







深度学习:CSPNet
前言
CSPNet 是作者 Chien-Yao Wang 于 2019 发表的论文 CSPNET: A NEW BACKBONE THAT CAN
ENHANCE LEARNING CAPABILITY OF CNN。也是对 DenseNet 网络推理效率低的改进版本。
解决的问题
- 由于在轻量级的网络下,他的精度会有所下降,CSPnet可以在维持足够精度的同时提升10%到20%的计算效率,同时可以应用于传统的 ResNet,ResNeXt,DenseNet等网络。
- 降低计算瓶颈。
- 降低内存资源。
Method
目前主流网络存在的问题
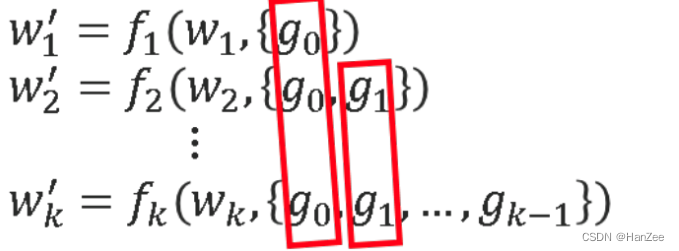
我们以DenseNet为例,如上图,我们上下两个分别为他们的推导公式,我们发现有很多以前的feature重复出现,在反向传播的过程中,网络会不断的学习这些相同的梯度,作者认为这些冗余feature会影响模型的性能,于是作者对网络做出了下面的改进。
##Cross Stage Partial Network
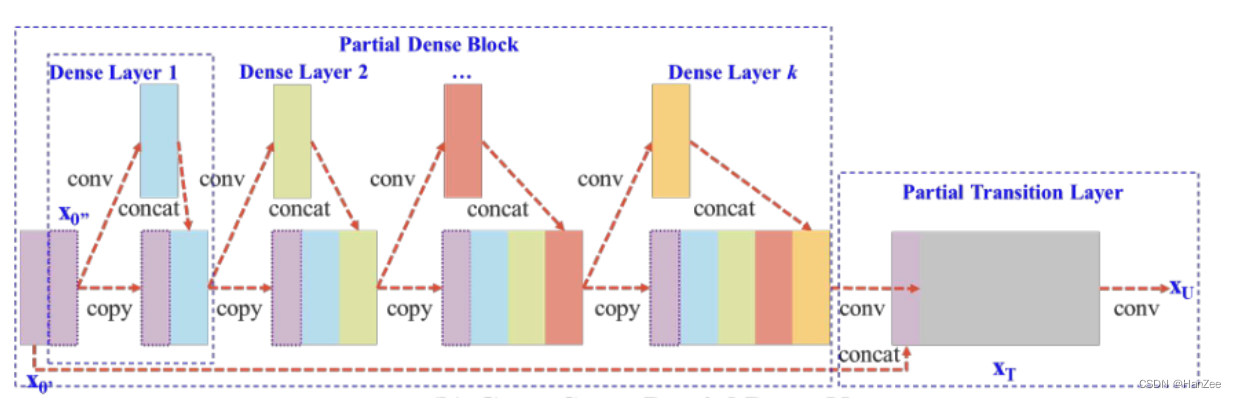
如上图为作者作出的改进,作者首先把input 分成两部分,一部分经过了卷基层,另一部分什么也不做,然后在把这两个结果concat拼接。
总体而言,所提出的 CSPDenseNet 保留了 DenseNet 特征重用特性的优势,但同时通过截断梯度流来防止过多的重复梯度信息。这个想法是通过设计分层特征融合策略并在局部transition层中使用来实现的。
Partial Dense Block
设计局部dense block的优点是:
- 增加梯度路径:通过拆分合并策略,梯度路径的数量可以增加一倍。由于采用了跨阶段策略,可以缓解使用显式特征图副本进行concatenation带来的缺点;
- 平衡每层的计算:通常,DenseNet 的base layer中的通道数远大于growth rate(注:DenseNet的超参数,值为dense block中dense卷积层的卷积核个数)。由于在一个局部dense block中参与dense层操作的base layer通道只占原始数量的一半,因此可以有效解决近一半的计算瓶颈(注:解决近一半的计算瓶颈是通过拆分输入通道实现,拆分各一半,一半传入dense block,一半直接传到dense block后);
- 减少内存流量:假设 DenseNet 中一个dense block的基本特征图大小为w × h × c,growth rate为 dd,总共有 m 个dense层。那么,那个dense block的CIO(Convolutional Input/Output)是( c × m ) + ( ( m ^ 2 + m ) × d ) / 2 。虽然 m 和 d 通常远小于 c,但局部dense block最多可以节省网络一半的内存流量。
Partial Transition Layer
在DenseNet中,Trainsition layer起到了特征融合的作用,在这里,作者采取了4中不同的融合策略进行试验如下图:
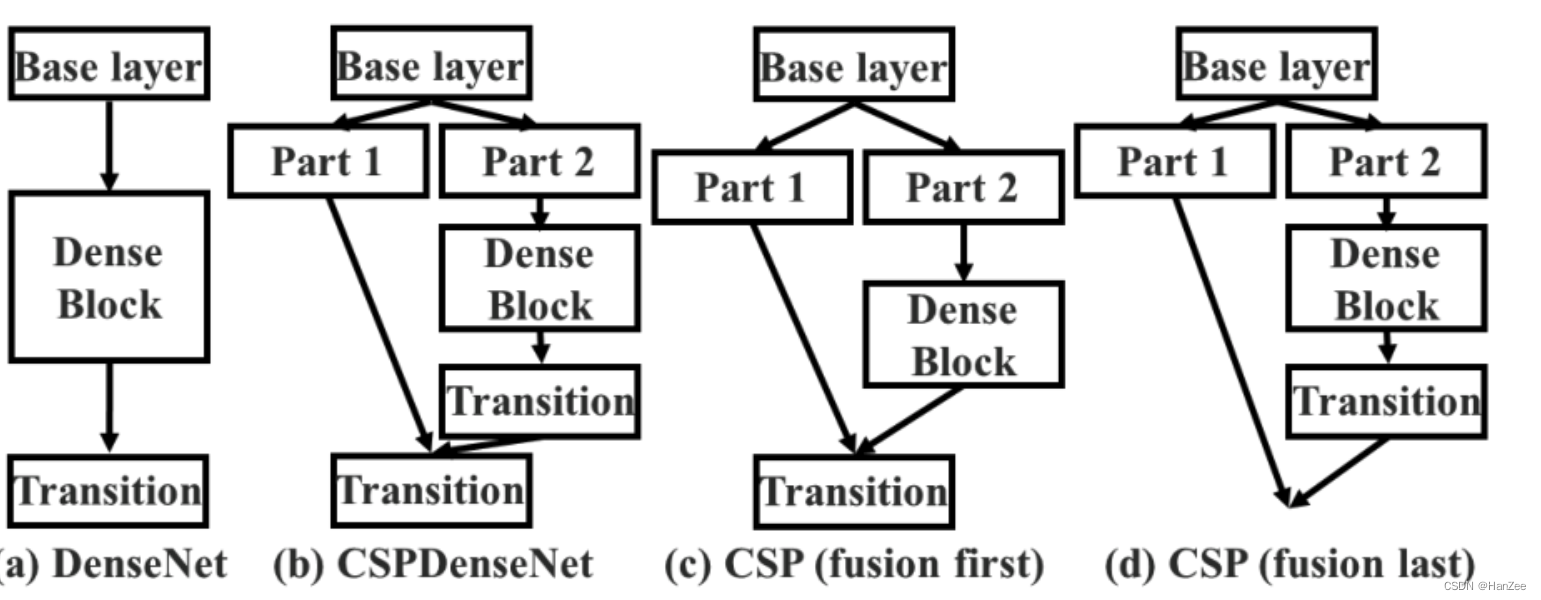
通过实验,最终作者选取了第三种方案,这种方案速度更快,精度更高。
Exact Fusion Model
略
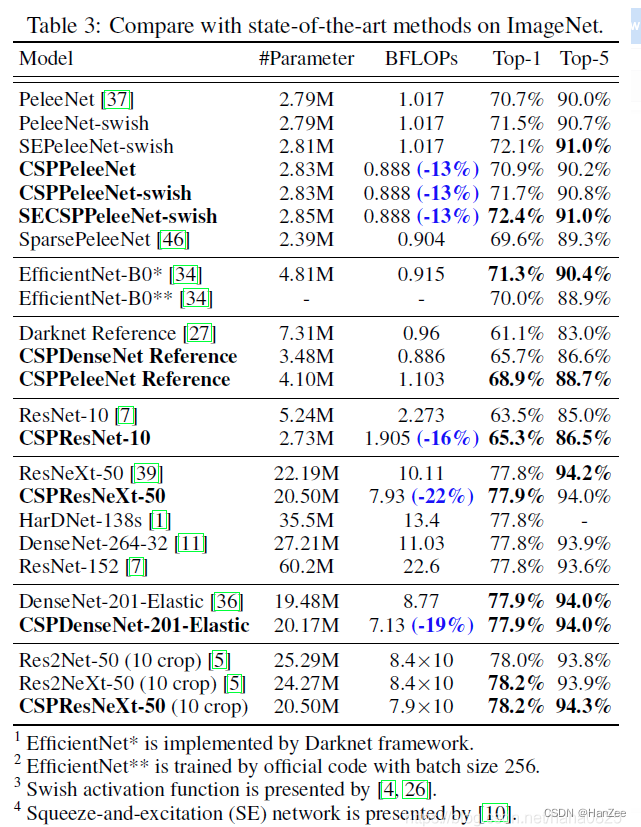
实验

















 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











