







1. 研究问题
由于显着的域差异,例如颜色、照明、对比度和纹理,最先进的立体匹配网络难以泛化到新的未知环境。
2. 研究方法
所提出的域不变的立体匹配网络(DSMNet),设计了两个新颖的可训练神经网络层,可以很好地进行跨域泛化,无需微调或域适应。提出了的域归一化(DN),该方法可以规范学习表示的分布,使它们对域差异保持不变,另外,提出的非局部结构保留的基于图的过滤层(SGF),可以提取鲁棒的结构和几何表示,从而进一步增强域不变泛化。
2.1 域差异的分类
- 图像级样式(例如颜色,照明 )
- 局部变化(例如对比度)
- 纹理图案,细节和噪声条件
- 其他复杂的域转移(例如不常见/非线性内容)
域差异可以用下式表达:
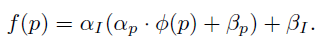
p
p
p是原图的像素特征,
f
(
p
)
f(p)
f(p)是域差异存在时的像素特征。
其中图像级差异用 α I \alpha_I αI和 β I \beta_I βI表示,一张图像的所有像素的 α I \alpha_I αI和 β I \beta_I βI都相同,局部变化用 α p \alpha_p αp表示,图像细节/噪声用 β p \beta_p βp表示,局部偏移 α p \alpha_p αp和 β p \beta_p βp在不同像素/局部都不相同,不常见/非线性内容用 ϕ \phi ϕ表示。
2.2 DSMNet
提出了两个新颖的神经网络层,首先,提出域归一化(DN)层在图像级空间(高度和宽度)和像素级通道维度上完全调节特征的分布,以移除图像级域偏移和局部对比度变化的影响。然后提出非局部结构保留的基于图的过滤(SGF)层,进一步平滑域敏感的局部噪声/细节,它还有助于捕获更鲁棒的结构和几何表示,对其他复杂域差异更鲁棒。
2.2.1 Domain Normalization
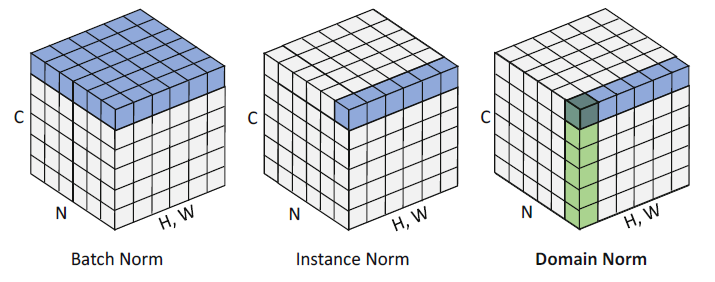
Batch Normalization (BN)
BN的公式如下所示:
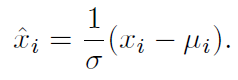
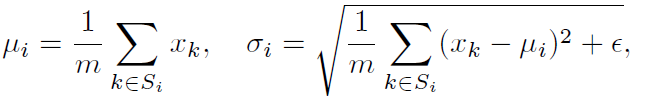
BN在立体立体匹配网络中已经是默认的特征归一化操作了,虽然它可以减少训练深度网络中的内部协变量移位效应,加快训练,但它是域相关的,对跨域泛化能力有负面影响。具体来说,在一个数据集上计算的BN的均值和标准差不能迁移到其他数据集上,否则对泛化产生负面影响。
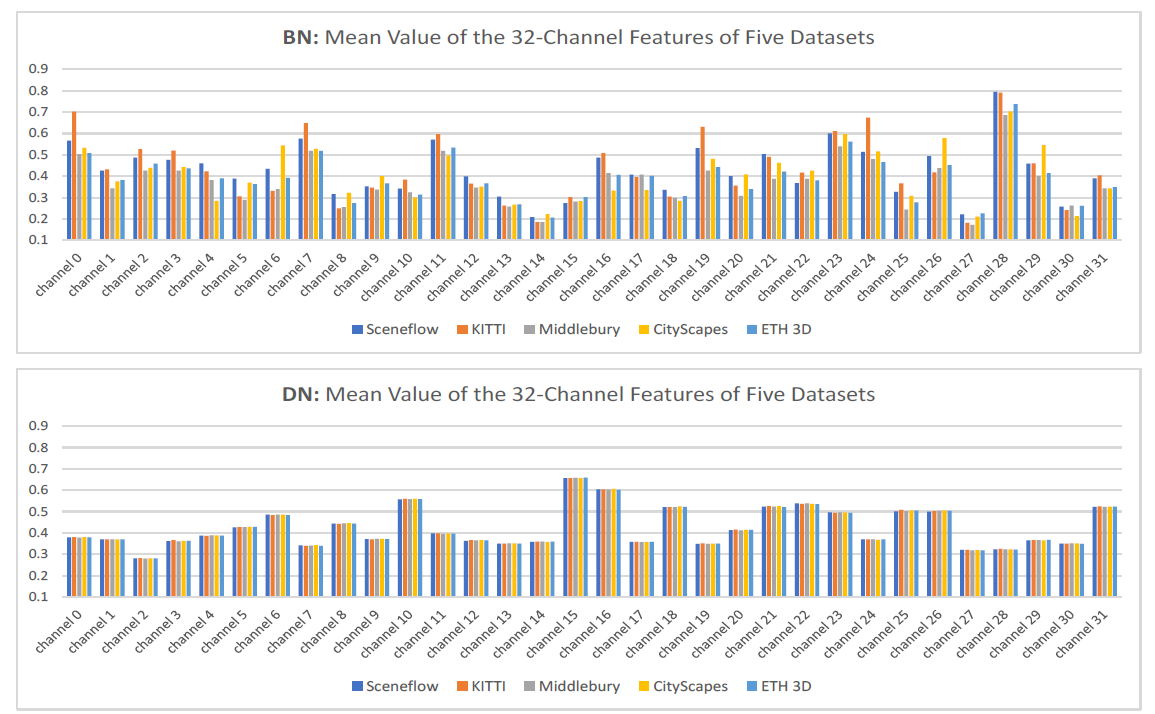
如下图所示,使用BN进行归一化后,特征提取网络的输出中,对于不同的数据集,每个通道的均值和方差都不同,大大影响了模型的泛化性能。而使用DN进行归一化后,每个通道的均值和方差都接近一致,表明了网络的泛化性能很好。
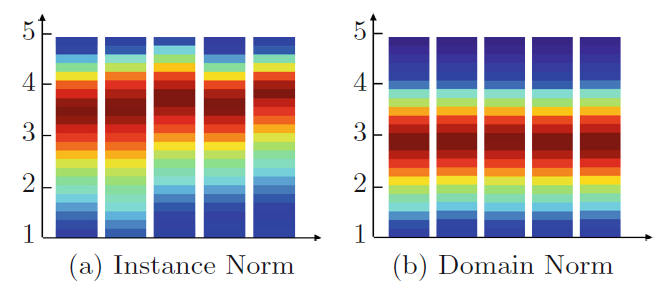
Instance Normalization (IN)
IN与BN的区别是IN在每个样本上进行归一化,理论上,IN 是域不变的, 跨空间维度(H,W)的归一化减少了图像级别的样式变化。然而,立体视图的匹配是通过使用每个像素的 C 通道特征向量找到每个像素的准确对应关系在像素级别实现的。特征范数和尺度的任何不一致都会显着影响匹配成本和相似性测量。
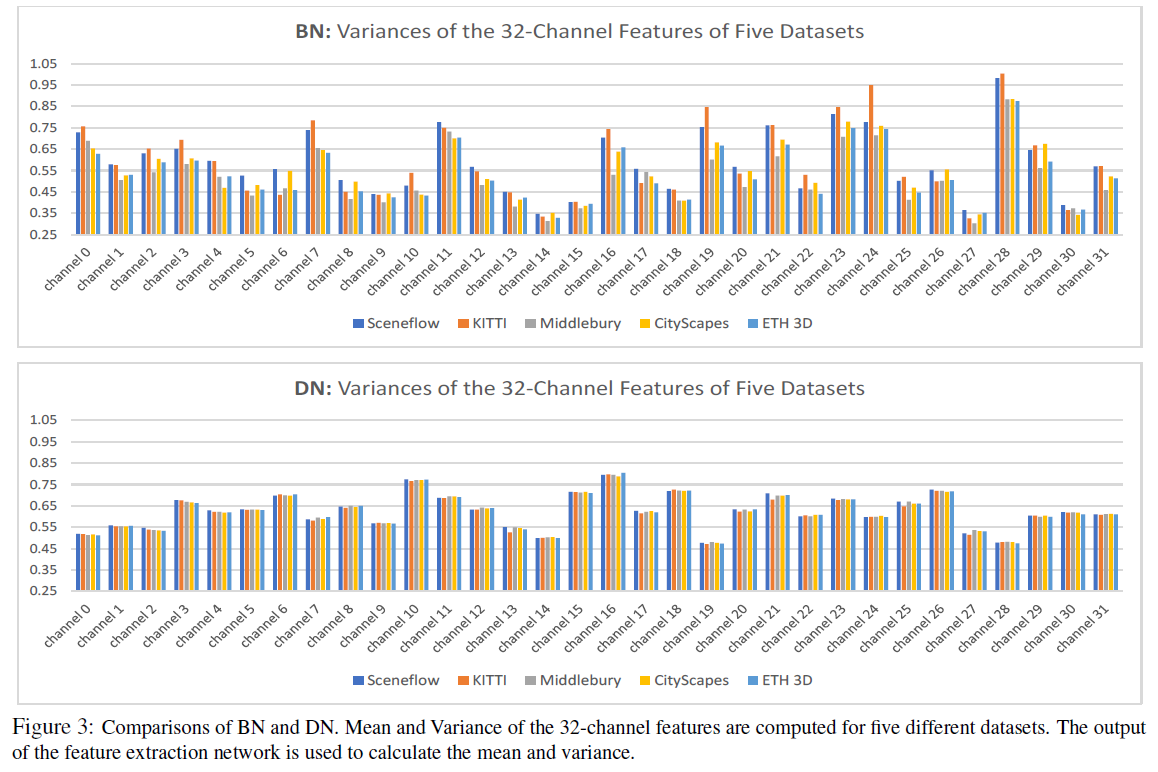
如下图所示,五个条是在五个不同的数据集上的每个通道输出特征的范数(考虑所有像素),可以看到,IN无法解决不同数据集在各个通道上的域差异。这样会影响匹配成本的质量,从而影响视差图的精度。
domain-invariant normalization (DN)
DN中,除了跨空间维归一化,还使用L2归一化来沿通道轴的特征归一化。如下所示:
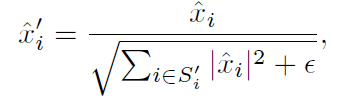
最后在L2正则化的基础上添加了一个逐通道的缩放系数γ和偏移系数β以增加表示能力:
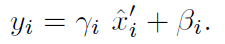
2.2.2 Structure-Preserving Graph-Based Filtering(SGF)
本文提出了一种可训练的基于结构保留图的滤波器(SGF),它利用上下文信息并避免仅仅记住局部域敏感的纹理模式、细节或噪声以实现稳健的立体匹配。本文的灵感来自于传统的基于图的滤波器,它能有效地利用结构和几何信息来保存结构和去除/平滑细节、去噪。
Formulation
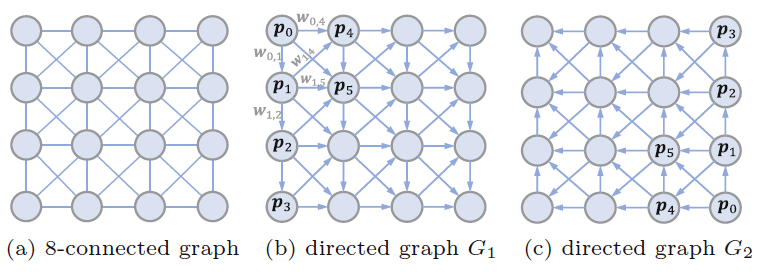
对于一幅特征图 I I I,我们通过将像素p与它的八个邻域连接起来,构建一个8连通图。为了避免循环,实现对图的快速信息聚合,我们将图分成相反的有向图G1和G2。如下图所示:
设置每一个边的权重为
ω
e
\omega_e
ωe,每一个节点的特征向量为
C
(
p
)
C(p)
C(p),p和自己本身的权重为
ω
e
(
p
,
p
)
\omega_e(p,p)
ωe(p,p),对于图
G
i
(
i
=
0
,
1
)
G_i(i=0,1)
Gi(i=0,1),SGF的计算就可以表示为如下:
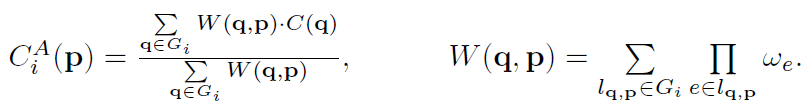
其中
l
q
,
p
l_{q,p}
lq,p是从q到p的可行路径,
e
(
q
,
q
)
e(q,q)
e(q,q)也被包含在路径中,并作为路径的开始。
W
(
q
,
p
)
W(q,p)
W(q,p)实际定义了q扩散到p的信息量的多少。边缘权重的计算方式如下:
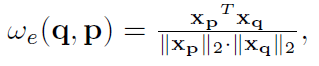
x
p
x_p
xp和
x
q
x_q
xq分别表示像素p和像素q的特征向量。
与其它有固定kernel size的局部滤波器相比,SGF能在整张图片上长距离的传播信息。为了稳定的训练和避免极端值,我们进一步对图Gi中与p相关联的权重增加一个归一化约束,
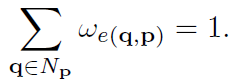
增加了归一化约束后,SGF的计算公式就可以进一步被简化为:
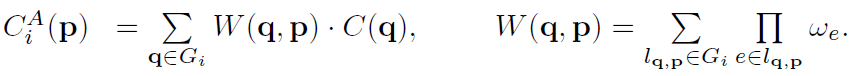
这种简化不仅增加了训练的鲁棒性,还降低了计算成本。
Linear Implementation
SGF可以实现为迭代线性聚合,其中节点按照图的方向依次更新(如在G1中,更新方向就是从上到下,再从左到右) ,在每一步中,p更新为:
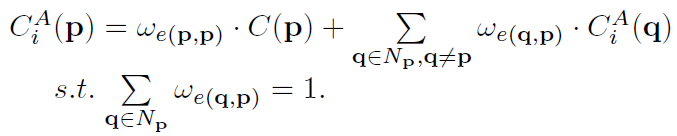
其中C可以是像素的特征向量,也可以是4D代价空间。
通过重复G1和G2的聚合过程,其中更新后的用G1表示,作为G2聚合的输入。
2.2.3 Network Architecture
网络结构以GANet作为Backbone,移除了GANet中的LGA层(因为它依赖于域,并捕捉到了很多对域变化非常敏感的局部图案),并且把BN层替换成了本文提出的DN层。在特征提取阶段有七个SGF层,在3D代价体聚合层有两个SGF层,分别用于通道维度和深度维度。
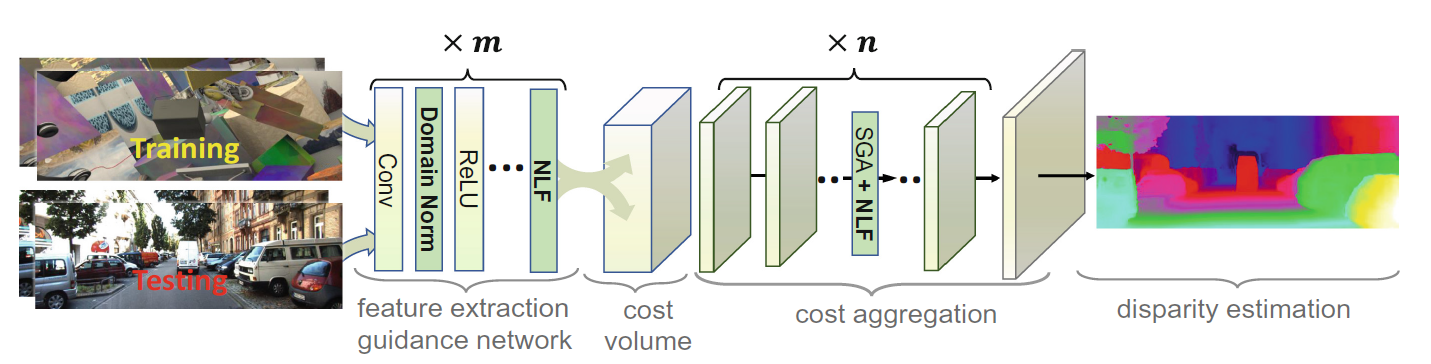
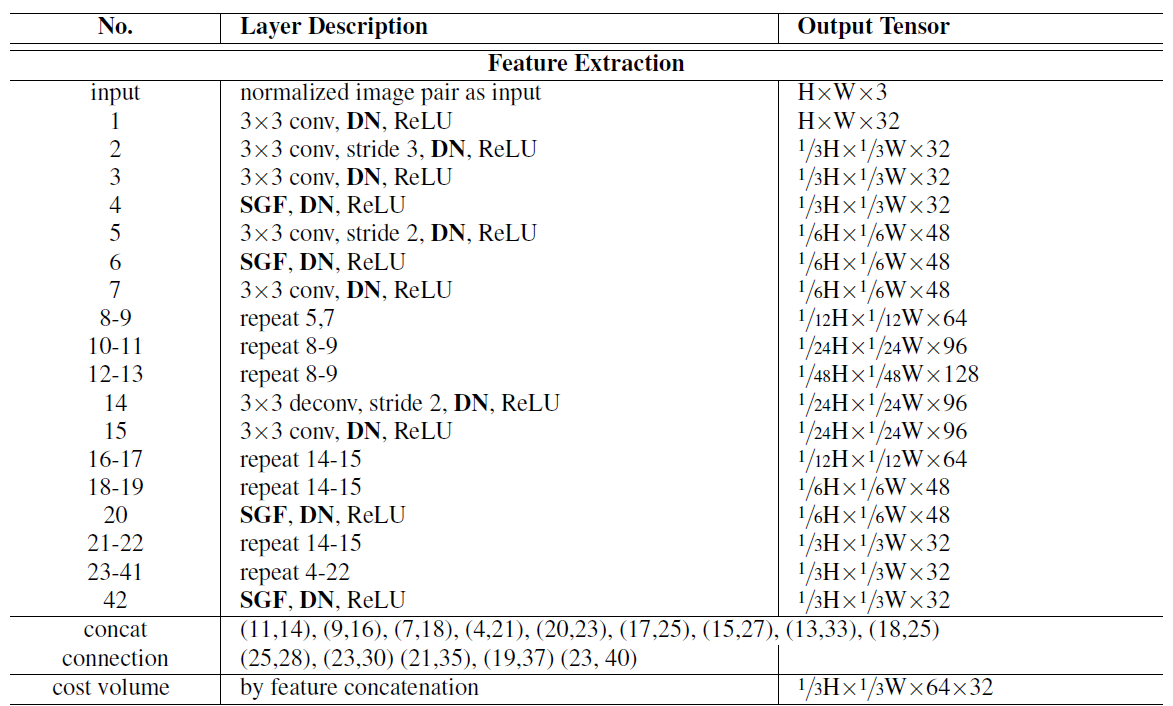
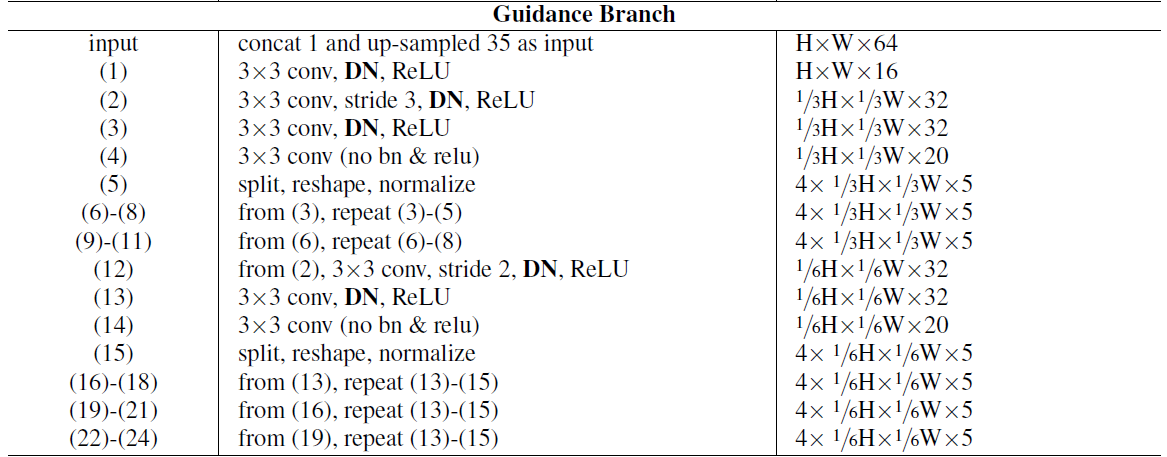
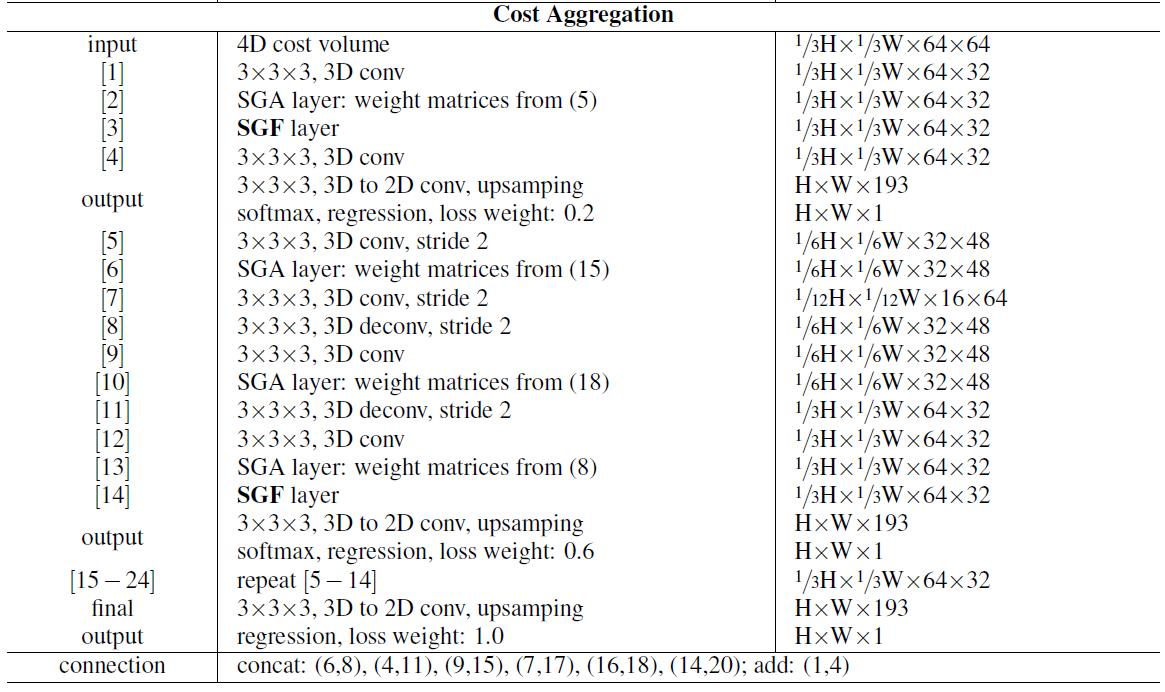
2.2.4 视差回归和损失函数
采用soft argmin 进行视差回归,然后使用smooth L1 loss 损失函数。
3. 实验结果
3.1 Ablation Study
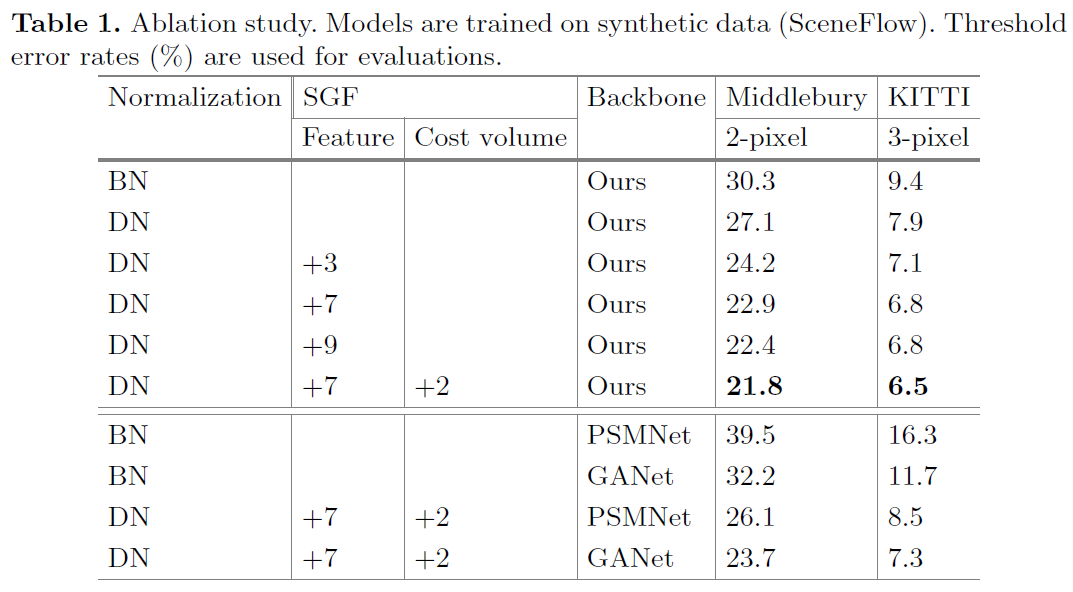
表明了DN和SGF能有效提高泛化能力,从而提高在新场景的视差估计精度。而且能够集成到其他最先进的方法,提高这些方法的泛化能力。
3.2 Component Analysis and Comparisons
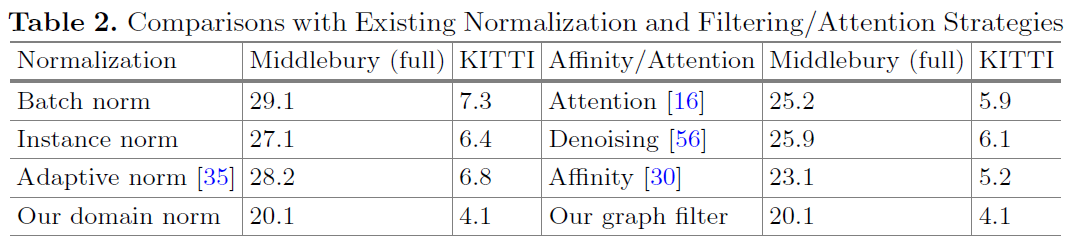
- 我们的域归一化在域不变立体匹配方面优于其他域归一化,因为它可以完全调节特征向量的分布并消除跨域泛化的图像级和局部对比度差异。
- 我们的 SGF 层更适合捕获结构和几何上下文以实现稳健的域不变立体匹配。
3.3 Cross-Domain Evaluations


DSMNet 在所有这些真实数据集的错误率上远远优于最先进的模型 3-30%。它也远优于传统算法,如 SGM 、costfilter 和 patchmatch。
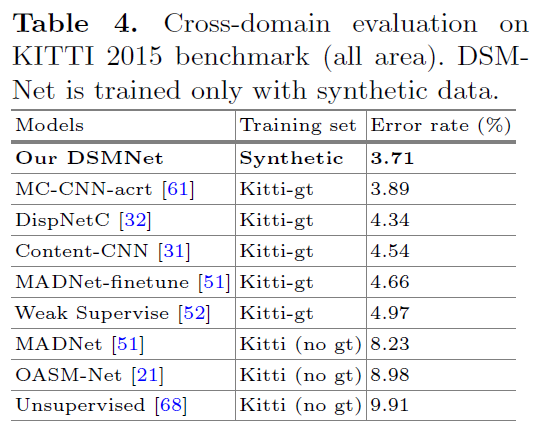
我们的模型远远优于在 KITTI 域上训练的大多数无监督/自监督模型。它甚至比在 KITTI 数据集上训练或微调的监督立体匹配网络更好。与其他微调的最先进模型,我们的 DSMNet(无微调)产生更准确的对象边界。
3.4 Fine-Tuning
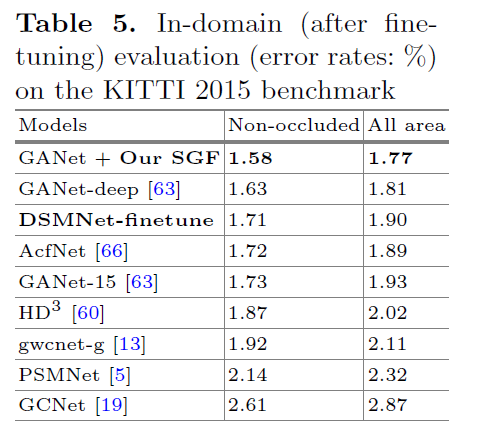
- 表明DSMNet 可以通过对一个特定数据集进行微调来达到相同的精度,而不会牺牲精度来提高其泛化能力。
- 表明 SGF 不仅可以提高跨域泛化能力,还可以提高测试域的准确性。
3.5 Efficiency and Parameters

可以看到,DSMNet相对于GANet,时间复杂度,参数量,内存占用都降低了,说明了DSMNet提出模块比较高效。
4. 结论
在四个真实数据集上验证了DSMNet,在跨域泛化中与其他最先进的模型相比显示了其卓越的准确性,它甚至优于一些使用测试域数据进行微调的深度神经网络模型(例如 MC-CNN)。















 1459
1459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









