







 本文详细分析了YOLOv2源码中的RNN和GRU层,包括forward_connected_layer、backward_connected_layer、update_connected_layer、forward_rnn_layer、backward_rnn_layer、update_rnn_layer以及forward_gru_layer。介绍了各函数的主要作用和参数含义,特别是GRU层的实现细节。
本文详细分析了YOLOv2源码中的RNN和GRU层,包括forward_connected_layer、backward_connected_layer、update_connected_layer、forward_rnn_layer、backward_rnn_layer、update_rnn_layer以及forward_gru_layer。介绍了各函数的主要作用和参数含义,特别是GRU层的实现细节。
我们再次回到了parse_network_cfg函数
//parse_network_cfg
else if(lt == ACTIVE){
l = parse_activation(options, params);
}
接着看后面这个parse_activation函数
#0x01 parse_activation
layer parse_activation(list *options, size_params params)
{
char *activation_s = option_find_str(options, "activation", "linear");
ACTIVATION activation = get_activation(activation_s);
layer l = make_activation_layer(params.batch, params.inputs, activation);
l.out_h = params.h;
l.out_w = params.w;
l.out_c = params.c;
l.h = params.h;
l.w = params.w;
l.c = params.c;
return l;
}
上面的一些参数我在之前的文章中已经说过了,这里就不再说明了。直接看关键函数make_activation_layer
layer make_activation_layer(int batch, int inputs, ACTIVATION activation)
{
...
l.forward = forward_activation_layer;
l.backward = backward_activation_layer;
...
return l;
}
前面的参数信息我这里也不再提了,直接看关键的两个函数,先看第一个forward_activation_layer
0x0101 forward_activation_layer
void forward_activation_layer(layer l, network net)
{
copy_cpu(l.outputs*l.batch, net.input, 1, l.output, 1);
activate_array(l.output, l.outputs*l.batch, l.activation);
}
貌似这里没什么好说的b( ̄▽ ̄)d
0x0102 backward_activation_layer
void backward_activation_layer(layer l, network net)
{
gradient_array(l.output, l.outputs*l.batch, l.activation, l.delta);
copy_cpu(l.outputs*l.batch, l.delta, 1, net.delta, 1);
}
貌似这里也没什么好说的d( •̀ ω •́ )y
回到parse_network_cfg函数
//parse_network_cfg
else if(lt == RNN){
l = parse_rnn(options, params);
}
#0x02 parse_rnn
layer parse_rnn(list *options, size_params params)
{
int output = option_find_int(options, "output",1);
int hidden = option_find_int(options, "hidden",1);
char *activation_s = option_find_str(options, "activation", "logistic");
ACTIVATION activation = get_activation(activation_s);
int batch_normalize = option_find_int_quiet(options, "batch_normalize", 0);
int logistic = option_find_int_quiet(options, "logistic", 0);
layer l = make_rnn_layer(params.batch, params.inputs, hidden, output, params.time_steps, activation, batch_normalize, logistic);
l.shortcut = option_find_int_quiet(options, "shortcut", 0);
return l;
}
我先说说这里的几个参数的含义,因为我之前有的没有讲过。
hidden:RNN隐藏层的元素个数time_steps:RNN的步长logistic:Logistic激活函数
接着我们来看关键函数make_rnn_layer
0x02 make_rnn_layer
作者这里使用的是vanilla RNN结构,有三个全连接层组成。
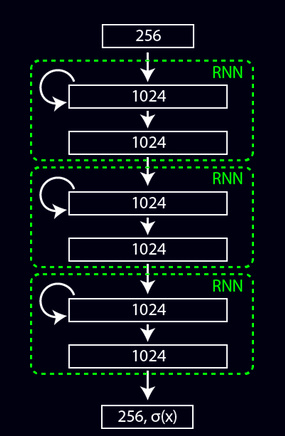
layer make_rnn_layer(int batch, int inputs, int outputs, int steps, ACTIVATION activation, int batch_normalize, int adam)
{
...
l.input_layer = malloc(sizeof(layer));//隐藏层1
fprintf(stderr, "\t\t");
*(l.input_layer) = make_connected_layer(batch*steps, inputs, outputs, activation, batch_normalize, adam);
l.input_layer->batch = batch;
l.self_layer = malloc(sizeof(layer));//隐藏层2
fprintf(stderr, "\t\t");
*(l.self_layer) = make_connected_layer(batch*steps, outputs, outputs, activation, batch_normalize, adam);
l.self_layer->batch = batch;
l.output_layer = malloc(sizeof(layer));//隐藏层3
fprintf(stderr, "\t\t");
*(l.output_layer) = make_connected_layer(batch*steps, outputs, outputs, activation, batch_normalize, adam);
l.output_layer->batch = batch;
l.outputs = outputs;
l.output = l.output_layer->output;
l.delta = l.output_layer->delta;
l.forward = forward_rnn_layer;
l.backward = backward_rnn_layer;
l.update = update_rnn_layer;
...
我们看这里的make_connected_layer函数
0x0201 make_connected_layer
layer make_connected_layer(int batch, int inputs, int outputs, ACTIVATION activation, int batch_normalize, int adam)
{
...
l.forward = forward_connected_layer;
l.backward = backward_connected_layer;
l.update = update_connected_layer;
...
}
这里的参数信息也没什么好说的,直接看函数吧
0x020101 forward_connected_layer
void forward_connected_layer(layer l, network net)
{
fill_cpu(l.outputs*l.batch, 0, l.output, 1);
int m = l.batch;
int k = l.inputs;
int n = l.outputs;
float *a = net.input;
float *b = l.weights;
float *c = l.output;
gemm(0,1,m,n,k,1,a,k,b,k,1,c,n);
if(l.batch_normalize){
forward_batchnorm_layer(l, net);
} else {
add_bias(l.output, l.biases, l.batch, l.outputs, 1);
}
activate_array(l.output, l.outputs*l.batch, l.activation);
}
这个函数其实没什么好说的,要注意的地方就是这里的b是转置的。还有一个地方要注意的是,这里没有了groups
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7737
7737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









