优点是,它可以避免所有的对大量真实数据进行标注的困难,并且它可以消除真实数据集中错误的深度值带来的负面影响。
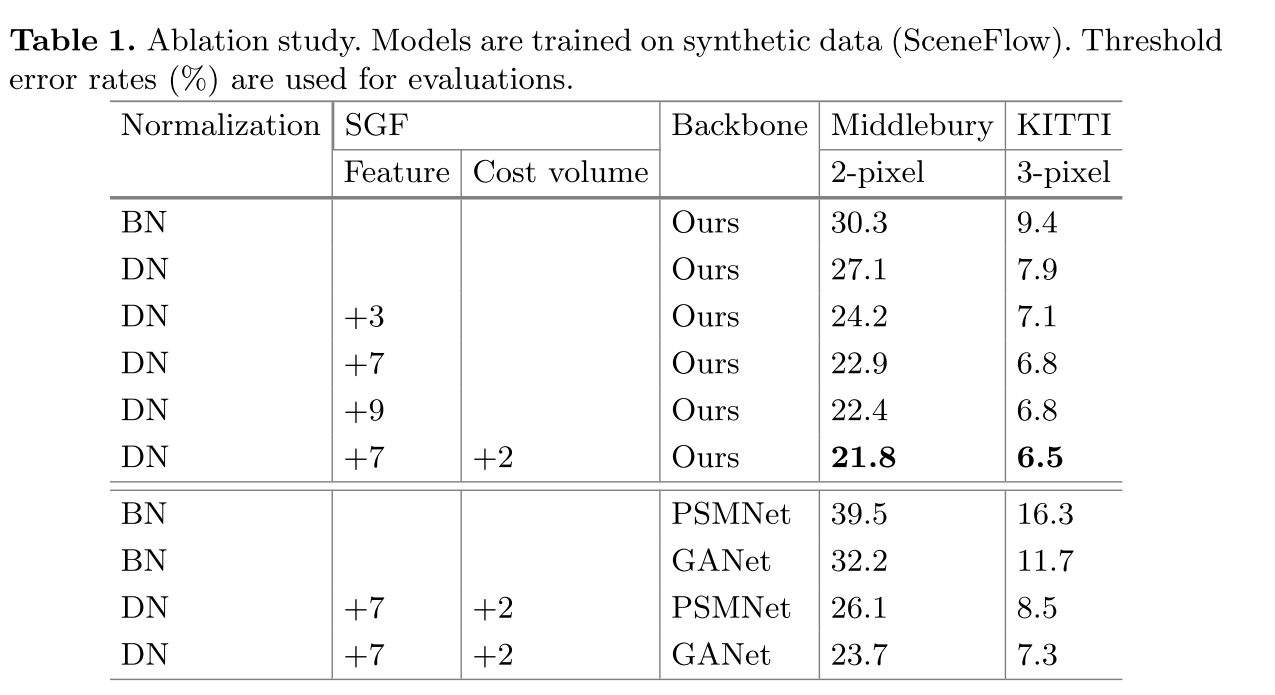
展示了DN层的效果,随着DN层的增加,误差下降。
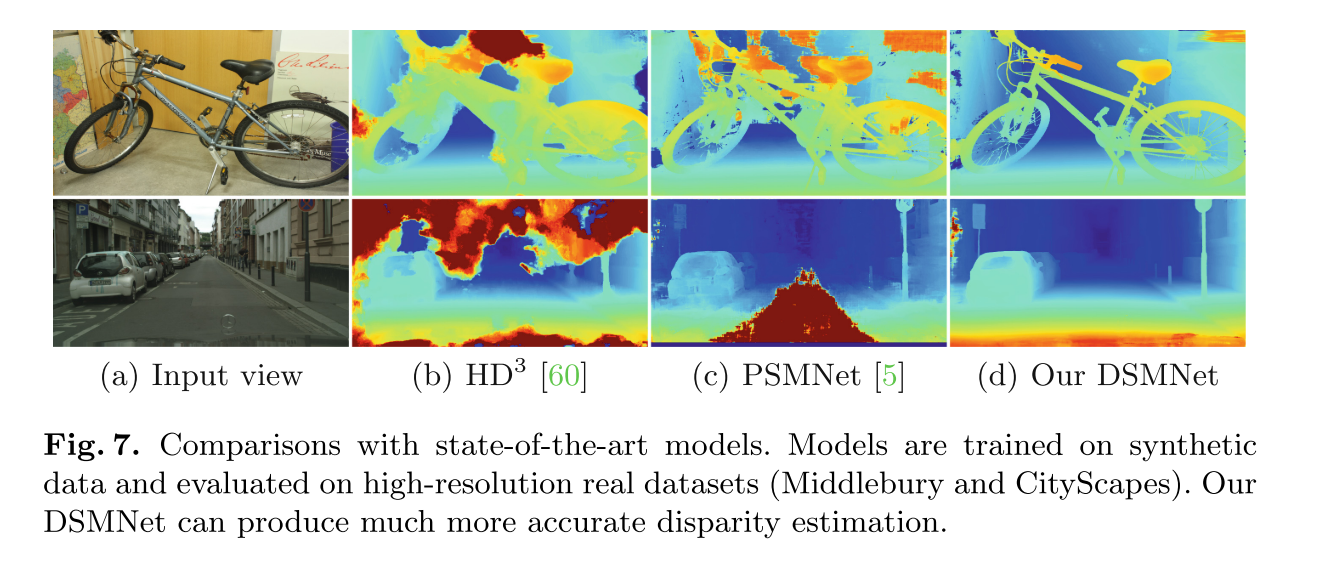
优异的跨域表现,在合成数据集上进行训练的图片在真实数据及上有准确的深度预测。
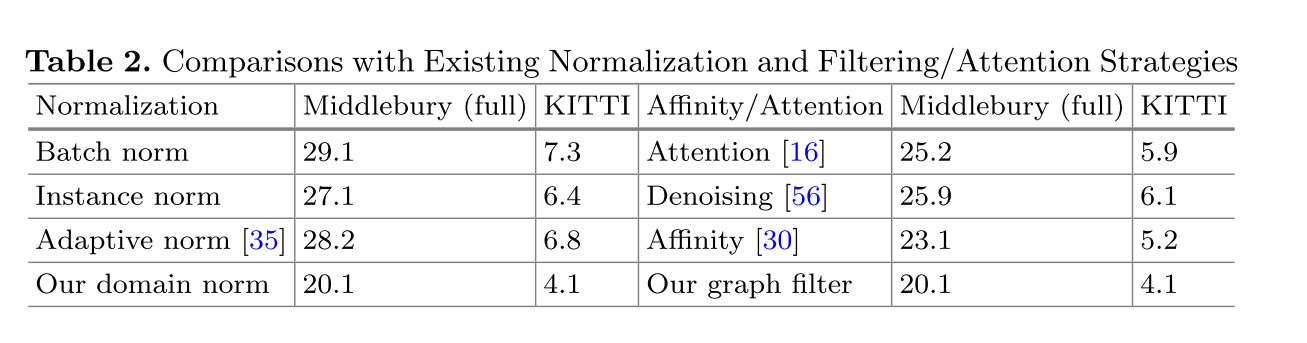
和BN\IN\AN的对比
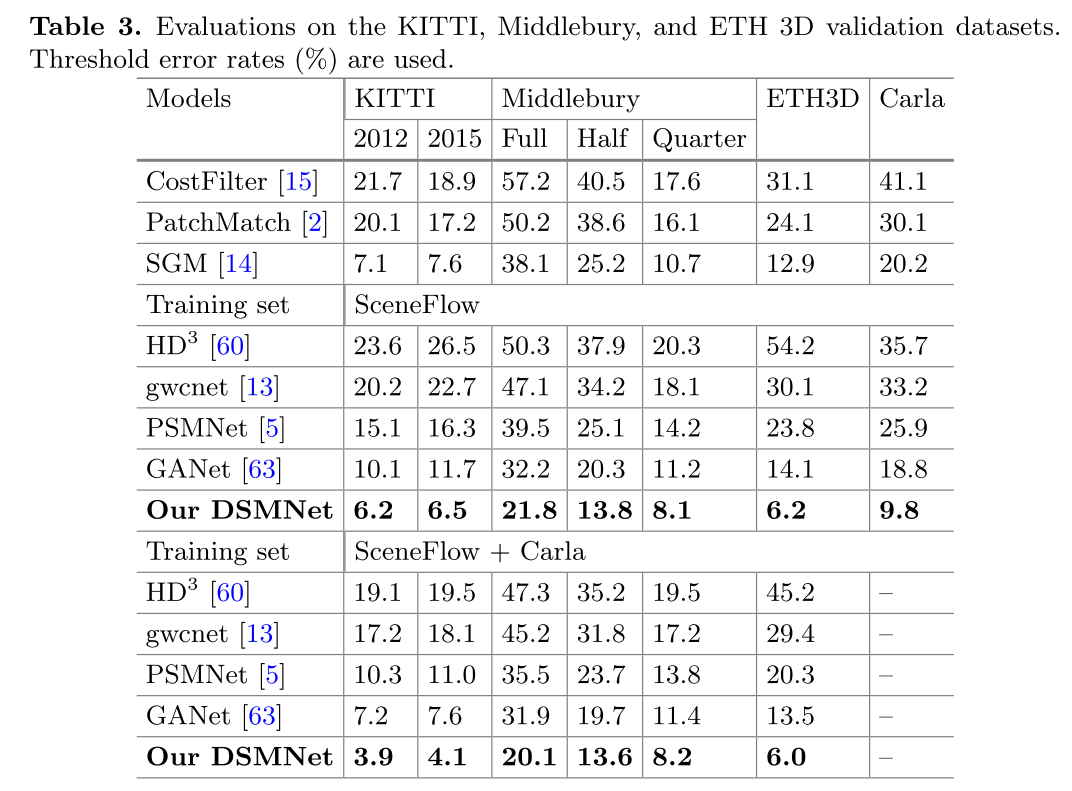
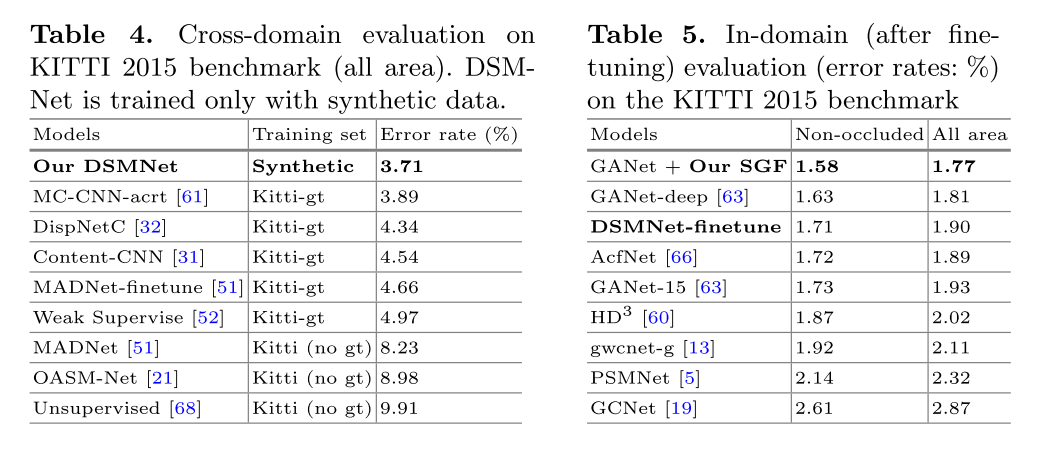
微调后的表现也很好
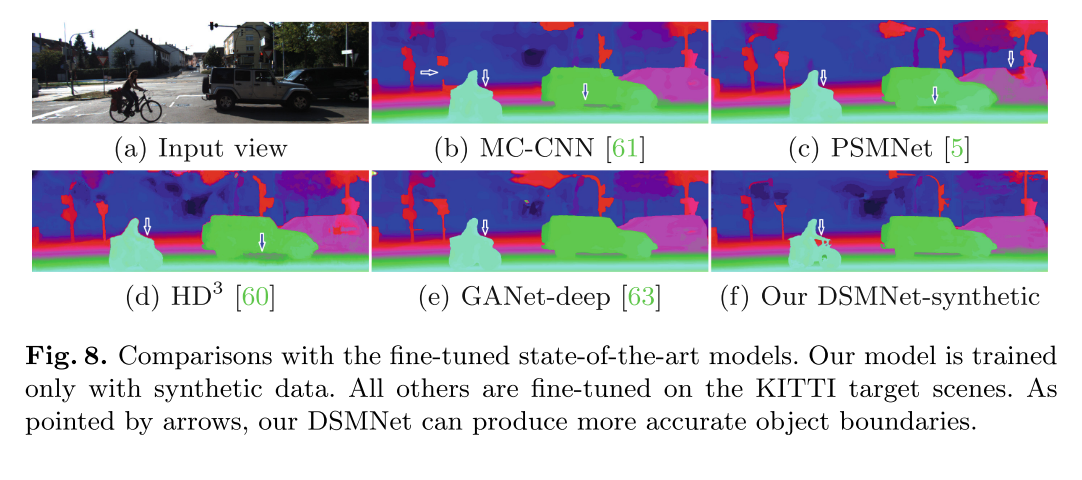
展示了DSMNet在目标域上进行微调时的最佳性能
可以迁移到光流预测上
















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









