







目录
3.2 Structure-preserving Graph-based Filtering
摘要:
在本文中,我们的目标是设计一个领域不变的立体匹配网络(DSMNet),它可以很好地推广到看不见的场景中。
为了实现这一目标,我们提出了:
i)一种新的“领域标准化”方法,规范化学习表示的分布,使它们对领域的差异是不变,
ii)一个端到端可训练的结构保留图的过滤器来提取鲁棒的结构和几何表示,可以进一步增强领域不变推广。
1.介绍
然而,最先进的立体声匹配网络(监督[5,19,63]和无监督[51,68])不能在没有微调或适应的情况下很好地推广到不可见的数据。它们的困难在于很大的领域差异(如颜色、照明、对比度和纹理)。如图1所示,一个特定数据集上的预训练模型在其他真实和看不见的场景上产生糟糕的结果。
领域自适应和转移学习方法。[3,12,51])尝试将其从一个源域传输或适应到另一个新域。通常,自适应需要大量来自新领域的立体图像。然而,这些在许多真实的场景中是不容易得到的。然而,我们仍然需要一个很好的方法来估计视差,即使没有来自新领域的数据来自适应。
我们关注的是更具挑战性但更关键的领域泛化[1]问题,它假设没有访问目标信息来进行适应或微调。也就是说,我们试图设计一个模型,可以很好地推广到看不见的数据,而没有任何再训练或适应。
设计这样一个域不变立体匹配网络DSMNet的困难来源于显著的域差异,4个方面:
1.图像级样式:颜色、照明
2.局部变化:对比度
3.纹理图案、细节和噪声约束
4.其他复杂的领域转移(不常见的/非线性的内容)
可以描述为:
![]()
p是每个像素的特征。
图像级的样式差异可以表示为αI和βI。图像的像素具有相同的αI和βI。
局部的变化(对比度)是αp;βp表示图像的细节/噪声。局部移位αp和βp在不同的区域/像素内发生变化
而φ是其他不常见的领域差异的表达式,它们不能轻易地表述为特定的模型。
在本文中,我们提出了两种新的可训练的神经网络层来构建不需要优化或自适应的跨域泛化的DSMNet。
3.DSMNet
1.我们提出了一种新的域归一化(DN)来消除图像级域位移的影响(αI和βI:例如。颜色、风格、照度)和局部对比度的变化(等式(1)中的αp。
2.可训练的基于结构保持图的滤波(SGF)层来平滑域敏感的局部噪声/细节(βp),并捕获结构和几何上下文作为域不变立体重建的鲁棒特征。
3.1 Domain Normalization
BN:
6张图片的相同通道进行Normalization
它与域相关,对跨域泛化能力有负面影响。
IN:
1张图片的1个通道进行Normalization
实例规范化只能减少图像级的差异,但不能规范化像素级的C通道特征向量。

我们的方法将沿空间轴(H、W)的特征标准化,以诱导类似于IN以及沿通道维数(C)的样式不变表示,以增强局部不变性。

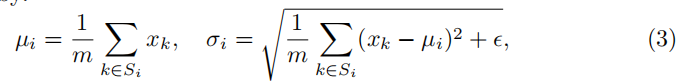
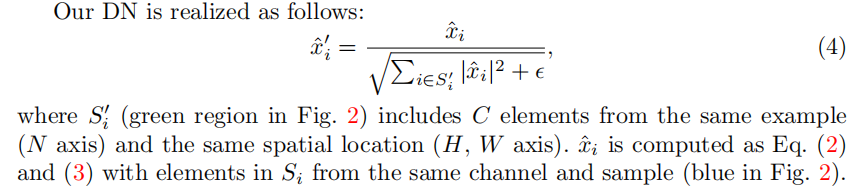
在我们的DN中,除了跨空间维归一化,我们还使用L2归一化来沿通道轴的特征归一化。他们相互合作,以解决对图像级别域位移的敏感性(等式中的αI和βI)(1))和局部对比度变化(αp)。
最后,增加了可训练的每通道尺度γ和shift β,以增强作为BN和IN的鉴别表示能力

3.2 Structure-preserving Graph-based Filtering
我们的灵感来自于传统的基于图的滤波器,它们在使用结构和几何信息进行结构保护纹理和细节去除/平滑[62]、[6,62]去噪、以及深度感知估计和增强[29,58]方面非常有效。
对于一个二维图像/特征图I,我们通过将像素p连接到它的8个邻域来构造一个8连通图(见图4)。为了避免循环和实现在图上的快速信息聚合,我们将其分为两个反向的有向图G1、G2(见图4(b)和4(c))。我们将权重ωe分配给每个边的e∈G,并为每个节点的p∈G分配一个特征(或颜色)向量C(p)。我们还允许p用权重ωe(p,p)向自己传播信息。对于图Gi(i=0,1),我们的SGF的定义如下:
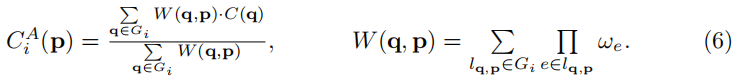

lq,p是一个从q到p的可行路径。我们考虑了从源节点q到目标节点p的所有有效路径。
沿路径lq,p的传播权重是沿路径上所有边权重ωe的乘积。这里的权值W(q,p)被定义为从q到p的所有可行路径的权值的和,这决定了从q扩散到p有多少信息。
对于边权值ω(q、p),我们以自正则化的方式定义它如下:
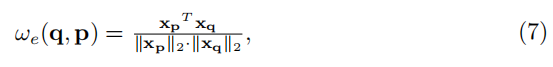
其中,xp和xq分别表示p和q的特征向量。
为了进行稳定的训练和避免极值,我们进一步向图Gi中与p相关的权值添加了一个标准化约束,如:

Np是p(包括其自身)的连接相邻邻居的集合,e(q、p)是连接q和p的直接边。
For example, in Fig. 4(b), for node p0, ωe(p0,p0) = 1; and for node p4, ω0,4 + ω1,4 + ωe(p4,p4) = 1.
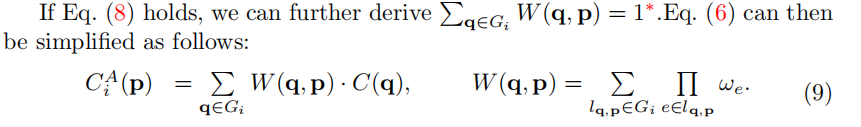
线性实现
等式(9)可以实现为一个迭代的线性聚合,其中节点按照图的方向按顺序更新。从上到下,然后从左到右,在G1中。在每个步骤中,p都被更新为:
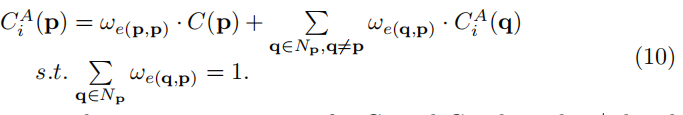
最后,我们重复了G1和G2的聚合过程,其中使用G1的更新表示被用作使用G2的聚合的输入。等式的聚合(10)是一个时间复杂度为O(n)的线性过程(图中有n个节点)。在训练过程中,可以实现反向传播,这也是一个线性过程
3.3 Network Architecture
我们利用GANet的主干作为基线架构。我们删除了[63]中的LGA层,因为它依赖于域,并且捕获了许多对域位移非常敏感的本地模式。

我们将原始的批处理归一化层替换为我们提出的域归一化层来进行特征提取。对于特征提取网络,我们总共使用了七个提出的过滤层。对于成本量的三维成本聚合,进一步增加两个SGF层,用于每个通道/深度的成本量过滤。
6.结论
在本文中,我们提出了我们域不变立体匹配网络的两个端到端可训练神经网络层。我们的新域归一化可以完全调节学习特征的分布,以解决显著的域位移,我们的SGF可以捕获更鲁棒的非局部结构和几何特征,以在跨域情况下精确的视差估计。我们已经在四个真实数据集上验证了我们的模型,并显示了它在跨域泛化中比其他最先进的模型更优越的精度。















 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









